机器学习入门 06 —— Seaborn使用
文章目录
- 系列文章
- 6 Seaborn
-
- 6.1 绘制单变量分布
- 6.2 绘制双变量分布
-
- 1 绘制散点图
- 2 绘制二维直方图
- 3 绘制核密度估计图
- 4 绘制成对的双变量分布
- 6.3 绘制分类数据图
-
- 1 类别散点图
-
- striplot()
- swarmplot()
- 2 箱型图和小提琴图
-
- 箱型图
- 小提琴图
- 3 条形图和点图
-
- 条形图
- 点图
- 6.4 案例:NBA球员数据分析
-
- 1 基本数据介绍
- 2 获取数据
- 3 数据分析
-
- 数据相关性分析
- 数据排名分析
- 球员薪资和年龄分布
系列文章
机器学习入门 01 —— 机器学习概述
机器学习入门 02 —— 环境搭建(Jupyter Notebook 及扩展库的安装与使用)
机器学习入门 03 —— Matplotlib使用
机器学习入门 04 —— Numpy使用
机器学习入门 05 —— Pandas使用
机器学习入门 06 —— Seaborn使用
6 Seaborn
Seaborn也是用于绘制图形的,Matplotlib虽然已经是比较优秀的绘图库了,但它的API使用比较复杂,而Seaborn是基于Matplotlib核心库进行了更高级的API封装,可以轻松绘制更漂亮的图形,其配色更加舒适、图形样式更加细腻。
如果没有安装,可以通过命令
pip3 install seaborn安装。我是使用了Anaconda进行包管理,所以基本上库都安装过了。可以看我另一篇博客,使用Anaconda管理Python包要方便很多。
Seaborn的使用非常简单,它不会像Matplotlib那样给你提供很多函数,通常我们根据变量的数目来决定使用哪个函数,单变量distplot()、双变量jointplot()。
设置主题 sns.set_style("whitegrid")
1.darkgrid(灰色网格)
2.whitegrid(白色网格)
3.dark(黑色)
4.white(白色)
5.ticks(十字叉)
white和ticks两种主题都会包含没有必要的上边框和右边框。我们可以用despine()函数去除。
# 去掉多余的线
sns.despine()
6.1 绘制单变量分布
单变量顾名思义,就是只有一个变量,因此数据也是Series类型的。Seaborn的函数distplot()默认绘制的是带有核密度估计曲线的直方图。(核密度估计曲线不懂没关系,后面看例子就明白了)
seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None, color=None)
- a:表示要观察的数据,可以是Series、一维数组、列表等。
- bins:用于控制条柱的数量。
- hist:是否绘制直方图。
- kde:是否绘制高斯核密度估计曲线。可以更加直观的看出数据分布特征。
- rug:是否在轴上绘制rugplot。
下面通过例子来简单看看。
import numpy as np
import seaborn as sns
np.random.seed(0) # 确定随机种子,使得每次随机的数字相同以便观察
array = np.random.randn(100) # 生成100个随机数的数组
# 绘制直方图
sns.distplot(array, bins=10, hist=True, kde=True, rug=True)

6.2 绘制双变量分布
双变量也很简单,只需使用jointplot()就可以绘制,默认是绘制双变量散点图。
seaborn.jointplot(x, y, data=None, kind='scatter', stat_func=None, color=None, ratio=5, space=0.2, dropna=True)
- kind:表示绘制图形的类型,默认散点
scatter,其他还有直方图hex、核密度估计曲线kde、 - stat_func:是否显示关系统计量。
- color:绘图元素的颜色。例如 color='r’就是红色。
- size:图的大小。
- ratio:中心图与上侧、右侧图的比例,值越大,中心图占比越大。
- space:中心图与上侧、右侧图的间隔。
import numpy as np
import pandas as pd
import seaborn as sns
sns.set() # 导入seaborn的默认设置
data = pd.DataFrame({'x':np.random.randn(500), 'y':np.random.randn(500)}) # 生成随机DataFrame
1 绘制散点图
sns.jointplot(x="x", y="y", data=data)

2 绘制二维直方图
sns.jointplot(x="x", y="y", data=data, kind='hex')
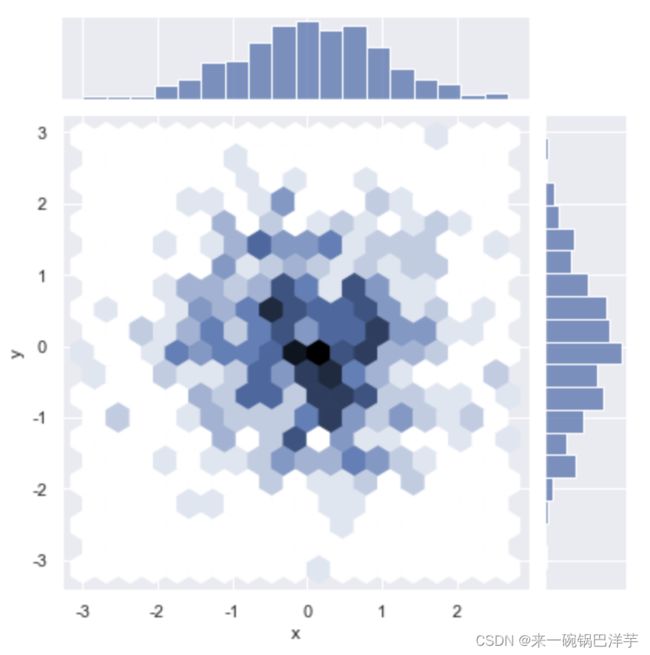
3 绘制核密度估计图
sns.jointplot(x="x", y="y", data=data, kind='kde')
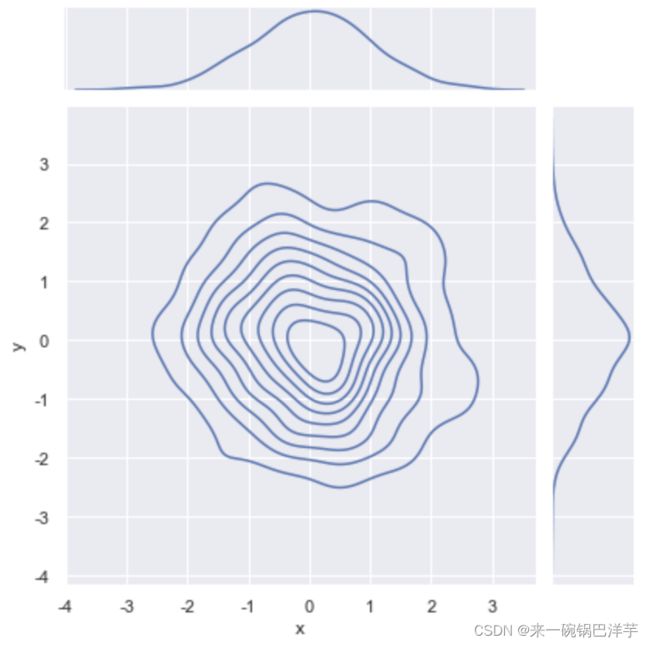
4 绘制成对的双变量分布
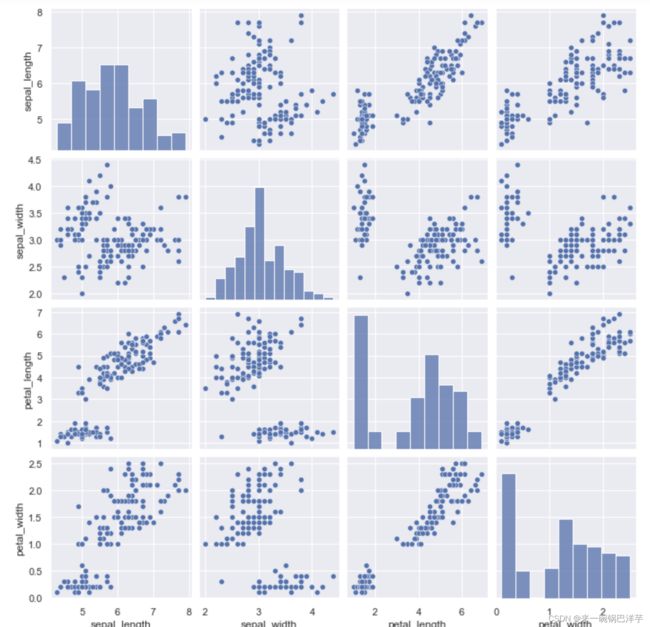
要想在数据集中绘制多个成对的双变量分布,则可以使用pairplot()函数实现,该函数会创建一个坐标轴矩阵,并且显示Datafram对象中每对变量的关系。另外,pairplot()函数也可以绘制每个变量在对角轴上的单变量分布。
如果下面代码中加载数据集失败可以看我另一篇博客:解决sns.load_dataset()加载失败问题
# 这里使用seaborn自带的数据来显示
dataset = sns.load_dataset('iris') # 加载鸢尾花数据集
dataset.head()
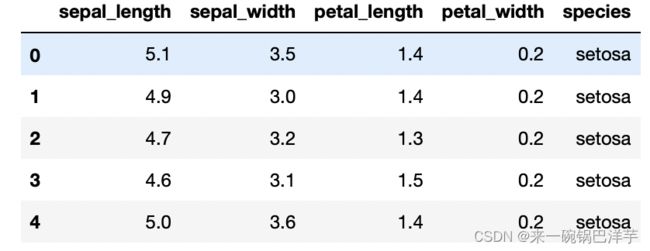
# 绘制多个成对的双变量分布
sns.pairplot(dataset)
6.3 绘制分类数据图
数据集中的数据类型有很多种,除了连续的特征变量之外,最常见的就是类别型的数据了,比如人的性别、学历、爱好等,这些数据类型都不能用连续的变量来表示,而是用分类的数据来表示。
Seaborn针对分类数据提供了专门的可视化函数,这些函数大致可以分为如下三种:
- 分类数据散点图: swarmplot()与 stripplot()。
- 类数据的分布图: boxplot() 与 violinplot()。
- 分类数据的统计估算图:barplot() 与 pointplot()。
1 类别散点图
包括striplot()和swarmplot(),它们的区别是,swarmplot()不会让数据重叠。
striplot()
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=True, dodge=False)
- x,y,hue:x和y是坐标轴标签。hue是对数据再次分类。
- data:用于绘制的数据集。如果x和y不存在,则它将作为宽格式,否则将作为长格式。
- jitter:当有很多数据点重叠时,可以指定抖动的数量或者设为Tue使用默认值。(默认就是True)
- dodge:是否让不同类别的数据分开显示。
下面用代码演示下:
# 获取tips数据
tips = sns.load_dataset('tips')
tips.head(3)
默认的样式
# 展示不同时间点time的总账单数目
sns.stripplot(x='time', y='total_bill', data=tips)

参数修改样式
# 展示不同时间点time的总账单数目
# hue='day',根据day进行细分。
# jitter=False,去除一些重合的数据。
# dodge=True,把不同day分开。(如果设为False,那么lunch的蓝色和黄色会重叠,dinner的三个也会重叠)
sns.stripplot(x='time', y='total_bill', hue='day', data=tips, jitter=False, dodge=True)
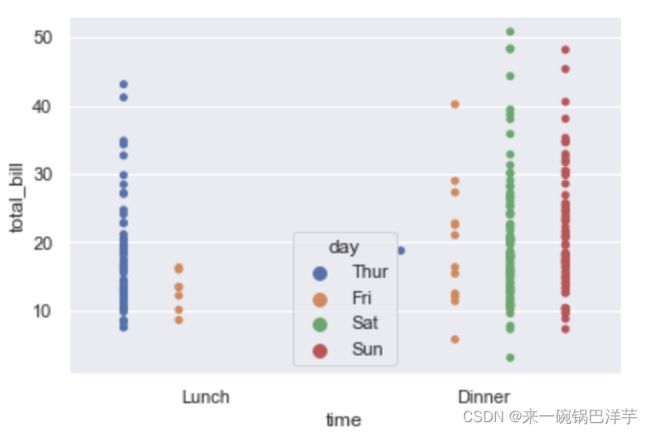
swarmplot()
以树状的形式展现,这样就不会重叠,其他用法和striplot差不多。
sns.swarmplot(x="day", y="total_bill", data=tips)

2 箱型图和小提琴图
- 箱型图:它能显示出一组数据的最大值、最小值、中位数、及上下四分位数。
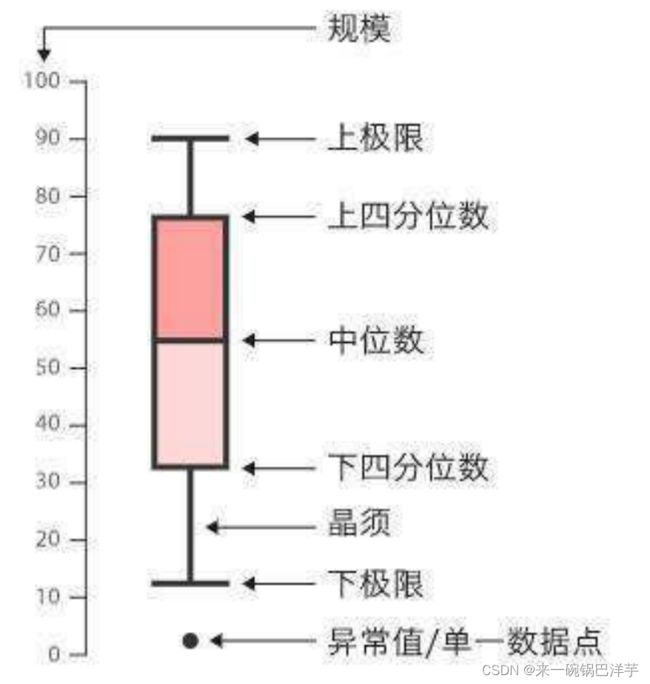
- 小提琴图:
- 小提琴图 (Violin Plot) 用于显示数据分布及其概率密度。
- 这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状。
- 中间的黑色粗条表示四分位数范围,从其延伸的幼细黑线代表 95% 置信区间,而白点则为中位数。
- 箱形图在数据显示方面受到限制,简单的设计往往隐藏了有关数据分布的重要细节。例如使用箱形图时,我们不能了解数据分布。虽然小提琴图可以显示更多详情,但它们也可能包含较多干扰信息。

箱型图
seaborn.boxplot(x=None, y=None, hue=None, data=None, orient=None, color=None, saturation=0.75, width=0.8)
- palette:用于设置不同级别色相的颜色变量。---- palette=[“r”,“g”,“b”,“y”]
- saturation:用于设置数据显示的颜色饱和度。---- 使用小数表示
sns.boxplot(x="day", y="total_bill", data=tips)

小提琴图
seaborn.violinplot(x=None, y=None, hue=None, data=None)
sns.violinplot(x="day", y="total_bill", data=tips)

3 条形图和点图
要想查看每个分类的集中趋势,则可以使用条形图和点图进行展示。
条形图
最常用的查看集中趋势的图形就是条形图。默认情况下, barplot函数会在整个数据集上使用均值进行估计。若每个类别中有多个类别时**(使用了hue参数),则条形图可以使用引导来计算估计的置信区间(是指由样本统计量所构造的总体参数的估计区间)**,并使用误差条来表示置信区间(就是下面黑色的那条线)。
sns.barplot(x="day", y="total_bill", data=tips)

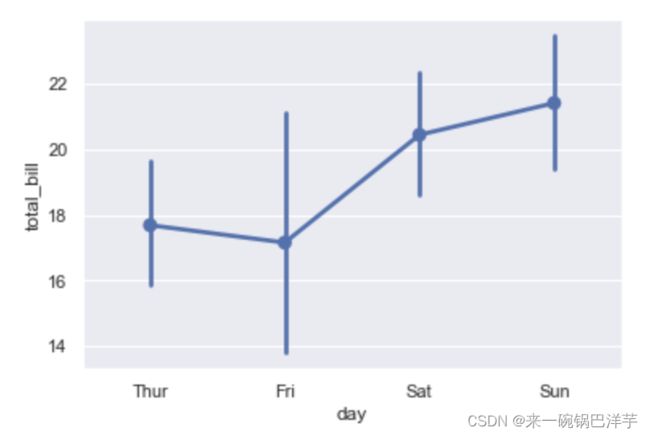
点图
另外一种用于估计的图形是点图,可以调用 pointplot()函数进行绘制,该函数会用高度低计值对数据进行描述,而不是显示完整的条形,它只会绘制点估计和置信区间。
sns.pointplot(x="day", y="total_bill", data=tips)
6.4 案例:NBA球员数据分析
1 基本数据介绍
每个球迷心中都有一个属于自己的迈克尔·乔丹、科比·布莱恩特、勒布朗·詹姆斯。 本案例将用jupyter notebook完成NBA菜鸟数据分析初探。
数据集下载:https://download.csdn.net/download/qq_39763246/20936311
案例中使用的数据是2017年NBA球员基本数据,数据字段见下表:
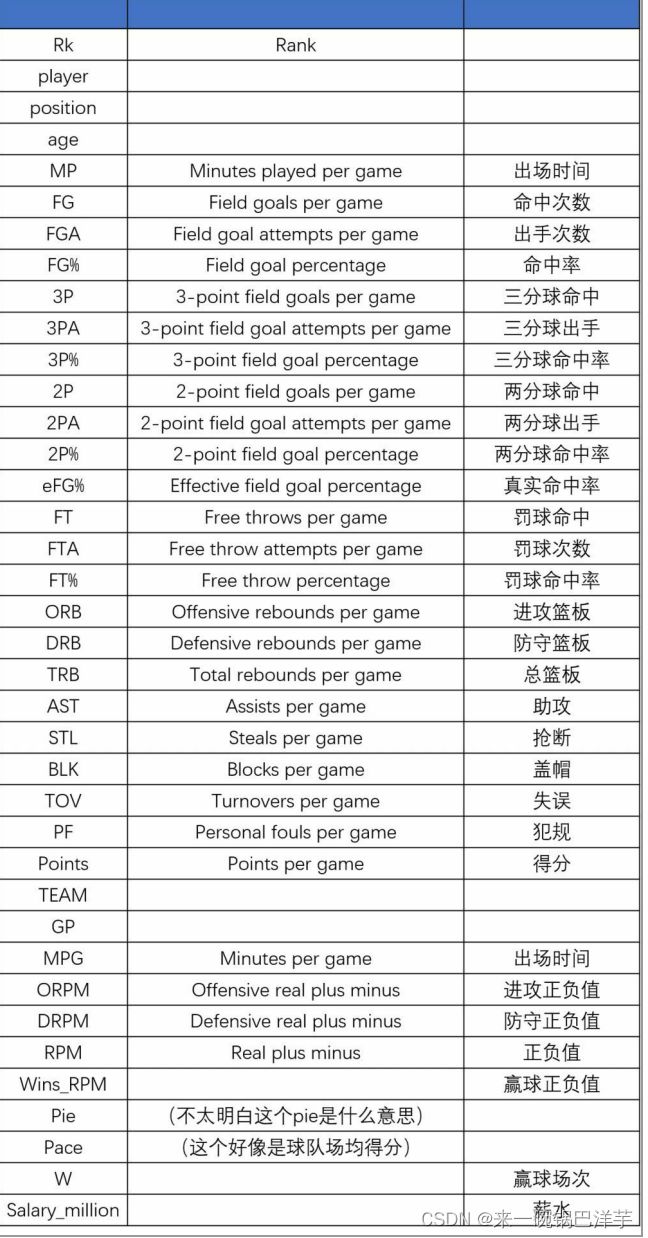
2 获取数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv("2017年NBA球员相关信息.csv")
data.head(3)

data.describe() # 查看每列的基本信息 统计、平均值、标准差、最值等

3 数据分析
数据相关性分析
数据相关性用了热力图来体现,每个格子中的值表示x轴与y轴的相关性。值越大,说明越相关。例如,第一列中ORPM与RPM最相关,根据字段表可以看出,是进攻正负值和正负值。
# 这里只取了部分列,为了让图像更清晰
data_cor = data.loc[:, ['RPM', 'AGE', 'SALARY_MILLIONS', 'ORB', 'DRB', 'TRB',
'AST', 'STL', 'BLK', 'TOV', 'PF', 'POINTS', 'GP', 'MPG', 'ORPM', 'DRPM']]
# 获取两列数据之间的相关性
corr = data_cor.corr()
# 创建画布 以便用sns画图时好设置图像大小
plt.figure(figsize=(20, 8), dpi=100) # 因为seaborn是基于matplotlib的,设置plt就可以设置sns。
# corr是数据,square让图像是正方形(默认是长方形),linewidths设置每个格子间隙,annot显示每个格子具体值
sns.heatmap(corr, square=True, linewidths=0.1, annot=True)

数据排名分析
# 按照球员薪资降序排名
data.loc[:, ["PLAYER", "SALARY_MILLIONS"]].sort_values(by="SALARY_MILLIONS", ascending=False).head()
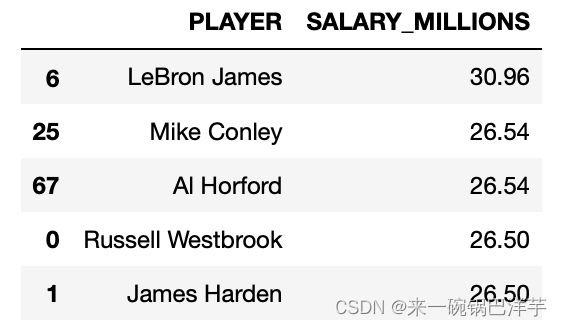
球员薪资和年龄分布
# 利用seaborn中的distplot绘图来分别看一下球员薪水、年龄的分布情况
sns.set_style("darkgrid")
plt.figure(figsize=(14, 5)) # 创建画布(以便设置seaborn的图形大小)
plt.subplot(1, 2, 1) # 表明 这次有1行2列个图,这是第1个图。
sns.distplot(data["SALARY_MILLIONS"])
plt.ylabel("salary")
plt.subplot(1, 2, 2) # 表明 这次有1行2列个图,这是第2个图。
sns.distplot(data["AGE"])
plt.ylabel("AGE")
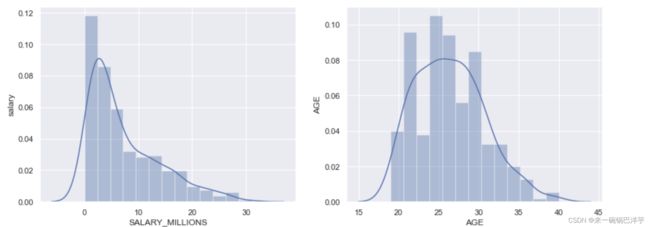
、