Python爬虫入门 ~ selenium访问元素信息与交互基本使用
访问元素信息
前面我们成功定位到了页面的标签元素,那接下来就该轮到获取元素的信息了,常用的函数有以下几种:
- get_attribute
- text
- tag_name
前置准备
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True)
options.add_experimental_option('excludeSwitches', ['enable-automation'])
path = 'chromedriver.exe'
browser = webdriver.Chrome(service=Service(path), options=options)
url = 'https://www.baidu.com/'
browser.get(url)
复制代码get_attribute
获取元素属性,通过get_attribute函数,指定我们所需要的标签属性,即可得到对应的属性值。
obj = browser.find_element(By.ID, "su")
print(obj.get_attribute("class"))
复制代码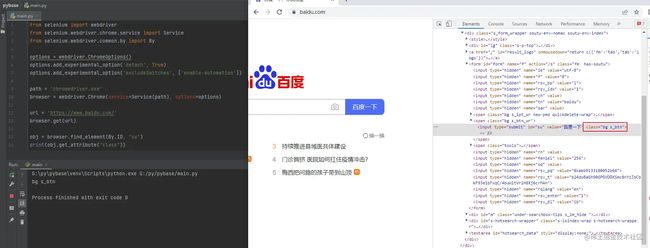
text
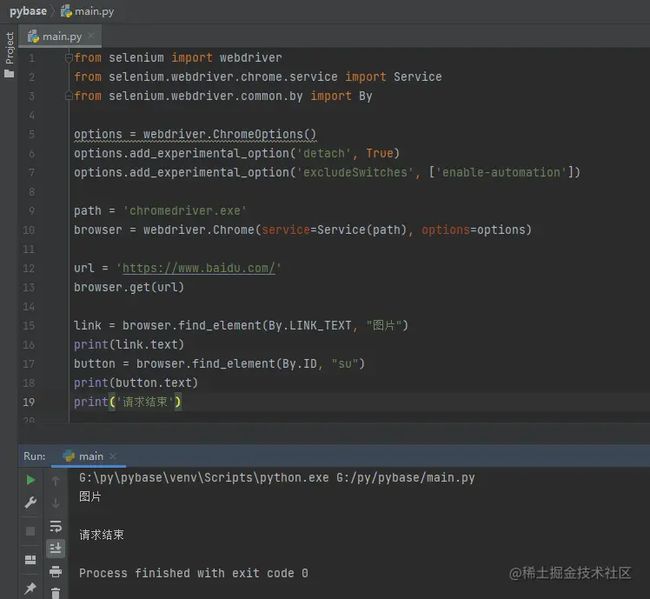
获取元素文本,使用text函数,可以获取到标签体中的文本内容,这里需要注意的是,一定得是标签体中有文字的才能正常获取到数据,想"百度一下"按钮是没有文本的,则无法获取到数据。
link = browser.find_element(By.LINK_TEXT, "图片")
print(link.text)
复制代码
tag_name
获取标签名
link = browser.find_element(By.LINK_TEXT, "图片")
print(link.tag_name)
复制代码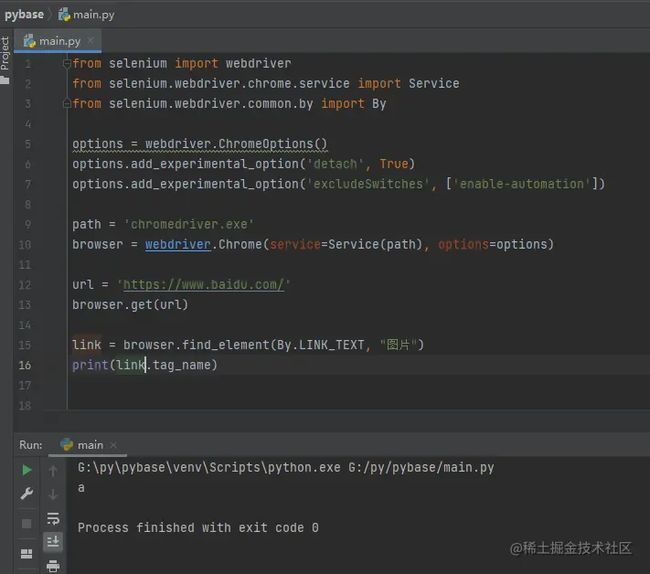
交互
元素的定位与信息获取都有了,那就该轮到交互了,常用的交互动作有:
- 点击:click()
- 输入:send_keys()
- 后退:browser.back()
- 前进:borwser.forword()
- 滚动:browser.execute_script(js代码)
- 获取网页代码:page_source
- 退出:browser.quit()
整合案例
需求:打开百度网站搜索“掘金”,然后下滑到页面底部,点击下一页,并返回上一页,再重新前进页面。
前置准备
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True)
options.add_experimental_option('excludeSwitches', ['enable-automation'])
path = 'chromedriver.exe'
browser = webdriver.Chrome(service=Service(path), options=options)
url = 'https://www.baidu.com/'
browser.get(url)
# 睡眠2秒,等待页面渲染完成
time.sleep(2)
复制代码输入搜索条件
打开页面之后,我们就可以向搜索框输入所需要查询的条件了,具体步骤如下:
- 使用
find_element定位到搜索框 - 使用
send_keys输入搜索条件
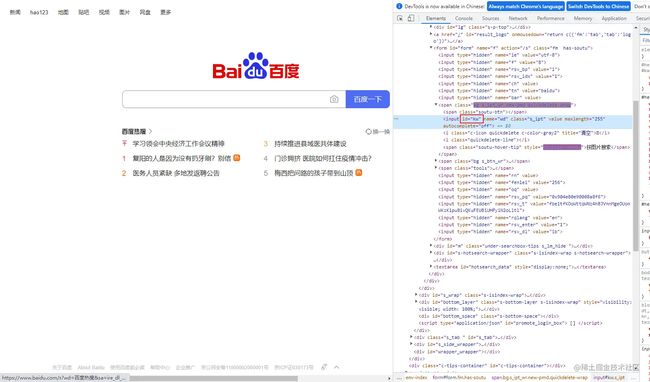
input = browser.find_element(By.ID, 'kw')
input.send_keys('掘金')
复制代码点击按钮
当搜索条件输入完成,我们就可以点击查询了,步骤:
- 使用
find_element定位到搜索按钮 - 使用
click触发点击事件

button = browser.find_element(By.ID, 'su')
button.click()
复制代码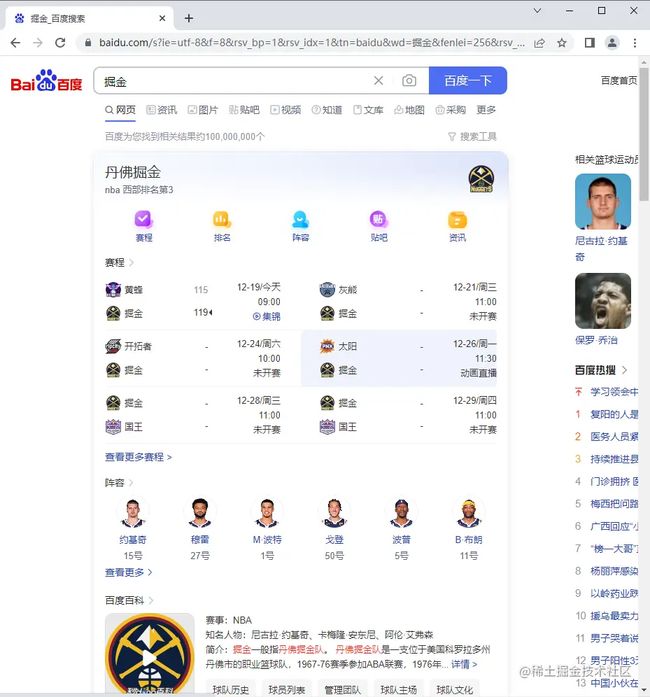
模拟鼠标滚动下滑
搜索完成了,接下来是将页面滚动到最下方,这里使用的是js命令,设置scrollTop=100000一般就可以滚动到最下方的了。
js_fun = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_fun)
复制代码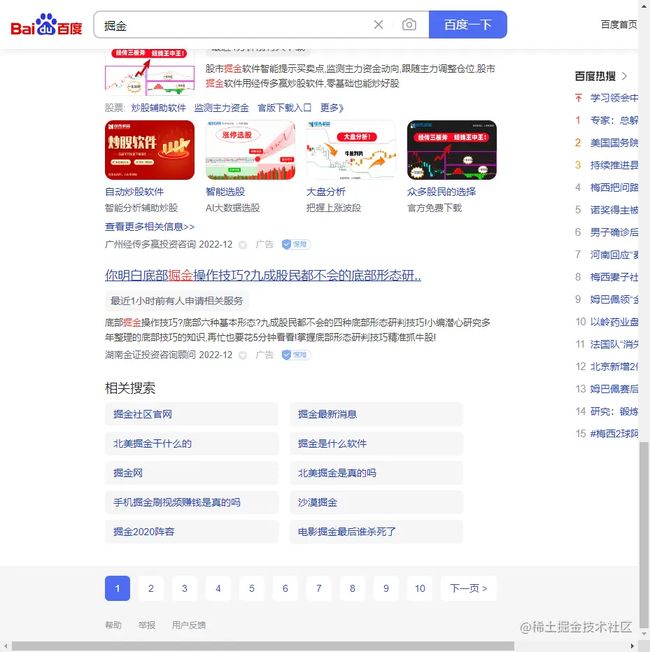
跳转下一页
next = browser.find_element(By.XPATH, '//a[@class="n"]')
next.click()
复制代码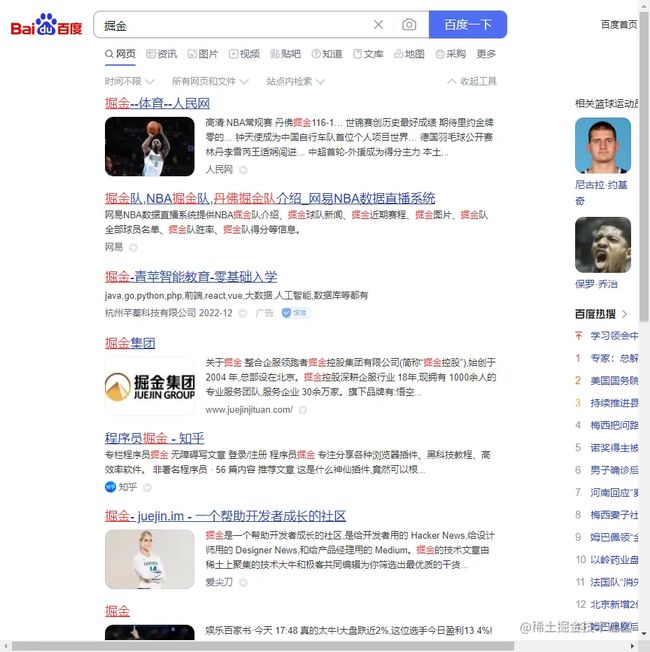
浏览器后退
browser.back()
复制代码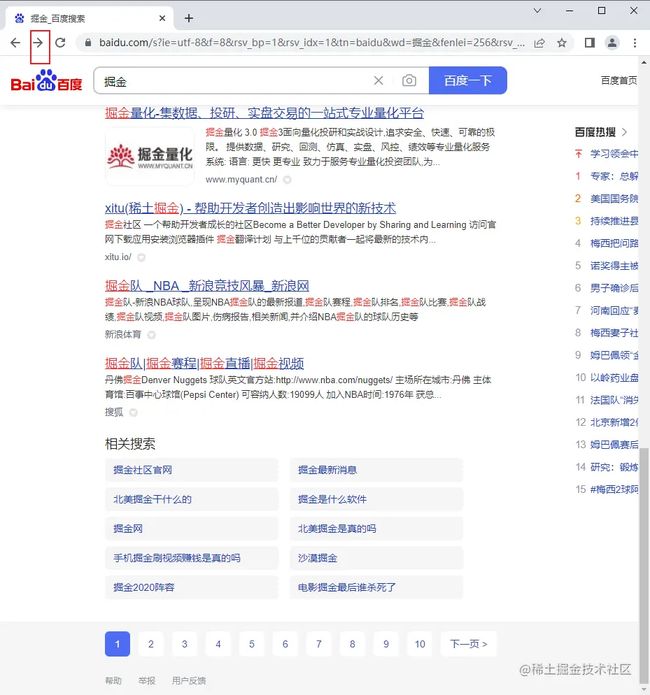
浏览器前进
browser.forward()
复制代码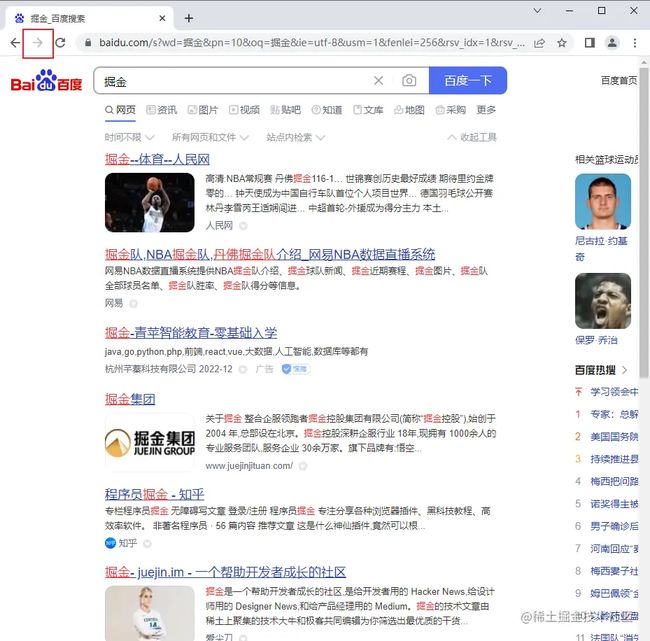
退出
browser.quit()
复制代码到这里,基本就将selenium常用的交互步骤都用上了,还是挺简单的,以后爬取别的数据也是针对性的调整一下元素的定位即可。