论文精读:Generative Adversarial Imitation Learning(生成对抗模仿学习)
生成对抗模仿学习论文分享(Generative Adversarial Imitation Learning)
1.背景介绍
1.1.论文背景
这篇论文是2016年由斯坦福大学研究团队提出的,两位作者,一位是Jonathan Ho,履历十分丰富,主要研究方向是无监督学习和强化学习,另一位是Stefano Ermon,他是斯坦福大学的副教授,主要研究方向是概率建模、生成学习和推理。
1.2.读前先问
- 为什么会选择这篇论文呢?
因为我的毕业设计自动驾驶,模型学习的效果并没有达到预期,一是训练的时间成本很高,二是没有办法让模型学会遵守交通规则。后来在《动手学强化学习》这本书里看到了模仿学习,综合考量了一下现在的模仿学习算法,最后选择了这篇论文,也就是基于生成对抗网络模仿学习。
- 大方向的任务是什么?
自动驾驶抽象出来其实是一个决策问题,那么强化学习就是让模型学习最优决策的。
- 这个方向有什么问题?是什么类型的问题?
- 对于比较复杂的场景智能体学习太慢。(DeepMind提出的Rainbow算法训练需要34200个GPU hour,差不多1000多天,所以必须的并行训练)
- 在现实场景中,奖励函数难以定义,依赖于现实环境的规则,设计不当的话智能体可能找到某些漏洞。(自动驾驶汽车停滞不前)
- 为什么会有这些问题?
- 智能体一开始学习时为了探索环境会更多的选择随机动作,比如DQN就会按照一个衰减的概率来选择是探索还是利用,就会导致前期花费大量的时间探索,而且大部分都是无意义的探索。
- 现实世界的规则不能详尽,就会导致奖励函数难以形式化的表达,体现在代码上就是很难通过一个函数来计算奖励。比如对于自动驾驶任务来说,交通规则就是一种限制,后绿灯、车道线和人行道等等,不可能按照《道路交通安全法》的所有条例来设计奖励函数,而且这些规则也是会变动的,不同的地区交通规则也不一样。
- 作者是怎么解决这个问题的?
- 首先,模仿学习可以通过专家经验来快速学习,这样就减少了探索的时间,避免智能体一开始就探索一些明显无意义的动作,比如前面有一堵墙,智能体就非得试验一下执行全速撞上去的动作会导致什么状态。
- 其次,在专家经验中包括了潜在的规则,比如自动驾驶,虽然我们没有办法结合所有的规则设计奖励函数,但是可以通过学习老司机的驾驶方式来学习规则,相当于专家经验隐式的给出了奖励函数的一个相对大小,但是也没有明确的定义。
- 怎么验证解决方案是否有效?
- 论文中:模型达到专家效果所需要的数据集大小。
- 考察学习速度:模型训练达到相同效果所需要的时间是否更短。
- 考察占用度量:相同状态下智能体采取的动作和专家采取的动作相同的重合率。
1.3.强化学习基础
首先还是来说一下强化学习。
强化学习是机器通过与环境交互来实现目标的一种算法,首先机器在环境的一个状态下感知环境,然后经过自身的计算做一个动作决策,之后把这个动作作用到环境当中,最后环境发生相应的改变,并且将相应的奖励和下一轮的状态传回机器,然后机器在下一轮交互中感知新的环境状态,以此类推。

在强化学习中机器称之为智能体(Agent),类似于有监督学习中的“模型”,但是强化学习中强调的是智能体不但可以感知周围的环境,还可以通过做决策直接改变这个环境,而不只是给出一些预测信号。
在强化学习中有一些基本概念:
- 随机过程
如果抛开智能体不谈,环境一般来说是动态的,它会随着某些因素的变化而不断演变,是一个随机过程。
随机过程是一连串随机现象动态关系的定量描述,研究对象是随时间演变的随机现象。
例:汽车经过一个十字路口,它可以直行、左转、右转和调头,这就是一个随机的过程,定量描述就是要确定它直行、左转、右转和调头的概率有多大。
随机现象在某个时刻t的取值是一个向量,用 S t S_{t} St表示,所有可能的状态组成状态集合 S S S。
对于一个随机过程,最关键的要素就是状态以及状态转移的条件概率分布,在某个时刻t的状态 S t S_{t} St通常取决于t时刻之前的状态,那么同理,下一时刻的状态为 S t + 1 S_{t+1} St+1的概率就可以表示成 P ( S t + 1 ∣ S 1 , . . . , S t ) P(S_{t+1}|S_{1},...,S_{t}) P(St+1∣S1,...,St)。
- 马尔可夫性质
此时如果加入马尔可夫性质:某时刻的状态只取决于上一时刻的状态,公式就可以简化成 P ( S t + 1 ∣ S t ) = P ( S t + 1 ∣ S 1 , . . . , S t ) P(S_{t+1}|S_{t}) = P(S_{t+1}|S_{1},...,S_{t}) P(St+1∣St)=P(St+1∣S1,...,St)。
马尔可夫性质就是说下一刻的状态只取决于当前状态,不会受到过去状态的影响,但并不代表和历史完全没有关系,因为t+1时刻的状态虽然只与t时刻的状态有关,但是t时刻的状态信息其实包含了t-1时刻的状态信息,通过这种链式关系,历史信息就被传递到了现在。
所以马尔可夫性质实际上是简化了计算,只要当前状态可知,所有的历史状态就不再需要了。
- 马尔可夫过程
具有马尔可夫性质的随机过程称之为马尔可夫过程,通常用元组(S, P)表示,其中S是随机过程中有限数量的状态集合,P是状态转移矩阵。
假设一共有n个状态,那么状态转移矩阵就定义了所有状态对之间的转移概率,矩阵的第i行第j列元素表示的就是从状态 s i s_{i} si转移到状态 s j s_{j} sj的概率。
P = [ P ( s 1 ∣ s 1 ) ⋯ P ( s n ∣ s 1 ) ⋮ ⋱ ⋮ P ( s 1 ∣ s n ) ⋯ P ( s n ∣ s n ) ] \mathcal{P}=\left[\begin{array}{ccc} P\left(s_{1} \mid s_{1}\right) & \cdots & P\left(s_{n} \mid s_{1}\right) \\ \vdots & \ddots & \vdots \\ P\left(s_{1} \mid s_{n}\right) & \cdots & P\left(s_{n} \mid s_{n}\right) \end{array}\right] P=⎣⎢⎡P(s1∣s1)⋮P(s1∣sn)⋯⋱⋯P(sn∣s1)⋮P(sn∣sn)⎦⎥⎤
- 马尔可夫奖励过程
如果在马尔可夫过程的基础上再加入奖励函数r和折扣因子γ,就可以达到马尔可夫奖励过程,由元组(S, P, r, γ)组成。
奖励函数r是指转移到某个状态s时得到的奖励,比如自动驾驶任务中给定一个任务过程:先洗车、然后加油、最后回家,那么当车辆到达洗车店的时候会得到一个奖励,再到达加油站的时候还会得到一个奖励,最后回家的时候也会得到一个奖励。
折扣因子γ的取值范围是[0, 1),左闭右开。引入折扣因子是因为远期利益具有一定的不确定性,有时我们希望能够尽快获得一个奖励,所以需要对远期利益打一些折扣。γ越接近1表示更关注长期的累积奖励,越接近0表示更关注短期奖励。
在马尔可夫奖励过程中,一个状态的期望回报被称为这个状态的价值,所有状态的价值就组成了价值函数,价值函数的输入为某个状态,输出为这个状态的分值。
同样对于洗车、加油和回家三个状态,洗车的价值没有加油的价值大,因为洗不洗车无所谓,但是不加油可能回不了家,加油的价值也没有回家的价值大,因为最终目的是回家。
所以r(洗车)=1、r(加油)=3、r(回家)=5。
- 马尔可夫决策过程
上面的随机过程都是环境自发改变的,如果有一个外界的刺激,也就是智能体的动作,那么环境的下一个状态的由当前状态和智能体的动作来共同决定。
马尔可夫决策过程就是在马尔可夫奖励过程的基础上再加入智能体的动作,由元组(S, P, A, r, γ)组成,其中A表示动作集合,而奖励函数和状态转移函数也与A有关。
智能体采取的动作是由策略 π \pi π决定的, π ( a ∣ s ) = P ( A t = a ∣ S t = s ) \pi(a|s)=P(A_{t}=a|S_{t}=s) π(a∣s)=P(At=a∣St=s),表示在输入状态为s的情况下采取动作a的概率。
价值函数分成了状态价值函数和动作价值函数:
状态价值函数:从状态 s s s出发遵循策略 π \pi π能获得的期望回报, V π ( s ) = E π [ G t ∣ S t = s ] V^{\pi}(s)=E_{\pi}[G_{t}|S_{t}=s] Vπ(s)=Eπ[Gt∣St=s]。
动作价值函数:在使用策略 π \pi π时,对当前状态 s s s执行动作 a a a得到的期望回报, Q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] Q^{\pi}(s,a)=E_{\pi}[G_{t}|S_{t}=s, A_{t}=a] Qπ(s,a)=Eπ[Gt∣St=s,At=a]。
- 占用度量
不同策略的价值函数是不一样的,因为智能体访问到的状态的概率分布式不一样的。
所以我们可以定义占用度量:表示在执行策略 π \pi π时状态动作对(s, a)被访问到的概率。
2.论文思想
2.1.模仿学习
强化学习的数据是通过智能体与环境的交互得到的,并不需要有监督学习中的标签,但是很依赖奖励函数的设置。在很多现实场景中,奖励函数被没有给定,如果简单的设计奖励函数就没法保证强化学习训练出来的策略满足实际要求。
例如对于自动驾驶汽车的控制,观测的是当前的环境感知信息,动作是接下来具体路径的规划,如果奖励函数只是简单的设置向前行驶不发生碰撞的奖励为+1,发生碰撞的奖励为-10,那么智能体学习的结果很可能是找个地方停滞不前,所以很多自动驾驶汽车的奖励函数都是经过精心设计和调试的。
假如说存在一个专家智能体,它的策略可以看成是最优策略,那么模仿学习就是通过直接模仿这个专家在环境中交互的状态动作数据来训练智能体的策略,这时候就不需要用到环境提供的奖励信号了。
2.2.行为克隆和逆强化学习
目前学术界模仿学习的方法基本上可以分为三类:
- 行为克隆(Behavior Cloning, BC):直接使用监督学习的方法,将专家数据中
(s, a)元组的s看作样本输入,a看作标签,学习的目标为: θ ∗ = arg min θ E ( s , a ) ∼ B [ L ( π θ ( s ) , a ) ] \theta^{*} = \arg \min_{\theta} E_{(s,a)\sim B}[L(\pi_{\theta}(s), a)] θ∗=argminθE(s,a)∼B[L(πθ(s),a)]
其中B是专家数据集,L是对应监督学习框架下的损失函数。如果动作是离散的,损失函数可以通过最大似然估计得到,如果动作是连续的,损失函数可以是均方误差。
优点:① 实现简单;② 可以很快学习到一个不错的策略。
缺点:① 需要大量数据支持;② 泛化能力不够强,不能处理专家经验中没有覆盖到的情况;③ 智能体拟合的专家轨迹可能是有偏的,可能会学到一些小习惯,无法判断知识的重要性;④ 监督学习中对于没见过的情况只是在这个情况效果不好,但是对于强化学习来说,现在的某个状态效果不好可能会影响后面的状态,即复合误差。
- 逆强化学习(Inverse Reinforcement Learning, IRL):假设环境的奖励函数应该使得专家策略获得最高的奖励值,进而学习背后的奖励函数,最后基于该奖励函数进行正向强化学习,从而得到模仿策略。
具体来讲,假设我们有一个专家策略 π E \pi_{E} πE,希望通过逆强化学习对其进行反向推演,实际上是在一个函数集合C中找到一个最优的损失函数。
所以逆强化学习的优化函数: maximize c ∈ C ( min π ∈ Π − H ( π ) + E π [ c ( s , a ) ] ) − E π E [ c ( s , a ) ] \underset{c \in \mathcal{C}}{\operatorname{maximize}}\left(\min _{\pi \in \Pi}-H(\pi)+\mathbb{E}_{\pi}[c(s, a)]\right)-\mathbb{E}_{\pi_{E}}[c(s, a)] c∈Cmaximize(minπ∈Π−H(π)+Eπ[c(s,a)])−EπE[c(s,a)],其中 π E \pi_{E} πE是专家策略, π \pi π是我们要学习的策略, H ( π ) ≜ E π [ − log π ( a ∣ s ) ] H(\pi) \triangleq \mathbb{E}_{\pi}[-\log \pi(a \mid s)] H(π)≜Eπ[−logπ(a∣s)]是策略 π \pi π的γ-折扣因果熵。
也就是说, E π E [ c ( s , a ) ] \mathbb{E}_{\pi_{E}}[c(s, a)] EπE[c(s,a)]是通过专家策略 π E \pi_{E} πE与环境进行交互采样得到的轨迹的期望损失,同理 E π [ c ( s , a ) ] \mathbb{E}_{\pi}[c(s, a)] Eπ[c(s,a)]是学习策略的通过专家采样轨迹的状态-行为对得到的期望损失,而引入最大因果熵的目的是对于观测到的专家轨迹中没有出现过的状态,尽量随机的采取动作。
所以,IRL就是寻找一个损失函数 c ∈ C c \in C c∈C,对于专家策略有较低的损失,对于其它策略有较高的损失,以此来反向推演专家策略的损失函数。从根本上来说,逆强化学习学到的损失函数是解释了专家的行动,并没有直接告诉智能体怎么去行动。
优点:学习损失函数,优先拟合专家轨迹,不存在复合误差的问题。
缺点:计算成本高,需要不断的进行内循环强化学习。
2.3.生成对抗模仿学习
- 生成对抗模仿学习(Generative Adversarial Imitation Learning, GAIL):基于生成对抗网络直接从数据中学习策略,绕过了中间逆强化学习的步骤。
生成对抗模仿学习的实质是模仿了专家策略的占用度量,尽量使得学习的策略在环境中的所有状态动作对的占用度量 ρ π ( s , a ) \rho_{\pi}(s,a) ρπ(s,a)和专家策略的占用度量 ρ π E ( s , a ) \rho_{\pi_{E}}(s,a) ρπE(s,a)一致。
为了达到这一目的,策略是需要和环境进行交互的,GAIL算法中有一个判别器和一个策略,策略 π \pi π就相当于生成对抗网络中的生成器,给定一个状态,策略会输出这个状态下应该采取的动作,而判别器D将状态动作对(s, a)作为输入,输出一个0~1的实数,表示判别器认为这个状态动作对是来自智能体策略还是专家策略。
判别器D的目标是尽量将专家数据的输出靠近0,将智能体策略的输出靠近1,这样才可以将两组数据分辨开来,所以判别器D的损失函数为: L ( ϕ ) = − E ρ π [ log D ϕ ( s , a ) ] − E ρ E [ l o g ( 1 − D ϕ ( s , a ) ) ] L(\phi)=-E_{\rho_{\pi}}[\log D_{\phi}(s, a)] - E_{\rho_{E}}[log(1-D_{\phi}(s, a))] L(ϕ)=−Eρπ[logDϕ(s,a)]−EρE[log(1−Dϕ(s,a))],其中 ϕ \phi ϕ是判别器D的参数。
智能体策略的目标是交互产生的轨迹能被判别器误认为是专家轨迹,所以可以用判别器D的输出作为奖励函数来训练智能体策略,也就是说智能体策略在环境中采样到状态s,并且采取动作a,这个状态动作对(s, a)会输入到判别器D中,输出D(s, a)的值,然后将奖励设置为r(s, a) = -log D(s, a)。最后,在不断对抗的过程中,智能体策略生成的数据分布会越来越接近真实的专家数据分布。
2.4.实验结果
论文中在gym的9个控制任务上对GAIL进行了评估,首先是用TRPO训练了一个专家策略,然后从专家策略中抽取不同轨迹的数据集,然后测试了三种算法,第一个是行为克隆算法,就是直接用给定的状态动作对进行有监督训练,第二个是特征期望匹配算法,这是一种逆强化学习算法,第三种就是GAIL。三个模型采用的是相同的神经网络架构,每次试验开始也是随机初始化,提供完全相同的环境交互。

实验结果图中,y轴表示模型表现能力,专家策略为1,随机动作为0,x轴表示数据集中专家轨迹的数量,也就是数据集的大小。
其中8个实验中,GAIL的效果都非常好。可以发现,行为克隆算法的效果非常依赖专家策略数据的数量,模型效果是随着数据量的提升而提升的,这说明行为克隆的专家数据利用率比较低。逆强化学习的效果比行为克隆要好一点,GAIL的性能基本上能够完全跟专家策略持平。
而且我们还可以发现,行为克隆的模型效果虽然会随着数据量的上升而提升,但是没有能够超过专家的,而生成GAIL的效果其实有几个是完全可以超过专家水平的。为什么会这样呢?首先行为克隆其实就是有监督训练,那么数据集的质量其实已经锁定了模型的上限,模型效果只能无限逼近这个上线而不能超过它。其次,生成对抗模仿学习不仅仅可以利用专家的数据,还会通过生成器生成新的数据,所以它的上限是有可能超过专家的。
举个例子,行为克隆就好像数学里的求极限,只能无限逼近极限值而不可能取到极限值,而生成对抗就好像一位老师,把毕生所学都交给你之后,你自己再通过不断的学习,最终超越了老师,长江后浪推前浪,前浪死在沙滩上,但是生成对抗的效果虽然有可能会比专家效果好,也不可能好太多,因为老师就在这,你超过了他之后,他就没法继续教导你了,你就需要继续寻找更厉害的老师。这就好像我们上学一样,上完了小学上初中,上完了初中上高中,上完了高中上大学,不断地在寻找更厉害的老师,向他们学习。
一点小想法:生成对抗模仿学习的模型效果有可能超过专家的效果,那么是不是可以将超过专家效果时生成数据也添加到专家轨迹中,相当于自己给自己当老师,不断超越自己。
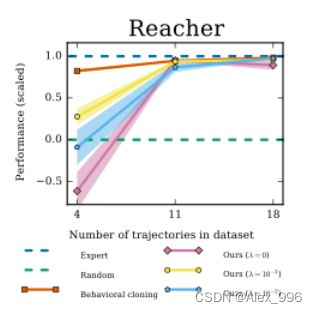
在Reacher任务中,行为克隆的样本利用效率比GAIL要更高,然后作者开始疯狂调参,但最终也没有比得过行为克隆,论文中也没有解释为什么,应该是跟这个任务的环境比较相关。
3.代码实践
Step 1.生成专家数据
通过PPO算法训练一个专家策略,首先定义了一个策略网络。
class PolicyNet(nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)
然后定义了一个价值评估网络。
class ValueNet(nn.Module):
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
之后就是通过PPO算法进行训练,这里采用了PPO-截断的方式。
class PPO:
""" PPO算法,采用截断方式 """
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, lambda_, epochs, eps, gamma):
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.critic = ValueNet(state_dim, hidden_dim).to(device)
self.actor_optimizer = th.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = th.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
self.lambda_ = lambda_
self.epochs = epochs
self.eps = eps
def take_action(self, state):
state = th.tensor([state], dtype=th.float).to(device)
probs = self.actor(state)
action_dist = th.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
def update(self, transition_dict):
states = th.tensor(transition_dict["states"], dtype=th.float).to(device)
actions = th.tensor(transition_dict["actions"], dtype=th.float).view(-1, 1).to(device)
rewards = th.tensor(transition_dict["rewards"], dtype=th.float).view(-1, 1).to(device)
next_states = th.tensor(transition_dict["next_states"], dtype=th.float).to(device)
dones = th.tensor(transition_dict["dones"], dtype=th.float).view(-1, 1).to(device)
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones).to(device)
td_delta = td_target - self.critic(states)
advantage = compute_advantage(self.gamma, self.lambda_, td_delta).to(device)
old_log_probs = th.log(self.actor(states).gather(1, actions.type(th.int64))).detach()
for _ in range(self.epochs):
log_probs = th.log(self.actor(states).gather(1, actions.type(th.int64)))
ratio = th.exp(log_probs - old_log_probs)
surr1 = ratio * advantage
surr2 = th.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantage
actor_loss = th.mean(-th.min(surr1, surr2))
critic_loss = th.mean(F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()
训练完了之后,最终的reward可以达到接近500.
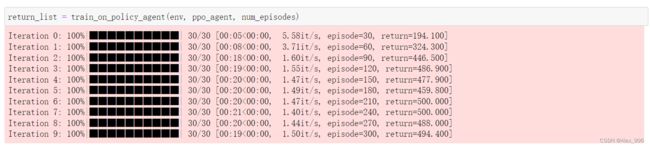
最后从PPO训练出来的专家策略中采样得到专家轨迹。
Step 2.行为克隆
行为克隆的实现其实很简单,就是一个策略网络,先以专家数据作为输入进行训练,然后直接在环境中测试智能体的效果。
class BehaviorClone:
def __init__(self, state_dim, hidden_dim, action_dim, lr):
self.policy = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.optimizer = th.optim.Adam(self.policy.parameters(), lr=lr)
def learn(self, states, actions):
states = th.tensor(states, dtype=th.float).to(device)
actions = th.tensor(actions).view(-1, 1).to(device)
log_probs = th.log(self.policy(states).gather(1, actions.type(th.int64)))
bc_loss = th.mean(-log_probs) # 最大似然估计
self.optimizer.zero_grad()
bc_loss.backward()
self.optimizer.step()
def take_action(self, state):
state = th.tensor([state], dtype=th.float).to(device)
probs = self.policy(state)
action_dist = th.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
Step 3.生成对抗模仿学习
最后生成对抗模仿学习,需要再定义一个判别器,我这是直接把状态和动作向量拼接在一起,也就是状态动作对,过了两层全连接,最后过了一个Sigmoid输出0~1之间的概率。
class Discriminator(nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(Discriminator, self).__init__()
self.fc1 = th.nn.Linear(state_dim + action_dim, hidden_dim)
self.fc2 = th.nn.Linear(hidden_dim, 1)
def forward(self, x, a):
cat = th.cat([x, a], dim=1)
x = F.relu(self.fc1(cat))
return th.sigmoid(self.fc2(x))
详细代码地址:https://gitcode.net/weixin_43336281/reinforcementlearning/-/tree/master/%E6%A8%A1%E4%BB%BF%E5%AD%A6%E4%B9%A0