KNN算法实战
目录
1.1最近邻算法
1.2 K-邻近算法
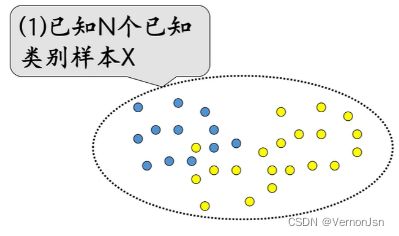
2.算法步骤:
3. KNN算法实战
3.1 实例分析算法步骤
3.2程序实现
4. KNN算法的探讨
4.1 算法优点
4.2 算法缺点
1.1 最近邻算法
最近邻算法(NN):为了判定未知样本的类别,以全部训练样本作为代表点计算位置样本与所有训练样本的距离,并以最邻近这的类别作为决策位置样本的唯一依据。但是最近邻算法作为分类原则是存下明显缺陷的。
最近邻算法的缺点---对噪声数据过于敏感
为了解决这个额问题,我们可以把位置样本周边的多个样本算在内,扩大与决策的样本量,以避免个别数据直接决定决策结果。
1.2 K-邻近算法
K近邻算法思想:K-近邻算法是最紧邻算法的一个延伸。基本思路是:选择未知样本一定范围内确定个数的K个样本,该K个样本大多数属于某一类型,则未知样本判定为该类型。
2.算法步骤:
2.1 KNN算法步骤:


![]()

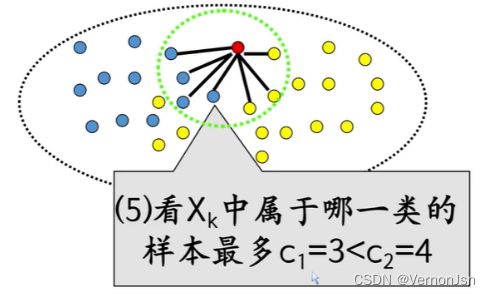
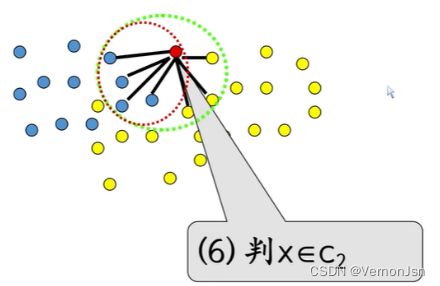
2.2 KNN算法步骤:
◆计算距离:计算测试对象与训练集中的每个对象的距离。距离的度量有很多种计算方法,如欧氏距离(欧几里得距离)和曼哈顿距离等。
欧式距离:

◆选取近邻:将距离升序排序,选择距离最近的K个样本点。
◆分类决策:根据这K个近邻归属的类别,采用多数表决的方法,由这K个点来投票决定测试对象归为哪一类。
2.3 KNN算法步骤:
Step.1--准备数据,分析数据,对数据进行预处理,归一化处理;
Step.2--划分训练集和测试集;
Step.3--计算未知样本和每个训练集样本的距离;
Step.4--设定参数,k值;
Step.5--将距离升序排列;
Step.6--选取距离最小的k个点;
Step.7--统计前k个最近邻样本点所在类别出现的次数;
Step.8--多数表决,选择出现频率最大的类别作为未知样本的类别。
2.4 KNN算法中的K
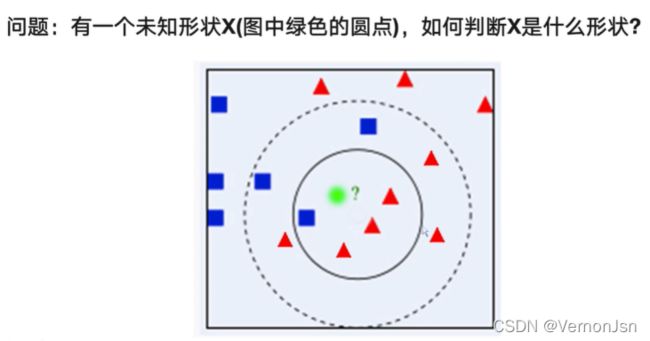
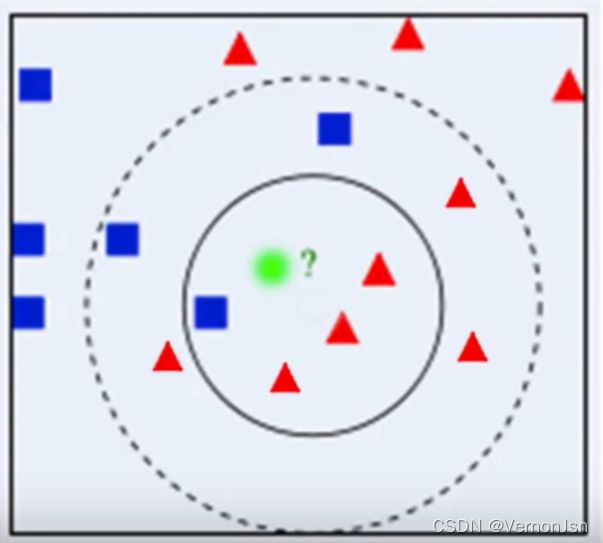
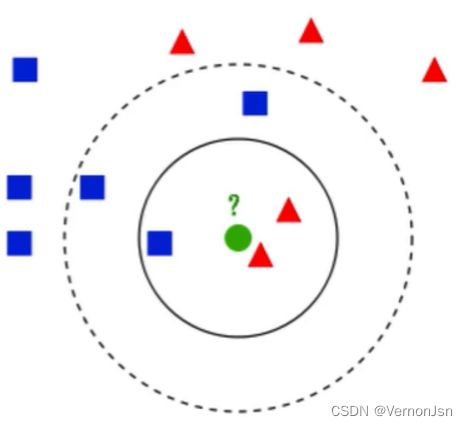
问题:有一-个未知形状X(图中绿色的圆点),如何判断X是什么形状?
若K=3,判定绿色待分类点属于红色的三角形- -类。
若K=5,判定绿色待分类点属于蓝色的正方形一类。
问:“ 分类器何种情况下会出错?”或者“答案是否总是正确的?”
答案是否定的,分类器并不会得到百分百正确的结果。
分类器的性能也会受到多种因素的影响,比如K的取值就在很大程度上影响了KNN分类器的预测结果,还有数据集本身也会影响
为了测试分类器的效果,我们将原始数据集分为两部分,训练集和测试集。通过大量的测试数据,我们可以得到分类器的错误率,即分类器给出错误结果的次数除以测试执行的总数。同时,我们也不难发现,KNN算法没有进行数据的训练,直接使用未知的数据与已知的数据进行比较,得到结果.因此,可以说KNN算法不具有显式的学习过程.
3. KNN算法实战
3.1 实例分析算法步骤
Step.1--准备数据,分析数据,对数据进行预处理;

Step.2--划分训练集和测试集;

Step.3--计算未知样本和每个训练集样本的距离;
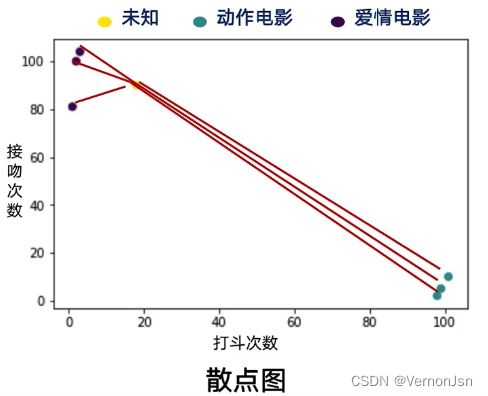
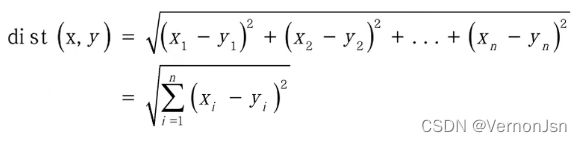
Step.5-将距离升序排列;
(1) Beautiful W oman
(2) He's Not Really into Dudes
(3) California Man
(4) Kevin Longblade
(5) Robo Slayer 3000
(6) Amped II
Step.6- .选取距离最小的k个点;
K=3
( 1 ) Beautiful Woman
(2) He's Not Really into Dudes
(3) California Man
Step.7-统计前k个最近邻样本点所在类别出现的次数;
爱情电影: 3次;
动作电影: 0次。
Step.8--多数表决,选择出现频率最大的类别作为未知样本的类别。
未知电影属于:爱情电影。
3.2程序实现
(1)构建数据集
import numpy as np
import matplotlib.pyplot as plt
fight=[3,2,1,101,99,98]
kiss=[104,100,81,10,5,2]
filmtype=[1,1,1,2,2,2]
plt.scatter(fight,kiss,c=filmtype)
plt.xlabel('fight')
plt.ylabel('kiss')
plt.title('movie)
plt.show()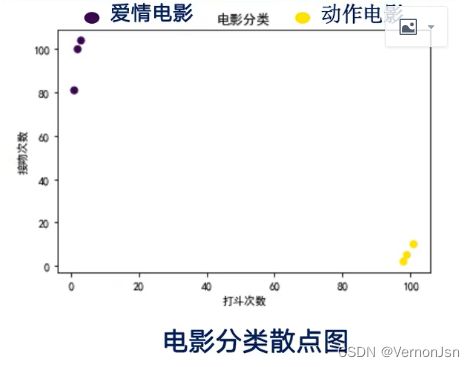
x=np.array([fght,kiss])
x=x.T
y=np.array(filmtype)
print(x)
print(y)结果:

(2)计算未知样本和每个训练集样本的距离
欧氏距离:
Python代码:
#求【18,90】与各个数据点的距离
xx=np.array([18,90])
dist+(((x-xx)** 2).sum(1))**0.5
print(dist)
得出结果:
[1.35273929 1.34144385 1.34403348 1.60758748 1.61054148 1.61260727]
(3)将距离升序排序
Python代码:
sortedDist=dist.argsort()
print(sortedDist)
得到排序索引:
[1 2 0 3 4 5]
(4) 选取距离最小的k个点,统计前k个点所在类别出现的次数
Python代码:
k=4
classCount={}
for i in range(k):
voteLabel = y[sortedDist[i]] #得到排序后的标签
classCount[voteLabel] =classCount.get(voteLabel,0)+1 #不同标签统计几次
print('class: count',classCount)
得到结果:例如1表示爱情片,统计了三次;2表示动作片统计了1次
class: count {1: 3, 2: 1}
(5)多数表决,输出结果
Python代码:
maxType=0
maxCount=- 1
for key,value in classCount.items():
if value>maxCount:
maxType=key
maxCount=value
print('output: ',maxType)得出结果:属于爱情片
output: 1
2.封装KNN函数
函数说明: KNN算法分类器
输入参数:
inX -未知样本(测试集)
dataSet -训练样本的特征矩阵(训练集)
labels -训练集分类标签向量
k -选择距离最小的k个点
返回:
maxType -分类结果
Python代码:
KNN函数部分:
import numpy as np
def knn(inX,dataSet,labels,k):
dist=(((dataSet-inX)**2).sum(1))**0.5
sortedDist=dist.argsort()
classCount={}
for i in range(k):
voteLabel = labels[sortedDist[i]]
classCount[voteLabel]=classCount.get(voteLabel,0)+1
maxType=0
maxCount=-1
for key,value in classCount.items():
if value > maxCount:
maxType = key
maxCount = value
return maxType测试部分:
import numpy as np
import matplotlib.pyplot as plt
import knn as K
fight=(3,2,1,101,99,98)
kiss=(104,100,81,10,5,2)
filmtype=(1,1,1,2,2,2)
plt.scatter(fight,kiss,c=filmtype)
x=np.array([fight,kiss])
y=np.array(filmtype)
x=x.T
print(x)
print(y)
xx=np.array([18,90])
result = K.knn(xx,x,y,4)
print('result:',result)3.3 案例实战
3.约会网站配对数据
海伦女士一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的任
选,但她并不是喜欢每-一个人。经过一番总结,她发现自己交往过的人可以进行如下分类:
●不喜欢
●魅力一般
●极具魅力
海伦收集约会数据已经有了一段时间, 她把这些数据存放在文本文件datingTestSet.txt中,
每个样本数据占据一-行, 总共有1000行。海伦收集的样本数据主要包含以下3种特征:
●每年出行的里程数
●玩游戏的时间占比
●每周吃冰淇淋的公升数
数据集解释:
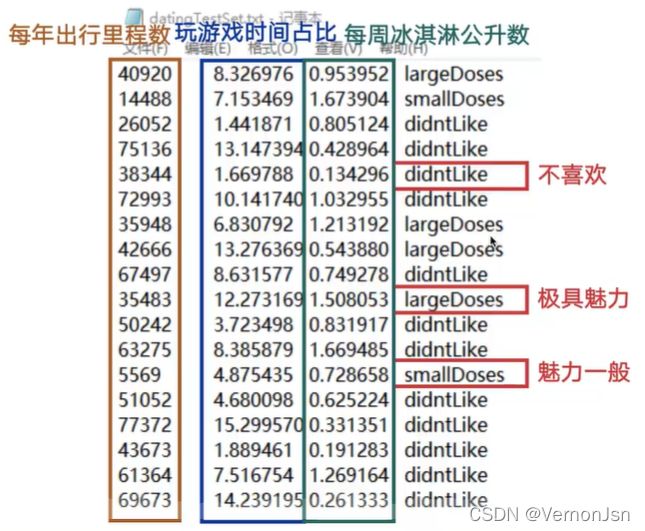
(1)读取数据集
将样本数据的格式转换为分类模型可以接收的格式。需要将数据分为特征矩阵和对应的分类标签向量。
file2matrix函数说明:打开并解析文件,
对数据进行分类: 1代表不喜欢,2代
表魅力-般,3代表极具魅力
输入参数:
filename-文件名
返回:
returnMat -特征矩阵
classLabelVector -分类标签向量
Python代码:
import numpy as np
def file2matrix(filename):
fr = open(filename)#打开文件
#初始化
numberOfLines = len(fr.readlines())#读出文件多少行
returnMat = np.zeros((numberOfLines,3))#文件总共多少行,加3列的矩阵
classLabelVector= []
fr = open(filename)
index= 0#定位到第一行
for line in fr.readlines():#读出所有行
line = line.strip()#清理每行数据,空格符
listFromLine = line.split('\t')#切分数据
returnMat[index,:] = listFromLine[0:3]#读出一行,切前三列
#将文本类型转为数字1,2,3
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1]== 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat,classLabelVector
datingDataMat,datingLabels=file2matrix('datingTestSet.txt')
print(datingDataMat)
print(datingLabels)得出结果:

(2)分析数据
# (2)分析数据
# Python代码:
import numpy as np
import matplotlib.pyplot as plt
datingDataMat,datingLabels=file2matrix('datingTestSet.txt')
plt.scatter(datingDataMat[:,0],datingDataMat[:,1],c=datingLabels)#横轴是里程数纵轴是游戏时间
plt.show()
得出结果:

(3)数据归一化处理
下表提取了四组样本数据,计算样本1和样本2之间的距离,使用欧式距离公式:


每年出行里程数对于计算结果的影响远远大于表中其他两个特征
归一化的处理方法有很多种,如0-1标准化, Z-score标准化 ,sigmoid压缩法等等。
0-1标准化公式:
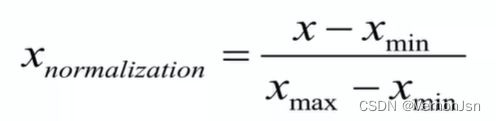
autoNorm函数说明:对数据进行归- -化
输入参数:
dataSet -特征矩阵
返回:
normDataSet -归-化后的特征矩阵
Python代码:
import numpy as np
def autoNorm(dataSet):
minVals = dataSet.min(0)#0表示按列获取最小值
maxVals = dataSet.max(0)#按列获取最大值
normDataSet = np.zeros(dataSet.shape)#创建于原数据同行同列的数据
normDataSet = (dataSet - minVals)/(maxVals-minVals)#归一化
return normDataSet
#测试
dataSet=autoNorm(datingDataMat)
print(dataSet)得到归一化后的特征矩阵:
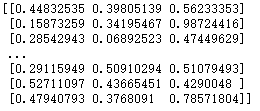
(4)测试KNN分类器模型
Python代码:
# (4)测试KNN分类器模型
import numpy as np
import knn as K
dataSet,labels=file2matrix('datingTestSet.txt')
normalSet= autoNorm(dataSet)
m=0.8#表示训练集占总共集合的占比
dataSize= normalSet.shape[0]
print('数据集总行数: ',dataSize)
trainSize=int(m* dataSize)
testSize=int((1-m)* dataSize)
k=5
results=[]
error=0
for i in range(testSize):
results=K.knn(normalSet[trainSize+i-1,:],normalSet[0:trainSize,:],labels[0:trainSize],k)
if results!=labels[trainSize+i-1]:
error=error+1
print('错误率: ',error/testSize)得出结果:
数据集总行数: 1000 错误率: 0.05527638190954774
可以改变函数训练集与测试集的占比( 改变变量m)和分类器k的值,观察检测错误率是否随着变量值的变化而变化。
4. KNN算法的探讨
观察下面的例子,我们看到,对于位置样本X,通过KNN算法,我们显然可以得到X应属于红点,但对于位置样本Y,通过KNN算法我们似乎得到了Y应属于蓝点的结论,而这个结论直观来看并没有说服力。

由上面的例子可见:该算法在分类时有个重要的不足是,当样本不平衡时,即:一个类的样本容量很大,而其他类样本数量很小时,很有可能导致当输入一个未知样本时,该样本的K个邻居中大数量类的样本占多数。 但是这类样本并不接近目标样本,而数量小的这类样本很靠近目标样本。这个时候,我们有理由认为该位置样本属于数量小的样本所属的一类,但是,KNN却不关心这个问题,它只关心哪类样本的数量最多,而不去把距离远近考虑在内,因此,我们可以采用权值的方法来改进。 和该样本距离小的邻居权值大,和该样本距离大的邻居权值则相对较小,由此,将距离远近的因素也考虑在内,避免因一个样本过大导致误判的情况。
和该样本距离小的邻居权值大,和该样本距离大的邻居权值则相对较小,由此,将距离远近的因素也考虑在内,避免因一个样本过大导致误判的情况。
思考:
从算法实现的过程大家可以发现,该算法存两个严重的问题:
第一个是需要存储全部的训练样本
第二个是需要进行繁重的距离计算量。
4.1 算法优点
●简单好用,容易理解,易于实现,既可以用来做分类也可以用来做回归;
●可用于数值型数据和离散型数据;
●适合对稀有事件进行分类;
●特别适合于多分类问题(对象具有多个类别标签)。
4.2 算法缺点
(1)样本库容量依赖性较强;
样本小时误差难以控制
(2) 无法给出数据的基础结构信息;
无法给出数据的内在含义,无法知晓平均实例样本和典型实例样本具有什么特征。
(3) 分类计算量大,速度慢,空间复杂度高;
KNN算法的计算复杂度和存储空间会随着训练集规模和特征维数的增大而迅速增加。对每- -个待分类的未知样本都要计算它与全体训练集样本点的距离,才能求出它的K个最近邻点。
(4)K值不好确定;
K值选择过小,得到的近邻数过少那么将会对数据中存在的噪声(特例)过于敏感,会降低分类
精度,容易发生过拟合;K值选择过大,并且待分类样本属于训练集中数据较少的那类,那么在选择K个近邻的时候,实际.上并不相似的数据也会被包含进来造成噪声增加而导致分类效果降低,容易发生欠拟合。
思考:KNN算法有哪些改进策略?
资源下载:KNN算法实战.zip-Python文档类资源-CSDN下载