计算机网络协议(UDP,TCP,NAT,HTTP,HTTPS,ARP,RARP等)汇总
目录
OSI七层模型
TCP/IP五层(四层)模型
一.DNS协议(应用层协议)
1.1什么是DNS协议?
1.2域名服务器
1.3本地域名服务器
1.4递归查询与迭代查询
1.5域名解析的过程:
二.NAT与NAPT协议
2.1何为NAT技术?
三.UTP与TCP协议
3.1UTP协议
3.1.1UDP协议格式
3.1.2UDP的特点
3.1.3UDP的缓冲区
3.1.3UDP的注意事项
3.1.3基于UDP的应用层协议
3.2TCP协议
3.2.1TCP协议格式
3.2.2确认应答机制(ACK机制)
3.2.3超时重传机制
3.2.4连接管理机制
3.2.5滑动窗口
3.2.6流量控制
3.2.7拥塞控制
3.2.8延迟应答
3.2.9捎带应答
3.2.10面向字节流
四.HTTP与HTTPS(应用层协议)
4.1HTTP协议
4.1.1HTTP是什么?
4.1.2HTTP的特点
4.1.3HTTP请求:
4.1.4HTTP响应:
4.2HTTPS协议
4.2.1什么是HTTPS?
4.2.2HTTPS的特点?
4.2.3对称加密与非对称加密?
4.2.4
五.常见状态码
1XX (接收的请求正在处理)
2XX(请求正常处理完毕)
3XX(重定向状态码)
4XX(请求可能出错,妨碍了服务器的处理)
5XX(服务器错误)
OSI七层模型
| 序号 | 名称 | 该层协议 | 解释 |
| 7 | 应用层 | 针对特定应用的协议(电子邮件用电子邮件协议,文件传输用文件传输协议,远程登陆用远程登陆协议) |
|
| 6 | 表示层 | 声音,图像,文字)等信息转换为网络的标准数据格式 |
|
| 5 | 会话层 | 通信管理(何时建立与断开连接,以及保持多久的连接) |
|
| 4 | 传输层 | TCP,UDP | 可靠的数据传输(数据是否有丢失) |
| 3 | 网络层 | IP | 地址管理与路由选择(IP协议,经过哪个路由传递到目标地址) |
| 2 | 数据链路层 | 传输和识别数据帧,数据帧与比特流之间的转换 |
|
| 1 | 物理层 | 用网线连接,电子信号与比特流之间的转换 |
TCP/IP五层(四层)模型
| 序号 | 名称 | 该层协议 | 解释 |
| 5 | 应用层 | HTTP,HTTPS | 针对特定应用的协议(电子邮件用电子邮件协议,文件传输用文件传输协议,远程登陆用远程登陆协议) |
| 4 | 传输层 | TCP,UDP | 可靠的数据传输(数据是否有丢失) |
| 3 | 网络层 | IP,ARP | 地址管理与路由选择(IP协议,经过哪个路由传递到目标地址) |
| 2 | 数据链路层 | 传输和识别数据帧,数据帧与比特流之间的转换 |
|
| 1 | 物理层 | 用网线连接,电子信号与比特流之间的转换 |
一.DNS协议(应用层协议)
1.1什么是DNS协议?
因为计算机操作系统只能解析IP地址,而不能解析域名(域名是为了方便人们记忆),所以DNS协议油然而生。
- DNS协议是一种将址域名转换为IP地的协议(或将IP地址转换为域名)
- DNS底层采用UDP(用户到服务器的通信)和TCP(服务器间的通信)协议
1.2域名服务器

- 根域名服务器管理所有的顶级域名服务器
- 顶级域名服务器管理各自的二级域名服务器
- 二级域名服务器管理各自的三级域名服务
例:www.baidu.com
- com:顶级域名
- baidu:权威(二级)域名服,一般是公司名
- www:三级域名yuming
1.3本地域名服务器
默认的域名服务器,用户所访问的第一个服务器
1.4递归查询与迭代查询
递归查询:别人帮我做事(我只要结果)
- 本机向本地域名服务器发出一次查询请求,然后等待最终的结果。如果本地域名服务器无法解析,自己会以DNS客户机的身份向其它域名服务器查询,直到得到最终的IP地址告诉本机
迭代查询:我自己做事情(每一步都需要我自己来完成)
- 本地域名服务器向根域名服务器查询,根域名服务器告诉它下一步到哪里去查询,然后它再去查,每次它都是以客户机的身份去各个服务器查询
1.5域名解析的过程:
- 在浏览器中输入www.qq.com域名,操作系统先会查询浏览器的DNS缓存,查看是否有这个网址映射关系,如果有,直接返回对应IP地址,完成域名解析。
- 如果没有,操作系统然后检查本地的hosts文件是否有这个网址映射关系,如果有,直接返回对应IP地址,完成域名解析。
- 如果hosts里没有这个域名的映射,则向路由器发起查询请求,是否有这个网址映射关系,如果有,直接返回对应IP地址,完成域名解析。
- 如果路由器缓存没有相应的网址映射关系,向本地域名服务器发起查询请求,本地域名服务器收到查询时,如果要查询的域名包含在本地域名服务器资源中,则返回解析结果给客户机,完成域名解析。
- 如果本地DNS服务器没有查询到,则本地DNS就把请求发至上一级域名服务,解析成功就返回给本地域名服务器解析结果,如果上一级域名服务器无法解析,本地域名服务其就向上上级服务器发起查询请求,直至13台根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(qq.com)给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找qq.com域服务器,重复上面的动作,进行查询,直至找到www.qq.com主机。
从客户端到本地DNS服务器是属于递归查询,而DNS服务器之间就是的交互查询就是迭代查询。
二.NAT与NAPT协议
2.1何为NAT技术?
NAT,全称为网络地址转换(Network Address Translation),是为了解决 IPv4 地址短缺而产生的技术。
三.UTP与TCP协议
3.1UTP协议
3.1.1UDP协议格式

- UDP首部有8个字节,由4个字段构成,每个字段都是2个字节
- 16位UDP长度:表示整个数据报(UDP首部+UDP数据)的最大长度(最大64K)
- 16位UDP检验和:如果校验和(双方约定好的字符串)出错, 就会直接丢弃;
3.1.2UDP的特点
- 无连接:知道对端的IP和端口号就可以直接进行通讯,不需要建立连接。
- 不可靠:没有类似TCP的安全机制(确认应答机制,超时重传机制,连接管理机制)。
- 面向数据报:不能够灵活的控制读写数据的次数,只能一次接受整个数据报文(系统级别操作,调用操作系统函数)
面向数据报:
- 应用层交给UDP多长的报文, UDP原样发送, 既不会拆分, 也不会合并;
- 用UDP传输100个字节的数据:如果发送端调用一次sendto, 发送100个字节, 那么接收端也必须调用对应的一次recvfrom, 接收100个字节; 而不能循环调用10次recvfrom, 每次接收10个字节;
3.1.3UDP的缓冲区
- UDP没有真正意义上的发送缓冲区
- UDP有接收缓存区,如果缓冲区已满,之后到达的数据就会被丢弃。
3.1.3UDP的注意事项
- UDP协议首部中有一个16位的最大长度. 也就是说一个UDP能传输的数据最大长度是64K(包含UDP首部)。如果我们需要传输的数据超过64K, 就需要在应用层手动的分包, 多次发送, 并在接收端手动拼装。
3.1.3基于UDP的应用层协议
- NFS: 网络文件系统
- TFTP: 简单文件传输协议
- DHCP: 动态主机配置协议
- BOOTP: 启动协议(用于无盘设备启动)
- DNS: 域名解析协议
3.2TCP协议
3.2.1TCP协议格式
3.2.2确认应答机制(ACK机制)
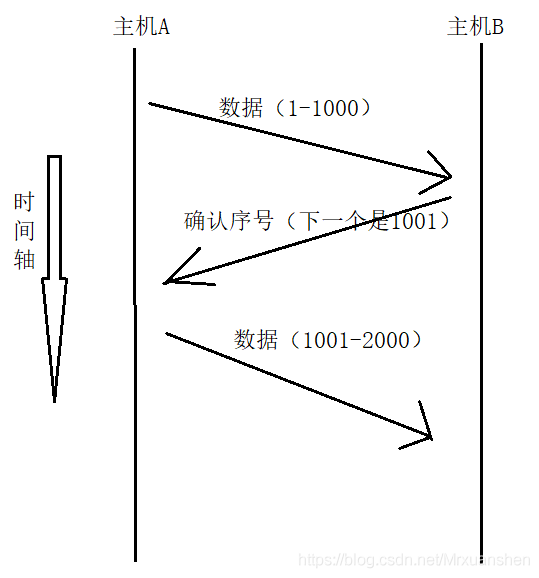
发送数据时:携带数据序号
接受数据时:携带确认序号
- TCP将每个字节的数据都进行了编号(序列号),每一个ACK都带有确认序号,意思是告诉发送者,我已经收到了哪些数据,下一次你应该从哪里开始发。
3.2.3超时重传机制
两种情况:
- 数据丢失
- 确认应答丢失(进行了超市重传,所以主机B可能收到重复的数据,可以利用序列号进行去重)
超时时间如何确定?
- TCP为了保证无论在任何环境下都有较高性能的通信, 因此会动态计算这个最大超时时间.(超时以500ms为一个单位进行控制)
- 如果重发一次之后, 仍然得不到应答, 等待 2*500ms 后再进行重传.
- 如果仍然得不到应答, 等待 4*500ms 进行重传. 依次类推, 以指数形式递增.
- 累计到一定的重传次数, TCP认为网络或者对端主机出现异常, 强制关闭连接.
3.2.4连接管理机制
正常情况下, tcp需要经过三次握手建立连接, 四次挥手断开连接.
三次握手:
刚开始, 客户端和服务器都处于 close状态.TCP服务器启动, 时刻准备接受客户端进程的连接请求, 此时服务器就进入了 listen(监听)状态
客户端向服务器主动发出连接请求, 服务器被动接受连接请求.
- TCP客户端进程向服务器发出连接请求报文,此时报文首部中的同步标志位SYN=1, 同时选择一个初始序列号 seq = x, 此时,TCP客户端进程进入了 SYN-sent(同步已发送状态)状态。TCP规定, SYN报文段(SYN=1的报文段)不能携带数据,但需要消耗掉一个序号。
- TCP服务器收到请求报文后, 如果同意连接, 则发出确认报文。确认报文中的 ACK=1, SYN=1, 确认序号是 x+1, 同时也要为自己初始化一个序列号 seq = y, 此时, TCP服务器进程进入了SYN-rcvd(同步收到)状态。这个报文也不能携带数据, 但是同样要消耗一个序号。
- TCP客户端进程收到确认后还,要向服务器给出确认。确认报文的ACK=1,确认序号是 y+1,自己的序列号是 x+1.
- 此时TCP连接建立,客户端进入established(已建立连接)状态。当服务器收到客户端的确认后也进入established状态,此后双方就可以开始通信了。
四次挥手:
数据传输完毕后,双方都可以释放连接.此时客户端和服务器都是处于established状态,然后客户端主动断开连接,服务器被动断开连接.
- 客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时客户端进入FIN-wait1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
- 服务器收到连接释放报文,发出确认报文,ACK=1,确认序号为 u+1,并且带上自己的序列号seq=v,此时服务端就进入了CLOSE-wait(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-wait状态持续的时间。
- 客户端收到服务器的确认请求后,此时客户端就进入FIN-wait2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最终数据)
- 服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
- 客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,确认序号为w+1,而自己的序列号是u+1,此时,客户端就进入了TIME-wait(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
- 服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
3.2.5滑动窗口
我们一次发送多条数据, 就可以大大的提高性能,滑动窗口机制就是如此;
- 窗口大小指的是无需等待确认应答而可以继续发送数据的最大值. 例如窗口大小是4000个字节(四个段).
- 发送前四个段的时候, 不需要等待任何ACK, 直接发送;
- 收到第一个ACK后, 滑动窗口向后移动, 继续发送第五个段的数据; 依次类推;
- 操作系统内核为了维护这个滑动窗口, 需要开辟发送缓冲区来记录当前还有哪些数据没有应答; 只有确认应答过的数据, 才能从缓冲区删掉;
- 窗口越大, 则网络的吞吐率就越高;
丢包情况:
1.数据包已经抵达, ACK被丢了.
- 这种情况下, 部分ACK丢了并不要紧, 因为可以通过后续的ACK进行确认;
2.数据包丢了
- 当某一段报文段(1-1000)丢失之后, 发送端会一直收到像1001 这样的ACK, 就像是在提醒发送端 "我想要的是 1001"一样;
- 如果发送端主机连续三次收到了同样一个 "1001" 这样的应答, 就会将对应的数据 1001 - 2000 重新发送;
- 这个时候接收端收到了 1001 之后, 再次返回的ACK就是 ,例如:7001了(因为2001 - 7000)接收端其实之前就已经收到了, 被放到了接收端操作系统内核的接收缓冲区中;
- 这种机制被称为 "高速重发控制"(也叫 "快重传")
3.2.6流量控制
接收端处理数据的速度是有限的. 如果发送端发的太快, 导致接收端的缓冲区满了, 这时如果发送端继续发送, 就会造成丢包。因此TCP支持根据接收端的处理能力, 来决定发送端的发送速度. 这个机制就叫做流量控制(Flow Control);
- 接收端将自己可以接收的缓冲区大小放入 TCP 首部中的 "窗口大小" 字段, 通过ACK端通知发送端;
- 窗口大小字段越大, 说明网络的吞吐量越高;
- 接收端一旦发现自己的缓冲区快满了, 就会将窗口大小设置成一个更小的值通知给发送端;
- 发送端接受到这个窗口之后, 就会减慢自己的发送速度;
- 如果接收端缓冲区满了, 就会将窗口置为0; 这时发送方不再发送数据, 但是需要定期发送一个窗口探测数据段, 使接收端把窗口大小告诉发送端.
3.2.7拥塞控制
- 此处引入一个概念程为拥塞窗口
- (慢启动)发送开始的时候, 定义拥塞窗口大小为1;每次收到一个ACK应答, 拥塞窗口加1;(指数级增加)
- 每次发送数据包的时候, 将拥塞窗口和接收端主机反馈的窗口大小做比较, 取较小的值作为实际发送的窗口;
- 为了不增长的那么快, 因此不能使拥塞窗口单纯的加倍,此处引入一个叫做慢启动的阈值
- 当拥塞窗口超过这个阈值的时候, 不再按照指数方式增长, 而是按照线性方式增长
- 当TCP开始启动的时候, 慢启动阈值等于窗口最大值; 在每次超时重发的时候, 慢启动阈值会变成上次网络拥塞的一半, 同时拥塞窗口置回1;
- 少量的丢包, 我们仅仅是触发超时重传;
3.2.8延迟应答
如果接收数据的主机立刻返回ACK应答, 这时候返回的窗口可能比较小.
- 假设接收端缓冲区为1M. 一次收到了500K的数据; 如果立刻应答, 返回的窗口就是500K;
- 但实际上可能处理端处理的速度很快, 10ms之内就把500K数据从缓冲区消费掉了;
- 在这种情况下, 接收端处理还远没有达到自己的极限, 即使窗口再放大一些, 也能处理过来;
- 如果接收端稍微等一会再应答, 比如等待200ms再应答, 那么这个时候返回的窗口大小就是1M;
所有的包都可以延迟应答么? 肯定也不是;
- 数量限制: 每隔几(如:2)个包就应答一次;
- 时间限制: 超过最大延迟时间(200ms)就应答一次;
3.2.9捎带应答
ACK就可以搭顺风车, 和服务器回应的 "数据" 一起回给客户端
3.2.10面向字节流
四.HTTP与HTTPS(应用层协议)
4.1HTTP协议
发展历史:
| 版本 | 产生时间 | 内容 | 发展现状 |
| HTTP/0.9 | 1991年 | 不涉及数据包传输,规定客户端和服务器之间通信格式,只能GET请求 | 没有作为正式的标准 |
| HTTP/1.0 | 1996年 | 传输内容格式不限制,增加PUT、PATCH、HEAD、 OPTIONS、DELETE命令 | 正式作为标准 |
| HTTP/1.1 | 1997年 | 持久连接(长连接)、节约带宽、HOST域、管道机制、分块传输编码 | 2015年前使用最广泛 |
| HTTP/2 | 2015年 | 多路复用、服务器推送、头信息压缩、二进制协议等 | 逐渐覆盖市场 |
4.1.1HTTP是什么?
HTTP是超文本传输协议,基于请求与响应的应用层协议
4.1.2HTTP的特点
- 支持客户/服务器模式
- 无状态:协议对客户端没有状态存储,比如访问一个网站需要反复进行登录操作
- 无连接:HTTP/1.1之前,限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- 基于请求和响应:由客户端发起请求,服务端数据响应
- 简单快速、灵活
- 通信使用明文,请求和响应不会对通信方进行确认、无法保护数据的完整性与安全性
4.1.3HTTP请求:
GET http://www.baidu.com?username=lx&password=qwe HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, -silverlight, application/x-shockwave-flash, */*
Referer: http://www.google.cn/
Accept-Language: zh-cn
Content-Length: 28
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; TheWorld)
Host: www.google.cn
Connection: Keep-Alive
Cookie: PREF=ID=80a06da87be9ae3c:U=f7167333e2c3b714:NW=1:TM=1261551909:LM=1261551917:S=ybYcq2wpfefs4V9g;
username=lx&password=qwe - 首行: [方法] + [url] + [版本]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个ContentLength属性来标识Body的长度;
4.1.4HTTP响应:
HTTP/1.1 200 OK
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint,
application/msword, application/x-silverlight, application/x-shockwave-flash, */*
Referer: http://www.google.cn/
Accept-Language: zh-cn
Content-Length: 36
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; TheWorld)
Host: www.google.cn
Connection: Keep-Alive
Cookie: PREF=ID=80a06da87be9ae3c:U=f7167333e2c3b714:NW=1:TM=1261551909:LM=1261551917:S=ybYcq2wpfefs4V9g;
NID=31=ojj8d-IygaEtSxLgaJmqSjVhCspkviJrB6omjamNrSm8lZhKy_yMfO2M4QMRKcH1g0iQv9u-2hfBW7bUFwVh7pGaRUb0RnHcJU37y-
FxlRugatx63JLv7CWMD6UB_O_r
hl=zh-CN&source=hp&q=domety - 首行: [版本号] + [状态码] + [状态码解释]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个ContentLength属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中.
4.2HTTPS协议
4.2.1什么是HTTPS?
- http传送数据(包括账号和密码),都是明文传送,很容易被窃取或者侦听,所以有了https,https多了一层加密解密层,在发送前加密,在收到后解密。
- HTTPS是身披SSL外壳的HTTP。HTTPS是一种通过计算机网络进行安全通信的传输协议,经由HTTP进行通信,利用SSL/TLS建立全信道,加密数据包。HTTPS使用的主要目的是提供对网站服务器的身份认证,同时保护交换数据的隐私与完整性。
- TLS是传输层加密协议,前身是SSL协议,有时候两者不区分
4.2.2HTTPS的特点?
- 内容加密:采用混合加密技术,中间者无法直接查看明文内容
- 验证身份:通过证书认证客户端访问的是自己的服务器
- 保护数据完整性:防止传输的内容被中间人冒充或者篡改
4.2.3对称加密与非对称加密?
对称加密:
- A和B对自己的数据进行加密。A和B会使用一个共享的密钥,A在发送数据之前,用这个密钥对数据加密。B在收到数据之后,用这个密钥对数据解密。因为加密解密用的是同一个密钥,所以这里的加密算法称为对称加密算法。
非对称加密:(存在中间人攻击)
-
非对称加密使用两个密钥,一个是public key,一个是private key。通过一个特殊的数学算法,使得数据的加密和解密使用不同的密钥。因为用的是不同的密钥,所以称为非对称加密。
-
非对称加密的好处在于,现在A可以保留private key,通过网络传递public key。这样,就算public key被C拦截了,因为没有private key,C还是没有办法完成信息的破解。既然不怕C知道public key,那现在A和B不用再见面商量密钥,直接通过网络传递public key就行。具体在使用中,A和B都各有一个public key和一个private key,这些key根据相应的算法已经生成好了。private key只保留在各自的本地,public key传给对方。
-
A要给B发送网络数据,那么A先使用自己的private key(只有A知道)加密数据的hash值,之后再用B的public key加密数据。之后,A将加密的hash值和加密的数据再加一些其他的信息,发送给B。B收到了之后,先用自己的private key(只有B知道)解密数据,本地运算一个hash值,之后用A的public key解密hash值,对比两个hash值,以检验数据的完整性。
CA证书:
-
现实中,通过CA证书来保证public key的真实性。CA也是基于非对称加密算法来工作。有了CA,B会先把自己的public key(和一些其他信息)交给CA。CA用自己的private key加密这些数据,加密完的数据称为B的数字证书。现在B要向A传递public key,B传递的是CA加密之后的数字证书。A收到以后,会通过CA发布的CA证书(包含了CA的public key),来解密B的数字证书,从而获得B的public key。
-
但是A怎么确保CA证书不被劫持。C完全可以把一个假的CA证书发给A,进而欺骗A。CA的大杀器就是,CA把自己的CA证书集成在了浏览器和操作系统里面。A拿到浏览器或者操作系统的时候,已经有了CA证书,没有必要通过网络获取,那自然也不存在劫持的问题。
SSL/TLS的工作过程:
- 通过CA体系交换public key
- 通过非对称加密算法,交换用于对称加密的密钥
- 通过对称加密算法,加密正常的网络通信
- 用户向web服务器发起一个安全连接的请求
- 服务器返回经过CA认证的数字证书,证书里面包含了服务器的public key
- 用户拿到数字证书,用自己浏览器内置的CA证书解密得到服务器的public key
- 用户用服务器的public key加密一个用于接下来的对称加密算法的密钥,传给web服务器
- 因为只有服务器有private key可以解密,所以不用担心中间人拦截这个加密的密钥
- 服务器拿到这个加密的密钥,解密获取密钥,再使用对称加密算法,和用户完成接下来的网络通信
4.2.4
五.常见状态码
1XX (接收的请求正在处理)
2XX(请求正常处理完毕)
| 200 |
请求成功 |
3XX(重定向状态码)
| 301 |
(永久移动) 请求的网页已永久移动到新位置。浏览器会自动访问新的url,今后用新的url进行登录 |
| 302 |
(临时移动) 服务器从别的网页资源响应请求,但请求者应继续使用原有url |
| 307 |
(临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 |
4XX(请求可能出错,妨碍了服务器的处理)
| 400 |
客户端请求语法错误,服务器无法理解(数据类型,数据格式,协议格式错误) |
| 401 |
请求要求身份验证(未登录访问敏感资源) |
| 403 |
服务器拒绝请求 |
| 404 |
服务器找不到请求的网页 |
| 405 |
客户端请求中的方法被禁止(服务端提供的请求方法不包含客户端的请求方法) |
5XX(服务器错误)
| 500 |
(服务器内部错误) 服务器遇到错误,无法完成请求。 |
| 502 |
(错误网关)服务器作为网关或代理,从上游服务器收到无效响应。 |
| 503 |
(服务不可用)服务器目前无法使用(停机维护) |