轻量化网络—— ShuffleNet_v1【论文笔记】
文章目录
-
- 1 前言
- 2 两大创新点
-
- 2.1 pointwise group convolution
- 2.2 channel shuffle
- 3 ShuffleNet Unit
- 4 ShuffleNet 网络结构
开始之前首先学习一个单词热热身:
shuffle 英[ˈʃʌfl]
v. 拖着脚走; (笨拙或尴尬地) 把脚动来动去; 坐立不安; 洗(牌);
n. 拖着脚走; 洗牌; 曳步舞;
1 前言
论文链接:https://arxiv.org/pdf/1707.01083.pdf
ShuffleNet是2017年由旷世科技提出的,它同样是一种着重应用于移动端的轻量化网络。ShuffleNet的核心采用了两种操作:pointwise group convolution和channel shuffle。我们知道分组卷积和深度可分离卷积都时用于减少模型计算成本的基本方法,分组卷积是由AlexNet首次提出的,而MobileNet系列网络中使用了深度可分离卷积,个人用一句话总结ShuffleNet:将分组卷积的思想应用于深度可分离卷积中的1×1卷积(Pointwise convolution),并且通过channel shuffle操作保证特征图各通道间的连通性。
“We notice that state-of-the-art architectures such as Xception and ResNeXt become less efficient in extremely small networks because of the costly dense 1×1 convolutions. We propose using pointwise group convolutions to reduce computation complexity of 1 × 1 convolutions.”
“To overcome the side effects brought by group convolutions, we come up with a novel channel shuffle operation to help the information flowing across feature channels.”
2 两大创新点
2.1 pointwise group convolution
我在笔记轻量化网络—— MobileNet_v1【论文笔记】中提到, 逐点卷积(pointwise convolution)使用了 output_channels个 维度为1×1×in_channels 的卷积核进行特征组合,用来将深度分离卷积后的特征图在通道方向上进行信息汇总,保证各通道间的特征信息共享交流,但是该1×1大小的卷积核的通道维数始终是与输入特征图的通道维数相同。
咦,既然用于提取特征的3×3大小的卷积核可以进行分组卷积,那么用于汇总通道方向上特征信息的1×1大小的卷积核也同样可以使用分组卷积,这个思想就是pointwise group convolution。
2.2 channel shuffle
但是又想到,对于输入特征图进行pointwise group convolution时,我们好像又切断了分到不同组的特征通道之间的特征信息共享交流,图下(a)所示,将输入分成红、绿、蓝三个组,进行pointwise group convolution后其输出仅与对应的三个组相关,不同组之间无信息交叉交流;
“It’s clear that outputs from a certain group only relate to the inputs within the group.”

那么怎么继续保持不同分组间的特征通道的特征信息交叉交流呢?channel shuffle可以解决该问题。它通过将每个分组后的通道再分成几组子通道,并将不同分组中的不同子通道进行混合(洗牌操作),那么就可以保证不同分组间的特征通道的特征信息可以共享。如上图(b)、(c)所示。
“We can first divide the channels in each group into several subgroups, then feed each group”
下图为混洗通道的具体做法及pytorch实现。(参考来源)

# 通道混洗的两种pytorch实现方法:
## 1 严格按论文的感觉
a = torch.randn(1,15,3,3)
batchsize, channels, height, width = a.size()
groups = 3
channels_per_group = int(channels /groups)
x = a.view(batchsize, groups, channels_per_group, height, width)
x = x.transpose(1, 2).contiguous()
x = x.view(batchsize, -1, height, width)
## 2
x = torch.randn(1,15,3,3)
N, C, H, W = x.size()
groups = 3
out = x.view(N, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous().view(N, C, H, W)
3 ShuffleNet Unit
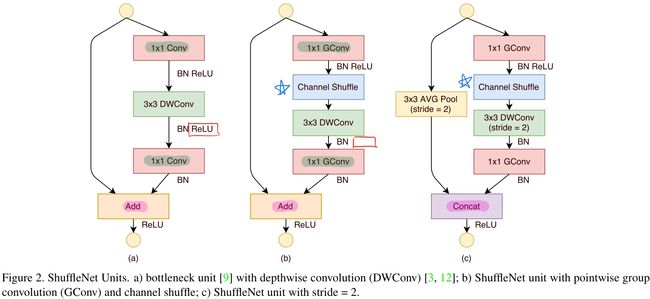
一个ShuffleNet Unit是通过对一个Resdual block进行改进后得到的,上图中图a)为一个Resdual block,图b)为输入输出特征图大小不变的ShuffleNet Unit,图c)为输出特征图大小为输入特征图大小一半的ShuffleNet Unit。
对于输入输出特征图大小不变的ShuffleNet Unit:
- 将第一个用于降低通道数的1×1卷积改为1×1分组卷积 +
Channel Shuffle; - 去掉原3×3深度卷积后的ReLU;
- 将第二个用于扩增通道数的1×1卷积改为1×1分组卷积;
对于输出特征图大小为输入特征图大小一半的ShuffleNet Unit:
- 将第一个用于降低通道数的1×1卷积改为1×1分组卷积 +
Channel Shuffle; - 令原3×3深度卷积的步长
stride=2, 并且去掉深度卷积后的ReLU; - 将第二个用于扩增通道数的1×1卷积改为1×1分组卷积;
- shortcut上添加一个3×3平均池化层
(stride=2)用于匹配特征图大小; - 对于块的输出,将原来的
add方式改为Concat方式。
对于第五点,原文中提到:“replace the element-wise addition with channel concatenation, which makes it easy to enlarge channel dimension with little extra computation cost. ”
4 ShuffleNet 网络结构

基于改进的ShuffleNet Unit,设计的ShuffleNet模型如上图所示。可以看到开始使用的普通的3x3的卷积和max pool层。然后是三个阶段,每个阶段都是重复堆积了几个ShuffleNet的基本单元。对于每个阶段,第一个基本单元采用的是stride=2,这样特征图width和height各降低一半,而通道数增加一倍。后面的基本单元都是stride=1,特征图和通道数都保持不变。对于基本单元来说,其中瓶颈层,就是3x3卷积层的通道数为输出通道数的1/4,这和残差单元的设计理念是一样的。
其中 g g g控制了group convolution中的分组数,分组越多,在相同计算资源下,可以使用更多的通道数,所以 g g g越大时,采用了更多的卷积核。这里给个例子,当 g = 3 g=3 g=3 时,对于第一阶段的第一个基本单元,其输入通道数为24,输出通道数为240,但是其stride=2,那么由于原输入通过avg pool可以贡献24个通道,所以相当于左支只需要产生240-24=216通道,中间瓶颈层的通道数就为216/4=54。其他的可以以此类推。当完成三阶段后,采用global pool将特征图大小降为1x1,最后是输出类别预测值的全连接层。
参考博客
欢迎关注【OAOA】
