推荐系统笔记(十四):极简图对比学习方法SimGCL
背景
SimGCL算法是在基于LightGCN图卷积学习算法的backbone之上,并针对SGL对比学习算法进一步研究,解释了并证明了对比学习中对图结构的改变的作用不大,而影响实验效果的主要因素在于损失函数和嵌入分布均匀性。
论文链接:https://arxiv.org/pdf/2112.08679.pdf
论文的主要贡献有:
(1)揭示了在基于对比学习范式的推荐模型中,对比学习通过学习更统一的用户/项目表示来进行推荐,可以缓解流行度的偏差。
(2)揭示了过去被认为是必要的图增强操作在推荐领域只是起到了很小的作用。
思想
在对比学习图卷积推荐算法SGL中,使用了三种方法进行图增强,包括随机去除一些点和对应的边(ND),随机取出一些边(ED),还有每一层layer都随机去除一些点和边(RW),如下图所示:
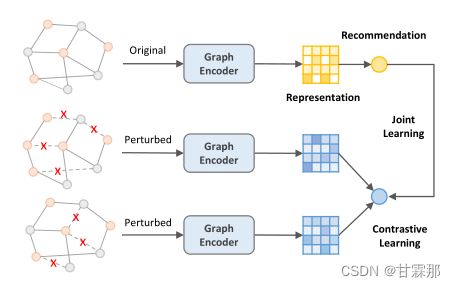
但是这样有效的原因尚不明确,SimGCL的作者发现图增强操作的drop rate在很高的时候依然会有很好的效果,这与主观上的认知相违背,经过消融实验证明了图增强操作对于实现效果的作用微乎其微,反而增大了计算量和复杂度,如下所示:
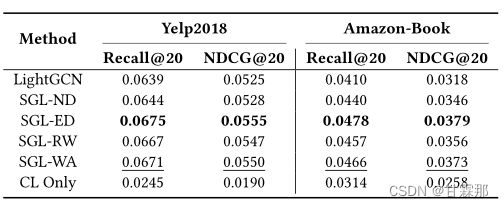
其中的SGL-WA就是取消了图增强但损失函数不变的方法,效果和最佳的图增强之间的差距在0.01之内,甚至可以忽略不计,可见图增强并非必须的操作,那么为什么SGL的效果相比于LightGCN的效果要好很多呢?
在SGL中,相比于LightGCN,SGL还额外改变了损失函数,使用了InfoNCE loss+BPR loss+Reg Loss三个损失的方法,经过实验发现SimGCL的结果的确要更好,速度要更快。
为什么损失函数能够得到这么好的效果呢?作者还做了对比试验CL only就是损失函数使用的是完全均匀的损失,将i和j之间的相似度计算变为1,这样会让嵌入在各个嵌入维度中是无差别的,就会呈现出完全均匀性,但从上图可以看出完全均匀性导致很差的效果。作者将不同方法得到的嵌入进行投影后绘制在二维平面上:

可见Cl only几乎完全均匀,但为什么效果会很差呢?作者的确提出,SGL优于LightGCN的主要原因在于优化对比损失函数可以学习到更均匀的分布,可以缓解流行性偏差。但是经过重写CL only的损失函数:

我们可以发现因为 1/ 是一个常数,优化CL损失实际上是最小化不同节点嵌入Zi和Zj和之间的余弦相似性,这将使得连接的节点远离表示空间中的那些“高度”中心节点,因此,即使在推荐损失的影响下,也会导致更均匀的分布,我们可以得出结论:分布的均匀性是对SGL中的推荐性能有决定性影响的潜在因素,而不是基于dropout的图增强,可以简单理解为提高了泛化能力。
我们可以认为均匀性和性能之间的正相关仅在有限的范围内保持。对均匀性的过度追求会忽略交互和相似用户/项目的亲密度,降低推荐性能。
原理
SimGCL是基于SGL和LightGCN的基础上的,关于这连个算法可以参考我的博客:
推荐系统笔记(五):lightGCN算法原理与背景_甘霖那的博客-CSDN博客推荐系统笔记(九):SGL --利用自监督对比学习缓解推荐系统长尾效应_甘霖那的博客-CSDN博客
SimGCL算法没有使用SGL的图增强算法,而是保留了SGL的损失函数,即InfoNCE Loss+BPR Loss+Reg Loss,而其余的部分使用的仍然是LightGCN的backbone,包括图计算传播,参数训练,邻接图计算等。
但与此同时,为了提高嵌入的均匀性,提高模型的鲁棒性和泛化能力,作者针对每一层图卷积最后的嵌入都加入了噪声。噪声满足以下两个条件:
![]()
![]()
即噪声要在数值上等于半径为 的超球面上的点,并且规定了噪声的方向必须与嵌入的方向相同,防止添加噪声导致误差变大,从而造成较大误差。直观理解可以参照下图:

其中![]() 和
和![]() 就是噪声添加后的方向,可见它们仍然处于同一个象限,相比于原来的的嵌入方向偏差并不太大,并且偏差的半径大小都是 ,并且应该满足均匀分布。遵循SGL采用LightGCN作为图编码器来传播节点信息,并由于其简单的结构性和有效性而放大偏差的影响。在每一层,对当前节点嵌入施加不同比例的随机噪声。最终扰动的节点表示可以被学习为:
就是噪声添加后的方向,可见它们仍然处于同一个象限,相比于原来的的嵌入方向偏差并不太大,并且偏差的半径大小都是 ,并且应该满足均匀分布。遵循SGL采用LightGCN作为图编码器来传播节点信息,并由于其简单的结构性和有效性而放大偏差的影响。在每一层,对当前节点嵌入施加不同比例的随机噪声。最终扰动的节点表示可以被学习为:
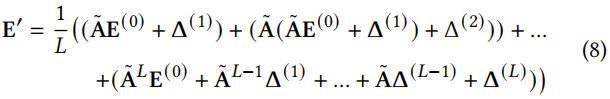
作者还添加了 和 两个参数来调节模型的均匀性做为超参数进行微调:
和 两个参数来调节模型的均匀性做为超参数进行微调:

经过实验作者证明了通过将 固定在0.1,将 更改为图8中所示的一组值。可以看出,随着 的增加,SimGCL的性能从一开始开始提高,在Douban-Book上 = 0.2、Yelp2018上 = 0.5、Amazon-Book上 = 2 时逐渐达到峰值。之后,它开始下降。此外,与图9相比,虽然 和 在相同范围内进行了调优,但在图8中观察到更显著的变化,这表明 可以提供一个更好地细粒度调节,超出仅调优 。
同时太大的的 会导致一个更均匀的分布,这有助于消除偏差。但是,当它太大时,推荐任务就会受到阻碍,因为连接节点之间的高相似性不能反映在过均匀的分布上。
在我个人实验中也针对这两个参数进行了网格搜索调优,最终得到了理想的结果。
总结
(1)在基于CL的推荐模型中,CL的损失是核心,而图的增强只起次要作用。
(2)优化CL损失可以得到更均匀的表示分布,能在推荐的场景中帮助消除偏差。
(3)通过在表示中加入有向随机噪声,进行不同的数据增强和对比,可以显著提高推荐能力。
代码复现:后几篇博客讲述。