论文研读-AI4VIS-可视化推荐-Table2Analysis/Table2Charts
目录
- 前言
- 一、Table2Analysis
-
- 1 动机与贡献
-
- 1.1 动机
- 1.2 贡献
- 2 问题
-
-
- 2.1 问题抽象
-
- 1. 抽象分析过程
- 2. 语言建模
- 2.2 存在挑战
- 3 Table2Analysis
-
- 3.1 马尔可夫决策
- 3.2 DQN 动作值近似器
- 3.3 启发式波束搜索
- 3.4 DQN训练
- 4 实验
-
- 4.1 PivotTable 语料库
- 4.2 标记特征
- 4.3 DQN超参数
- 4.4 搜索采样超参数
- 4.5 基线比较和总体准确性
- 5 相关工作
-
- 5.1 分析推荐
- 5.2 结构化学习和预测
- 5.3 深度强化学习
-
- 二、Table2Charts
-
- 1 动机与贡献
- 1.1 动机
-
- 1.2 贡献
- 2 问题
-
- 2.1 问题抽象
-
- 2.1.1 图模板
- 2.1.2 图模板表到序列生成
- 2.2 存在挑战
- 3 Table2Charts
-
- 3.1 填充模板: 带有复制机制的DQN
- 3.2 修复暴露偏差:搜索采样
- 3.3 混合训练和迁移学习
- 4 实验
-
- 4.1 图表语料库
- 4.2 多类型Reco任务的评估
-
- 4.2.1 基线模型
- 4.2.2 召回率大规模评估
- 4.2.3 人类准确率评估
- 4.2.4 效率比较
- 4.3 单类型Reco任务的评估
- 4.4 推荐案例研究
- 4.5 探索表格表示
- 5 相关工作
-
- 5.1 分析推荐
- 5.2 图表推荐
- 5.3 结构化预测
- 5.4 表征学习和预训练
- 6 结论
前言
Table2Analysis是发表在AAAI2020上的关于多维数据表格分析的文章,提出了Table2Analysis,从大量(Table,analysis)对中学习常用的分析模式,并推荐对任何一个以前从未见过的表进行分析。
Table2Charts发表在ACM会议KDD ’21(Conference on Knowledge Discovery and Data Mining),提出了 Table2Charts 框架,该框架可以从大量的(表,图表)对语料库中学习通用模式。此外,基于具有复制机制和启发式搜索的深度 Q-learning,Table2Charts 可进行表到序列的生成,其中每个序列都遵循图表模板。
一、Table2Analysis
1 动机与贡献
1.1 动机
数据分析自动推荐(automatic recommendation of data analyses)可以避免多维数据表分析时琐碎和耗时的操作。Excel电子表格或Power BI 报告,同时提供源数据集和结果视觉效果,嵌入了跨用户的通用分析模式(Common Analysis),包括数据语义的典型组合模式和关于数据特征的模式。
需要设计一种学习和推荐常见分析模式的技术。
1.2 贡献
- 新的通用分析任务。它需要学习数据分析领域中结构化预测和推荐的共同智慧。
- 设计了一个基于语言的Table2Analysis框架来学习和生成常见的分析,第一个利用表中的非结构化文本自动学习所需语义组合的方法。
- 收集了数据透视表推荐任务的大规模数据集。
2 问题
2.1 问题抽象
1. 抽象分析过程
问题场景:多维数据表数据字段:维度(类别属性)用于分组、 测量值(数值属性)通过聚合操作测量一组数据。
分析过程为先选择关心的测量值,然后分组,最后选择聚合函数。
过程抽象为一个3元组:<维度、测量、聚合函数>
目的:构建能够在较低层次上模仿人类范式的机器学习模型,并推荐在较高层次上的常见分析。
完整分析(高级层次):推荐引擎为用户提供一个数据分析候选列表,每个候选列表都是一个完整的分析,
下一步分析操作(低级层次):在用户构建分析的每一步,推荐引擎都会建议下一步的候选操作。
分析语言设计:将分析过程编码为一系列动作标记。每个表都是一组数据字段标记,每个分析都是一系列操作/引用标记。
- 源字段 数据字段f:字段名、数据值
- 分析语言
三种分析标记a- 选择源字段
- 从选择一个组件更改为另一个组件,[ANA](开始选择字段), [SEP](选择维度分组)
- 应用聚合操作 [Sum], [Count], [Average]

重点讨论仅使用一个度量值和仅使用聚合计算的基本分析。但当应用于具有多个度量值的分析和其他类型的计算运算符时,所提出的技术是通用的。
-
完整、部分和目标序列
完整序列 C D C_D CD,部分序列为 前缀 S D + S^+_D SD+\ C D C_D CD,目标序列 G D G_D GD(用户采用序列),部分目标 T D T_D TD= T D + T^+_D TD+ \ G D G_D GD -
示例
[ANA] [Sales] [SEP] [SalesRep] [SEP] [Region] [Sum]

2. 语言建模
表格分析作为一个集合到序列的框架,在学习阶段,它从大量(表格、分析)对中学习。在推荐阶段,它为给定的表生成top-k分析序列。问题关键在于建模,构建动作值(Q值)函数根据给定输入集和已生成前缀的当前状态对下一个动作分数进行建模。
语言建模任务:
- 完整分析:产生top k的完整分析序列推荐列表( s 1 − s 2 s_1-s_2 s1−s2),按照s(成为给定数据集D的常见分析的概率)排序。
- 下一步动作:给定部分序列s和下一个动作a,预测sa作为常见分析前缀的可能性 P(sa ∈ \in ∈ T D + T^+_D TD+ | s,D)。
2.2 存在挑战
挑战:
- open-vocabulary problem ,引用标记非离散,无法枚举,典型NLP场景中的传统技术无法解决。
- 成功指标不同,无法缓解误差,当出现较大误差时,应中断操作寻找新的搜索分支,而不是优化下一个动作以修复分数。
解决方案:
- 设计了神经网络模型的输入层,以嵌入表中无限数据字段的语义。
- 我们使用模型本身的定制波束搜索运行多个代理,以收集样本,弥补训练和推理之间的差距。
3 Table2Analysis
提出Table2Analysis框架,通过从现有(有时是不断增长的)分析语料库学习分析语言模型来推荐完整的分析。
数据集D的完整分析推荐任务转化为基于P(S)的状态空间 S D + S^+_D SD+上的搜索(和排序)问题,搜索过程将由近似于语言模型P的启发式函数引导。
3.1 马尔可夫决策
- 状态空间是S+D,可以将其视为一棵树,其中[ANA]作为其根节点(初始状态)。
- 动作空间AD:给定状态s的法律动作为

- 状态转换,执行动作a从s到s’:
 - 奖励函数RD被设计为反映目标序列是否被成功合成:
- 奖励函数RD被设计为反映目标序列是否被成功合成:
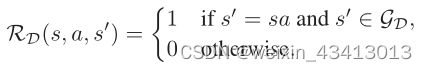
贴现率γ=1,因此分析序列的长度对其回报没有影响。
根据贝尔曼最优性方程,可以很容易地找到最佳行动值函数:
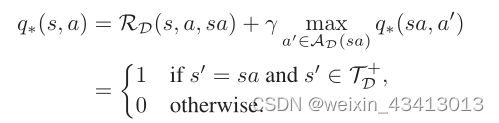
换句话说,q∗(s,a)等于1当且仅当sa是目标序列的前缀时。
3.2 DQN 动作值近似器
选择深度神经网络(DNN)作为q∗(s,a)近似器。首先,DNN以其从观察到的语料库到不可见输入的能力而闻名。其次,分析序列的长度是动态的。许多DNN结构可以处理不同的输入长度。第三,为了整合语义信息,一种理想的方法是对字段名中的自由文本采用语义嵌入。这种嵌入也最适合DNN。
我们的DQN(深度Q网络)Q(s,AD)将状态s和整个动作空间AD作为其输入,并对所有AD中的动作(忽略AD\AD中无效操作的输出)计算所有动作的估计动作值(从0到1)。动作空间序列包含源字段(按数据集D定义的顺序,如果有;还表示整个上下文),[SEP]和所有聚合函数(按使用频率的顺序,如有)。
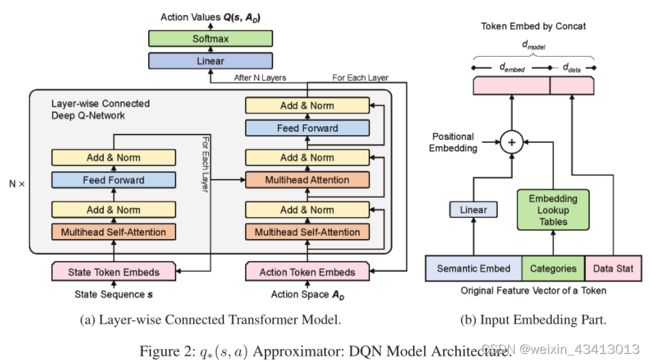
图2a是分层连接的Tansformer编码器解码器结构的变体(He等人.2018),我们为不同于传统NMT(神经机器翻译)的目的对其进行了修改。每个编码器层(图2a的左半部分)的键和值直接传递到相应的解码器层(图2a的右半部分)。与利用解码器部分逐个生成下一个字的典型NMT架构不同,分析序列的“生成”基于Q(s,AD),并导致状态序列的增长。同时,动作空间——DQN的“解码器”部分的输入——保持相同表的相同令牌集。
另一个主要挑战是如何将动作标记表示为DQN的特征向量输入。与典型NLP任务中固定的标记词汇不同,分析语言具有无限的字段标记可能性。幸运的是D中的字段数通常很小,这意味着动作空间也很小。因此,我们设计了一个输入嵌入网络(见图2b),将每个分析标记的丰富特征转换为嵌入向量,而不是将每个标记表示为其全局词汇索引的典型NLP方法。这种输入嵌入在状态序列和动作空间输入之间共享。三种标记特征融合在一起:
- 语义特征:任何组合结果,例如字段名的嵌入,都可以作为输入。它将由线性层调整大小,使其达到dembed的长度。
- 类别特征:每个分类特征还将通过可训练的查找表映射到dembed大小嵌入。标记类型和聚合函数类型是分析语言定义的两个分类特征。还包括特定于语料库的特征,如数据值类型(例如,字符串、十进制等)。
- 数据特征:通过级联直接附加到标记嵌入。它们捕获字段数据值的统计和分布信息。
除了 Transformer架构外,RNN还广泛用于seq2seq问题。然而,普通的seq2seq编码器在Table2Analysis情况下不工作,因为它的输出值具有全局词汇表大小的固定长度,在我们的情况下是无限的。未来的一项工作是尝试对现有RNN实现进行复杂的修改,包括不同大小的词汇表和引用机制,如指向或复制(Gu等人,2016)。
3.3 启发式波束搜索
为了生成多个序列用于分析推荐,使用DQN作为波束搜索的启发式函数。为了平衡性能和效率,我们重点研究了一类结合广度和深度优先搜索的向下搜索波束搜索算法。
它们采取以下步骤来搜索状态空间:
- 最初,搜索边界仅包含[ANA]
- 对于每一轮,从边界最多取出波束大小得分最高的部分序列:
(a)对于波束中的每个状态,贪婪地向下钻取(选择Q(s,a)最高的a进行附加),直到生成完整序列。来自每个展开的每个非最佳状态sa(对所有a的Q(s,AD)的评估∈ AD(s))以Q(s,a)作为其分数被置于前沿
(b)如果#扩展超出扩展限制,则停止。
对于定制的波束搜索,动作值估计可以直接用作对不同长度的到达状态进行排序的得分。这就是为什么在§2.2中我们没有采用经典的最大似然定义的原因之一,该定义仅给出局部比较的分数。
3.4 DQN训练
DQN Q(s,AD)可以通过广泛使用的教师强迫(Williams和Zipser 1989)进行训练,其中只考虑目标前缀TD(语料库中所有D)的下一个动作值。由于大部分大的状态空间S+D保持不变,教师强制可以很快完成。
然而,教师强迫会导致序列生成中的暴露偏差问题(Ranzato等人,2015)。在训练期间,DQN仅暴露于地面真值状态(目标前缀),而在推断时,DQN仅访问其自身的预测。因此,在生成过程中,它可能与要生成的实际序列相差很远。因此,仅看到部分目标将导致有偏差的估计。为了训练更好的DQN,需要对状态空间SD\TD的其余部分进行更多探索。
为了弥补训练和推理之间的差距,我们使用自定义波束搜索生成样本,并将DQN本身作为启发式函数。通过使用从自身生成的样本更新DQN的迭代,曝光偏差将通过分布偏移逐渐消除。在这个搜索抽样过程中,我们采用了强化学习的几种技术(Ranzato等人,2015):
- 回放内存:在搜索过程中,我们在步骤2a的每次扩展后将遇到的状态放入回放内存;通过从存储器随机生成一批样本状态,周期性地训练估计器Q(s,AD)。
- OU噪声:作为勘探随机性的来源,减少6 Ornstein-Uhlenbeck噪声(Lillicrap等人。2016)添加到Q(s,AD)估计结果。
- 多个代理:搜索多个表以加速采样并用不同的样本填充内存。
- 训练前:在状态空间中信息量最大的部分TD的监督下,教师强制可以通过第一列Q(s,AD)帮助避免冷启动问题。
如§3.1所述,我们已经知道精确的对于每个状态a的最佳动作值q∗(s,a)。因此,搜索采样实际上是一个有监督的学习过程。
在§4.5中,我们将更详细地讨论为什么先前用于NL序列生成中暴露偏差的技术(Bengio等人,2015;Ranzato等人,2015)在我们的分析序列生成场景中不起作用。
4 实验
构建了PivotTable 语料库,用于训练和评估Table2Analysis框架。
4.1 PivotTable 语料库
数据透视表代表了表格分析中的一大类分析。它遵循分析语言的定义,并添加了另一个约束:分析中有两个维度,每个维度都对数据进行一次划分。在Excel数据透视表的术语中,一个字段称为“行字段”,另一个字段称为“列字段”。
搜集了包含74299个英语Excel电子表格文件(带有数据透视表),这些文件是从公共网站上爬取而来的。我们利用OpenXML提取源数据集及其数据透视表。
数据预处理:
- 排除具有极端大小(即大于128个字段)和不完整数据透视表(即0个度量值)的罕见(<1%)数据集后,语料库中仍有121593个源数据集,186169个数据透视表。
- 将具有多个度量值的数据透视表拆分为多个数据透视表,每个数据透视表都有一个度量值。
Excel文件按7:1:2的比例分配用于训练、验证和测试。超参数实验基于验证集,而与基线方法的总体准确性和有效性比较则使用测试集。
4.2 标记特征
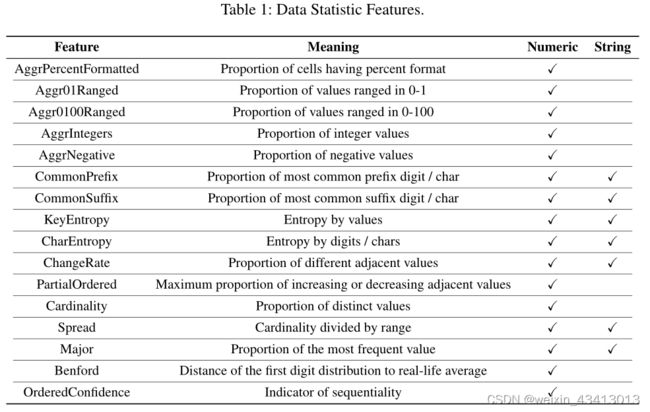
数据集的每个字段都有三种输入特征:语义嵌入、分类特征和数据统计。
- 语义嵌入:根据标记的名称(字段的标题字符串或函数的描述文本)来计算,使用BERT模型得到所有标记嵌入向量(768d)的平均输出值
- 类别特征:标记类型、聚合函数类型、字段类型、标记分割;诶性

- 数据统计特征:设计了16个特征,试图捕获重要的统计数据,这些统计数据可以为常见的分析建议提供信息。计算数字字段的所有特征,计算字符串字段的适用特征
4.3 DQN超参数
第一系列实验:DQN预训练
通过比较每个有效(s,a}对的精度、召回率和F1得分来选择DQN超参数
- 三种特征消融实验:使用所有特征,无数据统计特征,无语义嵌入特征。
- 两个DQN大小超参数实验:0.81M参数 4.60M parameters
- 负对数似然损失函数的四个类别权重设置:(1,1),(0.8,1)、(0.2,1)和(0.08,1),用于从q∗(s,a)。

结果: - 我们的输入嵌入层(为§3.2中分析语言的开放词汇表设计)即使在特征消除的情况下也能很好地工作。同时,语义嵌入比数据统计具有更高的特征重要性。
- 损失函数的类权重在精度和召回率之间进行权衡。(0.8,1)是F1得分最高的最佳点。因此,我们在接下来的章节中使用相应的预训练模型进行进一步的实验
4.4 搜索采样超参数
第二系列实验:搜索和采样过程
图4显示R@k对于6个超参数设置,在30个周期中的每个周期之后进行验证。R@k表示列表覆盖目标分析序列的表的比率。
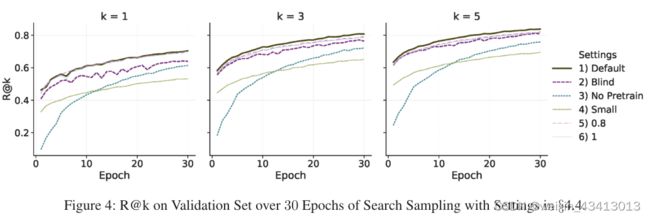
1)默认”设置,该设置从预训练的权重为0.8,1的大模型开始,并使用OU噪声进行探索。
- 清晰的增长线R@k表明搜索采样可以缓解我们在§3.4中讨论的分析序列生成的暴露偏差问题。
- 搜索采样中采用的技术改进了学习过程。E、 当比较1)和2)时,OU噪声优于盲探索,这表明减小的噪声可以更好地针对分布偏移进行正则化。在1)和3)之间的比较中也验证了使用预训练模型的有效性。
- 大模型的性能明显优于小模型(1 vs 4). 0.2是类权重的最佳值(1 vs 5,6)。
4.5 基线比较和总体准确性
评估了在测试集上基线方法和Table2Analysis的不同。
- 计划取样 :现有的采样方法DAD和MIXER被用于解决自然语言生成问题中的暴露偏差问题。在每个时间步,DAD以一定的概率将前一时间步模型的预测或真实数据作为输入。MIXER(Ranzato et al.2015)借鉴了DAD的思想,训练标记损失和序列损失,利用退火计划来控制两种损失之间的权衡。
由于不同的成功指标和分析语法限制,DAD和MIXER都不能直接应用于Table2Analysis。基于BLEU分数等宽松指标,他们都假设在序列中出现错误预测标记后,即将到来的预测仍应与剩余的真实值相匹配。这不适合现在的场景,例如,当目标数据透视表为 [ANA] [Sales] [SEP] [Region] [SEP] [Sum]时,如果生成了错误的前缀[ANA] [Sales] [SEP] [SEP],则DAD和MIXER将假定[SEP]是下一个正确的标记(目标中的第五个标记),这违反了精确二维细分的数据透视表语法。
提出了一种用于DQN训练的基线计划采样算法。以预先训练好的DQN为出发点,通过退火计划对DQN进行进一步训练,以对地面真值或模型生成的状态进行采样。
在每个epoch,前 l 个步骤采用地面真值状态,其余步骤采用模型生成的状态(以估计值作为权重进行采样)。l 会定期减小,以便随着训练的进行,对更多模型生成的状态进行采样。这使得模型能够更清楚地知道在推理过程中如何使用它。
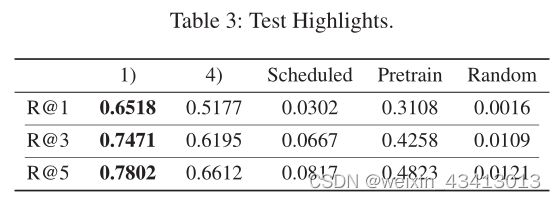
- 测试集对比:
- 实证研究:
- 为了更直观地理解推荐结果,下面我们列出了图1a中销售表运行示例的前5个推荐(按模型1)。

令人印象深刻的是,表2和表3也(部分)在基于原始实验记录的模型1的顶部建议中,这表明分析模型推荐语义有意义的分析。
对于推荐,我们在TOP1达到78%的召回率,TOP 5分别达到65%和78%
5 相关工作
5.1 分析推荐
对于数据分析和洞察建议,现有系统中通常使用协同过滤或统计显著性。
-
协同过滤:传统的协同过滤方法适用于根据用户历史记录在完全相同的表或少量具有对齐模式的表上提出建议的场景。本文中的场景用户概要文件/历史数据和全局模式都不可用。Table2Analysis框架可以看作是一种新的协同过滤方法,它通过学习共同的智慧,并通过神经网络在大量不同的表之间隐式地匹配共同的模式。
-
统计显著性方法是很有效的,但分析的语义意义也是非常重要的。现有的工作并没有很好地利用表格中通过人类自由文本呈现的语义信息。
5.2 结构化学习和预测
学习和生成结构(Learning and generating structures)有许多应用,其中许多与自然语言处理相关。
- Data to Text:从结构化数据生成不同类型的文本和文档
- Text to SQL:从自然语言生成查询
- Program Synthesis(程序合成):生成符合清晰规则和示例输入/输出对的程序。DeepCoder
模型架构:基于注意力的模型, seq2seq编码器-解码器体系结构
现有技术是为自然语言生成而设计的,不适用于分析序列生成,存在开放词汇表和暴露偏差问题。
5.3 深度强化学习
我们在Table2Analysis中使用的一些术语(action value, exploration vs. exploitation)和技术(如replay memory, OU noise)来自强化学习文献,尤其是首次成功应用于游戏环境的基于价值的无模型深度RL( value-based model-free deep RL)(Mnih et al.2015)。
搜索抽样过程深受强化RL工作的启发,如(Mnih等人2015年)和(Lillicrap等人2016年)。
二、Table2Charts
1 动机与贡献
1.1 动机
人们花费大量时间构建不同类型的图表,以支持对多维数据集(表格)的分析。数据查询(选择要分析的数据)和设计选择(如何可视化所选数据)都是在创建图表期间进行的。这个繁琐的过程需要数据分析和可视化工具方面的经验和专业知识。
许多工作建立机器学习模型,推荐数据查询和/或设计选择,如DeepEye、Data2Vis、Draclearn和VizML。只考虑了多类型任务,同时推荐几个主要类型的图表(如直线、条形图、散点图、饼图)。
没有解决单一类型的任务,每个任务都为给定的表推荐一种特定类型的图表,包括使用较少但有意义的次要图表类型(如面积图和雷达图)
1.2 贡献
- 学习人类图表创作智慧的Table2Charts框架
- 我们进行了规模最大的语料库训练(165k表格和266k图表来自Excel语料库),对图表推荐系统进行了各种评估(在Excel、Plotly和web表格语料库上)。
- 我们展示了学习共享表格表示(将表格字段编码为嵌入向量)以增强下游数据分析任务的可行性。
2 问题
2.1 问题抽象
通过填充图表语法模板,将单类型和多类型图表推荐任务制定为表到动作序列生成。
图表类型: 直线图、条形图、散点图和饼图以及面积图和雷达图。
2.1.1 图模板
图表可以被视为数据查询和设计选择的一系列操作。
创建图的基本操作: 选择/引用表字段和运行特定的图表命令/操作来组织和绘制所选的字段
定义:
-
操作空间/符号
字段引用标记 f
命令标记 C
图表类型标记 [line] 分割符[sep] -分割表格字段 操作G[Cluster] (意味着多个字段的值被并排放置), [Stack] (对于每个x轴的类别/标签逐个堆叠多个字段的值) -
图表语法模板
每种图表类型的语法模板可以被定义为Backus-Naur 形式:

f+ 和 f 是 y-字段,是在折线图、条形图、散点图和面积图中映射到y轴的字段,在饼图中映射到切片大小的字段,在雷达图中映射到径向轴的字段。多个y-字段表示多个值序列一起显示。
f* 和 f 是x-字段,是在折线图、条形图、散点图和面积图中映射到x轴,在饼图中映射到图例,在雷达图中映射到曲线极轴的字段。多个x-字段意味着连接。
模板定义中还包括硬约束,以限制启发式波束搜索(参见ğ3)。这些规则可以是任何手写的规则,比如字段映射到y轴的数据类型禁止是字符串类型。目前我们只设置了字段类型和数量的限制,剩下的让Table2Charts模型来学习。可以采用更多的规则,如Draco[13]中的规则作为硬约束来进一步改进框架。
还有更详细的图表美学[20]需要考虑,如形状、大小、颜色、线宽和类型等。主要关注数据查询的核心部分和设计选择如何选择和组合字段作为适当的图表类型的轴,以研究Table2Charts框架能否以数据驱动的方式学习常识。不考虑过滤、聚合或排序操作。
- 示例
[Bar] (Total Male Students) (Total Female Students) [SEP] (Program) [Stack].
2.1.2 图模板表到序列生成
表格到图表的推荐现在变成了如何有意义地填充图表模板的占位符。换句话说,如何学习生成遵循给定模板语法的动作标记序列(从左到右逐个标记)。
解决序列生成问题的一种常见方法是学习启发式波束搜索的估计函数。
给定表格D,不完整序列s,可以根据其对应的模板定义序列的有效动作空间 A D ( s ) A_D(s) AD(s)。根据语言建模模型,选择Q(s,a) = P(sa ∈ \in ∈ τ D \tau_D τD+| s,D)作为动作值函数,用于指导下一个动作标记a的选择。 τ D \tau_D τD+是所有目标图表序列(用户为D所采用的图表)及其前缀的集合。最优动作值参数为Q(s,a) 的学习目标:
2.2 存在挑战
推荐现实世界中常见的组合图表,应该考虑到效率、数据不平衡和表上下文的挑战。
- 成本分离:重复独立地为多类型任务和单类型任务设计、训练和部署模型,在内存和速度上都是低效的。
- 数据不平衡: 不同图表类型的可用数据高度不平衡。四种主要的图表类型(直线图、条形图、散点图和饼图)覆盖了98.91%的可用图表,而其他图表很少出现,因为非专业人士很难创建它们。由于小图表类型(面积和雷达)数据的缺乏,很难为它们建立高质量的模型。
- 表作为上下文:从表中选择和可视化数据不仅取决于数据统计,还取决于整个表上下文的语义。需要设计适当的模型,将表上下文纳入图表推荐。
3 Table2Charts
提出了Table2Charts框架,该框架从大量(表格、图表)对的语料库中学习常见模式,包括数据查询和设计选择,并为每个给定的表推荐图表。作为波束搜索的估计启发式算法,我们设计了一个编码器-解码器深度q值网络(DQN),它通过复制机制选择表字段去填充模板。Table2Charts框架如下图所示:

- 所有的推荐任务都共享一个编码器,但都有自己的解码器,这解决了单独的成本挑战。
- 在主要图表类型的多类型任务上使用混合学习对DQN进行训练。通过将编码器部分暴露给不同图表类型的不同源表,它学习包含表字段的语义和统计信息的共享表格表示。然后将预先训练好的表格表示传递给单类型任务的类型指定解码器,缓解了数据不平衡的问题。
3.1 填充模板: 带有复制机制的DQN
设计了DQN Q ( s , A D ) Q(s,A_D) Q(s,AD) 去近似 q ∗ ( s , a ) q*(s,a) q∗(s,a),输入所有表格字段 F D F_D FD和状态 s = s 0 . . . . s T − 1 s=s_0....s_{T-1} s=s0....sT−1,为所有动作a计算估计动作值,只有对于模板语法s的有效操作,才会被输出。
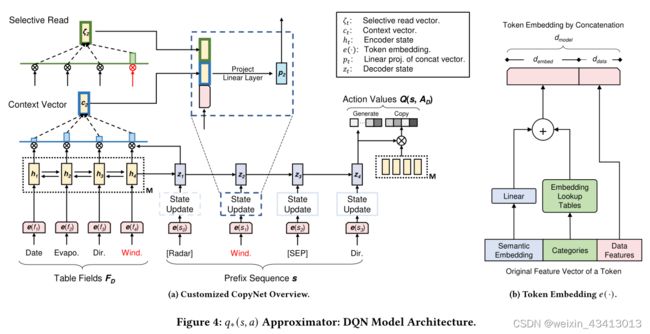
图4(a)是自定义的CopyNet结构,输出向量 Q ( s , A D ) Q(s,A_D) Q(s,AD)由两部分组成:Generate(用于命令)和Copy(用于字段)。
Generate包含命令C的动作值估计,它来自一个在最后解码器状态 z T z_T zT上应用了二进制softmax的全连接层。
Copy是字段可变长度的估计值,来自一个用于 z T z_T zT产生的二进制softmax和记忆(编码器输入的)的非线性转换。
编码器和解码器RNN部分分别采用双向和单向GRU[2]。M是字段 F D 在 F_D在 FD在双向GRU的输出。
解码状态 z t z_t zt被 p t p_t pt从之前的状态 z t − 1 z_{t-1} zt−1更新, p t p_t pt 是三部分串联向量的线性投影:选择性读取向量 ζ t \zeta_t ζt , 上下文向量 C t C_t Ct 和标记嵌入 e ( s t − 1 ) e(s_{t-1}) e(st−1)。选择性读取向量为一个字段标记从M中选择字段表示:

上下文向量是 z t − 1 z_{t-1} zt−1和M之间的线性注意力:
![]()
图4a中省略的标记嵌入部分如图4b所示。它是编码器的一部分,与解码器共享。将三种标记特征融合在一起:
1)使用FastText对标题名称进行语义嵌入;
2) 类别包括标记类型、字段数据类型等。;
3) 数据特征关于数据值的统计和分布信息。
我们的模型与原始CopyNet体系结构之间有几个不同之处:
- 命令标记的词汇较固定,表格字段中的词汇是无限的,命令与字段之间没有重叠。
- 输入标记首先通过嵌入(特征转换)网络而不是在NLP中嵌入矩阵的常用索引。
- 输出 Q ( s , A D ) Q(s,A_D) Q(s,AD)是每个动作的[0,1]值向量,而不是原始CopyNet中所有动作的概率分布。
我们设计的带有复制机制的DQN自然适合于从表字段生成结构的任务。它处理表字段的开放词汇表,并在表格表示(编码器)和模板填充(解码器)之间提供明确的划分。编码器部分接收整个表上下文并生成字段嵌入向量作为表格表示。解码器部分使用这些向量进行下一个动作标记估计。 Q ( s , A D ) Q(s,A_D) Q(s,AD)被Table2Charts用作波束搜索中的启发式函数,以生成多个序列。
3.2 修复暴露偏差:搜索采样
培训下一个标记估计器的传统方法是教师强制,只对用户创建的图表的前缀序列进行采样,并将估计的动作与实际用户动作进行比较。换言之,在老师的逼迫下,用于训练网络的唯一样本是来自(表格、图表)对语料库。
仅在教师强制的情况下,结果模型可能面临序列生成中常见的暴露偏差问题。在教师强迫过程中,该模型只暴露于基本真值状态(目标Prefjx);而在推理时,它只能获得自己的预测。因此,在生成过程中,它可能会偏离要生成的实际序列很远,从而导致有偏差的估计。
我们采用了另一文献中的搜索采样方法来缩小训练和推理之间的差距。受强化学习的启发,搜索采样过程采用 Q ( s , A D ) Q(s,A_D) Q(s,AD)作为启发式函数,在每个表上进行波束搜索。然后扩展状态(包括负样本,s 不在 τ D \tau_D τD+中)将存储在回放内存中,以便定期更新 Q ( s , A D ) Q(s,A_D) Q(s,AD)自身。在教师强迫的网络热身之后,这个过程非常有效。
3.3 混合训练和迁移学习
为了解决单独的成本和不平衡的数据挑战,将表格表示(编码器部分)可以与多个(一个多类型和六个单类型)任务共享。这将使编码器暴露于各种丰富的表格字段样本中,并减少部署任务模型的内存占用和推理时间。
我们提出了一个包含两个阶段的混合和传输范式:
- 混合训练:将所有主要图表类型的样本混合在一起,训练一个DQN模型,其混合编码器将转移到下一阶段,而整个混合DQN将用于多类型推荐任务。
- 迁移学习:保存前一阶段获取的混合编码器的参数。然后,对于每个单一类型的任务,仅使用此图表类型的数据,使用固定的共享编码器训练新的解码器。
与单独训练(仅使用该图表类型的数据)相比,Table2Charts中的混合和转移范式具有以下优势:
首先,占用的内存更小,推理速度更快,因为现在所有任务的DQN模型共享一个编码器,而单独训练仍然不能为每个任务有效地保留一个编码器。这解决了单独的成本挑战。其次,编码器所暴露的样本远远多于每种图表类型所能提供的样本。这不仅可以更好地学习和推广表格表示,还可以解决数据不平衡的问题。因此只有解码器部分(与较大的编码器部分相比较小)需要针对较小的图表类型进行调整。
4 实验
4.1 图表语料库
从公共网站上,我们收集了Excel 文件中165214个表格创建的266252个图表的大型语料库,并使用36888个表格中67617个图表的公共绘图语料库来验证Table2Charts框架在的有效性。
使用两个语料库Excel和Plotly进行训练和评估。Excel语料库由我们创建,用于训练和评估模型,但一些基线模型没有提供训练脚本。我们还对公共的Plotly语料库中的每个模型进行了评估,没有进行训练或优化。
- Excel
我们的图表语料库包含113390(42.59%)个折线、67600(25.39%)个柱状图、64934(24.39%)散点、17436(6.55%)饼图、1990(0.75%)面积和902(0.34%)雷达图。它们是使用OpenXML[11]从Excel电子表格文件中提取的,文件是从公共网站上爬网的。还采取了以下数据准备步骤:
1)单元格引用:清理电子表格单元格的位置引用,包含这些单元格引用的图表将从语料库中删除。
2)源表还原:在电子表格中,图表对象没有对其源表的引用。(仅保存直接单元格引用。)为了恢复其源表的区域和结构,我们根据其单元格引用实现了表检测算法[5]。如果未覆盖图表的引用,则会删除图表
3)组合图拆分:所有组合图都分为简单的图表。
4)表重复数据消除:为了避免重复表被分配到训练集和测试集中的数据泄露问题,表根据其模式进行分组8。然后在每个组中,合并相同的(表、图表)对。
5)下采样:重复数据消除后,每个模式中的表数量非常不平衡,0.23%的模式覆盖了这些表的20%。为了缓解这个问题,我们为每个唯一(模式、图表)对随机抽取最多10个唯一的表。
一共 98588个不同的方案,方案以7:1:2的比例随机分配用于训练、验证和测试。 - Plotly
我们还采用公共Plotly community feed语料库[8]和36888个样本表格,其中包含67617个图表(22644个折线图、20053个散点图、24204个条形图和716个饼图),用于在模型测试。为了提取(表、图表)对,按照VizML中的数据处理过程,我们下载了完整的语料库(205GB),并采用VizML中的数据清理代码来删除缺少数据的图表。此外,组合图拆分、表重复数据消除和向下采样的类似过程也应用于Excel语料库中的其余(表、图表)对。
4.2 多类型Reco任务的评估
对于多类型任务,使用Excel主要图表类型的样本对混合DQN进行训练。然后,将该混合训练的DQN用作波束搜索的启发式函数,以生成每个表的主要类型图的排序列表。
4.2.1 基线模型
我们将Table2Charts的召回和精确性框架与四条基线进行了比较:DeepEye[9]、Data2Vis[4]、Draclearn[13]和VizML[8]。
4.2.2 召回率大规模评估
在数据查询上,我们检查建议的字段是否与用户选择的字段匹配;
在设计选择上,我们评估模型是否可以在用户选择字段的情况下推荐正确的图表类型、字段映射和条形图分组操作。
评估指标top-k召回率显示了排名的图表建议列表如何与用户创建的图表相匹配.
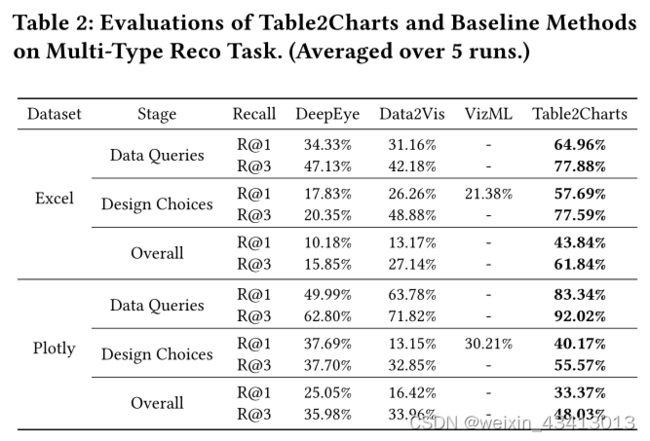
在Excel和Plotly语料库上,Table2Charts在所有三个阶段都优于基线方法。总体R@1和R@3在Excel上分别达到43.84%和61.84%(在Plotly上分别为33.37%和48.03%),大大超过基线(在Excel上至少翻了一番)。Plotly上数据查询阶段的召回次数高于Excel这是因为在Plotly语料库中,每个表只包含对应图表中使用的字段,从而降低了字段的选择难度。
4.2.3 人类准确率评估
此外,还对搜索引擎中500个频繁访问的web表格进行了人工评估,以验证所提出框架的准确性。
为评估推荐图表的质量,我们建立了一个标签网站,收集和比较Table2Charts、DeepEye和Data2Vis中排名前1的推荐的评级。10名从事web表可视化工作的专家以以下方式手动标记:对于给定的表,网站显示表内容以供阅读。3个模型推荐的3个图表将使用相同的可视化库呈现,并以随机顺序匿名显示。然后由专家标记三个1到5的整数评分

VizML和Draclearn不包括在内,因为VizML不能推荐包含数据查询的完整图表,而Draclearn的生成能力较弱。
为了检验统计显著性,我们进一步进行Wilcoxon符号秩检验[19],这是一种非参数统计假设检验,用于比较两个相关或匹配样本,以评估其总体平均秩是否存在差异(即,这是一种配对差异检验)。在95%的符合率水平下,将Table2Charts与DeepEye进行比较,并将Table2Charts与Data2Vis进行比较时,两者-Wilcoxon检验的值小于0.0001。这些结果表明,Table2Charts推荐的图表质量优于DeepEye和Data2Vis推荐的图表。
4.2.4 效率比较
平均而言,Table2Charts只需要12.14ms就可以为一个表生成图表建议,而DeepEye和Data2Vis的成本分别为48.19ms和210ms。总之,Table2Charts在性能和效率方面都优于基线方法。
4.3 单类型Reco任务的评估
对于所有图表类型,混合和迁移范式(Transfer)比单独训练(Separate)和仅混合(Mixed)DQN具有更高的召回率。Table2Charts通过学习共享表格上下文表示,可以很好地处理单一类型的任务。考虑到编码器和解码器部分设计为1.3M和0.5M参数的型号尺寸,Separate有10.8M参数,而Transfer只有4.3M参数。通过这种方式,Table2Charts减少了单独的成本,并提高了模型部署和推理的效率。
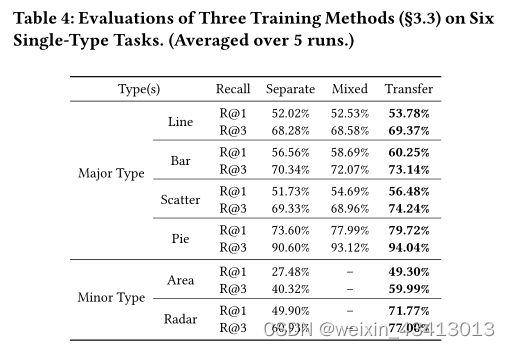
对于次要图表类型,表4中的Transfer和Separate的性能之间存在巨大差距。平均而言,使用混合和łTransfer范式R@1和R@3增长21.84%和17.87%。主要原因是共享编码器能够捕获和提取表上下文和字段语义的信息,并且小类型图的数量足以训练尺寸较小的解码器。因此,数据不平衡问题得到了解决。
4.4 推荐案例研究


当用户不知道从何处开始时,多类型混合模型使用推荐常见类型的图表:

混合模型成功地将图2a中的条形图推荐为top-1结果。2和3是一组可放在包含两个Y轴的柱状图。
多类型模型倾向于推荐通常由什么组成,因此可能缺乏多样性(例如,以上所有结果都是条形图)。因此,也可以将单一类型的建议放入列表中。(我们将如何将多类型和单类型模型的结果混合在一起,以获得平衡的建议,这将是未来的工作。)
当用户选择了特定的图表类型并需要自动帮助时,使用单一类型模型进行推荐。
4.5 探索表格表示
为了了解共享表格表示编码器生成的嵌入是如何工作的,从验证集中随机选择20000个字段(来自3039个表),并通过t-SNE 进行可视化
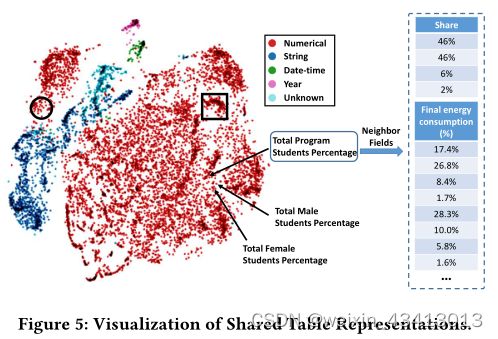
在图5的左侧,每个点表示一个字段,颜色表示其字段类型。在图中,我们可以看到字段类型信息是通过有意义的嵌入来学习的。例如,日期时间字段和年份字段十分紧密。一种可能的解释是,它们通常在折线图中用作x轴,因此具有类似的表示。
如图5所示,箭头标记的是与字段相对应的点,即总项目学生百分比。它们彼此接近,因为它们的记录值都是百分比。请注意他们比较紧密,因为它们的语义相似(包含性别信息)。一些示例邻居字段(基于余弦距离)如图5右侧所示,这些字段也是百分比。
图5中显示了另外两个集群的示例。在正方形区域中,有许多关于国家的字段。例如,有四个数字字段(来自四个表格),标题名称为美国、日本、英格兰和苏格兰,显示年度统计数据。在圆形区域中,许多字段扮演索引或ID的角色。例如,位于该集群中的四个字段(来自四个表),标题名为VerminID、index、category和Course Code,整数递增。这些整数失去了度量属性它们不用于数学运算/聚合。因此,这些字段非常接近图5中的字符串字段(深蓝色点)。
5 相关工作
5.1 分析推荐
对于一般的数据分析和来自表格的洞察建议,当前的系统主要基于协同过滤【10】、统计显著性【17】、启发式和历史匹配【6、12】或仅针对特定分析【24】的目标。他们很少考虑表上下文的语义,也很少解决推荐多种类型分析的挑战,这两种分析都是Table2Charts使用大规模人工创建的语料库以端到端的方式考虑的。
5.2 图表推荐
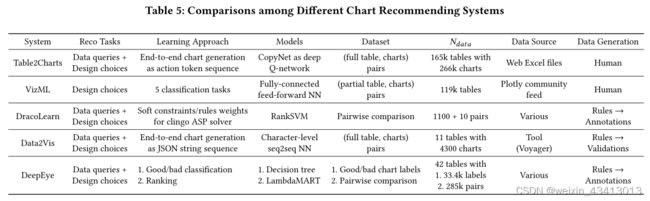
图表推荐是分析推荐中的一个重要分支。许多可视化推荐系统严重依赖于手工制作的启发式和规则,如Voyager[22]和Draclearn[13]。数据驱动方法在最近的基于学习的系统中越来越流行,如DeepEye[9]、Data2Vis[4]和VizML[8]。在ğ4.2中,我们讨论了DeepEye,Data2Vis、Draclearn和VizML作为基线。表5总结了它们与表2图表的更多差异。Draclearn和DeepEye都从低质量的数据中学习,并依赖于复杂的规则设计。Data2Vis来自Vega lite[15]JSON字符串的characterlevel seq2seq生成的原始模型。VizML只考虑设计选择,不处理数据查询。
5.3 结构化预测
填充图表模板并生成动作序列是一个结构化预测问题。有很多相关的工作,如NLQA和Text2SQL【18】。Table2Charts受到[7,24]的启发,设计了一种编码器-解码器体系结构,其中复制机制作为函数近似器。
5.4 表征学习和预训练
NLP中的单词嵌入[1]和预训练范式[3]启发我们学习多任务的预训练表表征[23]。字段嵌入对于更多的下游数据分析任务(包括推荐其他类型的分析)非常有用。
6 结论
在本文中,我们提出了Table2Charts框架,以解决同时考虑数据查询和设计选择的单类型和多类型图表推荐任务。通过从表字段复制,学习共享表表示,以提高所有图表类型的性能和效率。我们相信,所提出的技术在未来可以广泛用于表上的数据分析任务。