CVPR 2021 | 250 FPS!让实时语义分割飞起!重新思考BiSeNet
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:AI人工智能初学者

Rethinking BiSeNet For Real-time Semantic Segmentation
论文:https://arxiv.org/abs/2104.13188
代码(即将开源):
https://github.com/MichaelFan01/STDC-Seg
超强的实时语义分割新网络: STDC,表现SOTA! 性能优于BiSeNetV2、SFNet等网络,其中一版本性能高达97.0FPS/76.8%mIoU,代码即将开源!作者单位:美团
1 简介
BiSeNet已被证明在实时分割two-stream网络中是有效的。但是,其添加额外path以对空间信息进行编码的原理很耗时,并且由于缺少任务专用设计,因此从预训练任务(例如图像分类)中借用的主干可能无法有效地进行图像分割。
为了解决这些问题,作者提出了一种新颖且有效的结构,即通过消除结构冗余来缓解以上的耗时问题(Short-Term Dense Concatenate network)。具体来说,本文将特征图的维数逐渐降低,并将特征图聚合起来进行图像表征,形成了STDC网络的基本模块。在decoder中,提出了一个Detail Aggregation module将空间信息的学习以single-stream方式集成到low-level layers中。最后,将low-level features和deep features融合以预测最终的分割结果。

在Cityscapes上,在1080Ti上以250.4FPS的速度在测试集上实现了71.9%的mIoU,比最新方法快45.2%,在97.0FPS的情况下达到76.8%的mIoU,同时可以推断出更高分辨率的图像。
2 问题动机
为了更快的推理以达到实时的推理,很多的Researcher提出了很多的方法,也使用了很多轻量化的backbone,诸如DFANet、BiSeNetV1等模型;但是这些轻量化的Backbone主要是针对图像分类的设计,可能针对特定的语义分割任务性能并不是那么的好;
除此之外输入图像的分辨率似乎对于推理速度也有比较大的影响,但这样也很容易导致模型忽略目标边界和小物体的细节。

如图2(a)所示,为了解决以上问题,BiSeNet采用multi-path框架将low-level details和high-level semantics结合起来。然而,添加一条额外的path来获取low-level特征是很费时的,同时Auxiliary path也往往缺乏low-level信息的引导。
2.1 编码阶段
针对上诉问题作者设计了一种新的网络,目的是更快的推理速度、更具有可解释的结构和的现有方法对比更具竞争的性能。
首先,设计了一个新的结构Short-Term Dense Concatenate module模块(STDC模块),以通过少量的参数来获得Variant Scalable Receptive Fields。
其次,将STDC模块集成到U-net体系结构中,形成STDC Network,这一操作极大地提高了语义分割任务网络的性能。

如图3所示,将多个连续层的Feature maps连接起来,每个层对输入的图像/特征在不同的尺度和各自的域进行编码,从而实现多尺度特征表示。为了加快速度,逐步减小层的卷积核大小,同时在分割性能上的损失可以忽略不计。
2.2 解码阶段
在解码阶段,如图2(b)所示,采用Detail Guidance来引导low-level layers进行空间细节的学习,而不是使用额外的Path。
首先,利用Detail Aggregation模块生成详细的Ground-truth。
然后,利用binary cross-entropy loss和dice loss优化细节信息,将细节信息作为一种约束信息在推理时不需要。
最后,融合low-level layers信息和semantic信息预测语义分割结果。
3 Proposed Method
3.1 Design of Encoding Network
3.1.1 Short-Term Dense Concatenate Module
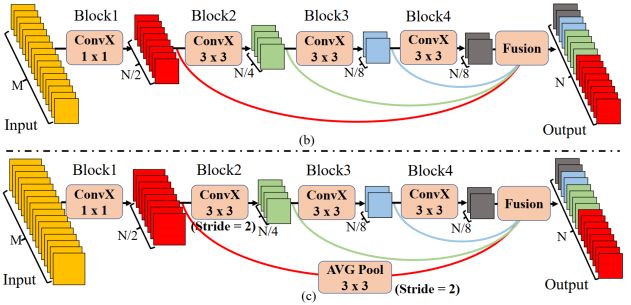
图4(b)和(c)展示了STDC模块的布局。具体来说,每个模块被分成几个子模块,用 表示第 块的运算。因此,第 块的输出如下:

其中 和 分别为第 块的输入和输出。 包括卷积层、BN层和ReLU, 是卷积层的内核大小。
在STDC模块中,第一个块的卷积核大小为1,其余的设置为3。给定STDC模块输出通道数为N;除了最后一个卷积层的卷积核数与前一个卷积层的卷积核数相同,其余第 块中卷积层的卷积核数均为 。
在图像分类任务中,More Channels in Higher Layers是一种常见的做法。但在语义分割任务中侧重于Scalable Receptive Field和Multi-Scale。Low-level layers需要足够的通道来编码Receptive Field较小的更细粒度的信息,而Receptive Field较大的high-level layers更注重high-level信息的引导,与Low-level layers设置相同的通道可能会导致信息冗余。
Downsample只在Block2中使用。为了获得更加丰富特征信息,作者选择通过skip-path cat 和 作为STDC模块的输出。在cat之前,要先通过3×3平均池化操作,将STDC模块中不同块的response maps降采样到相同的空间大小,STDC模块的最终输出为:
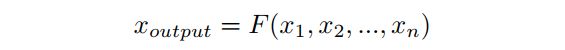
式中, 为STDC模块输出,F为方法中的融合操作, 是所有块的特征映射。考虑到效率,作者采用cat作为fusion操作。在本文中作者使用4个block构建STDC模块。

STDC Module的优势:
通过几何级数的方式精心调整块的卷积核的大小,从而显著降低了计算复杂度。
STDC模块的最终输出由所有块cat而成,保留了scalable respective fields和multi-scale information。
3.1.2 复杂度分析
给定输入通道维度 ,输出通道维度 ,则STDC模块parameter number为:
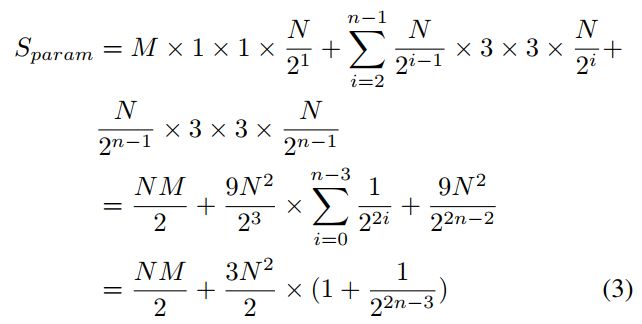
如式3所示,STDC模块的parameter number由预定义的输入输出通道维度决定,而block个数对parameter number的影响较小。特别是当n达到最大值时,STDC模块的参数数几乎保持不变,仅由M和n定义。
3.1.3 Network Architecture
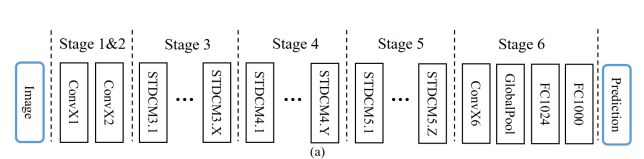

除输入层和预测层外,还包括6个阶段:
通常,Stage-1~5对输入的空间分辨率分别进行了2个下采样,Stage-6通过一个ConvX、一个全局平均池化层和两个全连接层输出预测logits。
Stage-1和Stage-2通常被是用于提取外观特征的low-level layers。为了追求效率,在Stage-1和Stage-2中每个阶段只使用一个卷积块,根据经验证明这是有效的。Stage-3、4、5中的STDC模块的数量在网络中是经过仔细调整的。在这些Stage中,每个Stage的第1个STDC模块使用stride=2的卷积块进行下采样,紧接着Stage的保持空间分辨率不变。
3.2 Design of Decoder
3.2.1 Segmentation Architecture
首先,使用预训练STDC网络作为编码器的Backbone,并采用BiSeNet的context path对context information进行编码。
如图3(a)所示,使用Stage-3,4,5分别生成了降样比为1/8,1/16,1/32的feature map。然后使用全局平均池化生成具有large receptive field的全局上下文信息。
采用U-shape结构对全局特征进行上采样,并将其与编码阶段的后2个阶段(Stage-4和Stage-5)的特征进行组合。
在BiSeNet之后使用Attention Refine模块来细化每2个阶段的组合特性。
在最终的语义分割预测中采用了BiSeNet中的Feature Fusion模块,将从Stage-3得到的1/8降采样特征与解码器得到的1/8降采样特征进行融合。作者认为这2个Stage的特征处于不同的特征表征层次。来自编码Stage的特征保留了丰富的细节信息,来自解码器的特征由于全局池化层的输入而包含了上下文信息。
具体来说,Seg Head包含一个3×3 Convon-Bn-Relu算子,然后进行1×1卷积,得到输出维数N(类的个数)。采用Cross-Entry Loss-OHEM优化语义分割学习任务。
3.2.2 Detail Guidance of Low-level Features

与相同下采样比的backbone low-level layers(Stage-3)相比,spatial path可以编码更多的spatial细节,如边界、角等。在此基础上,本文提出了一个细节引导模块来引导low-level layers以单流方式学习空间信息。作者将细节预测建模为二值分割任务。
首先,利用Laplacian算子对分割后的Ground-truth进行细节映射detail map Ground-truth(如图5(c)所示)。在Stage-3中插入detail Head生成detail feature map。
然后,使用detail ground-truth作为detail feature map的引导来指导low-level layers学习spatial detail feature。如图6(d)所示,经过detail引导的feature map比图6(c)所示的结果可以编码更多的空间细节。

最后,将学习到的细节特征与解码器深度块的上下文特征融合,进行分割预测。
1、Detail Ground-truth Generation
通过detail Aggregation模块从语义分割ground truth中生成binary detail ground-truth,如图5(c)中虚线蓝框所示。这种运算可以通过2-D拉普拉斯核卷积和可训练的 卷积来实现。
首先,使用如图5(e)所示的Laplacian算子生成不同步幅的soft thin detail feature map以获取多尺度细节信息。
然后,我们将细节特征映射上采样到原始大小,并融合一个可训练的11 - 1卷积来进行动态重加权。
最后,利用边界和角点信息采用阈值0.1将预测细节转化为最终的binary detail ground-truth。
2、Detail Loss
由于detail pixels的数量远少于非detail pixels,很明显detail预测是一个类不平衡问题。由于加权交叉熵总是导致粗糙的结果,于是作者采用binary cross-entropy和dice loss联合优化细节学习。dice loss衡量的是预测map和ground-truth之间的重叠。此外,它对前景/背景像素的数量不敏感,这意味着它可以缓解类不平衡的问题。因此,对于高度H、宽度W的预测detail图,detail loss 公式如下:

其中 为预测的细节, 为相应的细节ground-truth。 为binary cross-entropy loss, 为dice loss:
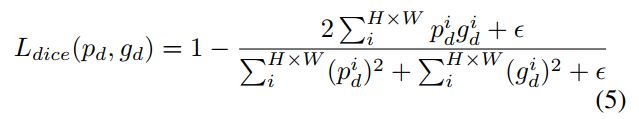
如图5(b)所示使用Detail Head生成Detail map,该map引导浅层对空间信息进行编码。Detail Head包括一个3×3 con-bn-relu算子,然后是一个1×1卷积来得到输出的Detail map。
在实验中Detail Head被证明是有效的增强特征表示。请注意,此分支将在推断阶段被丢弃。因此,这种侧信息可以在不耗费任何推理代价的情况下轻松地提高分割任务的准确性。
4. 实验
4.1 ImageNet实验
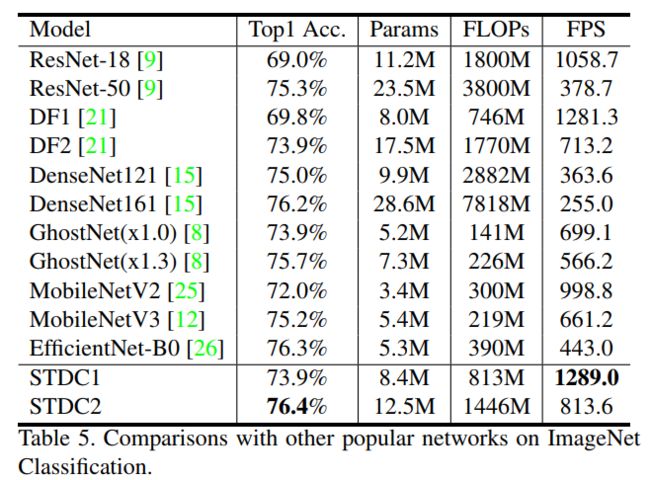
本文与最新的轻量级backbone进行对比,之类与常用的ResNet50进行一下比较可以看出来STDC2精度上比ResNet50高出1.1个百分点,但是速度是ResNet50的2.5倍,FLOPs是ResNet50的约1/3.
4.2 语义分割实验

从上表可以看出来,尽管mIoU在Cityscapes数据集不是最高的,甚至还不如比较火的DANet,但是速度却是最快的,居然达到了250FPS。只能说实在是香!!!
4.3 可视化对比

论文PDF和代码下载
后台回复:STDC,即可下载上述论文PDF
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!图像分割交流群成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看