linux0.11内核分析之进程调度
linux0.11内核分析之进程调度
文章目录
- linux0.11内核分析之进程调度
-
-
-
- 引入
- 进程调度策略概述
-
- 1、first come first serve(FCFS)
- 2、高优先级优先
- 3、时间片轮转法
- 进程调度相关源码阅读
-
- 1、schedule
- 2、sys_pause
- 3、system_call
- 进程调度策略特点分析
- 进程调度流程图
-
-
引入
对于一个操作系统小白来说,最重要系统性能的衡量指标就是——流畅度,也就是俗称的“卡不卡”,而这个系统性能背后的支撑就是linux内核的重要组成部分——进程的调度。
进程调度策略概述
进程调度的策略常见有三
1、first come first serve(FCFS)
顾名思义,即先来先服务。指的是每次选择一个最先进入进程队列的进程,为其分配CPU资源,使其进入运行状态,该进程将一直运行至完成或者事件发生使其进入阻塞状态。
-
优点:简单明了
-
缺点:如果进程需要长时间占用CPU资源,则在进程执行期间,别的进程将会一直无法运行,这样的策略将会导致“卡顿”如同家常便饭。
2、高优先级优先
对进程划分优先级,每次选择一个优先级最高的进程运行,低优先级的进程需要等到高优先级的进程运行完成方可获得CPU资源。而该策略又分为抢占式和非抢占式两种策略,区别是当前进程运行的时候能否被后来的高优先级进程打断。
- 优点:照顾紧迫型作业,让“好钢用在刀刃上”
- 缺点:如果队列中一直有新的高优先级进程进入,低优先级的进程可能永远不会被执行;如果低优先级进程访问了高优先级进程所需的共享资源,则高优先级进程由于资源被占用处于阻塞态,低优先级由于优先级低无法获得CPU资源,可能高优先级进程永远无法获得资源。
3、时间片轮转法
给就绪进程队列中的每一个进程分配一定量的时间片,当执行的时间片用完时,把进程送往就绪队列的末尾,再将CPU资源分配给队列中新的队首进程。
- 优点:雨露均沾,系统能对每一个进程做出响应
- 缺点:时间片的大小难以确定,需要经过多次实验方可确定最优值,保证既使得每一个进程都获得一定的CPU执行时间,又体现进程的执行效率
进程调度相关源码阅读
1、schedule
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
/* check alarm, wake up any interruptible tasks that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING;
}
/* this is the scheduler proper: */
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
}
switch_to(next);
}
进程调度的策略就放在这么一个小小的schedule函数中,函数的主体分为两部分。
首先是**检查所有进程的定时器,如果发现有进程的定时器已经达到目的时间了,则唤醒进程。**将进程的pid保存在next变量中。
其次是对当前所有进程进行遍历,并记录所有就绪的进程的状态与时间片数量,从中挑选出就绪且时间片最大的进程。此时next的值为0
如果没有一个进程处于就绪状态,则为将所有进程的时间片右移一位,随后将时间片的值加上进程的优先级。然后将CPU的使用权交给pid为next的进程,完成调度。
2、sys_pause
int sys_pause(void)
{
current->state = TASK_INTERRUPTIBLE;
schedule();
return 0;
}
对于sys_pause函数,内核的实现较为简单。首先,将当前进程的状态置为可中止的睡眠态,随后调用schedule函数进行进程调度
3、system_call
system_call:
cmpl $nr_system_calls-1,%eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx # push %ebx,%ecx,%edx as parameters
pushl %ebx # to the system call
movl $0x10,%edx # set up ds,es to kernel space
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # fs points to local data space
mov %dx,%fs
call sys_call_table(,%eax,4)
pushl %eax
movl current,%eax
cmpl $0,state(%eax) # state
jne reschedule
cmpl $0,counter(%eax) # counter
je reschedule
reschedule:
pushl $ret_from_sys_call
jmp schedule
在内核调用系统函数的时候,会用一个trap指令“INT 0x80”引发一个内部中断,随后调用system_call函数来进行处理(系统函数的调用),在system_call中,进程的状态从用户态转换为核心态,system_call函数根据保存在esp寄存器中的系统调用号到sys_call_table中寻找对应的系统调用函数并执行。
值得注意的是,在system_call函数的末尾,有两条条件跳转语句,指向同一个地址——reschedule,而该地址的内容是:**首先,把ret_from_sys_call地址压入栈中作为返回值,随后跳转到schedule进行进程的调度。**在完成调度后,跳转到ret_from_sys_call进行寄存器状态的恢复并返回到用户态。
为什么需要在system_call函数的末尾进行进程的调度呢?因为在系统调用函数执行时,可能会改变进程的运行状态,但是此时贸然调用schedule可能会破坏当前函数的栈状态,所以等到system_call执行结束后,检测进程的运行状态(state)和剩余时间片(counter),如果发现进程已经进入阻塞状态或者时间片已经消耗殆尽时,再执行一次schedule实现进程的调度。
进程调度策略特点分析
看完了源码,我们来分析进程调度策略的特点:
-
0号进程是系统的第一个进程,在所有进程时间片耗尽或者陷入阻塞状态的时候,把0号进程唤醒有利于系统的正常运行
-
在系统调用等事件改变了进程的时间片或进程状态时,调用调度函数及时完成系统资源在进程之间的交接
-
当所有进程处于阻塞态时,给进程分配时间片。但为了体现进程的优先级,分配的时间片与进程的优先级直接相关。而为了避免进程一直处于阻塞态,获得的时间片过大,使用右移操作把时间片的值限定在进程优先级的两倍
-
当多个进程处于就绪态时,通过比较时间片的大小进行系统资源的分配,结合上一条特性,既使得了低优先级的进程不至于被搁置太久,又保证了高优先级的进程能够及时获得系统资源
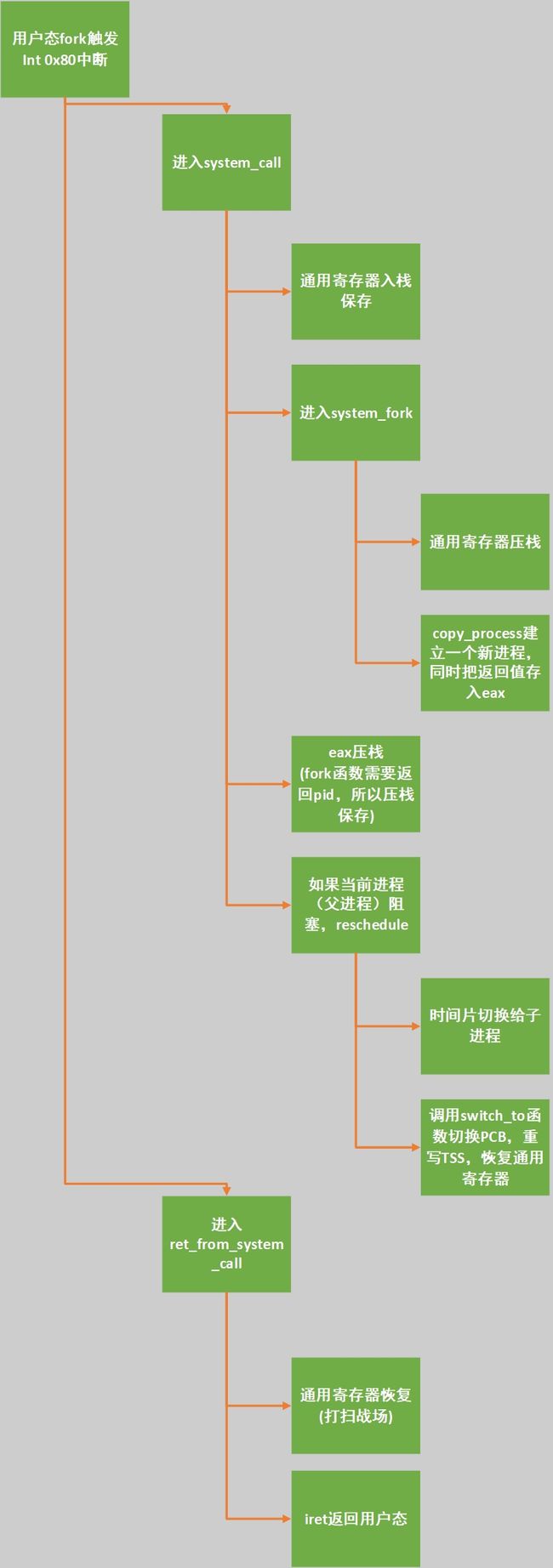
进程调度流程图
最后,千言万语不如一张流程图,贴上一张自己做的图,思路来自这篇优秀的博文
以fork函数为例: