【强化学习纲要】4 价值函数近似
【强化学习纲要】4 价值函数近似
-
- 4.1 价值函数近似基本原理
-
- 4.1.1 Introduction: Scaling up RL
- 4.1.2 梯度下降法
- 4.1.3 线性价值函数近似
- 4.2 价值函数近似for prediction
-
- 4.2.1 Incremental VFA(价值函数近似) Prediction Algorithms
- 4.2.2 Monte-Carlo Prediction with VFA
- 4.2.3 TD Prediction with VFA
- 4.3 价值函数近似for control
-
- 4.3.1 Action-Value Function Approximation
- 4.3.2 Incremental Control Algorithm
- 4.3.3 Mountain Car Example
- 4.3.4 Batch Reinforcement Learning
- 4.4 Deep Q networks
-
- 4.4.1 Deep Neural Networks
- 4.4.2 Deep Reinforcement Learning
- 4.4.3 Deep Q-Networks(DQN)
- 4.4.4 DQNs: Experience Replay(经验回放)
- 4.4.5 DQNs: Fixed Targets
- 4.4.6 Demo of DQNs
周博磊《强化学习纲要》
学习笔记
课程资料参见:https://github.com/zhoubolei/introRL.
教材:Sutton and Barton
《Reinforcement Learning: An Introduction》
4.1 价值函数近似基本原理
4.1.1 Introduction: Scaling up RL
之前我们遇到的都是状态很少的小规模问题,然后实际生活中很多问题都是大规模问题,如象棋( 1 0 47 10^{47} 1047states),围棋( 1 0 170 10^{170} 10170states),那么怎么用model-free的方法去估计和控制这些大规模问题的价值函数呢?
- 用查表的方式展现
- Q table,横轴是所有状态,纵轴是所有的action,通过查表,我们找到某列最大值的action是需要采取的action。但是如果状态非常多,table会非常大。
- 挑战:状态或者action太多;很难单独学习每个状态
- 怎样避免用一个table表征每个状态的模式?
- reward function or dynamics function
- value function, state-action function
- policy function
都是需要表示每一个状态的。
- 解决方案:用函数近似的方法估计
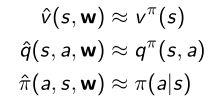
给定一个价值函数,我们可以用带参数的近似函数去近似它,如式子中用 w w w来拟合真实的价值函数。 - 好处:可以把见到的状态泛化到没有见到的状态,如果状态非常多,我们采样的状态是非常有限的。因此我们引入一个近似函数,通过插值的方法,把中间没有见到的函数估计出来。
- 用MC或TD learning的方法近似估计参数 w w w
价值函数的类别

类别1:输入是一种状态,输出是价值函数的值
类别2:对于q函数,将state和action作为输入,然后输出是给定状态和action的价值是多少
类别3:对于q函数,输入是状态,输出是对于所有哦action可能的q值,然后再输出后取argmax,就可以把最可能的action选出来
函数估计
多种表示形式:
- Linear combinations of features。把特征用线性的形式叠加出来。
- 神经网络。
- 决策树
- Nearest neighbors
主要使用前两类,因为是可微分的,我们可以很方便的优化近似函数里面的参数。
4.1.2 梯度下降法
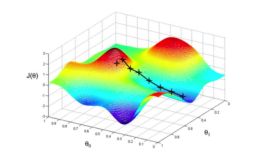
- 有一个objective function J ( w ) J(w) J(w),怎样优化参数 w w w能够极小化 J ( w ) J(w) J(w)
- 定义 J ( w ) J(w) J(w)关于参数 w w w的梯度:
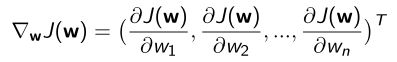
- Adjust w w w in the direction of the negative gradient, α \alpha α是step-size(步长),得到极小值
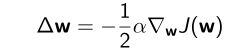
Value Function Approximation with an Oracle
价值函数估计的时候也是用的梯度下降法。如果已知每个状态,应该如何优化价值函数?
- Oracle真值函数,假设我们知道真实的价值函数 v π ( s ) v^{\pi}(s) vπ(s)是多少,就可以去拟合逼近它。
- 因此可以把 J ( w ) J(w) J(w)写成通过优化 w w w可以使得mean squared error极小化。
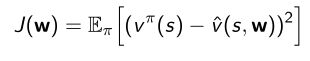
- 直接计算gradient,通过gradient descend可以迅速迭代然后找到可以极小化对应客观函数的 w w w
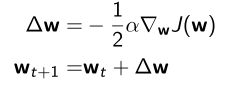
用特征向量描述状态

比如:
- Mountain Car
特征:车的位置,和速度 - Cart Pole
特征:位置,速度,木杆的角度,旋转的角度 - AlphaGo
特征:棋子位置,…每一个特征都是19*19的feature map,48个feature map叠加起来作为alphago的输入特征,传给价值函数

4.1.3 线性价值函数近似
- 用特征的线性叠加表示价值函数
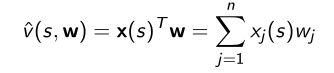
状态转化成特征向量 x ( s ) x(s) x(s),参数为 w w w - 优化objective function,使得线性加和的函数和真实的函数尽量的接近,mean square loss尽量的小
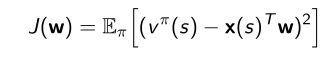
- 取一个gradient
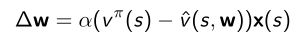
Update = StepSize × PredictionError × FeatureValue
这个形式只有线性模型近似价值函数的时候才有 - Stochastic gradient descent(随机梯度下降SGD)可以达到一个global optimum(全局优化)的值,因为是线性的,得到的local optimum(局部优化)接近global optimum(全局优化)。因此可以找到一个最佳的拟合价值函数 v π ( s ) v^{\pi}(s) vπ(s)的模型。
Linear Value Function Approximation with Table Lookup Feature
-
Table lookup feature是one-hot vector。
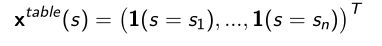
向量基本上都是0,只有一个元素是1,当前状态等于某一个状态,对应的那个元素会变成1,除了那个状态其他都是0. -
one-hot vector用线性模型来表示
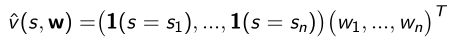
参数向量 w 1 w_1 w1… w n w_n wn乘以状态state的feature -
由于是one-hot vector,可以得到拟合价值函数就等于当前对应于某个位置的 w k w_k wk;因此现在优化的就是去估计 w k w_k wk
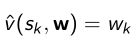
4.2 价值函数近似for prediction
- 实际上,如果没有oracle(真值函数)如何去拟合价值函数呢?
- 回顾model-free prediction
- 给定一个policy,估计每个状态它的价值是多少。
- 使用MC或TD的方法来优化价值函数
- 可以再model-free的过程中,把函数近似放到loop里面去,同时进行优化:一边优化价值函数,一边利用优化好的价值函数优化价值函数的近似。
4.2.1 Incremental VFA(价值函数近似) Prediction Algorithms
- 假设我们有真值 v π ( s ) v^{\pi}(s) vπ(s)的话,可以计算gradient:

- 但是实际情况是并没有真值,并没有oracle,只有reward
- 因此我们直接用target来替代真值
- 对于MC,用 G t G_t Gt去替代
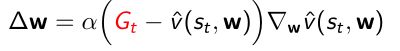
- 对于TD(0),用TD target来替代,由两部分组成:实际走完这一步的reward;bootstrapping估计得到下一个状态的近似价值函数

- 对于MC,用 G t G_t Gt去替代
4.2.2 Monte-Carlo Prediction with VFA
- 因为MC是采样得到的,因此 G t G_t Gt是unbiased无偏值的,但是对于真值是noisy sample
- unbiased的意思是:取 G t G_t Gt的期望是可以直接等于真值的,是noisy的,要采样很多次。
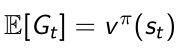
- 因此可以通过MC的方法得到很多状态,每一个状态得到对应的return,这样就得到很多的training pair
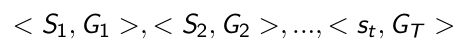
- 得到training pair后,使用类似于监督的方法产生gradient;如果是线性的话,可以提出特征 x ( s t ) x(s_t) x(st)
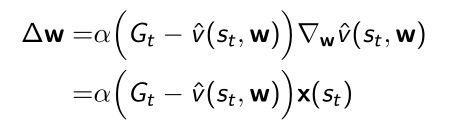
- 利用MC产生的gradient可以对价值函数估计参数进行优化,这样就可以得到一个近似的价值函数。
4.2.3 TD Prediction with VFA
- TD target是biased偏置的

- 因为如果取target的期望的话是不等于 v π ( s t ) v^{\pi}(s_t) vπ(st)的,因为TD target是包含了正在优化的参数 w w w的
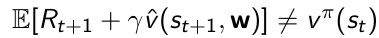
- 也可以产生一些training pair
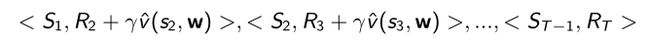
- 同样放入gradient里面
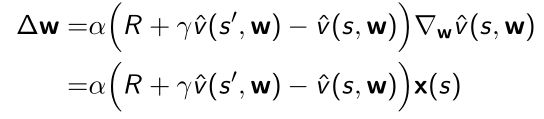
也叫做semi-gradient,不是真实的gradient,因为它包含优化的参数 w w w,不同的时刻 w w w不同所以gradient不一定很准。 - TD(0)如果采取的是线性特征 x ( s ) x(s) x(s),得到的是全局最优解。
4.3 价值函数近似for control
通过Generalized policy iteration达到
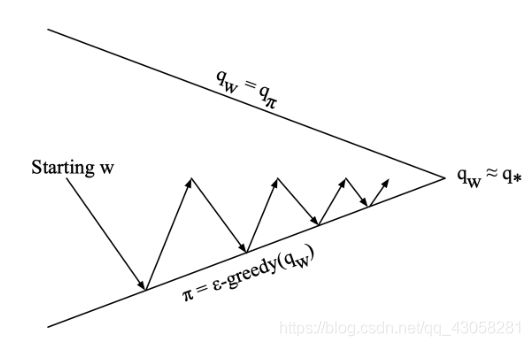
- Policy evaluation:approximate近似 policy evaluation,将q table用一个带参数 w w w的函数来近似
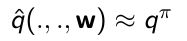
- Policy improvement:采用 ϵ \epsilon ϵ-greedy 改进算法
4.3.1 Action-Value Function Approximation
- 用一个函数去拟合价值函数

- 假设是知道ture action-value(oracle) q π ( s , a ) q^{\pi}(s,a) qπ(s,a)的,因此可以比较容易的写出objective function
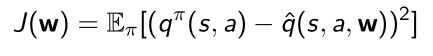
- 写出gradient,可以优化找到local minimum
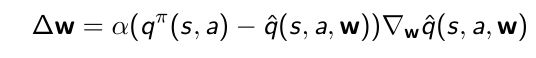
Linear Action-Value Function Approximation
- 定义特征,给定状态和行为,定义一些对应的特征向量,来刻画状态是怎么被描述的
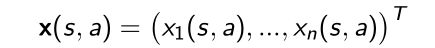
- 用线性拟合,定义好特征以后直接可以加和,元素的强度 w j w_j wj是我们需要学习的参数

- 这样我们就可以用gradient descent写出来
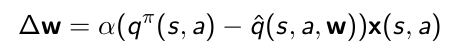
gradient等于step-size乘以估计的差异乘以特征向量
4.3.2 Incremental Control Algorithm
实际上,这里没有oracle,因此
- 用MC的return G t G_t Gt去替代oracle
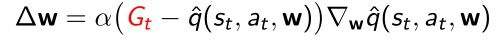
- 对于Sarsa,可以用Sarsa TD target去替代oracle
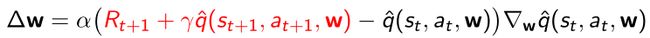
- 对于Q-learning,用Q-learning TD target去替代oracle,与Sarsa不同的是TD target是取一个max,估计q函数的近似并对应下一步的状态 s t + 1 s_{t+1} st+1并取对应得a(action这个值)最大得值作为target一部分
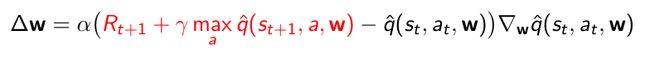
这样就可以得到gradient,然后用这个gradient去更新q函数近似函数的参数。
Semi-gradient Sarsa for VFA Control

开始的时候初始化需要优化的 w w w;如果是结束状态的话就用return;如果不是结束状态的话就往前走一步,采样出A’,构造出它的TD target作为oracle,然后算出它的gradient;每往前走一步更新一次 w w w;S和A都更新。
4.3.3 Mountain Car Example
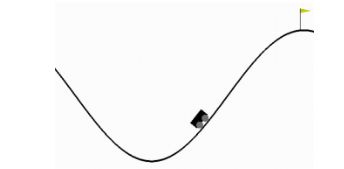
- 目标:控制车能够到达的位置
- 可以控制的:油门,油门的前后,以及不踩油门
- 定义状态,state feature actor描述状态特征
- 把2D平面画格子,看当前位置,落在哪个格子就用哪个格子的index来作为它的特征来描述它
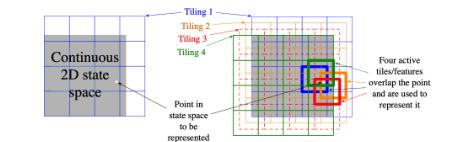
- 把2D平面画格子,看当前位置,落在哪个格子就用哪个格子的index来作为它的特征来描述它
- 构造出特征后,q函数的近似:
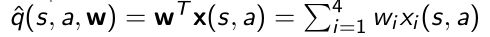
用线性函数近似它,把构造的特征 w e i g h t T weight^T weightT 求和。 - 可视化q函数的变化
拟合形式:cost-to-go function
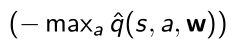
得到拟合的q函数后,在每一个action取最大值表示出来。
随着training的过程,episode越来越多,会得到一个螺旋上升的形状。表示在某一个位置(position)以及velocity,action最大的值是多少。
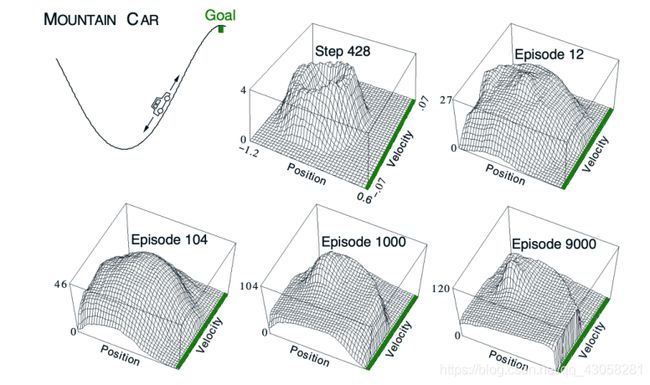
学到q函数后,可以进行插值把形状表示出来。 - 代码:(如何构造特征函数,以及怎么把特征函数放到q-learning里面的)
https://github.com/cuhkrlcourse/RLexample/blob/master/modelfree/q_learning_mountaincar.py
Convergence收敛的问题
- 对于Sarsa和Q-learning这两种gradient:
- Sarsa:
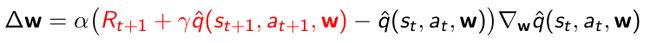
- Q-learning:

- Sarsa:
- TD这个方法如果是有VFA(价值函数估计)的话,它的gradient是不正确的,因为它的gradient本身包含了 w w w。
- 并且update包含了两个近似过程:Bellman backup和underlying value function。两个近似都会引入很多的噪声。
- 因此TD方法用off-policy或者用non-linear function approximation拟合的时候,优化过程不是很稳定,这也是强化学习为什么不稳定容易crash,相对于监督学习非常不稳地,因为它并没有一个值可以收敛。
- Off-policy control的挑战:behavior policy(采集数据的策略)和target policy(实际优化的策略)并不相同,导致价值函数估计也非常不准确。
The Deadly Triad(死亡三角) for the Danger of Instability and Divergence
潜在不确定因素:
- Function approximation:当利用一个函数来近似价值函数或者q函数时,因为用了近似,就会引入误差,这样就会导致很多问题。
- Bootstrapping:TD方法采取bootstrapping,基于之前的估计来估计当前的函数,这样也是引入了噪声,有时会使网络over confident;MC方法相对于TD方法好一些,因为MC使用的实际的return,且是unbiased,期望总是等于真值。
- Off-policy training:采集的data是用behavior policy采集的,但是优化的函数又是用的另一个函数,引入了不确定因素。
这也是前言研究想要克服的问题。
控制算法的收敛性问题
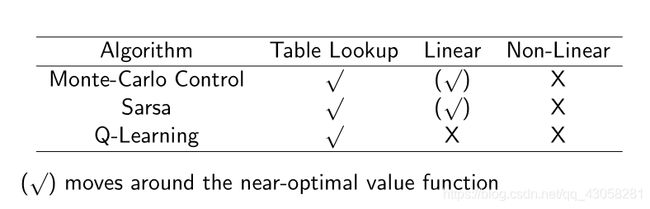
- MDP是小规模的,状态有限的时候,用Lookup table来表示它,对于MC,Sarsa,Q-learning都是可以找到一个最优解的;
- 如果MDP是比较大规模的,采取的方法是线性特征拟合的话,MC和Sarsa是可以找到一个近似最优解的价值函数,Q-learning不行;
- 如果选取的是非线性函数近似,比如神经网络,这三种算法都很难保证最后得到的解是最优解。
4.3.4 Batch Reinforcement Learning
- 前面的算法都是单步的强化学习算法,但实际的优化过程中,单步的incremental gradient descent是效率很低的。
- 因此有了Batch的方法,有了training batch,直接优化整个batch里面所有样本,使得函数可以拟合。
Least Square Prediction
- 假设有一个数据库(experience D D D)里面包含了采集到的pair < s 1 , v 1 π >
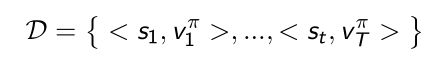
- 目标:优化 w w w来拟合整个采集到的数据 D D D,使得在这个数据库里面每个pair都极小化。
- 实际是想得到 w ∗ w^* w∗这样极小化的值
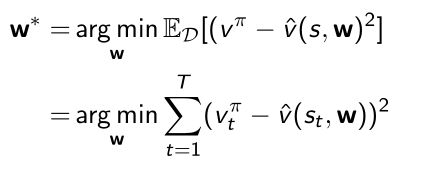
得到一个 w ∗ w^* w∗使得可以在数据集 D D D上面mean square loss极小化
Stochastic Gradient Descent(采样) with Experience Replay
- 如果 D D D集合非常大的话,数据没法全部放进来,因此可以采用采样的办法。
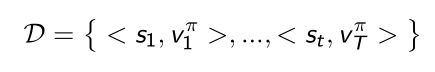
- 一个Batch包含10个或者20个样本,这些样本是从pair中随机采样如20个样本
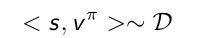
- 可以把这20个样本的gradient算出来,用gradient优化函数

然后重复,随机采样,优化… - 通过这个迭代的办法,最后可以收敛到mean square solution
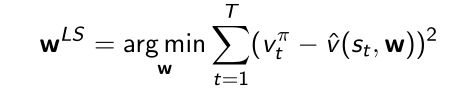
通过迭代的方法得到的 w w w和直接一步优化得到的 w w w是一样的。
4.4 Deep Q networks
如何用非线性函数来拟合价值函数?
线性价值函数拟合
- 先定义好特征函数,当给定状态的时候用 x ( s ) x(s) x(s)这个函数可以提取出对应的特征,然后把线性价值叠加来估计 v v v值。
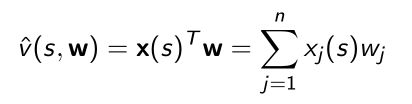
- Objection function
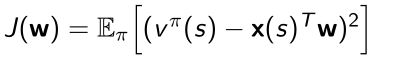
- 梯度
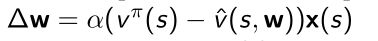
- 不同的MC或TD方法可以把真值 v π ( s ) v^{\pi}(s) vπ(s)替换
- MC,用sample return作为target
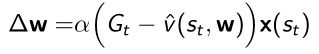
- TD,用one- step的奖励和bootstrap的 v v v值作为target算它的梯度进行优化
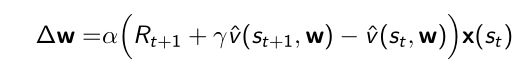
- MC,用sample return作为target
线性vs非线性价值函数拟合
- 线性价值函数拟合需要人为设计好的特征,但是这是非常困难的一件事情。
- 用非线性价值函数拟合,可以把特征提取和价值函数学习结合起来。
- 神经网络是非常常用的方法。
4.4.1 Deep Neural Networks
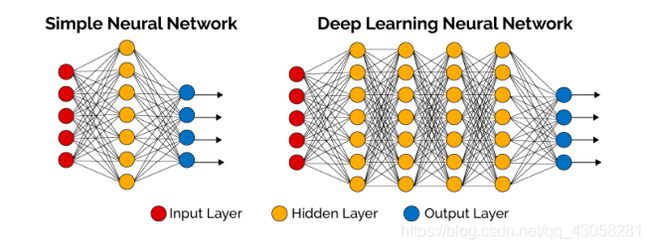
- Multiple layers of linear functions, with non-linear operators between layers
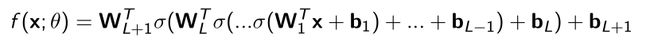
- 优化神经网络参数的时候,用的chain rule(链式法则)的方法backpropagate(反向传播)将梯度传回,将每一个参数都进行优化。

卷积神经网络
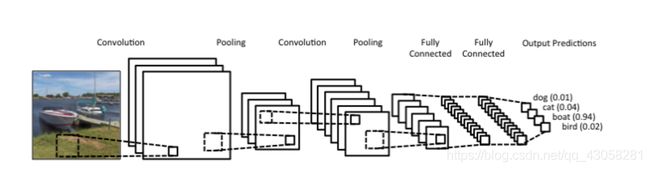
- Convolution encodes the local information in 2D feature map
- 卷积核,reLU非线性函数,batch normalization, etc
- 常用于计算机视觉领域
- 推荐CNN课程:http://cs231n.github.io/convolutional-networks/
4.4.2 Deep Reinforcement Learning
深度学习和强化学习的结合。
- 用神经网络来拟合强化学习的各个参数,如:
- 价值函数(value function)
- 策略函数(policy function)
- 环境模型(world model)
- 损失函数常用stochastic gradient descent(sGD随机梯度下降)来进行优化
- 挑战:
- 有很多模型参数要优化
- “死亡三角”
- 非线性拟合
- Bootstrapping
- Off-policy training
4.4.3 Deep Q-Networks(DQN)
- 2015年DeepMind提出的网络结构,发表到Nature的论文:Human-level control through deep reinforcement learning
- 用神经网络来拟合Q 函数
- 在Atari游戏有很好的效果
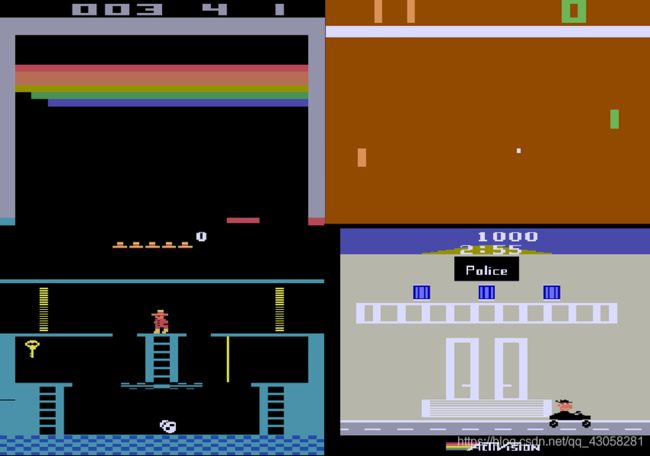
4 Atari Games: Breakout, Pong, Montezuma’s Revenge, Private Eye
回顾:Action-Value Function Approximation
- 参数 w w w,拟合q函数

- 构造出MSE(mean-square error)去优化,使得函数可以近似q函数

- 用sGD(随机梯度下降法)优化找到局部最优值
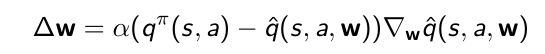
回顾:Incremental Control Algorithm

DQN for Playing Atari Games
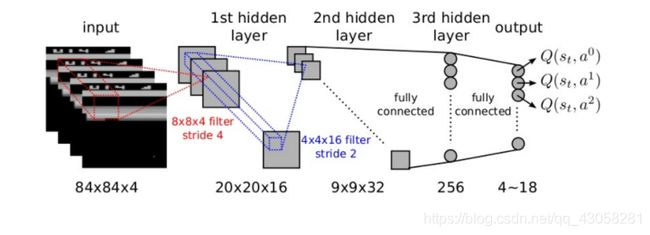
- 用神经网络来拟合q函数;
- 游戏页面连续的4帧的pixel作为输入;
- 输出是18个操作
- 奖励是游戏的增减分数
Q-learning with Value Function Approximation
- 两个要克服的问题
- 样本之间的相关性(correlation)。在强化学习里面收集的数据是一个时序的玩游戏的序列,如果是在像素级别,关联性是很高的,因为很可能只有很小的一部分有变化,其他都很类似。所以不同时序之间的correlation是非常高的,这样就使得学习非常困难。
- Non-stationary targets。因为target里面已经自带了模型的参数,使得训练变得困难。
- Deep Q-learning用了两种方法克服:
- 针对第一个问题,采用Experience replay的方法。
- 针对第二个问题,采用Fixed Q targets的方法。使得TD target在构建的时候,用第二个网络来构建,另外还有一个学习的网络,这样就有两个网络,就会有一些时间差。
4.4.4 DQNs: Experience Replay(经验回放)
- 采用一个容器(container)作为一个replay memory D D D,在replay memory里面存了很多不同环节得到的sample。
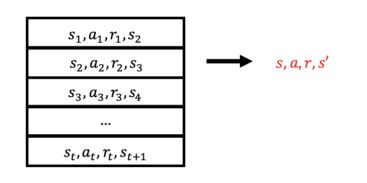
每一个格子存的sample叫做transition tuple,包含四个变量 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1),分别是当前的位置(状态)、采取的某个行为、得到的奖励、下一个状态。把每一个tuple打散存在replay memory里面。 - 在做experience replay(经验回放),在训练的过程中:
- 有一个网络一直在玩游戏,采集新的tuple,然后把tuple放到容器里面;另一方面,为了训练这个网络,有一个采样的过程,如在replay buffer里面进行随机的采样,因此每次采集到的sample都有可能是在不同的episode里面出现的。
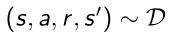
- 这样就得到了相关度比较低的tuple后,构建q-learning的target
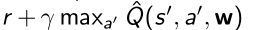
- 有了TD target以后,就可以构造出q函数拟合函数的Δw
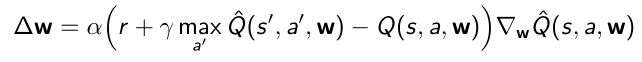
- 有一个网络一直在玩游戏,采集新的tuple,然后把tuple放到容器里面;另一方面,为了训练这个网络,有一个采样的过程,如在replay buffer里面进行随机的采样,因此每次采集到的sample都有可能是在不同的episode里面出现的。
4.4.5 DQNs: Fixed Targets
- 为了提高稳定性,target网络有确定的weights,或者target network和实际优化的网络之间存在一定时间差。
- target里面的权重用 w − w^- w−来表征, w w w则用来更新。
- 产生target的过程
- 先从replay buffer里面采集一些transition tuple,相关度较低
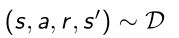
- 然后target network用 w − w^- w−来产生

- 然后进行优化,得到Δw
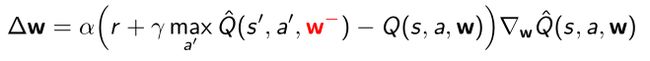
w − w^- w−和 w w w有一定的时间差,在很多时候都是不同的, w − w^- w−更新的要慢一些,这就使得TD target和实际的不同。
- 先从replay buffer里面采集一些transition tuple,相关度较低
Why fixed target
- 例子:想要优化一个网络使得它能够更好的估计出它的q target。猫是q优化的过程,猫要能够追上(预测)到q target(老鼠)
- 开始的时候猫可能离老鼠很远,但是猫追老鼠的同时老鼠也在动,因为q target与模型是相关的,在每次优化后,随着网络的更新,q target也会改变。
- 导致猫和老鼠都在动,在优化空间里面乱动

- 这样就会产生非常奇怪的优化轨迹,相当于使得整个训练过程非常不稳定

- 因此修复这个问题的方法是可以固定target,让老鼠动的不是那么频繁,如让它每5步动一次,这样猫就有足够的时间去接近target,逐渐距离会越来越小,这样就可以最终拟合得到最好的q network。这就是为什么需要fixed target。
DQNs在Atari上的结果
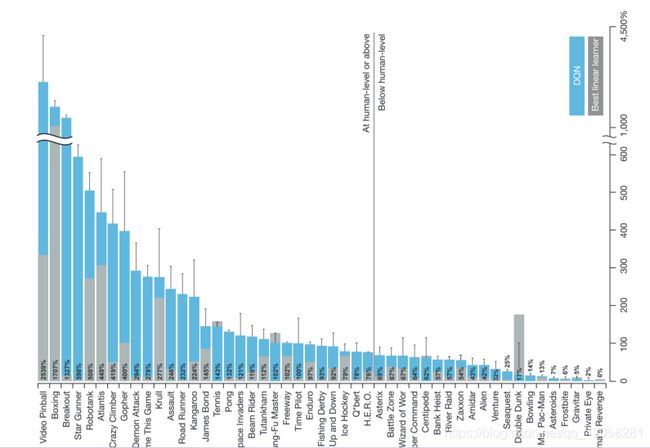
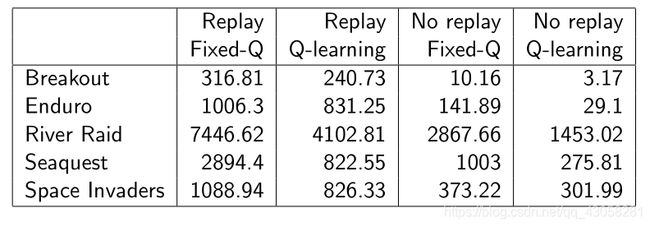
Abalation Study on DQNs
4.4.6 Demo of DQNs
-
Demo of Breakout by DQN:
https://www.youtube.com/watch?v=V1eYniJ0Rnk -
Demo of Flappy Bird by DQN:
https://www.youtube.com/watch?v=xM62SpKAZHU -
Code of DQN in PyTorch:
https://github.com/cuhkrlcourse/DeepRL-Tutorials/blob/master/01.DQN.ipynb -
Code of Flappy Bird:
https://github.com/xmfbit/DQN-FlappyBird
Code of DQN in PyTorch:
Imports
import gym
from gym import wrappers
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
from IPython.display import clear_output
from matplotlib import pyplot as plt
%matplotlib inline
import random
from timeit import default_timer as timer
from datetime import timedelta
import math
from utils.wrappers import make_atari, wrap_deepmind, wrap_pytorch
from utils.hyperparameters import Config
from agents.BaseAgent import BaseAgent
Hyperparameters
config = Config()
config.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#epsilon variables
config.epsilon_start = 1.0
config.epsilon_final = 0.01
config.epsilon_decay = 30000
config.epsilon_by_frame = lambda frame_idx: config.epsilon_final + (config.epsilon_start - config.epsilon_final) * math.exp(-1. * frame_idx / config.epsilon_decay)
#misc agent variables
config.GAMMA=0.99
config.LR=1e-4
#memory
config.TARGET_NET_UPDATE_FREQ = 1000
config.EXP_REPLAY_SIZE = 100000
config.BATCH_SIZE = 32
#Learning control variables
config.LEARN_START = 10000
config.MAX_FRAMES=1000000
Replay Memory
class ExperienceReplayMemory:
def __init__(self, capacity):
self.capacity = capacity
self.memory = []
def push(self, transition):
self.memory.append(transition)
if len(self.memory) > self.capacity:
del self.memory[0]
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
Network Declaration
class DQN(nn.Module):
def __init__(self, input_shape, num_actions):
super(DQN, self).__init__()
self.input_shape = input_shape
self.num_actions = num_actions
self.conv1 = nn.Conv2d(self.input_shape[0], 32, kernel_size=8, stride=4)
self.conv2 = nn.Conv2d(32, 64, kernel_size=4, stride=2)
self.conv3 = nn.Conv2d(64, 64, kernel_size=3, stride=1)
self.fc1 = nn.Linear(self.feature_size(), 512)
#输出action
self.fc2 = nn.Linear(512, self.num_actions)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
def feature_size(self):
return self.conv3(self.conv2(self.conv1(torch.zeros(1, *self.input_shape)))).view(1, -1).size(1)
Agent
class Model(BaseAgent):
def __init__(self, static_policy=False, env=None, config=None):
super(Model, self).__init__()
self.device = config.device
self.gamma = config.GAMMA
self.lr = config.LR
self.target_net_update_freq = config.TARGET_NET_UPDATE_FREQ
self.experience_replay_size = config.EXP_REPLAY_SIZE
self.batch_size = config.BATCH_SIZE
self.learn_start = config.LEARN_START
self.static_policy = static_policy
self.num_feats = env.observation_space.shape
self.num_actions = env.action_space.n
self.env = env
self.declare_networks()
#构造target model
self.target_model.load_state_dict(self.model.state_dict())
self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr)
#move to correct device
#原来的model
self.model = self.model.to(self.device)
#target model
self.target_model.to(self.device)
if self.static_policy:
self.model.eval()
self.target_model.eval()
else:
self.model.train()
self.target_model.train()
self.update_count = 0
self.declare_memory()
def declare_networks(self):
self.model = DQN(self.num_feats, self.num_actions)
self.target_model = DQN(self.num_feats, self.num_actions)
def declare_memory(self):
self.memory = ExperienceReplayMemory(self.experience_replay_size)
def append_to_replay(self, s, a, r, s_):
self.memory.push((s, a, r, s_))
def prep_minibatch(self):
# random transition batch is taken from experience replay memory
transitions = self.memory.sample(self.batch_size)
batch_state, batch_action, batch_reward, batch_next_state = zip(*transitions)
shape = (-1,)+self.num_feats
batch_state = torch.tensor(batch_state, device=self.device, dtype=torch.float).view(shape)
batch_action = torch.tensor(batch_action, device=self.device, dtype=torch.long).squeeze().view(-1, 1)
batch_reward = torch.tensor(batch_reward, device=self.device, dtype=torch.float).squeeze().view(-1, 1)
non_final_mask = torch.tensor(tuple(map(lambda s: s is not None, batch_next_state)), device=self.device, dtype=torch.uint8)
try: #sometimes all next states are false
non_final_next_states = torch.tensor([s for s in batch_next_state if s is not None], device=self.sdevice, dtype=torch.float).view(shape)
empty_next_state_values = False
except:
non_final_next_states = None
empty_next_state_values = True
return batch_state, batch_action, batch_reward, non_final_next_states, non_final_mask, empty_next_state_values
def compute_loss(self, batch_vars):
batch_state, batch_action, batch_reward, non_final_next_states, non_final_mask, empty_next_state_values = batch_vars
#estimate
current_q_values = self.model(batch_state).gather(1, batch_action)
#产生target的过程
with torch.no_grad():
#构造 max_next_q_values
max_next_q_values = torch.zeros(self.batch_size, device=self.device, dtype=torch.float).unsqueeze(dim=1)
if not empty_next_state_values:
max_next_action = self.get_max_next_state_action(non_final_next_states)
#构造max_next_q_values的时候是使用target network,
#把上一帧的状态放到target network里面,然后取max action
max_next_q_values[non_final_mask] = self.target_model(non_final_next_states).gather(1, max_next_action)
expected_q_values = batch_reward + (self.gamma*max_next_q_values)
#loss
diff = (expected_q_values - current_q_values)
loss = self.huber(diff)
loss = loss.mean()
return loss
def update(self, s, a, r, s_, frame=0):
if self.static_policy:
return None
self.append_to_replay(s, a, r, s_)
if frame < self.learn_start:
return None
batch_vars = self.prep_minibatch()
loss = self.compute_loss(batch_vars)
# Optimize the model
self.optimizer.zero_grad()
loss.backward()
for param in self.model.parameters():
param.grad.data.clamp_(-1, 1)
self.optimizer.step()
#每个一段时间更新一次target model,把优化的model copy到target里面来,
#这样开始两个network就一致,然后又让target network慢一些再更新一下
self.update_target_model()
self.save_loss(loss.item())
self.save_sigma_param_magnitudes()
def get_action(self, s, eps=0.1):
with torch.no_grad():
if np.random.random() >= eps or self.static_policy:
X = torch.tensor([s], device=self.device, dtype=torch.float)
a = self.model(X).max(1)[1].view(1, 1)
return a.item()
else:
return np.random.randint(0, self.num_actions)
def update_target_model(self):
self.update_count+=1
self.update_count = self.update_count % self.target_net_update_freq
if self.update_count == 0:
self.target_model.load_state_dict(self.model.state_dict())
def get_max_next_state_action(self, next_states):
return self.target_model(next_states).max(dim=1)[1].view(-1, 1)
def huber(self, x):
cond = (x.abs() < 1.0).to(torch.float)
return 0.5 * x.pow(2) * cond + (x.abs() - 0.5) * (1 - cond)
Plot Results
def plot(frame_idx, rewards, losses, sigma, elapsed_time):
clear_output(True)
plt.figure(figsize=(20,5))
plt.subplot(131)
plt.title('frame %s. reward: %s. time: %s' % (frame_idx, np.mean(rewards[-10:]), elapsed_time))
plt.plot(rewards)
if losses:
plt.subplot(132)
plt.title('loss')
plt.plot(losses)
if sigma:
plt.subplot(133)
plt.title('noisy param magnitude')
plt.plot(sigma)
plt.show()
Training Loop
start=timer()
env_id = "PongNoFrameskip-v4"
env = make_atari(env_id)
env = wrap_deepmind(env, frame_stack=False)
env = wrap_pytorch(env)
model = Model(env=env, config=config)
episode_reward = 0
observation = env.reset()
for frame_idx in range(1, config.MAX_FRAMES + 1):
epsilon = config.epsilon_by_frame(frame_idx)
action = model.get_action(observation, epsilon)
prev_observation=observation
observation, reward, done, _ = env.step(action)
observation = None if done else observation
model.update(prev_observation, action, reward, observation, frame_idx)
episode_reward += reward
if done:
observation = env.reset()
model.save_reward(episode_reward)
episode_reward = 0
if np.mean(model.rewards[-10:]) > 19:
plot(frame_idx, model.rewards, model.losses, model.sigma_parameter_mag, timedelta(seconds=int(timer()-start)))
break
if frame_idx % 10000 == 0:
plot(frame_idx, model.rewards, model.losses, model.sigma_parameter_mag, timedelta(seconds=int(timer()-start)))
model.save_w()
env.close()
DQNs总结
- DQN uses experience replay and fixed Q-targets
- Store transition ( s t , a t , r t + 1 , s t + 1 ) (s_t ,a_ t ,r_{t+1} ,s_{t+1}) (st,at,rt+1,st+1) in replay memory D
- Sample random mini-batch of transitions ( s , a , r , s ′ ) (s,a,r,s') (s,a,r,s′) from D
- Compute Q-learning targets w.r.t. old, fixed parameters w − w^− w−
- Optimizes MSE between Q-network and Q-learning targets using stochastic gradient descent
改进DQN
- Double DQN: Deep Reinforcement Learning with Double Q-Learning.Van Hasselt et al, AAAI 2016
- Dueling DQN: Dueling Network Architectures for Deep Reinforcement Learning. Wang et al, best paper ICML 2016
- Prioritized Replay: Prioritized Experience Replay. Schaul et al, ICLR 2016
- 技术实现:
https://github.com/cuhkrlcourse/DeepRL-Tutorials
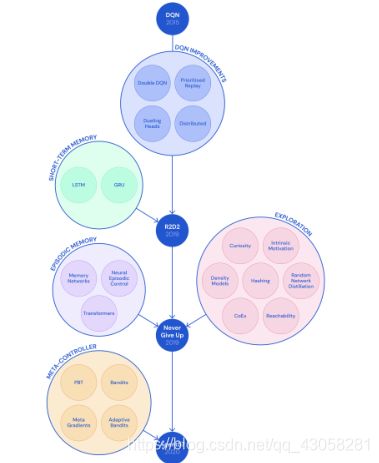
March 31, 2020: Agent57
五年内的改进集合
https://deepmind.com/blog/article/Agent57-Outperforming-the-human-Atari-benchmark
Optional Homework
- Go through the Jupytor tutorial and training your own gaming agent:
https://github.com/cuhkrlcourse/DeepRL-Tutorials - Optional Homework 2:
https://github.com/cuhkrlcourse/ierg6130-assignment