【学习笔记】《深入浅出Pandas》第2章:数据结构
在本章,将深入了解Pandas的底层数据结构及其依赖的Numpy库的基础用法,还将学习数据生成操作。
文章目录
- 2.1 数据结构概述
-
- 2.1.1 什么是数据
- 2.1.2 什么是数据结构
- 2.1.3 小结
- 2.2 Python的数据结构
-
- 2.2.1 数字
- 2.2.2 字符串
- 2.2.3 布尔型
- 2.2.4 列表
- 2.2.5 元组
- 2.2.6 字典
- 2.2.7 集合
- 2.2.8 小结
- 2.3 Numpy
-
- 2.3.1 Numpy简介
- 2.3.2 数据结构
- 2.3.3 创建数据
- 2.3.4 数据类型
- 2.3.5 数组信息
- 2.3.6 统计计算
- 2.4 Pandas的数据结构
-
- 2.4.1 Series
- 2.4.2 DataFrame
- 2.4.3 索引
- 2.5 Pandas生成数据
-
- 2.5.1 导入Pandas
- 2.5.2 创建数据
- 2.5.3 生成Series
- 2.5.4 生成DataFrame
- 2.5.5 小结
- 2.6 Pandas的数据类型
-
- 2.6.1 数据类型查看
- 2.6.2 常见数据类型
- 2.6.3 数据检测
2.1 数据结构概述
2.1.1 什么是数据
2.1.2 什么是数据结构
数据结构(Data Structure)是组织数据、存储数据的方式。在计算机中,常见的数据结构有栈(Stack)、队列(Queue)、数组(Array)、链表(Linked List)、树(Tree)、图(Graph)等。
数组由相同类型元素的集合组成,对每一个元素分配一个存储空间,这些存储空间是连续的。每个空间都会有一个索引(index)来标识元素的存储位置。
现实数据往往由多个数组组成,它们共用一个行索引,组成二维数组,对应于数学中矩阵的概念。
2.1.3 小结
2.2 Python的数据结构
在标准的Python数据类型中,有些是可变的,有些是不可变的。不可变意味着你不能对它进行操作,只能读取。
不可变数据:Number(数字)、String(字符串)、Tuple(元组)。
可变数据:List(列表)、Dictionary(字典)、Set(集合)。
用Python内置的type()函数查看数据的类型,也可以用isinstance来判断数据是不是指定的类型,返回True和False。
2.2.1 数字
Python的数字类型可以存储数学中的各种数字,包括常见的自然数、复数中的虚数、无穷大数、正负数、带小数点的数、不同进制的数等。
数字的操作运算:+、 -、 *、 / 、 **(幂运算)、 %(取余)、 //(地板除,相除后只保留整数部分,即向下取整,但是如果其中一个操作数为负数,则取负无穷大方向距离结果最近的整数)
2.2.2 字符串
可以对字符串作切片访问(同时适用于字符、列表、元组等)。字符串从左到右,索引从0开始;从右往左,索引从-1开始。可以取字符串中的片段,切片索引按左闭右开的原则:
var = 'Hello World!'
var[0] # 'H'
var[-1] # '!'
var[-3:-1] # 'ld'
var[1:7] # 'ello W' (有个空格,不包含最后一位索引7)
var[6:] # 'World!' (只指定开头,包含后面所有的字符)
var[:] # 'Hello World!' (相当于复制)
var[0:5:2] # 'Hlo'(2为步长,相当于按2的倍数取)
var[1:7:3] # 'eo'
var[::-1] # '!dlroW olleH' (实现反转字符功能)
下面是常见的字符操作:
len('good') # 4 (字符长度)
'good'.replace('g', 'G') # 'Good' (替换字符)
'山-水-风-雨'.split('-') # ['山', '水', '风', '雨'](指定字符分割)
'好山好水好风光'.split('好') # ['', '山', '水', '风光']
'-'.join(['山', '水', '风', '雨']) # '山-水-风-雨'
'good'.upper() # 'GOOD' (全转大写)
'GOOD'.lower() # 'good' (全转小写)
'Good Bye'.swapcase() # 'gOOD bYE' (大小写互换)
'good'.capitalize() # 'Good' (首字母转大写)
'good'.islower() # True (是否全是小写)
'good'.isupper() # False (是否全是大写)
'3月'.zfill(3) # '03月'(指定长度,如长度不够,前面补0)
2.2.3 布尔型
在Python里,True和False代表真和假,它们都属于布尔型,布尔型也只有这两个值。
2.2.4 列表
列表是用方括号组织起来的,每个元素用逗号隔开,每个具体元素可以是任意类型的内容。通常元素的类型是相同的,但也可以不同。
列表和字符串一样支持切片访问,可以将字符串中的一个字符当成列表中的一个元素。
以下是常见的列表操作:
a = [1, 2, 3]
len(a) # 3 (元素个数)
max(a) # 3 (最大值)
min(a) # 1 (最小值)
sum(a) # 6 (求和)
a.index(2) # 1 (指定元素位置)
a.count(1) # 1 (求元素的个数)
for i in a: print(i) # 迭代元素
sorted(a) # 返回一个排序的列表,但不改变原列表
any(a) # True (是否至少有一个元素为真)
all(a) # True (是否所有元素为真)
a.append(4) # a: [1, 2, 3, 4] (增加一个元素)
a.pop() # 每执行一次,删除最后一个元素
a.extend([9, 8]) # a:[1, 2, 3, 9, 8] (与其他列表合并)
a.insert(1, 'a') # a:[1, 'a', 2, 3] (在指定索引位置插入元素, 索引从0开始)
a.remove('a') # 删除第一个指定元素
a.clear() # [] (清空)
另外,需要掌握列表的推导式,可以由可迭代对象快速生成一个列表。推导式就是用for循环结合if表达式生成一个列表。
# 将一个可迭代的对象展开,形成一个列表
[i for i in range(5)] # [0, 1, 2, 3, 4]
# 将结果进行处理
['第'+str(i) for i in range(5)] # ['第0', '第1', '第2', '第3', '第4']
# 可以进行条件筛选,实现取偶数
[i for i in range(5) if i%2==0] # [0, 2, 4]
# 拆开字符,过滤空格,全部变成大写
[i.upper() for i in 'Hello world' if i != ' ']
# ['H', 'E', 'L', 'L', 'O', 'W', 'O', 'R', 'L', 'D']
2.2.5 元组
元组和列表类似,二者区别是元组不可以改变,而列表可变。元组使用圆括号()。
元组的索引机制和列表一样。
另外,需要掌握元组的解包操作。
x = (1, 2, 3, 4, 5)
a, *b = x # a占第一个,剩余的组成列表全部给b
# a -> 1
# b -> [2, 3, 4, 5]
# a, b -> (1, [2, 3, 4, 5])
a, *b, c = x # a占第一个,c占最后一个,剩余的组成列表全部给b
# a -> 1
# b -> [2, 3, 4]
# c -> 5
# a, b, c -> (1, [2, 3, 4, 5], 5)
2.2.6 字典
字典由键值对(key-value)组成。
用以下方法定义:
d = {} # 定义空字典
d = dict() # 定义空字典
d = {'a': 1, 'b': 2, 'c': 3}
d = {'a': 1, 'a': 1, 'a': 1} # {'a': 1} key不能重复, 重复时取最后一个
d = {'a': 1, 'b': {'x':3}} # 嵌套词典
d = {'a': [1, 2, 3], 'b': [4, 5, 6]} # 嵌套列表
# 以下均可定义如下结果
# {'name': 'Tom', 'age': 18, 'height': 180}
d = dict(name='Tom', age=18, height=180)
d = dict([('name', 'Tom'), ('age', 18), ('height', 180)])
d = dict(zip(['name', 'age', 'height'], ['Tom', 18, 180]))
访问字典的方法如下:
d['name'] # 'Tom' (获取键的值)
d['age'] = 20 # 将age的值更新为20
d['Female'] = 'man' # 增加属性
d.get('height', 180) # 180
# 嵌套取值
d = {'a': {'name': 'Tom', 'age':18}, 'b':[4, 5, 6]}
d['b'][1] # 5
d['a']['age'] # 18
常用的字典操作方法如下:
d.pop('name') # 'Tom' (删除指定key)
d.popitem() # 随机删除某一项
del d['name'] # 删除键值对
d.clear # 清空字典
# 按类型访问,可迭代
d.keys() # 列出所有键
d.values() # 列出所有制
d.items() # 列出所有键值对元组(k, v)
# 操作
d.setdefault('a', 3) # 插入一个键并给定默认值3,如果不指定,则为None
d1.update(dict2) # 将字典dict2的键值对添加到字典dict
# 如果键存在,则返回其对应值;如果键不在字典中,则返回默认值
d.get('math', 100) # 100
d2 = d.copy() # 深拷贝,d变化不影响d2
d = {'a': 1, 'b': 2, 'c': 3}
max(d) # 'c' (最大的键)
min(d) # 'a' (最小的键)
len(d) # 3 (字典的长度)
str(d) # "{'a': 1, 'b': 2, 'c': 3}" (字符串形式)
any(d) # True (只要一个键为True)
all(d) # True (所有键都为True)
sorted(d) # ['a', 'b', 'c'] # (所有键的列表排序)
2.2.7 集合
集合是存放无顺序、无索引内容的容器。用花括号{}表示。它可以消除重复元素,也可以作交、差、并、补等数学运算。
以下是它的定义方法:
s = {} # 空集合
s = {'5元', '10元', '20元'} # 定义集合
s = set() # 空集合
s = set([1, 2, 3, 4, 5]) # {1, 2, 3, 4, 5} (使用列表定义)
s = {1, True, 'a'}
s = {1, 1, 1} # s = {1} (去重)
type(s) # set (类型检测)
集合没有顺序,没有索引,所以无法指定位置去访问,但可以用for遍历的方式进行读取。
以下是常用操作:
s = {'a', 'b', 'c'}
# 判断是否有某个元素
'a' in s # True
# 添加元素
s.add(2) # {2, 'a', 'b', 'c'}
s.update([1, 3, 4]) # {1, 2, 3, 4, 'a', 'b', 'c'}
# 删除和清空元素
s.remove('a') #{'b', 'c'}
s.discard('3') # 删除一个元素,无则忽略,不会报错
s.clear() # set() (清空)
集合的数学运算如下:
s1 = {1, 2, 3}
s2 = {2, 3, 4}
# 交集
s1 & s2 # {2, 3}
s1.intersection(s2) # {2, 3}
s1.intersection_update(s2) #{2, 3} (交集,会覆盖s1)
# 并集
s1 | s2 # {1, 2, 3, 4}
s1.union(s2) # {1, 2, 3, 4}
# 差集
s1.difference(s2) # {1}
s1.difference_update(s2) # {1} (差集,会覆盖s1)
# 交集之外
s1.symmetric_difference(s2) # {1, 4}
# 是否没有交集
s1.isdisjoint(s2) # False
# s1是否是s2的子集
s1.issubset(s2) # False
# s1是否是s2的超集,即s1是否包含s2中的所有元素
s1.issuperset(s2) # False
2.2.8 小结
2.3 Numpy
Numpy是Python的一个高性能矩阵计算的科学计算库。它的主要用途是以数组的形式进行数据操作和数学运算。Pandas的数据结构和运算的底层工作交由Numpy完成。
2.3.1 Numpy简介
Numpy提供了两个基本对象。
ndarray:存储数据的多维数组。
ufunc: 对数组进行处理的函数。
2.3.2 数据结构
ndarray提供了一维到三维的数据结构,所有元素必须是相同类型。
2.3.3 创建数据
import numpy as np
# 创建数据 一维 array([1, 2, 3])
np.array([1, 2, 3])
np.array((1, 2 ,3))
# 二维 array([[1, 2],
# [1, 2]])
np.array(((1, 2), (1, 2)))
np.array(([1, 2], [1, 2]))
以下是常见的数据生成函数:
np.arange(10) # 10个,不包括10,步长为1
np.arange(3, 10, 0.1) # 3-9,步长为0.1
np.linspace(2.0, 3.0, num=5, endpoint=False) # 2.0-3.0,生成均匀的5个值,不包括3.0
np.random.randn(6, 4) # 返回一个6*4的随机数组, 浮点型
np.random.randint(3, 7, size=(2, 4)) # 指定范围、指定形状的数组,整型
# 创建值为0的数组
np.zeros(6) # 6个浮点0.
np.zeros((5, 6), dtype=int) # 5*6整型0
np.ones(4)
np.empty(4)
# 创建一份和目标结构相同的0值数组
np.zeros_like(np.arange(6))
np.ones_like(np.arange(6))
np.empty_like(np.arange(6))
np.empty用法
2.3.4 数据类型
np.int64 # 有符号64位整型
np.float32 # 标准双精度浮点类型
np.complex # 由128位的浮点数组成的复数类型
np.bool # bool类型(True or False)
np.object # Python中的object类型
np.string 固定长度的string类型
np.unicode # 固定长度的unicode类型
np.NaN # np.float的子类型
np.nan
2.3.5 数组信息
n.shape() # 数组形状,返回值是一个元组
n.shape = (4, 1) # 改变形状
a = n.reshape((2, 2)) # 改变原数组的形状,创建一个新数组
n.dtype # 数据类型
n.ndim # 维度数
n.size # 元素数
np.typeDict # np的所有数据类型
2.3.6 统计计算
np.array([10, 20, 30, 40])[:3] # 切片
a = np.array([10, 20, 30, 40])
b = np.array([1, 2, 3, 4])
a + b # array([11, 22, 33, 44]) (矩阵相加)
a.max()
a.min()
a.sum()
b.sum(axis=1) # 多维可以指定方向
a.std()
a.all # True
a.cumsum() # array([10, 30, 60, 100])
2.4 Pandas的数据结构
Pandas提供Series和DataFrame作为数组数据的存储框架。
| 名称 | 维度数据 | 描述 |
|---|---|---|
| Series | 1 | 带标签的一维同构数组 |
| DataFrame | 2 | 带标签的、大小可变的二维异构表格 |
注意:Pandas之前支持的三维面板(Panel)结构已不再支持,可以使用多层索引形式来实现。
2.4.1 Series
Series(系列、数列、序列)是一个带有标签的一维数组,这一系列连续的数据代表了一定的业务意义。它是Pandas最基础的数据结构。
中国 14.34
美国 21.43
日本 5.08
dtype:float64
其中,国家是标签(索引),不是具体的数据,起到解释、定位数据的作用。如果没有标签,只是一个数据,不具有业务意义。
2.4.2 DataFrame
DataFrame(数据框),一个二维数据结构:

第一行是表头(字段名),代表数据属性;
第一列是索引,是这行数据所描述的主体,也是这条数据的关键。
典型的DataFrame结构如下:
人口 GDP
中国 13.97 14.34
美国 3.28 21.43
日本 1.26 5.08
2.4.3 索引
在后续内容中,不同场景下可能会对索引使用以下名称:
- 索引(index):行和列上的标签,标识二维数据坐标的行索引和列索引。默认状况下,指的是每一行的索引。如果是Series,那只能是行上的索引。列索引又称字段名、表头。
- 自然索引、数字索引:行和列的0~n(n为数据长度-1)形式的索引,数据天然具有的索引形式。
- 标签(label):行索引和列索引,如果是Series,那只能是行上的索引。
- 轴(axis):仅在DataFrame结构中,代表数据方向,如行和列,用0代表列(默认),1代表行。
2.5 Pandas生成数据
2.5.1 导入Pandas
import pandas as pd
import numpy as np
2.5.2 创建数据

pd.DataFrame()是一个字典,每条数据为一个Series,键为表头(列索引),值为具体数据。
DataFrame可以容纳Series,所以在定义DataFrame时可以使用Series,也可以利用Numpy的方法。
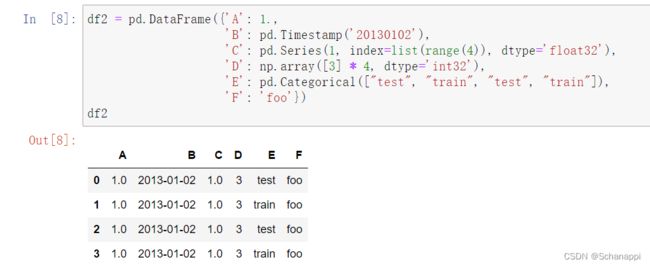 从DataFrame中选取一列就会返回一个Series,选择多列返回的就是DataFrame:
从DataFrame中选取一列就会返回一个Series,选择多列返回的就是DataFrame:

单独创建一个Series:

使用type函数可以查看数据类型:

2.5.3 生成Series
Series是一个带有标签的一维数组,它可以由任何类型数据构成。轴标签 成为索引,它是Pandas最基础的数据结构。
创建方式如下:
s = pd.Series(data, index=index)
data可以是Python对象、Numpy的ndarray、一个标量(定值,如8)。
index是轴上的一个列表,必须与data的长度相同,如果没有指定,则自动从0开始,表示为[0, …, len(data)-1]。
(1)使用列表和元组:
pd.Series(['a', 'b', 'c', 'd', 'e'])
pd.Series(('a', 'b', 'c', 'd', 'e'))
(2)使用ndarray:
# 由索引分别为a、b、c、d和e的5个随机浮点数组成
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
s.index # 查看索引
s = pd.Series(np.random.randn(5)) # 未指定索引
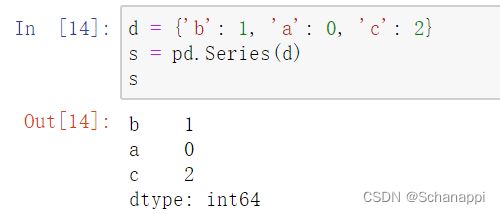
(3)使用字典:
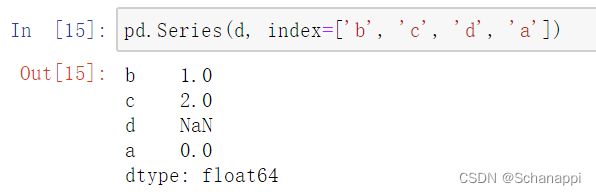
如果指定索引,则会按照索引顺序,如果有无法和索引对应的值,会产生缺失值:
(4)使用标量:
对于一个具体的值,如果不指定索引,则其长度为1;如果指定索引,则其长度为索引的数量,每个索引的值都是它。

2.5.4 生成DataFrame
DataFrame是二维数据结构,有多个数据列,由多个Series组成。
格式定义如下:
df = pd.DataFrame(data=None, index=None, columns=None)
# data:具体数据,结构化或同构的ndarray、可迭代对象、字典或DataFrame
# index:索引,类似数组的对象,支持解包,如果没有指定,会自动生成RangeIndex(0, 1, 2, ..., n)
# columns:列索引(表头),如果没有指定,会自动生成RangeIndex(0, 1, 2, ..., n)
# 此外,还可以用dtype指定数据类型,如果没有指定,系统会自动推断。
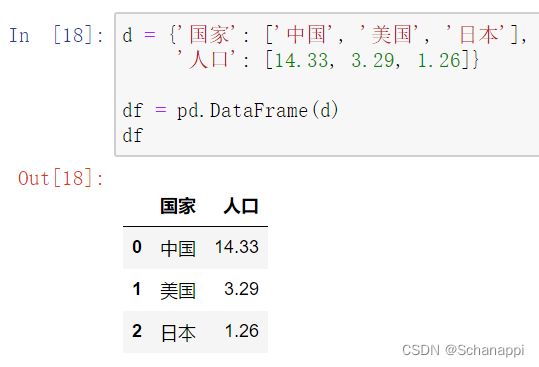
(1)字典:
字典中的键为列名,值一般为一个或元组,是具体数据。
如果生成的时候指定了索引名称,会使用指定的索引名,如a、b、c:

(2)Series组成的字典:
字典里的一个键值对为一列数据,键是列名,值是一个Series:

(3)字典组成的列表:
由字典组成的一个列表,每个字典是一行数据,指定索引后会使用指定索引:
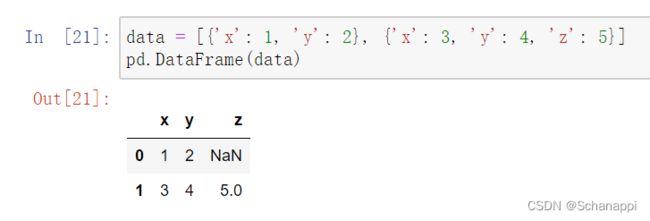
(4)Series生成:
一个Series会生成只有一列的DataFrame:
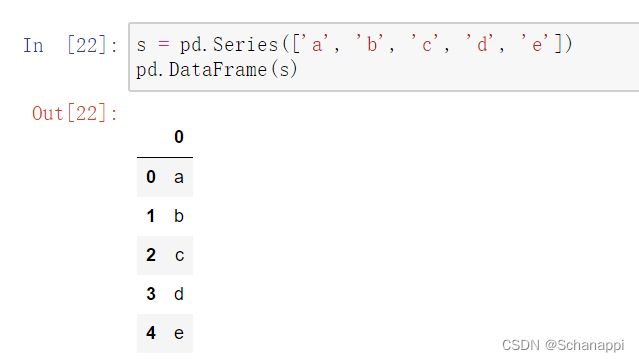
(5)其他方法
以下两种方法可以从字典和列表格式中取得数据:
# 从字典里生成
pd.DataFrame.from_dict({'国家': ['中国', '美国', '日本'], '人口': [13.97, 3.28, 1.26]})
# 从列表、元组、ndarray中生成
pd.DataFrame.from_records([('中国', '美国', '日本'), (13.97, 3.28, 1.26)])
# 列内容为一个字典
pd.json_normalize(df.col)
df.col.array(pd.Series)
2.5.5 小结
本节介绍了DataFrame和Series结构数据的生成。
在实际业务中一般不需要我们生成数据,而是有已经采集好的数据集,直接加载到DataFrame即可。
2.6 Pandas的数据类型
2.6.1 数据类型查看
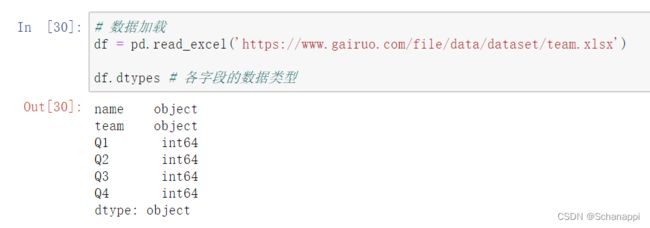
查看具体字段的类型:
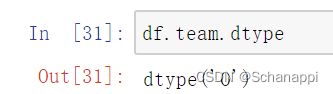
df.team是一个Series,所以使用的是dtype。
2.6.2 常见数据类型
默认数据类型是int64和float64,文字类型是object。
常见类型如下:
float
int
bool
datetime64[ns]
datetime64[ns, tz]
timedelta64[ns]
timedelta[ns]
category
object
string
2.6.3 数据检测
使用类型判断方法检测数据的类型是否与该方法中指定的类型一致,如果一致,则返回True,注意传入的是一个Series:
pd.api.types.is_bool_dtype(s)
pd.api.types.is_categorical_dtype(s)
pd.api.types.is_datetime64_any_dtype(s)
pd.api.types.is_datetime64_ns_dtype(s)
pd.api.types.is_datetime64_dtype(s)
pd.api.types.is_float_dtype(s)
pd.api.types.is_int64_dtype(s)
pd.api.types.is_numerica_dtype(s)
pd.api.types.is_object_dtype(s)
pd.api.types.is_string_dtype(s)
pd.api.types.is_timedelta64_dtype(s)