数据挖掘实验三:极限学习机(python实现)
目录
- 实验内容
-
- 实验背景介绍
- 输入输出及具体要求
- 训练及测试数据
- 源程序
-
- matrix.py用于自定义矩阵
- model.py用于训练模型
- use_model.py用于使用模型,进行预测
实验内容
实验背景介绍
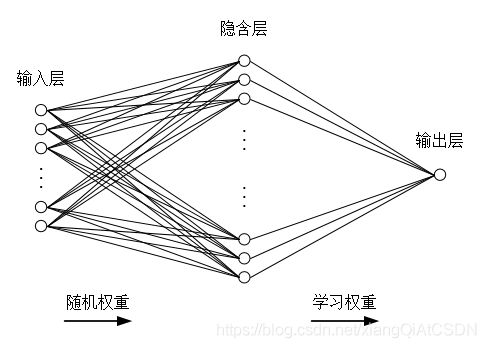
相比较其他传统的神经元网络算法,极限学习机基于单隐层前馈神经网络,具有速度快、易于实现、泛化能力强等优势。对于任意输入集合,随机设定输入层结点到隐含层的权重值以及隐含层偏差后,具有h个隐含层结点的单隐层前馈神经网络几乎能以任意区间、无限可导的非零激活函数,逼近任何一个连续的函数。极限学习机工作结构如图1所示。
激活函数可以是任意无限可到、值域在(0,1)之中的函数,如图2所示。
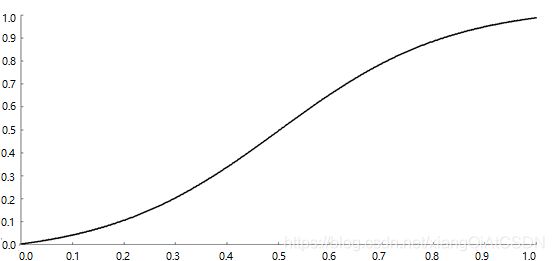
图2 极限学习机的一种激活函数
我们这里把这个激活函数固定下来,如下所示。
g ( z ) = 1 1 + e − z g(z) = \frac{1}{1+e^{-z}} g(z)=1+e−z1
图1中,输入层和隐含层之间有权重;隐含层和输出层之间也有权重。但是,输入层和隐含层之间的权重可以随机设定,包括截距!这是极限学习机和普通的神经元网络最大的不同之处。
假设一共有n行输入,而隐含层的节点数量(是输入变量数量的2~3倍左右)有h个,根据已经设定的权重,我们会有:
( H i , 1 , H i , 2 , . . . . . . , H i , Q i ) , i = 1 , 2 , . . . , n (H_{i,1},H_{i,2},......,H_i,Q_i), i = 1,2,...,n (Hi,1,Hi,2,......,Hi,Qi),i=1,2,...,n
对于数据集中的第i个输入,Hi,j是各个隐含节点的输出, Qi是第i个真实输出值。注意,所有输入节点汇聚到一个节点之后,除了乘以加权系数之外,还要有一个截距。
假设隐含节点的各个输出到最终输出之间的连接权重是wj, j=1, 2, …, h,则我们要求得一组w,使得下式取得最小值:
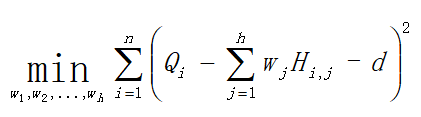
求解这一最小值问题,恰好就是最小二乘法的功能。其中d是截距。求解这一问题的解法是:
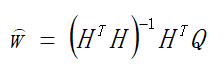
式(4)中的H要比(3)中的H多一个变量d。
输入输出及具体要求
建立极限学习机之后,对附件中训练数据进行训练,获得极限学习机的网络结构和模型,然后对预测数据进行预测。
预测数据一共10条,通过预测,会得到10个预测结果,这些结果要用文本的形式在一行中显示。为了和真实结果进行对比,不能用图片的形式显示预测结果。
实验报告中要有训练数据的模型结果和真实结果差的平方的平均值,然后求平方根之后的结果。
训练及测试数据
太多了,自己编吧,老师给的数据7个属性1个标签
源程序
matrix.py用于自定义矩阵
class MyMatrix(object):
def __init__(self, row, column, value=0):
self.row = row
self.column = column
if value == 0:
self._matrix = [0.0 for i in range(row * column)]
else:
assert len(value) == row * column, '赋值数量不匹配'
self._matrix = list(value)
# 重写中括号引用
def __getitem__(self, index):
if isinstance(index, int):
assert index <= self.row, str(index) + ' ' + str(self.row) + ' index超了'
row = []
for i in range(self.column):
row.append(self._matrix[self.column * (index - 1) + i])
return row
elif isinstance(index, tuple):
assert index[0] <= self.row and index[1] <= self.column, str(index[0]) + ' ' + str(self.row) + ' ' + str(
index[1]) + ' ' + str(self.column) + ' index超了'
return self._matrix[self.column * (index[0] - 1) + index[1] - 1]
# m[i, 0] ~ m[i, j] = value,给矩阵第i行赋值,list或tuple
# m[i, j] = value
def __setitem__(self, index, value):
if isinstance(index, int):
assert index <= self.row, str(index) + ' ' + str(self.row) + ' index超了'
for i in range(self.column):
self._matrix[self.column * (index - 1) + i] = value[i]
elif isinstance(index, tuple):
assert index[0] <= self.row and index[1] <= self.column, str(index[0]) + ' ' + str(self.row) + ' ' + str(
index[1]) + ' ' + str(self.column) + ' index超了'
self._matrix[self.column * (index[0] - 1) + index[1] - 1] = value
# A * B (A * 2.0)
def __mul__(A, B):
# 矩阵乘以一个数
if isinstance(B, int) or isinstance(B, float):
temp = MyMatrix(A.row, A.column)
for r in range(1, A.row + 1):
for c in range(1, A.column + 1):
temp[r, c] = A[r, c] * B
else:
# 矩阵乘以矩阵
assert A.column == B.row, str(A.row) + str(A.column) + str(B.row) + str(B.column) + '维度不匹配,不能相乘'
temp = MyMatrix(A.row, B.column)
for r in range(1, A.row + 1):
for c in range(1, B.column + 1):
sum = 0
for k in range(1, A.column + 1):
sum += A[r, k] * B[k, c]
temp[r, c] = sum
return temp
# A + B
def __add__(A, B):
assert A.row == B.row and A.column == B.column, str(A.row) + str(A.column) + str(B.row) + str(
B.column) + '维度不匹配,不能相加'
temp = MyMatrix(A.row, A.column)
for r in range(1, A.row + 1):
for c in range(1, A.column + 1):
temp[r, c] = A[r, c] + B[r, c]
return temp
# print(M)
def __str__(self):
out = ""
for r in range(1, self.row + 1):
for c in range(1, self.column + 1):
out = out + str(self[r, c]) + ' '
out += "\n"
return out
# A(T),求矩阵的转置
def transpose(self):
trans = MyMatrix(self.column, self.row)
for r in range(1, 1 + self.column):
for c in range(1, 1 + self.row):
trans[r, c] = self[c, r]
return trans
# 求逆
def invert(self):
# assert self.row == self.column, "不是方阵"
inv2 = MyMatrix(self.row, self.column * 2)
# 构造 n * 2n 的矩阵
for r in range(1, 1 + inv2.row):
doub = self[r]
for i in range(1, 1 + inv2.row):
if i == r:
doub.append(1)
else:
doub.append(0)
inv2[r] = doub
# 初等行变换
for r in range(1, inv2.row + 1):
# 判断矩阵是否可逆
if inv2[r, r] == 0:
for rr in range(r + 1, inv2.row + 1):
if inv2[rr, r] != 0:
inv2[r], inv2[rr] = inv2[rr], inv2[r]
break
# assert inv2[r, r] != 0, '矩阵不可逆'
temp = inv2[r, r]
for c in range(r, inv2.column + 1):
inv2[r, c] /= temp
for rr in range(1, inv2.row + 1):
temp = inv2[rr, r]
for c in range(r, inv2.column + 1):
if rr == r:
continue
inv2[rr, c] -= temp * inv2[r, c]
inv = MyMatrix(inv2.row, inv2.row)
for i in range(1, 1 + inv.row):
doub = inv2[i]
inv[i] = doub[inv.row:]
return inv
model.py用于训练模型
from matrix import MyMatrix
import math
import random
# 最小二乘法
def least_square_method(H, Q):
return (H.transpose() * H).invert() * H.transpose() * Q
class ELM(object):
def __init__(self, inputSize, outputSize, bit):
self.inputSize = inputSize
self.outputSize = outputSize
# hiddensize取变量的2~3倍
self.hiddenSize = bit * 2
self.bit = bit
self.H = 0
self.w = 0
# 随机出bit * hiddensize的weight权重
ran = [random.uniform(-0.2, 0.2) for i in range(self.bit * self.hiddenSize)]
self.weight = MyMatrix(self.bit, self.hiddenSize, ran)
# 随机出hiddensize * 1的bias截距
ran = [random.uniform(0, 1) for i in range(self.hiddenSize)]
self.bias = MyMatrix(self.hiddenSize, 1, ran)
# 实验要求中指定的函数
def sigmoid(self, x):
return 1 / (1 + math.e ** (x * -1))
def train(self, X, Q):
# 隐含层输出H inputsize * hiddensize
self.H = X * self.weight
# 激活函数,H仍然是inputsize * hiddensize
for r in range(1, 1 + self.H.row):
for c in range(1, 1 + self.H.column):
self.H[r, c] = self.sigmoid(self.H[r, c] + self.bias[c, 1])
# 最小二乘法求w
self.w = least_square_method(self.H, Q)
# 返回
return self.H * self.w
def predict(self, X):
# 隐含层输出
self.H = X * self.weight
# 激活函数
for r in range(1, 1 + self.H.row):
for c in range(1, 1 + self.H.column):
self.H[r, c] = self.sigmoid(self.H[r, c] + self.bias[c, 1])
return self.H * self.w
use_model.py用于使用模型,进行预测
import numpy as np
from model import ELM
from matrix import MyMatrix
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 矩阵格式变成我们自定义的矩阵类
def reshapeX(row, column, ij):
li = []
for i in ij:
for j in i:
li.append(float(j))
return MyMatrix(int(row), int(column), li)
# 矩阵格式变成我们自定义的矩阵类
def reshapeY(row, ij):
li = []
for i in ij:
li.append(float(i))
return MyMatrix(int(row), 1, li)
if __name__ == '__main__':
# 从train.txt读数据到X_train,Y_train
X_train = []
Y_train0 = []
file = open('train.txt', 'r')
while True:
line = file.readline()
if line:
# 去掉空格
line.replace(" ", "")
# 分隔
temp_x = line.split(',')
temp_x2 = []
for i in temp_x:
temp_x2.append(float(i))
X_train.append(temp_x2[:-1])
Y_train0.append(temp_x2[-1])
else:
break
file.close()
# print(X_train)
# print(Y_train)
# 从predict.txt读数据到X_test
X_test = []
file = open('predict.txt', 'r')
while True:
line = file.readline()
if line:
# 去掉空格
line.replace(" ", "")
# 分隔
temp_pre_x = line.split(',')
temp_pre_x2 = []
for i in temp_pre_x:
temp_pre_x2.append(float(i))
X_test.append(temp_pre_x2)
else:
break
file.close()
# print(X_test)
# 输入7,输出1
elm = ELM(7, 1, 7)
X_train = reshapeX(len(X_train), len(X_train[0]), X_train)
X_test = reshapeX(len(X_test), len(X_test[0]), X_test)
Y_train = reshapeY(len(Y_train0), Y_train0)
elm.train(X_train, Y_train)
Y_predict = elm.predict(X_test)
# print(type(Y_predict))
# print(Y_predict)
li = []
for i in range(1, Y_predict.row + 1):
for j in range(1, Y_predict.column + 1):
li.append(Y_predict[i, j])
Y_predict = np.array(li)
print(Y_predict)
# 计算差方均值的平方根
Y_predict2 = elm.predict(X_train)
li = []
for i in range(1, Y_predict2.row + 1):
for j in range(1, Y_predict2.column + 1):
li.append(Y_predict2[i, j])
Y_predict2 = np.array(li)
# print(Y_predict2)
ans = 0
for i in range(0, len(Y_predict2)):
square_delta = (Y_predict2[i] - Y_train0[i]) ** 2
# print(square_delta)
ans += square_delta
ans /= len(Y_predict2)
ans = ans ** 0.5
print(ans)
ans2 = 0 # 修正异常数据
normal_num = 0 # 计数(正常个数)
for i in range(0, len(Y_predict2)):
square_delta = (Y_predict2[i] - Y_train0[i]) ** 2
# print(square_delta)
if square_delta < 1.5:
ans2 += square_delta
normal_num += 1
ans2 /= normal_num
ans2 = ans2 ** 0.5
print(ans2)