Example 6.6 Cliff Walking
This gridworld example compares Sarsa and Qlearning, highlighting the difference between on-policy (Sarsa) and off-policy (Qlearning) methods. Consider the gridworld shown in the upper part of Figure 6.5. This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is −1 on all transitions except those into the region marked “The Cliff.” Stepping into this region
incurs a reward of −100 and sends the agent instantly back to the start.
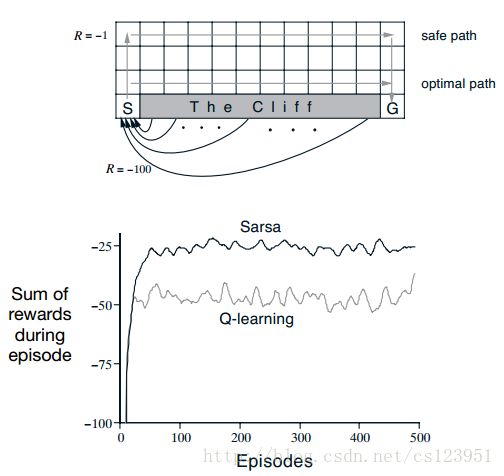
如图所示,在每个网格都可以走上下左右四个方向,但是进入cliff区域会马上回到s点,设S(0,0),G(12,0),建立坐标轴。整个网格长12,宽4。
设计环境奖励,下个状态,如下所示。
(1)如果当前状态是goal,则立即返回下个状态和奖励值,奖励值也为-1,goal的下一个状态其实是没用的,因为一旦检测到最终状态,就会结束,但是需要用到goal的下一个状态用来更新goal的Q(s,a)值。
(2)如果当前状态在cliff区域里面,则立即返回到S,奖励值为-100。
(3)其他则返回-1的奖励值。
def observe(x,y,q,a):
goal = 0
if x ==q.shape[0] - 1 and y == 0:
goal = 1
if a == 0:
y += 1
if a == 1:
x += 1
if a == 2:
y -= 1
if a == 3:
x -= 1
x = max(0,x)
x = min(q.shape[0]-1, x)
y = max(0,y)
y = min(q.shape[1]-1, y)
if goal == 1:
return x,y,-1
if x>0 and x0]-1 and y==0:
return 0,0,-100
return x,y,-1 还可以用数组定义环境的下一个状态和奖励值:
actionRewards = np.zeros((12, 4, 4))
actionRewards[:, :, :] = -1.0
actionRewards[1:11, 1, 2] = -100.0
actionRewards[0, 0, 1] = -100.0
actionDestination = []
for i in range(0, 12):
actionDestination.append([])
for j in range(0, 4):
destination = dict()
destination[0] = [i, min(j+1,3)]
destination[1] = [min(i+1,11), j]
if 0 < i < 11 and j == 1:
destination[2] = [0,0]
else:
destination[2] = [i, max(j - 1, 0)]
destination[3] = [max(i-1,0), j]
actionDestination[-1].append(destination)
actionDestination[0][0][1] = [0,0]这个和observe函数的作用是一样的,其中对于cliff区域的处理可能不一样,但是不影响最终结果。
然后定义sarsa函数,主要是a_next = epsilon_policy(x_next,y_next,q,epsilon)和q-learning有区别。另外,runs指500个episode执行了20次,然后取平均值。
def sarsa_on_policy(q):
runs = 20
rewards = np.zeros([500])
for j in range(runs):
for i in range(500):
reward_sum = 0
x = 0
y = 0
a = epsilon_policy(x,y,q,epsilon)
while True:
[x_next,y_next] = actionDestination[x][y][a]
reward = actionRewards[x][y][a]
reward_sum += reward
a_next = epsilon_policy(x_next,y_next,q,epsilon)
q[x][y][a] += alpha*(reward + gamma*q[x_next][y_next][a_next]-q[x][y][a])
if x == x_length - 1 and y==0:
break
x = x_next
y = y_next
a = a_next
rewards[i] += reward_sum
rewards /= runs
avg_rewards = []
for i in range(9):
avg_rewards.append(np.mean(rewards[:i+1]))
for i in range(10,len(rewards)+1):
avg_rewards.append(np.mean(rewards[i-10:i]))
return avg_rewards定义Q-learning函数,和sarsa的主要区别在于a_next = max_q(x_next,y_next,q):
def q_learning(q):
runs = 20
rewards = np.zeros([500])
for j in range(runs):
for i in range(500):
reward_sum = 0
x = 0
y = 0
while True:
a = epsilon_policy(x,y,q,epsilon)
x_next, y_next,reward = observe(x,y,a)
a_next = max_q(x_next,y_next,q)
reward_sum += reward
q[x][y][a] += alpha*(reward + gamma*q[x_next][y_next][a_next]-q[x][y][a])
if x == x_length - 1 and y==0:
break
x = x_next
y = y_next
rewards[i] += reward_sum
rewards /= runs
avg_rewards = []
for i in range(9):
avg_rewards.append(np.mean(rewards[:i+1]))
for i in range(10,len(rewards)+1):
avg_rewards.append(np.mean(rewards[i-10:i]))
return avg_rewards得到的奖励值为:
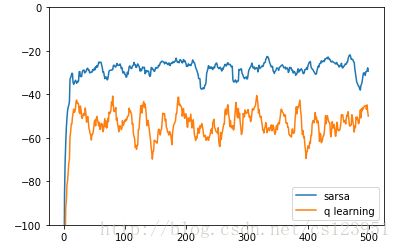
得到的最优路径如下:

总结:
1. Sarsa和Q-learning的不同主要在于更新Q值时,选择的行动a_next。Sarsa根据 ϵ−greedy 策略选择a_next,在接下来的行动中,也执行a_next;而Q-learning则不管行动依据的策略,而是选择q最大的a_next,在接下来的行动中,不执行a_next,而是根据 ϵ−greedy 策略选择a_next。可以将Sarsa理解为“言出必行”,而Q-learning则是“言行不一”。这也是on-policy和off-policy的差别。
2. 二者更新Q值的不同,产生的效果也不一样,从以上图片可以看出,Q-learning虽然比Sarsa早收敛,但是它的平均奖励值比Sarsa低。因为Q-learning根据Q的最大值来选择行动,而cliff区域边缘的Q值通常较大,因此容易跑到cliff边缘,而一不小心又会跑到cliff区域。因此虽然Sarsa还没得到最优路径,但Sarsa得到的平均奖励还比较高。Sarsa的优点是safer but learns longer。
源码:https://github.com/Mandalalala/Reinforcement-Learning-an-introduction/tree/master/Chapter%206