自然语言生成技术现状调查:核心任务、应用和评估(2)
论文前面部分:自然语言生成技术现状调查:核心任务、应用和评估(1)_流萤数点的博客-CSDN博客
目录
3.NLG体系结构和方法
3.1模块化的方法
3.2规划方法
3.2.1语法规划
3.2.2基于强化学习的不确定性随机规划
3.3.3NLG作为分类和优化
3.3.4 NLG as ‘Parsing’
3.3.5深度学习的方法
3.3.6 Encoder-Decoder架构
3.3.7 条件语言模型
3.4 结论
3.NLG体系结构和方法
在概述了nlg系统所包含的最常见的子任务之后,我们现在转向这些任务的组织方式。一般来说,我们可以区分nlg架构的三种主要方法:
- 模块化架构:在设计上,这样的架构涉及子任务之间相当清晰的划分,尽管它们之间有显著的变化;
- 规划视角:将文本生成视为规划将其与ai的悠久传统联系在一起,并为nlg的各种子任务提供更集成、更少模块化的视角;
- 集成或全局方法:现在是nlg中的主要趋势(更普遍的是在nlp中也是如此),这样的方法跨越了任务划分,通常通过严重依赖统计学习(非语言)输入和输出。
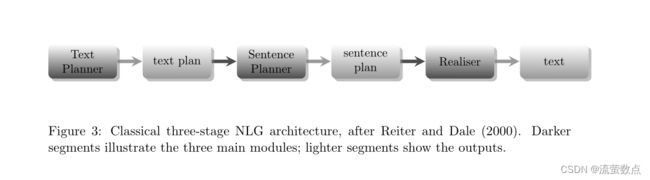
图3:Reiter和Dale(2000)之后的经典三级NLG架构。较暗的部分说明了三个主要模块;较轻的部分显示输出。
nlg的上述类型是基于体系结构方面的考虑。正交问题涉及到特定方法在多大程度上依赖于符号或基于知识的方法,而不是随机的、数据驱动的方法。重要的是要注意,上面列出的三种体系结构类型中没有一种固有地致力于上述任何一种。因此,一个系统可能具有模块化设计,但在几个甚至所有的子任务中合并随机方法。事实上,我们在第2节中对各种任务的调查包括了一些随机方法的例子。下面,我们还将讨论一些数据驱动系统,它们的设计可以说是模块化的。类似地,系统可以采用非模块化的视角,但避免使用数据驱动的模型(例如,这是下面第3.2节中讨论的一些基于规划的nlg系统的特性)。
许多模块化nlg系统不是数据驱动的事实很大程度上是由于历史原因,因为在上面概述的三种设计中,模块化是最古老的。然而,正如我们将在下面展示的,对经典模块化管道架构的挑战——曾经被Reiter(1994)指定为当时的共识——包括黑板和基于修订的架构,它们不是随机的。同时,必须承认,大规模采用综合的、非模块的方法受到了国家资料资料小组内采用数据驱动技术和发展支助培训和评价的数据储存库的重大影响。
总之,根据nlg系统的设计或开发中采用的方法,至少有两种正交的方法对其进行分类。为了便于阐述,我们在本节中的调查遵循上面概述的类型学。然而,读者应该记住这里提出的警告,并且在我们讨论每个标题下的不同方法时,无论如何将在下面反复提出。
3.1模块化的方法
现有的nlg调查,包括Reiter和Dale(1999,2000)和Reiter(2010)的调查,通常将图3中显示的管道体系结构的某些版本称为该领域的“共识”体系结构。最初由Reiter(1994)提出,管道是基于实际实践的一般化,并声称具有“事实上的标准”的地位。然而,正如我们将看到的,这一点已被反复争论。
管道中的不同模块包含第2节中描述的任务的不同子集。第一个模块是文本规划器(或文档规划器或Macroplanner),它结合了内容选择和文本结构(或文档规划)。因此,它主要关注战略生成(McDonald, 1993),“说什么”的选择。生成的文本计划是消息的结构化表示,是句子规划器(或微规划器)的输入,它通常结合了句子聚合、词汇化和引用表达式生成(Reiter & Dale, 2000)。如果文本计划相当于决定说什么,句子计划可以被理解为决定如何说。接下来要做的就是把它说出来,也就是说,通过应用语法和形态规则,以一种语法正确的方式生成最后的句子。这项任务由语言实现器执行。句子规划和实现包含了一系列传统上称为战术生成的任务。
管道体系结构与文本摘要中广泛使用的体系结构有一些共同的特征(Mani, 2001;Nenkova & McKeown, 2011),该过程被细分为(a)源文本的分析和信息的选择;(b)转换选定的信息以提高流利性;(c)综合总结。
第二个相关的架构,也被Reiter(1994)所注意到,是心理语言学为人类言语生产提出的,其中最具影响力的语言生产心理语言学模型,由Levelt(1989,1999)提出,在决定说什么和决定如何说之间做出了类似的区分。Levelt的模型允许通过反馈循环进行有限程度的自我监测,这一特性在Reiter的nlg管道中不存在,但继续在心理语言学中发挥重要作用(参见Pickering & Garrod, 2013),尽管在这方面也越来越强调更综合的模型。
图3中的体系结构的一个特征是,它代表了传统上被认为属于“什么”(战略)和“如何”(战术)的任务之间的明确划分。然而,这并不意味着这种划分在实践中被普遍接受。在早期的调查中,Mellish等人(2006)得出结论,虽然一些nlg系统包含了第2节中概述的许多核心任务,但它们的组织结构因系统而异。事实上,有些任务可能被划分到不同的模块中。例如,指代表达生成的内容确定部分可以放在句子计划器中,但关于形式的决定(例如是否使用回指名词,如果使用,产生什么样的名词)可能必须等待,至少要等到做出一些与实现相关的决定之后。基于这些观察,Mellish等人提出了另一种形式主义,“对象和箭头”框架,在这个框架中,nlg子任务之间可以容纳不同类型的信息流。该框架不是提供特定的体系结构,而是作为一种形式主义,可以在其中指定不同体系结构的高级描述。然而,它保留了一个原则,即任务,无论其组织,都是相对明确和区分的。
与图3中的管道体系结构相关的另一个最新进展是Reiter(2007)提出的一项建议,该建议适用于输入由原始(通常是数字)数据组成的系统,这些数据需要进行一些预处理,然后才能进行文本规划器设计用于执行的那种选择和规划。这些系统的主要特征是输入是非结构化的,这与在逻辑表单或数据库条目上操作的系统相反。应用程序域的例子包括气象报告(例如,Goldberg等,1994;Busemann & Horacek, 1997;Coch, 1998;特纳等人,2008年;斯里帕达等,2003;Ramos-Soto等人,2015),其中输入通常采用数值天气预测的形式;以及从患者数据中生成摘要(例如,Hueske-Kraus, 2003;哈里斯,2008;Gatt et al, 2009;Banaee等人,2013)。在这种情况下,nlg系统通常需要执行某种形式的数据抽象(例如,确定数据中的大致趋势),然后进行数据解释。用于执行这些任务的技术范围从信号处理技术的扩展(例如,Portet et al, 2009)到基于模糊集理论的推理形式主义的应用(例如,Ramos-Soto et al, 2015)。Reiter(2007)的建议通过“向后”扩展管道,合并文本规划之前的阶段来适应这些步骤。
尽管管道nlg体系结构优雅而简单,但也存在与之相关的挑战,其中有两点特别值得强调:
- 代沟指的是战略和战术组件之间的不匹配,所以在管道中的早期决策会产生无法预见的后果。以Inui、Tokunaga和Tanaka(1992)的例子来说,生成系统可能会在句子规划阶段确定特定的句子顺序,但一旦句子实际实现并插入正字法,这可能会变得模棱两可;
- 约束下生成:这本身可能是代沟的一个实例,当系统的输出必须满足某些要求时,这个问题就会发生,例如,它不能超过某个长度(参见Reiter, 2000,讨论)。在实现阶段,将这一约束形式化似乎是可能的——例如,通过规定单词或字符数量的长度约束——但在早期阶段要困难得多,因为在早期阶段,表征是前语言的,它们到最终文本的映射可能是不可预测的。
这些以及相关的问题推动了可选架构的开发。
例如,一些早期的nlg系统是基于交互设计的,其中模块最初不完整的输出可以根据后期模块的反馈而充实起来(pauline系统就是这样的一个例子;Hovy, 1988)。在黑板架构中,甚至采取了更灵活的立场,在这种架构中,特定于任务的过程不是严格预先组织的,而是随着输出的反应性地执行它们的任务,以任务之间共享的数据结构表示(例如,Nirenburg, Lesser, & Nyberg, 1989)。最后,基于修订的体系结构允许在被监视的模块之间进行有限形式的反馈,并有可能更改被证明不令人满意的选择(例如,Mann & Moore, 1981;Inui等人,1992)。这样做的好处是不需要“早期”模块意识到它们对后续模块的选择的后果,因为出错的地方总是可以修改的(Inui et al, 1992)。修订不一定是为了纠正缺点而进行的。例如,Robin(1993)在体育总结中使用了修订;对初稿进行了修订,以增加与草案中所报告的事件有关的历史背景资料,并就这些资料与正文的关系作出了决定。正如De Smedt、Horacek和Zock(1996)所指出的那样,所有这些替代方案的潜在代价当然是效率的降低。
尽管模块化方法受到了早期的批评,但战略与战术的划分继续影响着最近的数据驱动nlg方法,包括下面第3.3节和3.3.5节中讨论的一些方法(例如Duˇsek & Jurˇc´istanbulˇcek, 2015年,2016年,等等)。
然而,管道的其他替代方案通常会模糊nlg系统中模块之间的边界。这一特点在近年提出的一些以规划为基础的综合办法中更为明显。我们现在要讲的就是这些。
3.2规划方法
在人工智能中,规划问题可以被描述为确定一个或多个行动序列以满足特定目标的过程。初始目标可以分解为子目标,每一个子目标都有其前提条件和效果。在经典的规划范例中(条形;Fikes & Nilsson, 1971),动作被表示为这些先决条件和效果的元组。
规划和nlg之间的联系在于,文本生成可以被视为为实现交际目标而计划的行为的执行,其中每个动作都会导致一个新的状态,也就是说,一个语境的变化,包括迄今为止的语言互动或话语历史,还包括物理或情境语境以及用户的信念和行动(见Lemon, 2008;Rieser & Lemon, 2009;Dethlefs, 2014;Garoufi & Koller, 2013;Garoufi, 2014,关于这个话题的一些最新观点)。因此,对nlg的这种观点与“语言作为行动”的观点相关(Clark, 1996),这一观点本身植根于由Austin(1962)和Searle(1969)的工作开创的哲学传统。事实上,一些最早的人工智能作品都遵循了这一传统(特别是Cohen & Perrault, 1979;Cohen & Levesque, 1985)为言语行为及其后果寻求一个明确的先决条件(类似于Searle的幸福条件)的表述。
考虑到原则上对计划中可以包含什么类型的行动没有限制,基于计划的nlg方法有可能跨越通常封装在经典管道架构中的许多任务的边界,通过将说什么和如何说的问题视为同一组操作的重要组成部分,将战术和战略元素结合起来。事实上,在早期的工作中有一些重要的先例,将nlg作为目标层次的统一观点,kamp系统(Appelt, 1985)是最著名的例子之一。例如,为了在kamp中生成指称表达,其出发点是推理对话者的信念和相互知识,然后系统生成子目标,一直延伸到属性选择和实现,最后生成指称np,其预期效果是改变听者对指称表达者的信念状态(参见Heeman & Hirst, 1995,关于生成对话中指称表达的类似方法)。
然而,这些观点的一个问题是,关于信念、欲望和意图(或bdi,在Bratman, 1987之后经常被称为bdi)的深度推理需要高度表达的形式主义,并引起相当大的计算开销。一种解决方案是避免通用的推理形式主义,而是采用一种语言框架来适应nlg的规划范式。
3.2.1语法规划
在规划术语中解释语言形式主义的想法在早期的nlg工作中再次有所预示。例如,一些早期的系统(例如kpml,我们在第2.6节的实现中简要讨论过;Bateman, 1997)是基于系统功能语法(sfg;(韩立德和马蒂森,2004),这可以被视为当代基于规划的方法的先驱,因为sfg将语言建构建模为通过一个延伸到语用意图的决策网络的遍历的结果。
Hovy(1991)和Moore和Paris(1993)都将修辞结构理论(Mann & Thompson, 1988)的关系解释为文本规划的操作符。
最近的一些方法将大部分规划机制集成到语法本身中,将语言结构视为规划操作符。这就需要语法形式主义,它整合了从语用学到形态句法的多层次语言分析。
当代基于规划的nlg方法通常采用词汇化树毗邻语法的形式主义(ltag;Joshi & Schabes, 1997),尽管其他形式主义,如组合范畴语法(Steedman, 2000)也已被证明足以完成这项任务(特别是Nakatsu & White, 2010,关于使用语篇组合范畴语法的生成方法)。
在ltag中,语言结构的片段(词典中的所谓基本树)可以与语义和语用信息相结合,这些信息指定(a)为了恰当地使用条目需要获得哪些语义前提条件;(b)使用该特定物品将达到什么实用目标(见Stone & Webber, 1998;Garoufi & Koller, 2013;Koller & Striegnitz, 2002,基于计划的工作使用ltag)。作为如何在计划框架中部署这种形式主义的一个例子,让我们关注引用目标实体的任务。Koller和Stone(2007)以一种不需要区分内容确定和实现阶段的方式制定了任务(Stone和Webber, 1998年已经采用了这种方法)。此外,它们不像传统管道中所做的那样,将句子计划、reg和实现分开。
考虑一下Mary likes the white rabbit(玛丽喜欢白兔)这个句子。为了便于表达,我们简化了形式,可以像下面这样表示词汇项(这个例子是基于Garoufi, 2014,尽管做了一些简化):
(12) likes(u, x, y) action:
preconditions:
• The proposition that x likes y is part of the knowledge base (i.e. the statement
is supported);
• x is animate;
• The current utterance u can be substituted into the derivation S under
construction;
effects:
• u is now part of S
• New np nodes for x in agent position and y in patient position have been set
up (and need to be filled).
与strips一样,算符由前置条件和结果组成。注意,与词汇项相关的先决条件需要知识库中的支持(因此引用输入kb,实现器通常无法访问它),并包括语义信息(例如代理需要动画化)。在插入like作为句子的主要动词之后,我们有两个名词短语,它们需要通过为参数x和y生成nps来填充。Koller和Stone没有将这一任务交给单独的reg模块,而是通过在将被纳入指称np的语言操作符(基本树)上关联进一步的语用前提条件来构建指称表达式。首先,实体必须是听者知识状态的一部分,因为一个识别描述(比如,到x)预设了听者熟悉它的前提。其次,在np中添加单词(如谓词rabbit或white)的一个效果是,短语排除了干扰物,即那些属性不为真的实体。在一个有一个人和两只兔子的场景中,其中只有一只兔子(在我们的例子中是y)是白色的,推导将首先用兔子更新与y对应的np,从而将人从分心物集中排除,但不满足区分y的目标(因为y不是唯一的兔子)。在np(白色)上添加另一个谓词就可以达到这个目的。
基于规划的方法的一个实际优势是可以获得大量现成的规划人员。一旦用适当的计划描述语言制定了nlg任务,例如规划域定义语言(pddl;McDermott, 2000),原则上可以使用任何规划器来生成文本。然而,规划者仍然受到效率问题的困扰。在对不同复杂性的nlg任务进行的一系列实验中,Koller和Petrick(2011)指出,规划者倾向于在预处理上花费大量时间,尽管一旦预处理完成,往往可以有效地找到解决方案。
3.2.2基于强化学习的不确定性随机规划
到目前为止,我们所讨论的规划方法主要是基于规则的,并且倾向于将计划中的行动及其后果(即其对环境的影响)之间的关系视为固定的(尽管存在例外,如在应急计划中,它生成多个计划来处理不同可能的结果;Steedman & Petrick, 2007)。
正如Rieser和Lemon(2009)所指出的,这种观点是不现实的。考虑一个生成餐厅推荐的系统。它的输出结果(即它所产生的新状态)受制于来自多种不确定性来源的噪声。在某种程度上,这是由于权衡,例如,需要包含适当数量的信息,同时避免过度冗长。另一个不确定性的来源是用户,用户的行为可能不是系统所预测的。米特尔(1991)的代沟的一个例子可以凸显出来,例如,如果随机实现器以含糊的或过长的话语呈现信息的内容(Rieser & Lemon, 2009),这个问题可以通过允许不同的子任务共享知识来源和受重叠约束的指导来解决(Dethlefs & Cuayáhuitl, 2015,下面讨论)。
简而言之,计划一个好的解决方案来达到交流目标可以被视为一个随机优化问题(这个主题我们将在下面的3.3.3节中再次讨论)。这一观点被许多基于强化学习的近期方法所认同(rl; Lemon, 2008;Rieser & Lemon, 2009, 2011),特别是那些在对话环境中处理NLG的游戏。
在这个框架中,生成可以被建模为马尔可夫决策过程,其中状态与可能的动作相关联,每个状态-动作对都与通过动作a从时刻t的状态移动到t + 1的新状态的概率相关联。对于学习算法来说,至关重要的是,过渡与强化信号相关联,通过量化生成输出的最优性的奖励函数。学习通常包括模拟,在模拟中,不同的生成策略或“策略”(本质上是通过状态空间的可能路径对应的计划)与不同的奖励相关联。rl框架被认为比监督学习或分类更能处理动态环境中的不确定性,因为它们不能适应不断变化的环境(Rieser & Lemon, 2009)。Rieser、Keizer、Liu和Lemon(2011)表明,在生成餐厅推荐时,这种方法可以有效优化信息呈现。Janarthanam和Lemon(2014)在给定用户知识的情况下,利用它来优化参考表达中的信息选择。当用户在对话过程中获得新知识时,系统学会适应其用户模型。
这项工作的一个重要贡献是探索联合优化,通过跨子任务共享知识,学习到的策略满足生成过程中不同子任务产生的多个约束。Lemon(2011)表明,联合优化可以学习一种策略,该策略决定何时生成信息性话语或查询以从用户那里获取更多信息。类似地,Cuayáhuitl和Dethlefs(2011)使用分层rl来联合优化寻找和描述短路线描述的问题,同时适应用户的先验知识,产生一种策略,即引导用户经过他们熟悉的地标,同时避免潜在的混淆路口。同样在寻路设置中,Dethlefs和Cuayáhuitl(2015)开发了一个分层模型,包括一组学习代理,其任务范围从内容选择到实现。他们表明,一个由代理共享知识的联合框架,优于一个单独的学习框架,在这个框架中,每个任务都是单独建模的。例如,联合策略学习给出高级导航指令,但如果用户偏离轨道,则切换到低级指令。此外,联合策略生成的语句不那么冗长,总体上导致更短的交互。
联合优化框架当然不是强化学习和基于计划的方法所独有的。前几节中讨论的许多内容确定方法,包括Marciniak和Strube(2005)以及Barzilay和Lapata(2005)的工作,也在其内容确定和实现的方法中使用联合优化(见第2.1节),以及Lampouras和Androutsopoulos(2013)的工作。
我们将在下面的3.3.3节中返回到优化。
总之,规划范式中的nlg研究强调了开发统一的形式来表示生成过程在多个层面上的约束的可取性,无论这是使用基于人工智能的规划形式(Koller & Petrick, 2011)完成的,还是通过强化学习随机完成的。在其贡献中,后者的工作阐明了(a)子问题之间的层次关系;和(b)不同子任务的联合优化。事实上,后一种趋势属于更广泛的关于nlg综合方法的研究,我们将注意力转向这一领域
就在下面。
3.3.3NLG作为分类和优化
考虑不同层次的nlg决策的另一种方法是在分类方面,这在具体任务的背景下已经遇到过,如内容确定(例如,Duboue & McKeown, 2003)和实现(例如,Filippova & Strube, 2007)。由于生成最终是关于在多个层次上做出选择,建模这个过程的一种方法是使用分类器级联,其中的输出是增量构造的,因此任何分类器Ci使用前一个分类器Ci−i的输出作为其输入的(一部分)。
在这个框架中,仍然可以从管道的角度来构想nlg。正如Marciniak和Strube(2005)所指出的,另一种思考方法是基于加权的多层晶格,其中生成相当于最佳优先遍历:在任何阶段i,分类器Ci产生最可能的输出,这沿着最可能的路径导致下一个阶段Ci+1。这种泛化在概念上与nlg的观点相关,即强化学习框架中的策略(参见上面的3.2.2节),它定义了对可能是分层组织的状态序列的遍历(例如,在Dethlefs & Cuayáhuitl, 2015的工作中)。
Marciniak和Strube(2004)从一个小型的人工注释路线描述文本语料库开始,将生成划分为一系列8个分类问题,从确定话语单元的线性优先级,到确定动词的词汇形式及其论证类型。生成决策使用基于实例的KStar算法,该算法在所有分类决策上的表现优于大多数基线。Varges和Mellish(2010)也讨论了基于实例的nlg方法,尽管采用的是一种过度生成-排序方法,即规则过度生成候选对象,然后通过与实例库的比较对候选对象进行排序。
最近,Zarrieß和Kuhn(2013)采用了一个类似的框架,再次将文本数据作为他们的起点,用依赖表示进行注释,如下面的(14)所示,其中引用标记为v和p,并在依赖的隐式头部下划线。

这些作者使用一系列分类器来执行引用表达式的生成和实现。他们使用基于支持向量机的排序模型,给定从注释文本(如(14))中提取的输入依赖表示,该模型按任意顺序执行两个任务:(a)将输入映射到一个浅语法树以进行线性化;(b)插入参考表达式。有趣的是,Zarrieß和Kuhn(2013)观察到,这两个任务的性能都是顺序相关的,因为当它们在序列中排在第二位时,这两个分类任务的性能都更差。他们观察到,当任务并行执行时,性能略有改善,但在基于修订的体系结构中,性能最好,在这种体系结构中,语法映射之后是引用表达式插入,然后是语法修订。
nlg的分类级联保持了任务之间的清晰分离,但这一领域的研究反映了早期对管道的普遍关注(见3.1节),主要问题是错误传播。不明智的选择当然会进一步影响下游的分类,这种情况类似于代沟问题。Zarrieß和Kuhn(2013)的结论是支持基于修订的架构,这使我们的论述回到了原点,因为一个众所周知的解决方案被证明可以在新框架中产生改进。
到目前为止,我们的讨论已经反复强调了一个事实,即nlg任务的顺序组织容易受到错误传播的影响,无论是以分类器错误的形式出现,还是基于规则的模块中的决策对下游组件产生负面影响。
一个潜在的解决方案是将发电视为一个优化问题,在一个指数级大的可能组合空间中寻求最佳决策组合。我们已经遇到了优化技术的使用,如整数线性规划(ilp)在聚合和内容确定的上下文中(第2.3节)。例如,Barzilay和Lapata(2006)根据内容单元的成对相似度对其进行分组,并通过一个优化步骤来识别一组最大程度相似的对。Marciniak和Strube(2004,2005)也利用ilp作为一种方法来抵消他们最初基于分类的方法中的错误传播问题。在从owl本体生成文本的背景下,Lampouras和Androutsopoulos(2013)也采取了类似的解决方案。Lampouras和Androutsopoulos表明,与管道系统相比,使用整数线性规划共同确定内容选择、词汇化和聚合的联合优化产生了更紧凑的本体事实的口头表达(作者在Androutsopoulos, Lampouras, & Galanis, 2013)。
从概念上讲,优化框架很简单:
- 每个nlg任务再次被建模为分类或标签分配,但这一次,标签被建模为二元选择(标签被分配或不被分配),与一个成本函数相关联,该函数根据训练数据中标签出现的概率定义;
- 强烈相互依赖的成对任务(例如,句法选择和reg实现,在Zarrieß & Kuhn, 2013年的例子中)的成本基于它们标签的联合概率;
- ILP模型寻求使总成本最小化的全局标签解决方案,附加的约束是,如果一对相关标签
中的一个被选中,另一个也必须被选中。
优化解决方案已被证明优于不同版本的分类管道(例如,Marciniak & Strube, 2004),就像Dethlefs和Cuayáhuitl(2015)的结果一样,上面讨论过,表明联合策略的强化学习比学习独立nlg任务的孤立策略产生更好的对话交互。
Lampouras和Vlachos(2016)的模仿学习框架(在前面的3.3.1节中讨论过),寻求联合优化内容确定和实现,也显示出了实现竞争性结果的能力,接近Wen等人(2015)在sf上的系统和Duˇsek和Jurˇc´伊斯坦布尔ˇcek(2015)在百吉饼上的系统的性能。
3.3.4 NLG as ‘Parsing’
近年来,从概率上下文无关语法(cfg)的形式来看生成,甚至作为语义解析的“逆”,已经有了一种兴趣的复兴。例如,Belz(2008)将nlg问题完全形式化为cfgs:一个基本生成器通过应用cfg规则扩展输入(在这种情况下是天气数据位);然后使用语料库派生的概率来控制在过程的每个阶段扩展哪些规则的选择。这个作品中的基发生器是手工制作的。然而,从语料库中提取规则或模板是可能的,正如聚合规则所做的那样(Stent & Molina, 2009;White & Howcroft, 2015和第2.3节),以及在文本到文本框架中句子规划和实现的更一般的统计方法(例如,Kondadadi等人,2013)。类似地,从结构化知识库(以rdf等形式表示)中获取nlg的方法描述了从与文本描述配对的输入中提取词汇化语法或模板的技术(Ell & Harth, 2014;杜马和克莱因,2013年;嘉瓦利和嘉登,2014)。
Mooney及其同事的工作(Wong & Mooney, 2007;Chen & Mooney, 2008;Kim & Mooney, 2010)比较了受黄蜂语义解析器启发的许多不同的生成策略(Wong & Mooney, 2007),该解析器利用统计机器翻译技术从话语对及其语义表示中学习到的概率同步cfg规则。Chen和Mooney(2008)通过在一个生成框架中对黄蜂进行调整,以及进一步对其进行调整以产生一个新的系统——黄蜂-世代(wasper-gen),来使用这个框架进行生成。wasp寻求最大化给定句子的意义表示(mr)的概率,而wasper-gen则相反,寻找给定输入mr的最大可能句子,也就是说,学习从意义到文本的翻译模型。在使用体育节目数据集(robocup数据集)进行训练时,wasper-gen在基于语料库的评估指标上比黄蜂表现更好,根据实验参与者的主观判断,wasper-gen达到了接近人类文本的流利程度和语义正确性。但是请注意,这个框架主要关注战术生成。内容确定是单独执行的,使用em-算法的变体来收敛于一个概率模型,该模型预测哪些事件或谓词应该被提及。
相比之下,Konstas和Lapata(2012, 2013)的工作也依赖于cfgs,自始至终使用统一的框架。起点是文本与数据库记录的对齐,扩展了Liang等人(2009)的建议。将输入数据转换为输出文本的过程是根据规则建模的,这些规则隐式地包含了不同类型的决策。例如,给定一个天气记录数据库,规则可能采用(稍微简化)如下所示的形式:
(15) R(windSpeed) → F S(temperature), R(rain)
(16) F S(windSpeed,min) → F (windSpeed,max)F S(windSpeed,max)
(17) F S(windSpeed,min) → W (windSpeed,min)
其中R代表一个数据库记录,F S是一组字段,F (x, y)代表记录x中的字段y, W是一个单词序列,并且所有规则都具有相关概率,这些概率将rhs限定在lhs上,类似于'parsing'(语法分析)中使用的PCFGS。这些规则规定,在描述风速(15)之后,文本中应加上温度和降雨报告。根据规则(16),在最小风速之后,应提到具有一定概率的最大风速。规则(17)根据bigram语言模型将最小风速规则扩展为单词序列(Konstas & Lapata, 2012)。
Konstas和Lapata(2012)将从对齐阶段获得的规则集打包成超图,并将生成视为解码,以寻找最大可能的单词序列。
在这种观点下,生成类似于反向解析。解码过程使用cyk算法的改编。由于定义从输入到输出映射的模型不包含流畅性启发式,因此解码器与Konstas和Lapata(2013)提出的另外两个语言知识来源交织在一起:(a)加权有限状态自动机(表示n-gram语言模型);(b)依赖模型(cf.Ratnaparkhi, 2000,,上面也讨论过)。
3.3.5深度学习的方法
我们以深度神经网络(nn)体系结构的应用概述来结束对数据驱动神经网络的讨论。最近,人们对这些模型重新产生了兴趣(参见Goldberg, 2016,关于nlp的概述),而且到目前为止,在这个框架中所包含的nlg模型的范围相对较小(但稳步增长),因此决定单独设立一个章节是有理由的。在接下来的章节中,我们还将在更具体的标题下重新讨论nlg的nn模型,特别是在讨论风格变化(第5节)和图像字幕(第4节)时,它们现在是主要的方法。
事实上,nlg中nns的应用至少可以追溯到Kukich(1987),尽管她的工作仅限于小规模的例子。自20世纪90年代初以来,当神经方法在自然语言处理和人工智能领域的兴趣减弱时,认知科学研究一直在继续探索它们在句法和语言产生方面的应用(例如,Elman, 1990,1993;Chang, Dell, & Bock, 2006)。最近对网络神经网络的兴趣的复苏部分是由于硬件的进步,可以支持资源密集型学习问题(Goodfellow, Bengio, & Courville, 2016)。更重要的是,神经网络被设计成通过利用反向传播(LeCun, Bengio, & Hinton, 2015;Goodfellow等人,2016)。这样的表示是密集的、低维的和分布式的,使它们非常适合捕捉语法和语义的概括(见Mikolov, Chen, Corrado, & Dean, 2013;Luong, Socher, & Manning, 2013;彭宁顿,索彻,和曼宁,2014年,除其他外)。神经网络在使用前馈网络的顺序建模方面也取得了显著的成功(Bengio, Ducharme, Vincent, & Janvin, 2003;Schwenk & Gauvain, 2005)、对数双线性模型(Mnih & Hinton, 2007)和循环神经网络(rnns, Mikolov, Karafiat, Burget, cernoky, & Khudanpur, 2010),包括具有长短期记忆单元的rnns (lstm, Hochreiter & Urgen Schmidhuber, 1997)。后者是目前用于语言建模任务的主要rnn类型。与标准语言模型相比,它们的主要优点是处理不同长度的序列,同时通过将历史投影到低维空间避免数据稀疏性和参数数量的激增,从而使相似的历史共享表示。
Sutskever、Martens和Hinton(2011)展示了循环网络对nlg的潜在效用,他们使用字符级别的lstm模型来生成语法英语句子。不过,这只着重于实现这些目标的潜力。从语义或上下文输入生成的模型围绕下面描述的两种相关类型的模型聚集。
3.3.6 Encoder-Decoder架构
一个有影响力的体系结构是编码器-解码器框架(Sutskever, Vinyals, & Le, 2014),其中rnn用于将输入编码为向量表示,向量表示作为解码器rnn的辅助输入。这种编码和解码之间的解耦使得在多任务学习设置中跨多个nlp任务共享编码向量在原则上成为可能(参见Dong, Wu, He, Yu, & Wang, 2015;Luong, Le, Sutskever, Vinyals, & Kaiser, 2015,为一些最近的案例研究)。编码器-解码器体系结构特别适合于序列到序列(seq2seq)任务,如机器翻译,这可以被认为是需要映射源语言中的变长输入序列到目标语言中的变长序列(例如,Kalchbrenner & Blunsom, 2013;Bahdanau, Cho, & Bengio, 2015)。很容易将此视图调整为数据到文本的nlg。例如,Castro Ferreira、Calixto、Wubben和Krahmer(2017)采用seq2seq模型从抽象意义表示(amrs)生成文本。
编码器-解码器范式的另一个重要发展是使用基于注意力的机制,这迫使编码器在训练过程中,在预测解码过程中输出的某些部分时,对输入编码的部分赋予更多的权重(cf. Bahdanau等人,2015;Xu, Ba, Kiros, Cho, Courville, Salakhutdinov, Zemel, & Bengio, 2015)。这种机制消除了直接输入输出对齐的需要,因为基于注意的模型能够基于输入表示和输出文本的松散耦合学习输入输出对应关系(参见Duˇsek & Jurˇc´伊斯坦布尔ˇcek, 2016,进行讨论)。
在nlg中,在交互式上下文中(如对话或社交媒体帖子)生成响应的许多方法都采用了这种架构。例如,Wen等人(2015)使用语义条件lstms来生成对话中的下一个动作;Sordoni、Galley、Auli、Brockett、Ji、Mitchell、Nie、Gao和Dolan(2015)采取了一种相关的方法,他们使用rnn对输入话语和对话上下文进行编码,并使用解码器预测应答中的下一个单词(另见Serban、Sordoni、Bengio、Courville和Pineau, 2016)。戈亚尔、戴梅特曼和高斯尔(2016)发现,使用基于字符的rnn比使用基于单词的rnn能提高生成对话行为的质量。
Duˇsek和Jurˇc´土耳其ˇcek(2016)还使用了一个seq2seq模型,关注对话生成,比较了一个端到端模型,其中内容选择和实现是联合优化的(因此输出是字符串),和一个输出深度语法树的模型,然后使用一个成熟的实现器实现(如Duˇsek和Jurˇc´土耳其ˇcek, 2015)。与Wen等人(2015)一样,他们在解码过程中使用重排序器对波束搜索输出进行排序,对省略相关信息或包含不相关信息的输出进行惩罚。他们在bagel上的评估表明,联合优化设置优于为后续实现生成树的seq2seq模型。Mei等人(2016)还使用weathergov数据(Angeli等人,2010)明确指出了内容选择和实现的划分。他们使用双向lstm编码器将输入记录映射到隐藏状态,接着是基于注意力的对齐器,其对内容选择进行建模,根据它们的先验概率和它们与词汇表中的单词对齐的可能性来确定哪些记录需要提及;进一步的细化步骤是将结果与先验的一致性进行加权,使更重要的记录更有可能被口头记录。
在这种方法中,lstms能够学习记录和描述符之间的长期依赖关系,这是Angeli的对数线性模型显式考虑的因素(参见上面的3.3.2节)。类似的方法现在也被用于自动生成诗歌(例如,Zhang & Lapata, 2014),我们将在下面返回这个话题。
3.3.7 条件语言模型
数据到文本过程的一个相关视图将生成器视为一个有条件的语言模型,其中通过从一个以输入特征为条件的分布中采样单词或字符来生成输出,这些特征可能包括语义、上下文或风格属性。
例如,Lebret等人(2016)限制生成来自相应维基事实表的维基百科传记的首句,并在前馈神经网络中联合建模内容选择和实现(Bengio等人,2003),根据从输入表获得的本地上下文和全局特征调节输出词的概率。这使模型偏向于对字段内容的完全覆盖。例如,表中包含人名的字段通常由多个单词组成,模型应该将组成整个名字的单词连接起来。虽然这个模型比上面讨论的一些模型更简单,但也可以认为它包含了注意机制。Lipton、Vikram和McAuley(2016)使用以语义信息和情绪为条件的字符级rnn生成产品评论,而Tang、Yang、Carton、Zhang和Mei(2016)使用以输入“上下文”为条件的lstm生成此类评论,其中上下文包含离散信息(用户、位置等)和连续信息。在文体和情感生成的许多模型中也采用了类似的方法(参见Li, Galley, Brockett, Spithourakis, Gao, & Dolan, 2016;赫齐格,Shmueli-scheuer, Sandbank, & Konopnicki, 2017;Asghar, Poupart, Hoey, Jiang和Mou, 2017;胡,杨,梁,Salakhutdinov,邢,2017;Ficler & Goldberg, 2017,以及下面第5节的讨论)。
3.4 结论
从最近的工作中出现的一个重要主题是模糊了传统架构中封装的任务之间的边界。这在基于规划的方法中是显而易见的,但从这个角度来看,最根本的突破可能出现在随机数据到文本系统中,该系统利用输入数据和输出文本之间的对齐,在统一的框架中结合面向内容和语言的选择。在随机nlg研究提出的开放问题中,有一个是哪些子任务需要联合优化,如果是的话,哪些知识来源应该在它们之间共享。这在最近使用神经模型的工作中也可以看到,与将任务分开的模型相比,内容选择和实现的联合学习被声称能产生更好的输出(例如,Duˇsek & Jurˇc´伊斯坦布尔ˇcek, 2016)。
一个突出的问题是在实现充分的文本输出与高效、健壮地实现文本输出之间取得平衡。早期脱离流水线架构的方法往往牺牲流水线架构,取而代之的是流水线架构;在基于修订和黑板的架构中就是这样。在某种程度上,基于规划的方法也是如此,这些方法根植于人工智能中具有悠久历史的范式:正如最近的实证工作所表明的(Koller & Petrick, 2011),这些方法也容易受到相当大的计算成本的影响,尽管这带来了语言生成的统一观点的优势,这也与易于理解的语言形式主义(如ltag)相兼容。
随机方法提出了一个不同的问题,即获取正确的数据来构建必要的统计模型。虽然已经有了大量的数据集,但对于餐厅或酒店领域的推荐、简要的天气报告或体育总结等任务,数据驱动的nlg模型能否扩展到大量异构数据(数字、符号等)是标准的领域,以及需要生成较长文本的领域,还有待观察。虽然这样的数据不容易获得,但群体外包技术可能被利用(Mairesse & Young, 2014;Novikova & Rieser, 2016b)。
正如我们所看到的,系统在是否需要对齐数据(我们指的是字符串与它们对应的输入部分配对的数据)方面存在差异。随着深度学习方法越来越流行——正如我们将在下一节中看到的,它们现在是某些任务的主要方法,如生成图像标题——校准的需求变得不那么迫切,因为较松散的输入输出耦合可以构成足够的训练数据,特别是在包含注意机制的模型中。随着这些技术得到更好的理解,它们可能在更广泛的nlg任务以及端到端nlg系统中扮演更重要的角色。
对深度学习重新产生兴趣的第二个可能的结果是它对表示学习和体系结构的影响。在最近的一篇观点文章中,Manning(2015)提出,深度学习对nlp的贡献迄今为止主要是由于分布式表示的力量,而不是利用多层模型的“深度”。然而,正如曼宁还指出的,更大的深度可以带来代表性优势。
当研究人员开始定义复杂的体系结构,在训练过程中通过最小化损失函数“自我组织”时,结果可能是这样的体系结构的不同组件获得了与当前问题的不同方面相关的核心表示。
这就提出了一个问题,这种表示是否可以重用,就像计算机视觉中的深度卷积网络层在不同粒度级别学习表示一样,这些表示最终在一系列任务中被重用(例如,不仅仅是对象识别,尽管vgg等网络通常是为这类任务而训练的;参见Simonyan & Zisserman, 2015)。最近在迁移学习方面的尝试(特别是在seq2seq范式中)提出了一个相关的目标,即尝试学习从一个任务转移到另一个任务的域不变表示。
nlp,特别是nlg领域,是否会再次强调对nlg的多层次方法,使用“深度”体系结构,其组件学习不同子任务的最佳表示,也许会沿着上面第2节详细描述的路线?这种表示在多大程度上是可重用的?正如其他一些评论者所指出的,在自然语言处理中,学习促进迁移学习的领域不变语言表示的前景仍然有些难以捉摸,尽管已有确定性的成功,尤其是那些在分布式词表示发展中得分的人。这很可能是统计nlg研究的下一个前沿。