神经网络的学习
整个深度学习就是靠梯度下降算法撑起来的。
整个运行的过程就是求解一个巨大的函数,求解这个函数的方法使用的就是梯度下降算法。
Conv2d(imput, output, kernel_size, stride, padding)
其中output就是卷积核个数,下层卷积层的输入跟上层卷积层的输出应保持一致。stride为步长,如果不标注的话默认为1。padding为零填充,它的作用是可以使卷积过程从卷积核的中心开始。
一般情况下,采用的kernel_size为3*3的。
超参数:epoch,learning rate,kernel_size,batch_size
view函数将张量x变形成一维向量形式,总特征数不变,为全连接层做准备
covn2d为卷积层
maxpool为池化层
relu为激活函数
SGD和交叉熵损失为计算loss函数的
最好能用上adam
nn.linear做线性操作,进行张量计算。
tensor分为头信息区(Tensor)和存储区(Storage)
信息区主要存放以下信息:形状(size)、步长(stride)、数据类型(type)等。
而真正的数据则保存成连续数组,保存在存储区。
x = x.view(x.size(0), -1)
view是一种切片方法。
张量:张量是线性代数中用到的一种数据结构,类似向量和矩阵,你可以在张量上进行算术运算。是向量和矩阵的推广,可以理解为多维数组。
view(-1,x)这里面的x必须是总量能整除的,这种情况下前面的-1是任意值都可以了
在张量间的计算过程中,如果在所有输入中,有一个输入需要求导,那么输出一定会需要求导;相反,只有当所有输入都不需要求导的时候,输出才会不需要。也就是:Tensor变量的requires_grad的属性默认为False,若一个节点requires_grad被设置为True,那么所有依赖它的节点的requires_grad都为True
在写代码的过程中,不要把网络的输入和Ground Truth的requires_grad设置为True。这样会增大计算量和内存占用。
下面将网络参数的requires_grad设置为False
这样训练的过程中部分网络会被冻结,这些层的参数就不会再更新,在迁移学习中很有用。
torch.rand和torch.randn有什么区别? y = torch.rand(5,3) y=torch.randn(5,3)
一个均匀分布,一个是标准正态分布。
x=torch.randn(3,requires_grad=True)
print(x.requires_grad
)# True
print((x**2).requires_grad)
True
with torch.no_grad():
print((x**2).requires_grad)
False
print((x**2).requires_grad)
True
使用with torch.no_grad():可以暂时不追踪网络参数中的倒数,这样可以减少可能存在的计算和内存消耗。
反向传播以及网络的更新
创建一个很简单的网络:两个卷积层,一个全连接层
model = Simple()
为了方便观察数据变化,把所有网络参数都初始化为 0.1
for m in model.parameters():
m.data.fill_(0.1)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1.0)
model.train()
模拟输入8个 sample,每个的大小是 10x10,
值都初始化为1,让每次输出结果都固定,方便观察
images = torch.ones(8, 3, 10, 10)
targets = torch.ones(8, dtype=torch.long)
output = model(images)
print(output.shape)
torch.Size([8, 20])
loss = criterion(output, targets)
print(model.conv1.weight.grad)
None
loss.backward()
print(model.conv1.weight.grad[0][0][0])
tensor([-0.0782, -0.0842, -0.0782])
通过一次反向传播,计算出网络参数的导数,
因为篇幅原因,我们只观察一小部分结果
print(model.conv1.weight[0][0][0])
tensor([0.1000, 0.1000, 0.1000], grad_fn=)
我们知道网络参数的值一开始都初始化为 0.1 的
optimizer.step()
print(model.conv1.weight[0][0][0])
tensor([0.1782, 0.1842, 0.1782], grad_fn=)
回想刚才我们设置 learning rate 为 1,这样,
更新后的结果,正好是 (原始权重 - 求导结果) !
optimizer.zero_grad()
print(model.conv1.weight.grad[0][0][0])
#tensor([0., 0., 0.])
每次更新完权重之后,我们记得要把导数清零啊,
不然下次会得到一个和上次计算一起累加的结果。
当然,zero_grad() 的位置,可以放到前边去,
只要保证在计算导数前,参数的导数是清零的就好
另外,这个时候我们已经把整个网络参数的值都传到optimizer里面了,这种情况下我们屌用model.zero_grad(),效果是和optimizer.zero_grad()一样的,但是更多的是使用optimizer.zero_grad()。
tensor.detach()
a = torch.tensor([7., 0, 0], requires_grad=True)
b = a + 2
print(b)
tensor([9., 2., 2.], grad_fn=)
loss = torch.mean(b * b)
b_ = b.detach()
b_.zero_()
print(b)
tensor([0., 0., 0.], grad_fn=)
储存空间共享,修改 b_ , b 的值也变了
loss.backward()
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
在这个例子中,b是用来计算loss的一个变量,我们在计算完loss之后,进行反向传播之前,修改了b的值。这么做会导致相关的导数的计算结果错误,因为我们在计算导数的过程中还会用到b值,但是它已经变了(和正向传播过程中的值不一样了),发生这种情况的时候,pytorch会选择报错来提醒我们。
CPU and GPU
在进行了tensor.to(device)以后,直接在代码的最后加一句指定device就能直接使用了。
device = torch.device(“cuda”) if torch.cuda.is_available() else torch.device(“cpu”)
a = torch.rand([3,3]).to(device)
干其他的活
b = torch.rand([3,3]).to(device)
关于使用GPU还有一个点,在我们想把GPU tensor转换成Numpy变量的时候,需要先将tensor转换到CPU中去,因为Numpy是CPU-only的。其次,如果tensor需要求导的话,还需要加一步detach,再转换成Numpy。例子如下:
x = torch.rand([3,3], device=‘cuda’)
x_ = x.cpu().numpy()
y = torch.rand([3,3], requires_grad=True, device=‘cuda’).
y_ = y.cpu().detach().numpy()
y_ = y.detach().cpu().numpy() 也可以
二者好像差别不大?我们来比比时间:
start_t = time.time()
for i in range(10000):
y_ = y.cpu().detach().numpy()
print(time.time() - start_t)
1.1049120426177979
start_t = time.time()
for i in range(10000):
y_ = y.detach().cpu().numpy()
print(time.time() - start_t)
1.115112543106079
时间差别不是很大,当然,这个速度差别可能和电脑配置
(比如 GPU 很贵,CPU 却很烂)有关。
进行绝对地址查找 (root=r’D:\python_script\mnist\mnist’)
数据的保存和读取
#只保存和加载模型
torch.save(model.state_dict(),path)
model = TheModelClass(...)
model.load_state_dict(torch.load(path))
#完整的保存和加载模型
torch.save(model,path)
model = torch.load(path)
Checkpoint:检查点用计算换区内存(节省内存)。检查点部分并不保存中间激活值,而是在反向传播时重新计算它们。它可以应用于模型的任何部分
关于模型调优,超参的选择,可以百度先看一下别人怎么调的,都改了什么东西,尽可能地得出一些自己的结论?
答:首先在层数低的时候,比如CNN和lenet中,epoch的仍然具有一定的影响,当网络层数加深以后,epoch的影响变的不是很大,因为网络的loss会出现一定的波动,这个波动在每个epoch之间的差距很容易造成。所以在网络层数加深以后,卷积核的个数,尺寸,步长以及全连接层的参数就变得格外重要。一般情况下,随着卷积核个数(通道深度的加深),计算速度会变的巨慢,精度会相应的提高很多,所以这个平衡需要根据自己电脑的实际计算能力去设置参数。这时候的batch_size和learning_rate调的合适也可以提高训练速度。
模型训练,将所有需要改动的超参写得集中一些,掌握模型的集中保存方式,以及模型Checkpoint, Earlystop, tensorboard, ReduceLROnPlateau
将alex_net的超参数写的集中起来,学习内部的相应步骤关于保存模型的方式没有找到集中的方式,只找到了
只保存和加载模型
torch.save(model.state_dict(),path)
model = TheModelClass(…)
model.load_state_dict(torch.load(path))
完整的保存和模型加载
torch.save(model,path)
model = torch.load(path)
回调函数(callback)是在屌用fit时传入模型的一个对象(即实现特定方法的类实例),它在训练过程中的不同时间点都会被模型调用。它可以访问关于模型状态与性能的所有可用数据,还可以采取行动:中断训练、保存模型、加载一组不同权重或改变模型的状态。
Checkpoint:检查点
主要作用是用计算换内存(节省内存)。检查点部分并不保存中间激活值,而是在反向传播时重新计算它们。它可以应用于模型的任何部分。这是一种用时间换取空间的方法。
解决过拟合问题有两个方向:降低参数空间的维度或者降低每个维度上的有效规模。
降低参数数量的方法包括 greedy constructive learning、剪枝和权重共享等。
降低每个参数维度的有效规模的方法主要是正则化,如权重衰变(weight decay)和早停法(early stopping)等
(是不是可以理解为早停法是正则化方法的一种?)
早停法基本含义是在训练中计算模型在验证集上的表现,当模型在验证集上的表现开始下降的时候,停止训练,这样就能避免继续训练导致过拟合的问题。
主要步骤如下:
1.将原始的训练数据划分成训练集和验证集
2.只在训练集上进行训练,并每隔一个周期计算模型在验证集上的误差,例如,每15个epoch
3.当模型在验证集上的误差比上一次训练结果差的时候停止训练
4.使用上一次迭代结果中的参数作为模型的最终参数
但是模型在验证集上可能会表现为在短暂的变差之后有可能继续变好
第一类停止标准,定义一个新变量叫泛化损失(generalization loss),它描述的是在当前迭代周期t中,![]()
泛化误差相比较目前的最低的误差的一个增长率:

较高的泛化损失显然是停止训练的一个候选标注,因为它直接表明了过拟合。当泛化损失超过一定阈值的时候,停止训练来定义,当大于一定值的时候,停止训练。
第二类停止标准,当训练的速度很快的时候,我们可能希望模型继续训练。因为如果训练错误依然下降很快,那么泛化损失有很大概率被修复。我们通常会假设过拟合只会在训练错误降低很慢的时候出现,定义一个K周期,以及基于周期的一个新变量度量进展。
(此处本应有公式,但是这个公式我没有办法复述,在努力的找)
它表的含义是当前的指定迭代周期的内平均训练错误比该期间最小的训练错误大多少。
需要注意的是,当训练过程边的不稳定的时候,这个measure progress结果可能很大,其中训练错误会变大而不是变小。实际上,很多算法都由于选择了不适当的较大的步长而导致这样的抖动,除非全局都不稳定,否则在较长的训练之后,measure progress结果趋向于0。由此,我们引入了第二个停止标准,即泛化损失和进展熵,大于指定值的时候停止。
第三类停止标准,完全依赖于泛化错误的变化,即当泛化错误在连续s个周期内增长的时候停止(up)
当验证集错误在连续s个周期内都出现增长的时候,我们假设这样的现象表明了过拟合,它与错误增长了多大是相互独立的。这个停止标准可以度量局部的变化,因此可以用在剪枝算法中,即在训练阶段,允许误差可以比前面最小值高很多时候保留。
tensorBoard是一个可视化工具
它可以用来展示网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,我们可以设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),使用tensorBoard可以很直观的帮我们进行参数的选择
目前有几种流行的方法尝试着将tensorboard可视化移植到他们所使用的框架中来
Crayon是一个支持任何语言使用的tensorboard框架(目前支持python和lua,并且安装过程十分繁琐,不推荐此方法)
使用tensorboard_logger实现tensorboard可视化
Tensorboard_logger是由TeamHG-Memex开发的使用tensorboard的库,可以访问文档界面,安装略有繁琐,需要安装tensorflow和他们开发的tensorboard_logger
导入一个脚本实现tensorboard可视化
只需要安装cpu版本的tensorflow,通过pip install tensorflow就能够快速安装,然后只需要复制这个网址里面的代码到你的项目文件目录,新建一个logger.py的文件,将代码复制进去就OK。 然后在python文件里面输入from logger import Logger,在训练之前定义好乡村方tensorboard文件的文件夹,logger = Logger(‘./logs’)这里可以使用任何文件夹存放tensorboard文件。
!!我查到的都是需要先安装tensorflow然后在下载log!!
ReduceLROnPlateau 回调函数
在训练过程中如果出现了损失平台(loss plateau),即损失率不怎么变化时,改变学习率。
这里找到的是一个keras的程序
#这里找到的是一个keras的程序
callbacks_list = [
keras.callbacks.ReduceLROnPlateau(
monitor='val_loss', #←------ 监控模型的验证损失
factor=0.1, #←------ 触发时将学习率除以10
patience=10 #←------ 如果验证损失在10轮内都没有改善,那么就触发这个回调函数
)
]
mnist_CNN
import torch
import torchvision
import torch.utils.data as Data
from CNN import CNN
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
# class torch.nn.Conv2d(in_channels, out_channels,kernel_size, stride=1,padiding=0,dilation=1, groups=1,bias=True)
# in_channels:在文本应用中,即为词向量的维度。
# out_channels:卷积产生的通道数,有多少个out_channels,就需要多少个一维卷积(也就是卷积核的数量)
# kernel_size:卷积核的尺寸;卷积核的第二个维度由in_channels决定,所以实际上卷积核的大小为:kernel_size*in_channels
# padding:对输入的每一条边,补充0的层数。
# conv1输入通道数为1,输出通道数为16
self.conv1 = nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2)# 通常认为3是最好的,3*3最好
self.maxpool1 = nn.MaxPool2d(2,2)
# conv2输入通道数为16,输出通道数为32
self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2)
self.maxpool2 = nn.MaxPool2d(2,2)
self.fc1 = nn.Linear(32*7*7, 10)
def forward(self, x):
# 输入x -> conv1 -> relu -> 2×2窗口的最大池化
x = F.relu(self.conv1(x))
x = self.maxpool1(x)
# 输入x -> conv2 -> relu -> 2×2窗口的最大池化
x = F.relu(self.conv2(x))
x = self.maxpool2(x)
# view函数将张量x变形成一维向量形式,总特征数不变,为全连接层做准备
x = x.view(x.size(0), -1)
x = self.fc1(x)
return x
# 进行数据初始化,在download=True时,如果没有手写数字体的数据集的话会自动从网上download。
DOWNLOAD = True
if __name__ =='__main__':
# 定义训练集的路径,如果没有数据集的话就会自动下载。
train_data=torchvision.datasets.MNIST(
root='./mnist',
train=True,
# transform=torchvision.transforms.ToTensor():
# Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
transform=torchvision.transforms.ToTensor(),
download=DOWNLOAD,
)
cnn = CNN()
# 将需要训练的数据集导入,batch_size定义:一次训练所选取的样本数
# Batch Size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况。
# 通过并行化提高内存的利用率。就是尽量让你的GPU满载运行,提高训练速度。
# 没有batch_size的时候,梯度准确,只适用于小样本数据库。
# batch_size,梯度变来变去,非常不准确,网络很难收敛。
# batch_size增大,梯度变准确。
# batch_size增大,梯度已经非常准确,再增加batch_size也没有用。
# batch_size增大以后,要想达到相同的准确度,必须要增加epoch。
# shuffle函数的意义就是将序列的所有元素随机排列。
train_loader = Data.DataLoader(dataset=train_data, batch_size=5, shuffle=True)# 在修改的时候最好改batch_size 2的平方次
test_data = torchvision.datasets.MNIST(root='./mnist/',train=False)
# unsqueeze()函数会增加一个维度
# 取了测试集数据来验证是否已经训练好了。
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000] / 255.
test_y = test_data.test_labels[:2000]
# 来看看计算机是否有cuda,用以加速计算
have_cuda = torch.cuda.is_available()
if have_cuda:
cnn.cuda()
test_x = test_x.cuda()
# 优化所有的cnn参数,learning_rate=0.001
optimizer = torch.optim.Adam(cnn.parameters(), lr=0.001)
# 计算交叉熵
loss_func = torch.nn.CrossEntropyLoss()
# 进行训练和测试,进行一个epoch
for epoch in range(1):
for step, (b_x, b_y) in enumerate(train_loader):
if have_cuda:
b_x = b_x.cuda()
b_y = b_y.cuda()
output = cnn(b_x) # cnn的输出
loss = loss_func(output, b_y) # 交叉熵损失
optimizer.zero_grad() # 清除梯度
loss.backward() # 反向传播,计算梯度
optimizer.step() # 应用梯度
if step % 500 == 0:
test_output = cnn(test_x) # 将测试集的数据进行cnn输出
pred_y = torch.max(test_output.cpu(), 1)[1].data.numpy()#把数据传入GPU计算
# float的作用是将证书和字符串转换成浮点数
# accuracy计算的是测试集数据总和除以label标答的结果。
accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
# %.4f是保留四位小数点,%.2f是保留两位小数。
print('step is: ',step)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.cpu().numpy(),
'| test accuracy: %.2f' % accuracy)
#最后打印10个测试集的数据进行验证。
test_output = cnn(test_x[:10])
pred_y = torch.max(test_output.cpu(), 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')
这个网络只有两层卷积层和一层全连接层,层数较少。
在调整参数的时候,随着网络层数增加,epoch和learning rate的影响越来越小,所以需要调整的参数有,卷积核的个数,卷积核的尺寸,步长,零填充padding的大小。
mnist_LeNet
import torch
import torchvision as tv
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
import argparse
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义网络结构
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# class torch.nn.Conv2d(in_channels, out_channels,kernel_size, stride=1,padiding=0,dilation=1, groups=1,bias=True)
# in_channels:在文本应用中,即为词向量的维度。
# out_channels:卷积产生的通道数,有多少个out_channels,就需要多少个一维卷积(也就是卷积核的数量)
# kernel_size:卷积核的尺寸;卷积核的第二个维度由in_channels决定,所以实际上卷积核的大小为:kernel_size*in_channels
# padding:对输入的每一条边,补充0的层数。
# conv1输入通道数为1,输出通道数为16
self.conv1 = nn.Sequential( # input_size=(1*28*28)
nn.Conv2d(1, 64, 3, 1, 1), # padding=2保证输入输出尺寸相同
nn.ReLU(), # input_size=(64*28*28)
nn.MaxPool2d(kernel_size=2, stride=2)# output_size=(64*14*14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 128, 3,1, 1),# 如果不输入padding的话padding=0.
nn.ReLU(), #input_size=(128*14*14)
nn.MaxPool2d(2, 2) #output_size=(128*7*7)
)
# 三个全连接层,输出成一维向量
self.fc1 = nn.Sequential(
nn.Linear(128*7*7, 512),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(512, 1024),
nn.ReLU()
)
self.fc3 = nn.Linear(1024, 10)
# 定义前向传播过程,输入为x
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# nn.Linear()的输入输出都是维度为一的值,所以要把多维度的tensor展平成一维
x = x.view(x.size(0), -1) #将128*7*7展开成6272
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
#使得我们能够手动输入命令行参数,就是让风格变得和Linux命令行差不多
parser = argparse.ArgumentParser()
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints') #模型保存路径
parser.add_argument('--net', default='./model/net.pth', help="path to netG (to continue training)") #模型加载路径
opt = parser.parse_args()
# 超参数设置
EPOCH = 8 #遍历数据集次数
BATCH_SIZE = 64 #批处理尺寸(batch_size)
LR = 0.001 #学习率
# 定义数据预处理方式
transform = transforms.ToTensor()
# 定义训练数据集
trainset = tv.datasets.MNIST(
root='./mnist/',
train=True,
download=True,
transform=transform)
# 定义训练批处理数据
trainloader = torch.utils.data.DataLoader(
trainset,
batch_size=BATCH_SIZE,
shuffle=True,
)
# 定义测试数据集
testset = tv.datasets.MNIST(
root='./mnist/',
train=True,
download=True,
transform=transform)
# 定义测试批处理数据
testloader = torch.utils.data.DataLoader(
testset,
batch_size=BATCH_SIZE,
shuffle=False,
)
# 定义损失函数loss function 和优化方式(采用SGD)
net = LeNet().to(device)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,通常用于多分类问题上
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9)
# 训练
if __name__ == "__main__":
print('Start!')
for epoch in range(EPOCH):
sum_loss = 0.0
# 数据读取
for i, data in enumerate(trainloader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# 梯度清零
optimizer.zero_grad()
# forward + backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 每训练100个batch打印一次平均loss
#sum_loss += loss.item()
#if i % 100 == 99:
#print('[%d, %d] loss: %.03f'
#% (epoch + 1, i + 1, sum_loss / 1000))
#sum_loss = 0.0
# 每跑完一次epoch测试一下准确率
with torch.no_grad():
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
# 取得分最高的那个类
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('第%d个epoch的识别准确率为:%d%%' % (epoch + 1, (100 * correct / total)))
mnist_AlexNet
下面是AlexNet对mnist进行的学习代码
AlexNet一共有8层网络 ,5层卷积层,3层池化层,3层全连接层。
#AlexNet & MNIST
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torch.nn.functional as F
import time
cfg = {
'Alex':[64,'M',128,'M',256,512,1024,'M',],
'FC': [1024*3*3,4096,2048,1024,10]
}
num_epochs = 20 #训练次数
running_loss_first = 0
batch_size_first = 100
#定义网络结构
class FlattenLayer(torch.nn.Module):
def __init__(self):
super(FlattenLayer,self).__init__()
def forward(self,x):
return x.view(x.shape[0],-1)
class AlexNet(nn.Module):
def __init__(self,Alex_name):
super(AlexNet,self).__init__()
self.alex_layer = self.alex_block(cfg[Alex_name]) #AlexCONV1(3,96, k=11,s=4,p=0)
self.FC_layer = self.fc_block(cfg['FC'])
def forward(self,x):
out_alex = self.alex_layer(x)
out = out_alex.view(out_alex.size(0),-1)
out = self.FC_layer(out_alex)
return out
def alex_block(self,cfg_alex):
layers = []
in_channels = 1
for out_channels in cfg_alex:
if out_channels == 'M':
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
else:
layers.append(nn.Conv2d(in_channels,out_channels,kernel_size=5,padding=2,bias=False))
layers.append(nn.BatchNorm2d(out_channels))
layers.append(nn.ReLU(inplace=True))
in_channels = out_channels
return nn.Sequential(*layers)
def fc_block(self,cfg_fc):
fc_net = nn.Sequential()
fc_features, fc_hidden_units, fc_output_units = cfg_fc[0:3]
fc_net.add_module("fc", nn.Sequential(
FlattenLayer(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_output_units)
))
return fc_net
#transform
transform = transforms.Compose([ #这主要是串联多个图片变换的操作
transforms.RandomHorizontalFlip(),# 功能:依据概率p对PIL图片进行水平翻转,其中p为概率,默认值为0.5
# PIL是python第三方图像处理库,但是由于他强大的功能和众多的使用人数,已经被默认为python的官方图像处理库了。
# PIL非常适合于图像归档以及图像的批处理任务
transforms.RandomGrayscale(), # 功能:将图片转为灰度图
transforms.ToTensor(), # 功能:将PIL Image或者 ndarray 转换为tensor,并且归一化至[0-1]
])
transform1 = transforms.Compose([
transforms.ToTensor()
])
# 加载数据
trainset = torchvision.datasets.MNIST(root='./mnist',train=True,download=True,transform=transform)# 在这里可以使用绝对地址进行操作
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100,shuffle=True,num_workers=0)# shuffle是将序列的所有元素重新随机排序
# windows下num_workers设置为0,不然有bug
testset = torchvision.datasets.MNIST(root='./mnist',train=False,download=True,transform=transform1)
testloader = torch.utils.data.DataLoader(testset,batch_size=100,shuffle=False,num_workers=0)
#net
net = AlexNet('Alex')
#损失函数:这里用交叉熵
criterion = nn.CrossEntropyLoss()
#优化器 这里用SGD
optimizer = optim.SGD(net.parameters(),lr=1e-3, momentum=0.9)
#device : GPU or CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
print("Start Training!")
for epoch in range(num_epochs):
running_loss = running_loss_first
batch_size = batch_size_first
for i, data in enumerate(trainloader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('[%d, %5d] loss:%.4f'%(epoch+1, (i+1)*100, loss.item()))
print("Finished Traning")
#保存训练模型
torch.save(net, 'MNIST.pkl')
net = torch.load('MNIST.pkl')
#开始识别
with torch.no_grad():
#在接下来的代码中,所有Tensor的requires_grad都会被设置为False
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
out = net(images)
_, predicted = torch.max(out.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images:{}%'.format(100 * correct / total)) #输出识别准确率
mnist_VGG
下图为VGGNet系列模型的结构
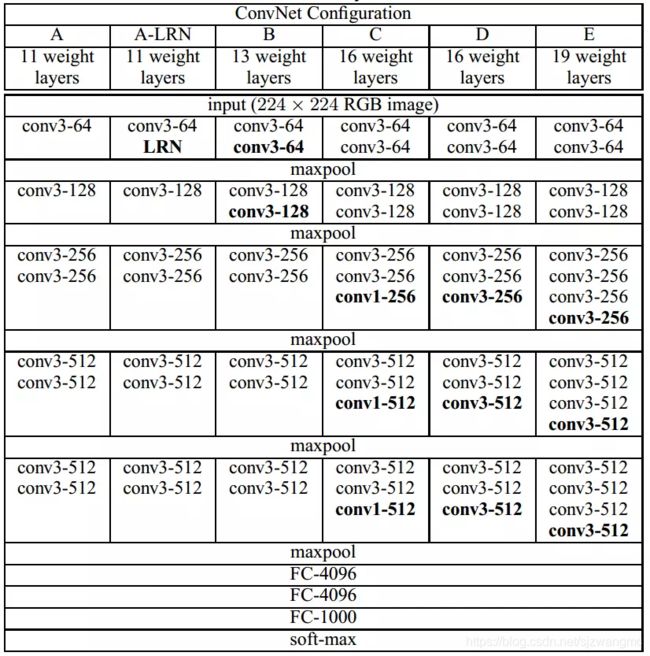
下图为参数个数比较
A和A-LRN的比较,只有一个LRN的差异,在经过多次训练比较发现,LRN增加了复杂度,损耗内存,存在的意义不是很大。
B与C相比较多使用了几个1×1的卷积层,在输入输出维度不变的情况下,增加非线性变换,提高网络的表达能力。
C和D相比较还是C的特征提取会更好一些,虽然1×1的卷积很好很有效,但是相比较于3×3的,还是3×3的更好一些。
其他的几个相比较,模型越来越深。
可训练参数的个数相差不大。
VGG对于AlexNet的优势
1.通过重复使用简单的Block块来构建深度模型
2,使用了更多小的卷积核
3.小池化核。AlexNet的3×3的池化核,VGG全部为2×2的池化核
4.模型深度更深,表达能力更强
5.由于使用更小的卷积核来构建和构建更深的网络,由多个小的卷积核堆叠来增大accept field(3个33的卷积核的堆叠accept field和77的accept field一样大小)
6.由于使用小的卷积核,降低了可训练参数个数,并增加了更多的分线性变化,提高了对特征的学习能力。(这里涉及到了一个词:感受野,两个33卷积核叠加就可以得到55的感受野大小。)
下面是accept field示意图: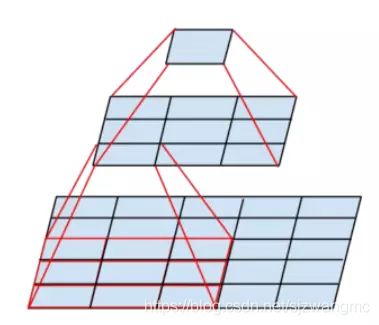
import torch
import time
from torch import nn, optim
import torchvision
import sys
#定义VGG各种不同的结构和最后的全连接层结构
cfg = {
'VGG11': [64, 'M', 128, 'M', 256,'M', 512, 'M', 512,'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [8, 8, 'M', 16, 16, 'M', 32, 32, 32, 'M', 64, 64, 64, 'M', 64, 64, 64, 'M'],
'VGG19': [8, 8, 'M', 16, 16, 'M', 32, 32, 32, 32, 'M', 64, 64, 64, 64, 'M', 64, 64, 64, 64, 'M'],
'FC': [64*7*7, 256, 10]
}
#将数据展开成二维数据,用在全连接层之前和卷积层之后
class FlattenLayer(torch.nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x shape: (batch, *, *, ...)
return x.view(x.shape[0], -1)
class VGG(nn.Module):
# nn.Module是一个特殊的nn模块,加载nn.Module,这是为了继承父类
def __init__(self, vgg_name):
super(VGG, self).__init__()
# super 加载父类中的__init__()函数
self.VGG_layer = self.vgg_block(cfg[vgg_name])
self.FC_layer = self.fc_block(cfg['FC'])
#前向传播算法
def forward(self, x):
out_vgg = self.VGG_layer(x)
out = out_vgg.view(out_vgg.size(0), -1)
# 这一步将out拉成out.size(0)的一维向量
out = self.FC_layer(out_vgg)
return out
#VGG模块
def vgg_block(self, cfg_vgg):
layers = []
in_channels = 1
for out_channels in cfg_vgg:
if out_channels == 'M':
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
else:
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3,padding=1, bias=False))
layers.append(nn.BatchNorm2d(out_channels))
layers.append(nn.ReLU(inplace=True))
in_channels = out_channels
return nn.Sequential(*layers)
#全连接模块
def fc_block(self, cfg_fc):
fc_net = nn.Sequential()
fc_features, fc_hidden_units, fc_output_units = cfg_fc[0:]
fc_net.add_module("fc", nn.Sequential(
FlattenLayer(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_output_units)
))
return fc_net
#加载MNIST数据,返回训练数据集和测试数据集
def load_data_fashion_mnist(batch_size, resize=None, root=r'D:\python_script\mnist\mnist'):
"""Download the fashion mnist dataset and then load into memory."""
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.MNIST(root=r'D:\python_script\mnist\mnist', train=True, download=False, transform=transform)
mnist_test = torchvision.datasets.MNIST(root=r'D:\python_script\mnist\mnist', train=True, download=False, transform=transform)
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
return train_iter, test_iter
#测试准确率
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
else: # 自定义的模型, 3.13节之后不会用到, 不考虑GPU
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
#模型训练,定义损失函数、优化函数
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
loss = torch.nn.CrossEntropyLoss()
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
def main():
net = VGG('VGG19')
print(net)
#一个batch_size为64张图片,进行梯度下降更新参数
batch_size = 64
#使用cuda来训练
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#加载MNIST数据集,返回训练集和测试集
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=224)
lr, num_epochs = 0.001, 5
#使用Adam优化算法替代传统的SGD,能够自适应学习率
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
#训练--迭代更新参数
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
main()
mnist_resnet50
# -*- coding: utf-8 -*-
"""Untitled7.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1qXioS5zHfba9vM-FbB-zBuprV5mZBf21
"""
import torch
from torch.utils.data import DataLoader, sampler
from torchvision.datasets import MNIST
import torch.optim
from torch import nn
from torchvision import transforms
import matplotlib.pyplot as plt
transformations = transforms.Compose([ transforms.ToTensor(),transforms.Normalize(mean =(0.1307, ) , std = (0.3081,))])
data = MNIST( r"D:\python_script\mnist\mnist\MNIST", train = True,download = True, transform= transformations )
# mean =(0.1307, ) and std = (0.3081,) are taken from net
#but a small snippet of simple code can be used to find mean and Standard deviation to standardize the inputs of MNIST data
train_loader = DataLoader(data, batch_size = 2)
data = MNIST( r"D:\python_script\mnist\mnist\MNIST", train = False,download = True, transform= transformations )
test_loader = DataLoader(data, batch_size = 2 )
class identity_block (nn.Module): #identity block is such that it maintains the number of channels and
#keep the channel number of output and x same
def __init__(self, channels_in, filters, f= 1): #input pixel size of image and is one of the standard
super().__init__() #it is defined with inheritence of nn.Module so as to make
# it usable inside nn.Sequential.
c1,c2,c3 = filters #blocks of Resnet architechture
self.model0 = nn.Sequential( nn.Conv2d(channels_in, c1, kernel_size=(1,1),stride = (1,1) ),
nn.BatchNorm2d(c1, momentum = None, affine = False),
nn.LeakyReLU(),
nn.Conv2d( c1 ,c2, kernel_size=(f,f),stride = (1,1), padding = (int((f-1)/2),int((f-1)/2))),
nn.BatchNorm2d(c2, momentum = None, affine = False),
nn.LeakyReLU(),
nn.Conv2d(c2,c3, kernel_size=(1,1),stride = (1,1) ),
nn.BatchNorm2d(c3, momentum = None, affine = False))
for i in self.model0:
if list(i.parameters()).__len__()>0:
i.parameters = [ nn.init.xavier_uniform_(j) for j in list( i.weight)]
def forward( self,img):
z = self.model0(img) + img
out = nn.LeakyReLU()
return out(z)
class convolutional_block (nn.Module): #similar to identity block and is the other important block in Resnet
#but changes the pixel size from first sub-block and channel number
def __init__( self, channels_in,filters, s= 1, f= 1): #changes though out
super().__init__()
c1,c2,c3 = filters
self.model0 = nn.Sequential( nn.Conv2d(channels_in, c1, kernel_size=(1,1), stride = (s,s) ),
nn.BatchNorm2d(c1, momentum = None, affine = False),
nn.LeakyReLU(), #uptohere sub-block-1
nn.Conv2d( c1 ,c2, kernel_size =(f,f),stride = (1,1 ), padding =( int( (f-1)/2),int((f-1)/2))),
nn.BatchNorm2d(c2, momentum = None, affine = False),
nn.LeakyReLU(), #uptohere sub-block-2
nn.Conv2d( c2,c3, kernel_size=(1,1),stride = (1,1) ),
nn.BatchNorm2d(c3, momentum = None, affine = False) #uptohere sub-block-3
)
self.model1 = nn.Sequential( nn.Conv2d(channels_in, c3, kernel_size=(1,1),stride = (s,s) ),
nn.BatchNorm2d(c3, momentum = None, affine = False) ) #to make number of channels and pixel
#size of input equal to output
#of model before adding to it
for i in self.model0:
if list(i.parameters()).__len__()>0:
i.parameters = [ nn.init.xavier_uniform_(j) for j in list( i.weight)]
for i in self.model1:
if list(i.parameters()).__len__()>0:
i.parameters = [ nn.init.xavier_uniform_(j) for j in list( i.weight)]
#keep the channel number of output and x same
def forward(self, img):
final_model = nn.LeakyReLU()
x = self.model0(img)
y = self.model1(img)
return final_model( x+y )
class flatten(nn.Module): #defined under nn.Module to serve purpose describes above
def forward( self, x ):
a,b,c,d = x.shape
return x.view( a,-1 )
#final model assembling
class Resnet( nn.Module):
def __init__(self, lr_ = 0.01):
super().__init__()
self.device = torch.device( "cuda" if torch.cuda.is_available() else "cpu" )
self.model = nn.Sequential (nn.ConstantPad2d( 3,0 ),
nn.Conv2d(1,64, (2, 2), stride = (2, 2)),
nn.BatchNorm2d( 64, affine = False, momentum= None),
nn.ReLU(),
convolutional_block( 64,filters = [64, 64, 256] , f = 3, s = 1),
identity_block(256,f= 3, filters = [64, 64, 256]),
identity_block(256, f = 3, filters = [64, 64, 256]),
convolutional_block(256,f = 3, filters = [128,128, 512], s = 2),
identity_block( 512,f = 3, filters = [128,128, 512]),
identity_block(512, f = 3, filters = [128,128, 512]),
identity_block(512, f = 3, filters = [128,128, 512]),
convolutional_block(512,f = 3, filters = [256,256, 1024], s = 2),
identity_block( 1024,f = 3, filters = [256,256, 1024]),
identity_block( 1024,f = 3, filters = [256,256, 1024]),
identity_block(1024, f = 3, filters = [256,256, 1024]),
convolutional_block(1024,f = 3, filters = [512,512, 2048], s = 2),
identity_block( 2048,f = 3, filters = [512,512, 2048]),
identity_block( 2048,f = 3, filters = [512,512, 2048]),
identity_block(2048, f = 3, filters = [512,512, 2048]),
convolutional_block(2048,f = 3, filters = [1024,1024,4*1024], s = 2),
identity_block( 4096,f = 3, filters = [1024,1024,4*1024]),
identity_block( 4096,f = 3, filters = [1024,1024,4*1024]),
identity_block(4096, f = 3, filters = [1024,1024,4*1024]),
convolutional_block(2*2048,f = 3, filters = [2*1024,2*1024,2*4*1024], s = 2),
identity_block( 2*4096,f = 3, filters = [2*1024,2*1024,2*4*1024]),
identity_block( 2*4096,f = 3, filters = [2*1024,2*1024,2*4*1024]),
identity_block(2*4096, f = 3, filters = [2*1024,2*1024,2*4*1024]),
flatten(),
nn.Linear(8192, 100 ),
nn.BatchNorm1d( 100 ),
nn.ReLU(),
nn.Linear(100,10),
nn.Softmax() )
self.optimizer = torch.optim.Adam(self.model.parameters(), lr = lr_)
self.criterion = nn.NLLLoss()
def forward(self, images):
x, y = torch.max(self.model(images),1)
return x,y
def train( self, train_loader, epochs):
self.model.to( self.device )
losses = []
for epoch in range(epochs):
print(epoch)
for images, labels in train_loader:
images = images.to( self.device)
labels = labels.to( self.device )
self.optimizer.zero_grad()
out = self.model(images)
loss = self.criterion ( out, labels)
loss.backward()
self.optimizer.step()
losses.append(loss)
return losses
#oops here i made a mistake of not loading data to cuda as it was done with train data
#during prediction making to check accuracy
def predict( self, data_loader):
total_correct = 0
with torch.no_grad():
for inputs,label in data_loader:
inputs, labels = inputs.to( self.device), labels.to( self.device)
out = self.model(inputs)
_,pred = torch.max(out,1)
correct = pred.eq( label).sum()
total_correct += correct
return total_correct/len(data_loader)
model = Resnet(0.01)
a = model.train(train_loader, 5)
plt.plot(a)
def prediction( self, data_loader):
total_correct = 0
total_examples = 0
with torch.no_grad():
for inputs,label in data_loader:
examples, channels,_,g = inputs.shape
inputs, label = inputs.to( self.device), label.to( self.device)
out = self.model(inputs)
_,pred = torch.max(out,1)
correct = pred.eq( label).sum()
total_correct += correct
total_examples += examples
return total_correct.item()/total_examples
#so here i changed the definition of model's prediction function without disturbing the learned parameters of trained model
#also i did not correct it as it might prove useful to many readers of this notebook
model.predict = prediction.__get__( model, Resnet)
model.predict(train_loader)
softmax较为通俗的讲解