随着2012年AlexNet大放异彩,相比以前浅学习方法在ImageNet中top5 error前所未有的下降约10%,CNN已经越来越被人们关注。后续VGG,GoogleNet,ResNet进一步提高CNN的性能。但是到ResNet,网络已经达到152层,模型大小动辄几百300MB+。这种巨大的存储和计算开销,已经严重限制了CNN在某些低功耗领域的应用。
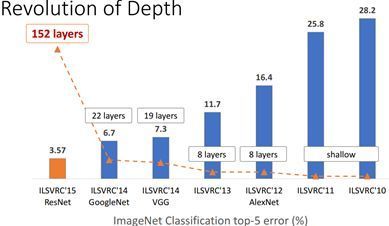

图1 CNN在ImageNet上的表现
说到这里,讲个故事。之前有位读者朋友,他要做一个在无人机上对地的实时行人检测与识别Demo。他问:如何在ARM芯片实时跑起来Faster R-CNN。先不理会问题本身,可以看出,在实际应用中CNN应用受限于硬件与存储(如不能在无人机上挂几张Nvidia Titan Xp)。
所以必须有一种能在算法层面有效的压缩存储和计算量的方法。而MobileNet/ShuffleNet正为我们打开这扇窗。
本文按照网络提出的顺序依次介绍:
MobileNet v1 -> ShuffleNet v1 -> MobileNet v2 -> ShuffleNet v2
Group convolution
谈论起MoblieNet/ShuffleNet这些网络结构,就绕不开Group convolution,甚至可以认为这些网络结构只是Group convolution的变形而已。
那么什么是Group convolution?
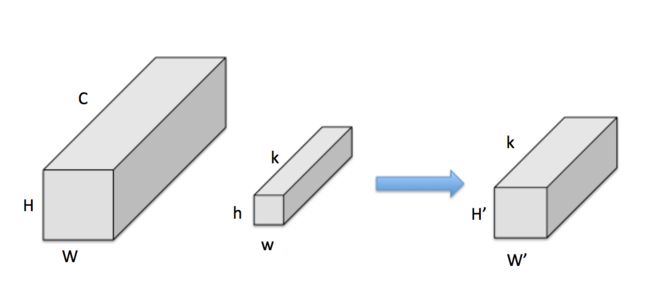

图2 convolution
假设有输入feature map,尺寸为 ,同时有 个 卷积核。对于一般卷积,输出feature map尺寸为 (这里不关心 和 )。

图3 Group convolution(group=2)
而Group convolution的实质就是将convolution分为 个独立的组,分别计算。即:
- 把input feature分为 组,每组尺寸为 ,假设可整除,下同
- 把kernel也分为 组,每组尺寸为
- 按顺序,每组input feature和kernel分别做普通卷积,输出 组 特征,即一共
其实Group convolution并不是什么新东西,早在AlexNet就使用了Group convolution,通过在conv2层设置group=2,将整个网络分为了两组(具体AlexNet网络结构请查看caffe官方给出的deploy文件)。
layer {
name: "conv2"
......
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
}
}
这是由于当时的GTX 580显存太小,没法放下整个网络,所以Alex采用Group convolution将整个网络分成两组后,分别放入一张卡进行训练而已。
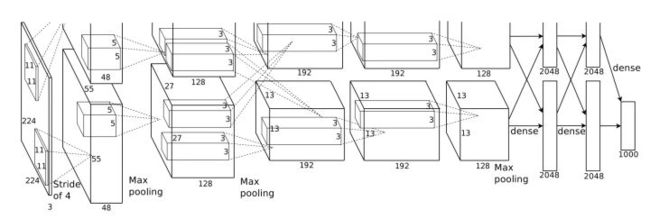
图4 AlexNet网络结构
MobileNet v1
MobileNet v1 paper
Mobilenet v1是Google于2017年发布的网络架构,旨在充分利用移动设备和嵌入式应用的有限的资源,有效地最大化模型的准确性,以满足有限资源下的各种应用案例。Mobilenet v1也可以像其他流行模型(如VGG,ResNet)一样用于分类、检测、嵌入和分割等任务提取图像卷积特征。
Mobilenet v1核心是把卷积拆分为Depthwise+Pointwise两部分。

图5
为了解释Mobilenet,假设有 的输入,同时有 个 的卷积。如果设置 且 ,那么普通卷积输出为 ,如图6。

图6 普通3x3卷积,k=2
Depthwise是指将 的输入分为 组,然后每一组做 卷积,如图7。这样相当于收集了每个Channel的空间特征,即Depthwise特征。

图7 depthwise卷积,g=k=3
Pointwise是指对 的输入做 个普通的 卷积,如图8。这样相当于收集了每个点的特征,即Pointwise特征。Depthwise+Pointwise最终输出也是 。

图8 pointwise卷积,k=2
这样就把一个普通卷积拆分成了Depthwise+Pointwise两部分。其实Mobilenet v1就是做了如下转换,如图9:
- **普通卷积:**3x3 Conv+BN+ReLU
- **Mobilenet卷积:**3x3 Depthwise Conv+BN+ReLU 和 1x1 Pointwise Conv+BN+ReLU
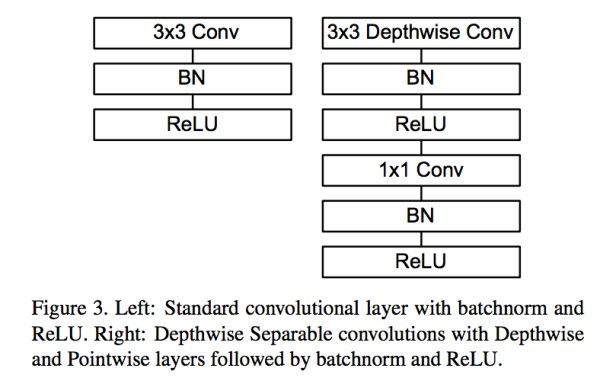
图9
那这样做有什么好处?对比一下不同卷积的乘法次数:
- 图6 普通卷积计算量为:
- 图7 Depthwise计算量为:
- 图8 Pointwise计算量为:
通过Depthwise+Pointwise的拆分,相当于将普通卷积的计算量压缩为:
当然,除了针对卷积优化外,Mobilenet v1还给出了基本网络结构,如图10。
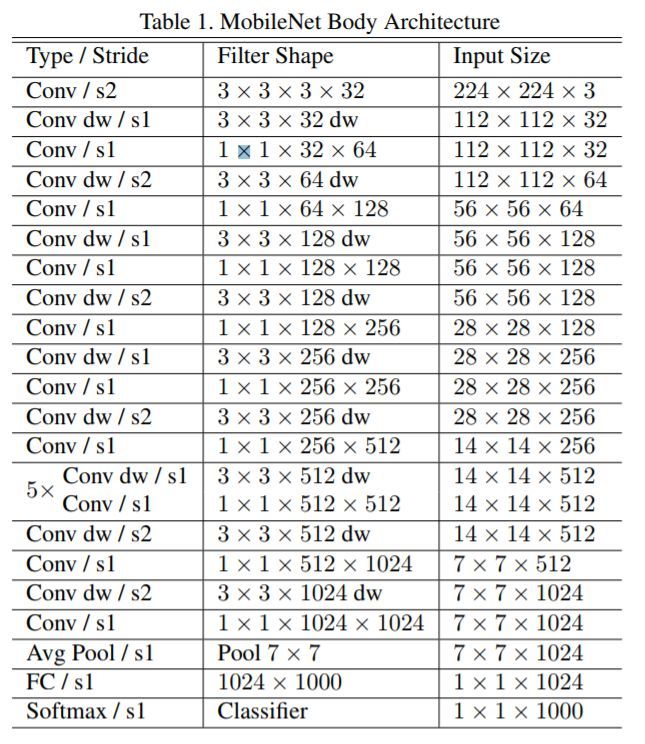
图10 MobileNet Body Architecture(alpha=1.0)
Mobilenet v1已经非常小了,但是还可以对图10 Architecture中的所有卷积层 数量统一乘以缩小因子 (其中 ![\alpha\in(0,1],典型值为1,0.75,0.5和0.25](https://www.zhihu.com/equation?tex=%5Calpha%5Cin%280%2C1%5D%EF%BC%8C%E5%85%B8%E5%9E%8B%E5%80%BC%E4%B8%BA1%EF%BC%8C0.75%EF%BC%8C0.5%E5%92%8C0.25) )以压缩网络。这样Depthwise+Pointwise总计算量可以进一降低为:
当然,压缩网络计算量肯定是有代价的。图11展示了 不同时Mobilenet v1在ImageNet上的性能。可以看到即使 时Mobilenet v1在ImageNet上依然有63.7%的准确度。
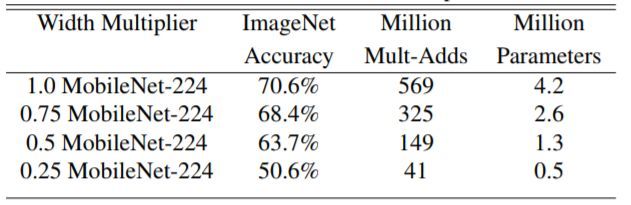
图11 MobileNet v1 alpha对比
图12展示Mobilenet v1 与GoogleNet和VGG16的在输入分辨率 情况下,准确度差距非常小,但是计算量和参数量都小很多。同时原文也给出了以Mobilenet v1提取特征的SSD/Faster R-CNN在COCO数据集上的性能,依然很厉害,就不列举了。
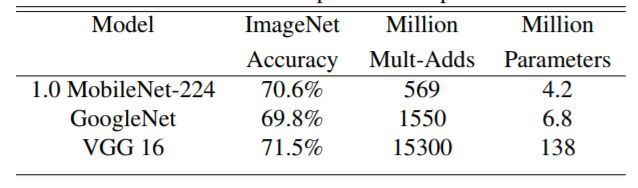
图12 MobileNet v1 vs GoogleNet / VGG16
总结一句,Mobilenet v1确实牛!这应该是作者知道的最有效的网络压缩方法了。反正实测超级好用。
ShuffleNet v1
ShuffleNet paper
ShuffleNet是Face++提出的一种轻量化网络结构,主要思路是使用Group convolution和Channel shuffle改进ResNet,可以看作是ResNet的压缩版本。
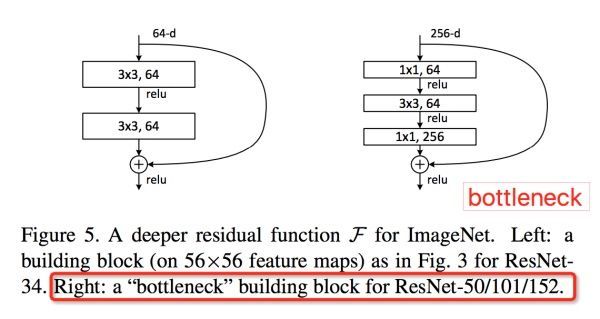
图13 ResNet bottlenect结构
这里简单介绍一下ResNet的bottleneck网络结构,如图13。注意Channel维度变化: ,宛如一个中间细两端粗的瓶颈,所以称为“bottleneck”。这种结构相比VGG,早已经被证明是非常效的,能够更好的提取图像特征。
图14展示了ShuffleNet的结构,其中(a)就是加入Depthwise的ResNet bottleneck结构,而(b)和(c)是加入Group convolution和Channel Shuffle的ShuffleNet的结构。

图14 ShuffleNet
那么ShuffleNet为何要这样做?既然是轻量化网络,我们还是来算算计算量。
假设输入feature为 , 所有的 卷积数为 , Depthwise卷积数为 ,Group convolution都分为 组。图14 (a)和(b)的网络乘法计算量:
- 图14(a) ResNet bottleneck:
- 图14(b) ShuffleNet stride=1结构:
相比原始加入Depthwise的ResNet缩小了很多的计算量。所以ShuffleNet相当于保留ResNet结构,同时又压低计算量的改进版。
这里解释下为何要做Channel Shuffle操作:
ShuffleNet的本质是将卷积运算限制在每个Group内,这样模型的计算量取得了显著的下降。然而导致模型的信息流限制在各个Group内,组与组之间没有信息交换,如图15,这会影响模型的表示能力。因此,需要引入组间信息交换的机制,即Channel Shuffle操作。同时Channel Shuffle是可导的,可以实现end-to-end一次性训练网络。
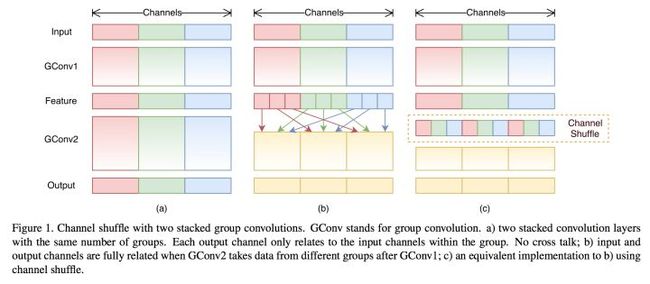
图15 Shuffle channel
当然,ShuffleNet有2个重要缺点:
- Shuffle channel在实现的时候需要大量的指针跳转和Memory set,这本身就是极其耗时的;同时又特别依赖实现细节,导致实际运行速度不会那么理想。
- Shuffle channel规则是人工设计出来的,不是网络自己学出来的。这不符合网络通过负反馈自动学习特征的基本原则,又陷入人工设计特征的老路(如sift/HOG等)。
这里还有一篇很棒的Face++自己的介绍:
为移动 AI 而生——旷视(Face++)最新成果 ShuffleNet 全面解读
MobileNet v2
MobileNet v2 paper
MobileNet V2是Google继V1之后提出的下一代轻量化网络,主要解决了V1在训练过程中非常容易特征退化的问题,V2相比V1效果有一定提升。
经过VGG,Mobilenet V1,ResNet等一系列网络结构的提出,卷积的计算方式也逐渐进化:
> (a) Regular convolution:AlexNet/VGG使用
> (b) Separable convolution block:拆分Regular convolution为Depth wise和Point wise
> (c) Separable with linear bottleneck:将ResNet bottleneck引入Separable convolution
> (d) bottleneck with expansion layer:将bottleneck结构反过来,相当于“两头细中间粗”
不过如果把这些基本卷积结构堆叠起来,(c)/(d)是完全一样的。
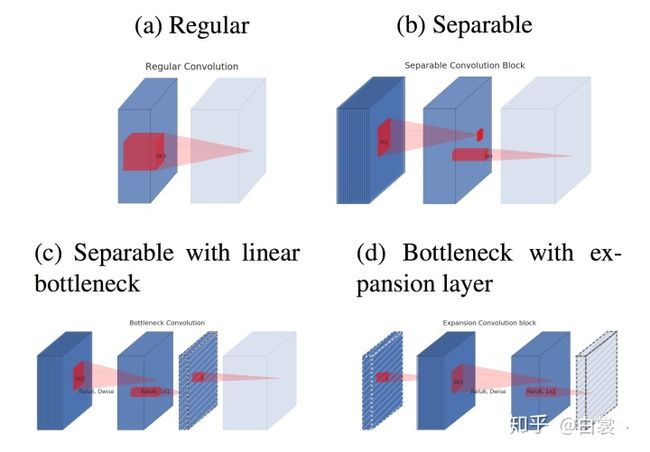
图16
看到这儿已经有了各种让然眼花缭乱的基本卷积结构,但是这些卷积结构是有的问题的:
问题1:ReLU造成的低维度数据坍塌(collapses)
Moblienet V2文中提出,假设在2维空间有一组由 个点组成的螺旋线 数据,经随机矩阵 映射到 维并进行ReLU运算,即:
再通过 矩阵的广义逆矩阵 将 映射回2维空间:
对比 和 发现,当映射维度 时,数据坍塌;当 时,数据基本被保存,如图17。虽然这不是严格的数学证明,但是至少说明:channel少的feature map不应后接ReLU,否则会破坏feature map。

图17
问题2:没有复用特征
在神经网络训练中如果某个卷积节点权重的值变为0就会“死掉”。因为对于任意输入,该节点的输出都是0。而ReLU对0值的梯度是0,所以后续无论怎么迭代这个节点的值都不会恢复了。而通过ResNet结构的特征复用,可以很大程度上缓解这种特征退化问题,如图18(这也从一个侧面说明ResNet为何好于VGG)。另外,一般情况训练网络使用的是float32浮点数;当使用低精度的float16时,这种特征复用可以更加有效的减缓退化。
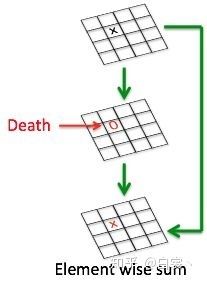
图18 复用特征可以减缓特征退化
基于上述两个问题,Mobilenet v2提出了Linear Bottlenecks+Inverted residual block作为网络基本结构,如图19。
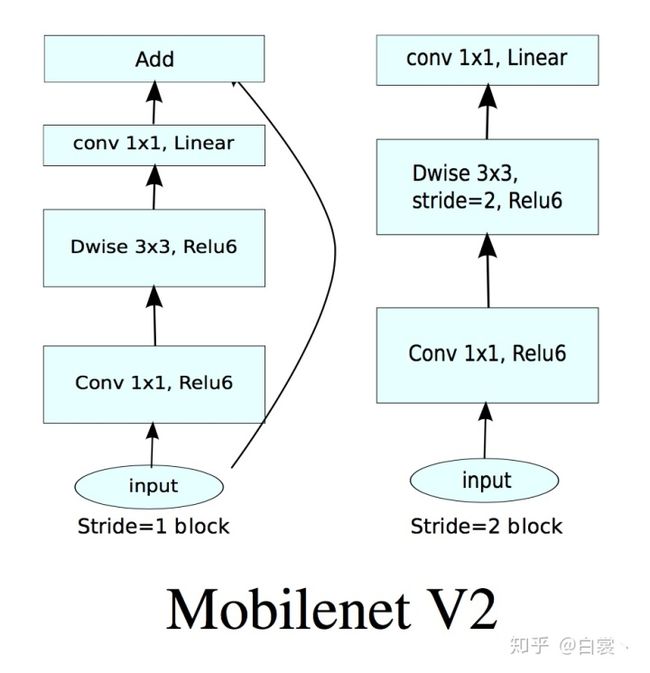
图19 Mobilenet v2基本卷积单元结构
理解之前的问题后看,其实Mobilenet V2使用的基本卷积单元结构有以下特点:
- 整体上继续使用Mobilenet V1的Separable convolution降低卷积运算量。
- 引入了特征复用结构。
- 采用Inverted residual block结构。该结构使用Point wise convolution先对feature map进行升维,再在升维后的特征接ReLU,减少ReLU对特征的破坏。

图18 Inverted residual block
当然文中依然给出了Mobilenet V2整体网络结构,如图19。其他细节与V1类似,就不赘述了。
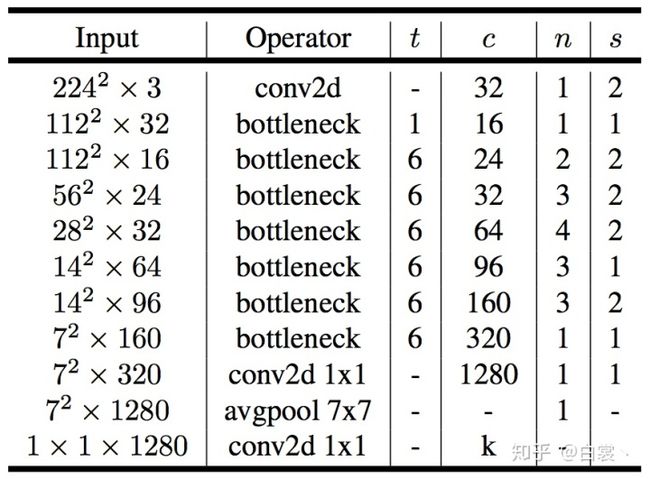
图19 Mobilenet V2网络结构
从实验效果看Mobilenet系列确实是良心之作,在大幅降低网络运算量的过程中基本保持性能不变,非常适合嵌入式平台使用。对有此类需求的朋友,建议试一试。
ShuffleNet v2
未完待续
注1:至于Xception,ResNeXt这些结构其实也和本文相关,但为了简化文章没有提及。有兴趣的朋友自行了解。
Xception:
Xception: Deep Learning with Depthwise Separable Convolutions
ResNeXt(ResNet v2):
Aggregated Residual Transformations for Deep Neural Networks
注2:目前Tensorflow官方已经发布了mobilenet,可以直接使用
Tensorflow slim mobilenet_v1
Tensorflow slim mobilenet_v2
最后要说的是:
作者只是根据自己的理解和工作经验写下此文,只作抛砖引玉用。
文章难免有偏差,望读者以怀疑的态度阅读,尽信书不如无书!