python 性能优化实例练习一——爬虫、多线程和Cython
以下内容是根据Fernando Doglio写的《Python性能分析与优化》第8章 付诸实践中的内容手动尝试的实际练习记录。在这本书中对Python方面性能优化进行了比较全面的介绍,包括优化方法、优化策略、优化脚本等,个人感觉比较适合对Python有一定熟练度,但不太了解怎么优化的人入门。
在这里强烈推荐需要对Python代码进行优化的小伙伴们学习原书,在我的资源中也有代码等的相关整理。
目录
- 0. 前言
- 1. 第一部分——代码撰写
-
- 1. 1 主要应用到的库
- 1. 2 代码和运行结果
- 2. 第二部分——多线程优化IO操作
-
- 2.1 代码和运行结果
- 3. 第三部分——使用Cython优化数据分析
-
- 3.1 Cython是什么
- 3.2 如何安装Cython
- 3.3 Cython怎么用
-
- 3.3.1 代码和运行结果
- 3.4 Cython参考链接
0. 前言
-
第一部分——代码撰写
这部分的主要任务是抓取科幻与灵异网(Science Fiction & Fantasy, http://scifi.stackexchange.com/)上的数据,主要抓取的是问题的标题,问题的正文,作者(原书中答案列表信息,我这里进行了省略)信息最后生成json文件。另外我也没有用性能分析工具分析性能,而是直接根据书中的内容进行优化。
关键词:爬虫、获取网页信息(gets)、html、json -
第二部分——多线程优化IO操作
对第一部分进行速度上的优化。
关键词:多线程、threading -
第三部分——使用Cython优化数据分析
这部分是对于第一部分生成的json文件进行数据分析,分析的问题有返回提问问题数量最多的作者排名、返回使用最常用词组数量最多的问题排名、返回问题标题中最常见的主题排名。Cython, 一种优化过的静态编译器, 可以让我们写静态代码, 并轻松借助C和C++的力量
关键词:Cython
原书中是提供代码的,但在实际使用过程中不太理想,所以对代码进行了一部分修改。
1. 第一部分——代码撰写
1. 1 主要应用到的库
-
BeautifulSoup
它是一个工具箱,通过解析文档为用户提供需要抓取的数据。
对格式进行转换,方便抓取?代码中涉及很多对html中信息的抓取,由于个人不太会html和CSS,所以参考了文章soup.select()函数的使用用法,另外转换后的数据一定要是Python支持的数据格式不然会出错(如果还是HTML格式的数据,在转换成JSON过程中就会报错,但是string格式就不会)。
具体实现方式我是通过单步调试,查看每个数据的结果,再结合“soup.select()函数的使用用”这篇文章选择出我所需要的数据。 -
requests
-
json
今年差不多已经遇到了五六次json格式了,python中json库的使用可以参考Python JSON。
1. 2 代码和运行结果
from bs4 import BeautifulSoup
import requests
import json
SO_URL = "http://scifi.stackexchange.com"
QUESTION_LIST_URL = SO_URL + "/questions"
# http://scifi.stackexchange.com/questions
MAX_PAGE_COUNT = 1
global_results = [] # 用于存储从网站上提取到的数据
initial_page = 1 # 首页就是第一页
# 问题的作者
def get_author_name(body):
# link_name = body.select(".user-details a")
# if len(link_name) == 0:
# text_name = body.select(".user-details")
# return text_name[0].text if len(text_name) > 0 else 'N/A'
# else:
# return link_name[0].text
link_name = body['href']
link_name = link_name.split('/')[-1]
return link_name
# 问题的内容
def get_question_answers(body):
answers = body.select(".answer")
a_data = []
if len(answers) == 0:
return a_data
for a in answers:
data = {
'body': a.select(".post-text")[0].get_text(),
'author': get_author_name(a)
}
a_data.append(data)
return a_data
def get_question_data(url):
print("Getting data from question page: %s " % url)
resp = requests.get(url)
if resp.status_code != 200:
print("Error while trying to scrape url: %s" % url)
return
body_soup = BeautifulSoup(resp.text)
# 定义一个将被转换成JSON格式的输出词典
q_data = {
# 问题的标题
# 'title': body_soup.select('title')[0].text,
'title': body_soup.select('title')[0].text,
# 问题的正文 这个有bug的,就是如果问题正文有两段,那么只能取第一段
'body': body_soup.select('.s-prose p')[0].text,
# 作者
'author': get_author_name(body_soup.select(".user-gravatar32 a")[0]),
# 答案列表
# 'answers': get_question_answers(body_soup)
}
return q_data
def get_questions_page(page_num, partial_results):
print("=====================================================")
print(" Getting list of questions for page %s" % page_num)
print("=====================================================")
url = QUESTION_LIST_URL + "?sort=newest&page=" + str(page_num)
# url = http://scifi.stackexchange.com/questions?sort=newest&page=1
resp = requests.get(url)
if resp.status_code != 200:
print("Error while trying to scrape url: %s" % url)
return
body = resp.text
main_soup = BeautifulSoup(body)
# 获取每个问题的网络链接
# questions = main_soup.select('.question-summary .question-hyperlink')
questions = main_soup.select('.s-post-summary--content .s-link')
urls = [SO_URL + x['href'] for x in questions]
# urls = http://scifi.stackexchange.com/questions/269140/manwha-manga-where-the-main-female-character-can-see-the-future
for url in urls:
q_data = get_question_data(url)
partial_results.append(q_data)
# 递归进行下一页搜索
if page_num < MAX_PAGE_COUNT:
get_questions_page(page_num + 1, partial_results)
get_questions_page(initial_page, global_results)
with open('scrapping-results.json', 'w') as outfile:
json.dump(global_results, outfile, indent=4)
print('----------------------------------------------------')
print('Results saved')
# 正常情况下会把爬取到的数据放入scrapping-results.json
代码运行成功后,会出现一个json文件:
![]()
文件里的内容:
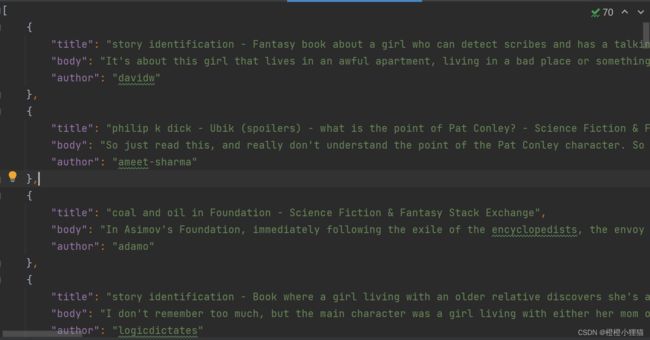
注意:代码可能存在一些时效性的,网站内容更新后json文件里的内容会与我的不同,另外如果原网站的html修改,可能会导致运行错误。
2. 第二部分——多线程优化IO操作
网络爬虫脚本基本算是一个IO密集型的循环任务, 通过最少的处理步骤从互联网上获取数据。 因此, 我们可以找到的第一条也是最符合逻辑的一条优化需求, 就是网络爬虫没有并行地处理请求。 由于我们的代码不是CPU密集型, 所以我们可以安全地使用多线程模块。
关于Python中线程的基本使用以前写过一篇:python 多线程编程
以下代码是对每一页创建一个单独的线程,每个线程负责爬取网站内容、转换格式等。
2.1 代码和运行结果
from bs4 import BeautifulSoup
import requests
import json
import threading
SO_URL = "http://scifi.stackexchange.com"
QUESTION_LIST_URL = SO_URL + "/questions"
# http://scifi.stackexchange.com/questions
MAX_PAGE_COUNT = 1
class ThreadManager:
instance = None
final_results = []
threads_done = 0
# 并行线程的数量,
# 将决定每个线程获取的页面总数量
totalConnections = 1
@staticmethod
def notify_connection_end(partial_results):
print("==== Thread is done! =====")
ThreadManager.threads_done += 1
ThreadManager.final_results += partial_results
# 本例中会创建4个线程,当4个线程全部完成后才会执行if后面的内容
if ThreadManager.threads_done == ThreadManager.totalConnections:
print("==== Saving data to file! ====")
with open('scrapping-results-optimized.json', 'w') as outfile:
json.dump(ThreadManager.final_results, outfile, indent=4)
# 问题的作者
def get_author_name(body):
# link_name = body.select(".user-details a")
# if len(link_name) == 0:
# text_name = body.select(".user-details")
# return text_name[0].text if len(text_name) > 0 else 'N/A'
# else:
# return link_name[0].text
link_name = body['href']
link_name = link_name.split('/')[-1]
return link_name
# 问题的内容
def get_question_answers(body):
answers = body.select(".answer")
a_data = []
if len(answers) == 0:
return a_data
for a in answers:
data = {
'body': a.select(".post-text")[0].get_text(),
'author': get_author_name(a)
}
a_data.append(data)
return a_data
def get_question_data(url):
print("Getting data from question page: %s " % url)
resp = requests.get(url)
if resp.status_code != 200:
print("Error while trying to scrape url: %s" % url)
return
body_soup = BeautifulSoup(resp.text)
# 定义一个将被转换成JSON格式的输出词典
q_data = {
# 问题的标题
# 'title': body_soup.select('title')[0].text,
'title': body_soup.select('title')[0].text,
# 问题的正文 这个有bug的,就是如果问题正文有两段,那么只能取第一段
'body': body_soup.select('.s-prose p')[0].text,
# 作者
'author': get_author_name(body_soup.select(".user-gravatar32 a")[0]),
# 答案列表
# 'answers': get_question_answers(body_soup)
}
return q_data
def get_questions_page(page_num, end_page, partial_results):
print("=====================================================")
print(" Getting list of questions for page %s" % page_num)
print("=====================================================")
url = QUESTION_LIST_URL + "?sort=newest&page=" + str(page_num)
resp = requests.get(url)
if resp.status_code != 200:
print("Error while trying to scrape url: %s" % url)
else:
body = resp.text
main_soup = BeautifulSoup(body)
# 获取每个问题的网络链接
questions = main_soup.select('.s-post-summary--content .s-link')
urls = [SO_URL + x['href'] for x in questions]
for url in urls:
q_data = get_question_data(url)
partial_results.append(q_data)
if page_num + 1 < end_page:
get_questions_page(page_num + 1, end_page, partial_results)
else:
# 当该线程负责的页数调用完时,调用ThreadManager的静态方法
ThreadManager.notify_connection_end(partial_results)
pages_per_connection = MAX_PAGE_COUNT / ThreadManager.totalConnections
# 1 = 1 / 1
# 即创建1个线程,每个线程负责采集1页的内容, 第一个线程第1页,哪怕两页都被被那个网址反爬虫
for i in range(ThreadManager.totalConnections):
init_page = i * pages_per_connection
end_page = init_page + pages_per_connection
t = threading.Thread(target=get_questions_page, args=(int(init_page), int(end_page), [],), name='connection-%s' % (i))
t.start()
在本例中只爬了一页的内容,因为即使两页也会被网页反爬虫,运行结果与上一篇相同,由于只生成了单线程,运行时间也与上一段代码类似,如果爬的页数多,这个多线程的优势体现出来,但应该需要一定的爬虫知识来避免网址的反爬虫。
3. 第三部分——使用Cython优化数据分析
数据分析脚本与网络爬虫脚本不同。 它不是一个I/O密集型的脚本, 而是CPU密集型脚本。 它需要的I/O操作极少, 主要是读取文件, 输出结果。
3.1 Cython是什么
从技术角度看, Cython(http://cython.org/) 并没有使用另一种与CPython不同的解释器, 但是它可以让我们直接将Python代码编译成C语言(CPython不会这么做) 。
你会看到Cython其实是一个转换器, 可以简单看成一个软件, 它可以把源代码从一种语言翻译成另一种语言。 类似的软件还有CoffeeScript和Dart。 这两个是不同的软件, 使用不同的语言, 但是都翻译成JavaScript。
3.2 如何安装Cython
| 环境 | 版本 |
|---|---|
| 操作系统 | win11 |
| IDE | PyCharm 2022.2.3 (Professional Edition) |
| 解释器 | anaconda python3.8 |
步骤一:
我先安装了windows11安装C++编译器mingw-w64
步骤二:
在终端中输入python analyzer-setup.py build_ext --inplace,出现了以下错误。
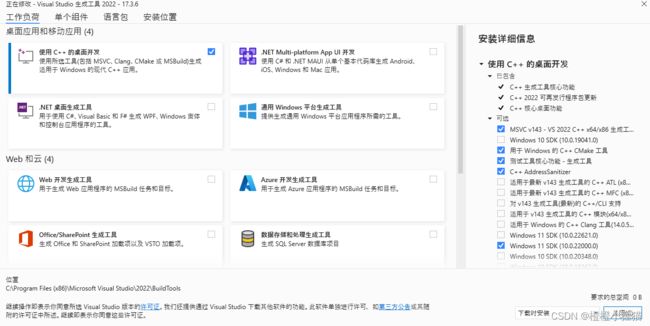
报错1:我按链接中的步骤完成下载:
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
按网站上的提示下载Visual Studio Installer,并安装了以下组件,并且将win10 SDK添加到了系统变量。
报错2:
完成以下步骤之后,出现了下面的错误提示。
(venv) PS D:\Python_workspace\test> python analyzer-setup.py build_ext --inplace
running build_ext
"C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\14.33.31629\bin\HostX86\x64\cl.exe" /c /nologo /O2 /W3 /GL /DNDEBUG /MD -ID
:\Python_workspace\test\venv\include -IC:\Users\Yaoyao\AppData\Local\Programs\Python\Python39\include -IC:\Users\Yaoyao\AppData\Local\Programs\Python\Pyt
hon39\Include "-IC:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\14.33.31629\include" "-IC:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Auxiliary\VS\include" /Tcanalyzer_cython.c /Fobuild\temp.win-amd64-3.9\Release\analyzer_cython.obj
analyzer_cython.c
C:\Users\Yaoyao\AppData\Local\Programs\Python\Python39\include\pyconfig.h(59): fatal error C1083: 无法打开包括文件: “io.h”: No such file or directory
error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio\\2022\\BuildTools\\VC\\Tools\\MSVC\\14.33.31629\\bin\\HostX86\\x64\\cl.exe' failed with exit code 2
我根据Cannot open include file: ‘io.h’: No such file or directory中的一个答案,以管理员身份运行Developer Command Prompt for VS 2022,切换到相应目录
报错3:
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyBaseObject_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_SetAttr
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyUnicode_InternFromString
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyCFunction_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyOS_snprintf
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyThreadState_Get
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_SetObject
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyCode_NewEmpty
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_GivenExceptionMatches
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___PyObject_CallFunction_SizeT
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyLong_AsUnsignedLong
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_WarnEx
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_RuntimeWarning
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyFunction_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyFrame_New
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_DeprecationWarning
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_KeyError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__Py_LeaveRecursiveCall
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyImport_ImportModule
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___PyLong_AsByteArray
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyImport_ImportModuleLevelObject
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_NormalizeException
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_SelfIter
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_Occurred
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyLong_FromSsize_t
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_GenericGetAttr
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyTraceBack_Here
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___PyThreadState_UncheckedGet
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_RuntimeError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyMethod_New
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_SetAttrString
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyLong_FromLong
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_GC_UnTrack
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_Hash
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_UnboundLocalError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_SetNone
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDict_GetItemWithError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyInterpreterState_GetID
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyLong_FromUnsignedLongLong
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__Py_GetVersion
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_GetAttr
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDict_Contains
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyLong_AsUnsignedLongLong
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyRun_StringFlags
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___Py_NoneStruct
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyLong_AsLongLong
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyTuple_New
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PySequence_Contains
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDict_SetItemString
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDict_Size
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyLong_FromLongLong
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyFloat_FromDouble
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDict_Items
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_AttributeError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyTuple_GetSlice
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_SetString
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_WriteUnraisable
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_GetIter
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyNumber_Add
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_WarnFormat
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyIter_Send
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_ValueError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyLong_FromUnsignedLong
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDict_Next
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_Format
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDict_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_RichCompare
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyTuple_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___Py_FalseStruct
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyCoro_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyNumber_InPlaceAdd
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyFloat_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___PyLong_FromByteArray
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyModule_NewObject
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyMethod_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyLong_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyType_IsSubtype
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyUnicode_Join
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_OverflowError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___Py_Dealloc
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyTuple_GetItem
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyImport_GetModuleDict
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyModule_GetDict
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_Free
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_ExceptionMatches
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_GC_Del
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_CallFunctionObjArgs
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyLong_AsLong
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDescr_IsData
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_ClearWeakRefs
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_Init
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_Not
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyUnicode_AsUTF8
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyUnicode_FromFormat
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyList_New
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PySlice_New
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyImport_AddModule
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyType_Ready
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_GetAttrString
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyErr_Clear
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyList_Append
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyUnicode_Decode
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyCode_New
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyException_SetTraceback
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDict_SetItem
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDict_New
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_CallFinalizerFromDealloc
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___PyDict_GetItem_KnownHash
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_StopIteration
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyCMethod_New
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___PyGen_SetStopIterationValue
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyList_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyDict_GetItemString
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_GetItem
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_CallObject
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyModuleDef_Init
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_GC_Track
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyBytes_FromStringAndSize
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyUnicode_Compare
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_StopAsyncIteration
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_IsSubclass
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_TypeError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyMem_Realloc
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_IsTrue
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_NameError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyTuple_Pack
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyMem_Malloc
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__Py_EnterRecursiveCall
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_ImportError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyGen_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___Py_TrueStruct
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyArg_UnpackTuple
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_SystemError
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___PyObject_GC_New
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyException_SetCause
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyAsyncGen_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyTraceBack_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyMethodDescr_Type
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyExc_GeneratorExit
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyUnicode_FromString
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___PyType_Lookup
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyObject_Call
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp__PyUnicode_FromStringAndSize
analyzer_cython.obj : error LNK2001: 无法解析的外部符号 __imp___PyObject_GetDictPtr
build\lib.win32-cpython-310\analyzer_cython.cp310-win_amd64.pyd : fatal error LNK1120: 144 个无法解析的外部命令
error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio\\2022\\BuildTools\\VC\\Tools\\MSVC\\14.33.31629\\bin\\HostX86\\x86\\link.exe' failed with exit code 1120
将python调整成了32位的python3.8
报错4:在python中无法导入生成的.pyd文件
摆烂了,知道的朋友提示一下
3.3 Cython怎么用
主要的软件和流程如图所示:
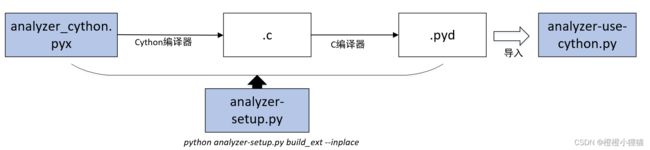
- 首先, 需要用Cython把.pyx文件编译(翻译) 成.c文件。 这些文件里的源代码, 基本都是纯Python代码加上一些Cython代码(写Cython代码也是小难点)。
- 然后, .c文件被C语言编译器编译成.so库, 这个库之后可以导入Python(.so是一个动态链接库,但与普通.so不同的是它可以导入python,这就与普通gcc编译出来的有点不一样)。
3. 编译代码有一些方法:
- 我们可以创建一个distutils配置文件。 bistutils是一个创建其他模块的工具, 我们可以用它生成自定义的C语言编译文件。
- 运行cython命令将.pyx文件编译成.c文件。
- 然后用C语言编译器把C代码手动编译成库文件。最后一种方法是用pyximport, 像导入.py文件一样导入.pyx直接使用。 - 为了有效地编译代码, 可以用下面的命令:
$ python analyzer-setup.py build_ext --inplace
3.3.1 代码和运行结果
全部代码中analyzer-use-cython.py代码还存在问题,因为我弄不明白在win11中pyd文件的导入。
analyzer_cython.pyx
import operator
import string
import nltk
from nltk.util import ngrams
import json
import re
SOURCE_FILE = './scrapping-results.json'
# 返回提问问题数量最多的作者排名
def get_most_active_users(data, int limit):
names = {}
for q in data:
if q['author'] not in names:
names[q['author']] = 1
else:
names[q['author']] += 1
return sorted(names.items(), reverse=True, key=operator.itemgetter(1))[:limit]
# 把问题的正文内容组合成一个列表
def flatten_questions_body(data):
body = []
for q in data:
body.append(q['body'])
return '. '.join(body)
# 返回使用最常用词组数量最多的问题排名
def get_most_common_phrases(d, int limit, int length):
body = flatten_questions_body(d)
phrases = {}
for sentence in nltk.sent_tokenize(body):
words = nltk.word_tokenize(sentence)
for phrase in ngrams(words, length):
if all(word not in string.punctuation for word in phrase):
key = ' '.join(phrase)
if key in phrases:
phrases[key] += 1
else:
phrases[key] = 1
return sorted(phrases.items(), reverse=True, key=operator.itemgetter(1))[:limit]
def get_node_content(node):
return ' '.join([x[0] for x in node])
# 把问题的标题内容组合成一个小写的列表
def flatten_questions_titles(data):
body = []
pattern = re.compile('(\[|\])')
for q in data:
lowered = q['title'].lower()
filtered = re.sub(pattern, ' ', lowered)
body.append(filtered)
return '. '.join(body)
# 返回问题标题中最常见的主题排名
def get_most_active_topics(data, int limit):
body = flatten_questions_titles(data)
sentences = nltk.sent_tokenize(body)
sentences = [nltk.word_tokenize(sent) for sent in sentences]
sentences = [nltk.pos_tag(sent) for sent in sentences]
grammar = "NP: {?}"
cp = nltk.RegexpParser(grammar)
results = {}
for sent in sentences:
parsed = cp.parse(sent)
trees = parsed.subtrees(filter=lambda x: x.label() == 'NP')
for t in trees:
key = get_node_content(t)
if key in results:
results[key] += 1
else:
results[key] = 1
return sorted(results.items(), reverse=True, key=operator.itemgetter(1))[:limit]
# 返回答题最多的用户排名
# 加载JSON文件并返回输出结果的词典
def load_json_data(file):
with open(file) as input_file:
return json.load(input_file)
def analyze_data(d):
return {
'most_active_users': get_most_active_users(d, 10),
'most_active_topics': get_most_active_topics(d, 10),
'most_common_phrases': get_most_common_phrases(d, 10, 4),
}
analyzer-setup.py
from distutils.core import setup
from Cython.Build import cythonize
setup(
name='Analyzer app',
ext_modules=cythonize("analyzer_cython.pyx"),
)
analyzer-use-cython.py
import xxx.pyd as analyzer
import visualizer
data_dict = analyzer.load_json_data(analyzer.SOURCE_FILE)
results = analyzer.analyze_data(data_dict)
print("=== ( Most Active Users ) === ")
visualizer.displayMostActiveUsers(results['most_active_users'])
print("=== ( Most Active Topics ) === ")
visualizer.displayMostActiveTopics(results['most_active_topics'])
print("=== ( Most Common Phrases ) === ")
visualizer.displayMostCommonPhrases(results['most_common_phrases'])
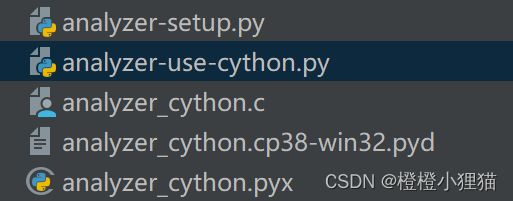
结果
以下是运行文件和生成的文件。
3.4 Cython参考链接
10分钟入门Cython
Cython 基本用法
Cython入门教程
Cython 3.0 中文文档