深度!用“极速统一”,开启金融行业数据分析新范式
作者:51CTO 赵立京
数据库作为金融信息系统的核心基础设施,历经数十年发展,为金融行业转型升级提供了有力的技术支撑。同时, 以银行为代表的金融行业是数据库销售额占比最高的市场,也是对数据库技术依赖度最高、要求最严格的市场。
据统计,2021 中国数据库市场行业分布中,金融占 20.2%,政府占 18.4%,互联网 14.8%,运营商 8.9%。IDC 预测, 2024 年全球数仓的市场规模将达到 297 亿美元,2019-2024 年的年复合增长率将达到 12%,其中云上的数仓市场规模将达到 181 亿美元,2019-2024 年的 CAGR 将达到 25.3%。预计 2024 年,中国数仓市场的规模是 168.5 亿元,中国大数据平台软件市场规模总体为 352.9 亿元,中国分析型数据库的整体市场将达到 521.4 亿元,复合增长率为 27.7%。
以往商业集中式数据库凭借较强的功能黏性、优秀的系统稳定性、良好的软硬适配能力,一直在金融行业占据较大份额。而互联网金融的异军突起,带来了高并发、海量数据、超高峰值等挑战。为应对这些实际场景,近年来各金融机构纷纷展开关于数据库的探索,并结合金融交易场景不断推陈出新,拉动数据库技术的迭代发展。
传统IT系统无法满足金融交易要求
信通院在去年发布的《金融级分布式数据库白皮书》中指出,金融行业普遍对数据库的安全性、可靠性、稳定性有着全行业最为严苛的要求,因此,满足金融行业需求的金融级数据库产品几乎成为所有行业中的标杆。报告认为, 金融级分布式数据库是能够满足金融级要求的高可用、高性能、低成本、线性水平扩展、企业级安全、便捷性运维的分布式数据库。
在众多金融级分布式数据库中,按照数据处理方式,大致可以分成两大类:联机事务处理 OLTP(On-line Transaction Processing)、联机分析处理 OLAP(On-line Analytical Processing)。OLTP 是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
可见,OLAP 数据库拥有高性能、可扩展、高可用和高容错等特性,因此在金融行业的应用规模有了明显的提升,并且正在从金融外围系统向核心业务延伸,有力支撑着金融行业的数字化转型。在过去几年中,我国数据库市场 “百花齐放”,包括传统数据库厂商,如达梦、人大金仓、神州通用;云厂商,如阿里云、腾讯云、华为云;新兴数据库厂商,如 StarRocks、PingCAP、星环科技、OceanBase;ICT 跨界厂商,如新华三、浪潮。这些厂商的数据库产品和方案,正在各大商业银行、金融机构及城商行的核心业务系统中投入使用并稳定运行,满足了金融行业核心业务系统对数据库的要求。
接下来我们来看两个实际案例,希望能为更多金融行业用户的转型带来借鉴和参考价值。
中原银行和众安保险迈入极速统一时代
中原银行是河南省唯一一家分支机构网点覆盖全省的省属法人银行,在全国城商行中的排名位列第 8 位,是河南首家资产超万亿的城商行。随着业务不断扩张、数据量的高速增长以及业务逻辑复杂程度的不断提升,中原银行需要快速响应客户需求,为其提供更加精准的服务,同时借助实时数据进行客户洞察,帮助银行业务人员做出业务决策,提高管理水平。
为此,中原银行搭建了一站式商业智能 BI 平台,该平台分为客户行为分析系统知秋、一站式报表平台鲁班、一站式大屏平台鸿图和自助分析平台云间四大应用系统,总用户超过一万人。为支持 BI 平台的快速高效工作,中原银行搭建了完整的数据平台。其中,该平台的存储计算层分为数据湖、离线数仓与实时数仓三部分,由实时数仓对实时数据进行处理,辅助进行实时决策。随着用户的增加,基于原有的数据平台架构,仅能支持 T+1 小时级别的准实时报表,难以满足银行在客户分析、风控管理等场景下的实时查询与分析需求。此外,原有数据平台流批链路复杂,运维成本高,且实时数据与离线数据的存储并不统一,存在冗余,造成存算资源的浪费。
为了提高数据平台的查询效率,深入挖掘实时数据的价值,提升实时响应能力,中原银行调研了市面上两款主流 OLAP 数据库产品,发现 ClickHouse 在单表查询和大宽表查询表现优秀,查询延迟也比较低,但是 Join 性能较差,且不易维护;StarRocks 在固化查询和灵活分析性能表现不错,多表查询性能也比较优秀,而且同时支持实时与离线导入分析场景。与此同时,StarRocks 具有流批一体、向量化执行、运维简单、查询效率高、兼容性好且能够满足高并发查询要求等六大优势,恰好满足了中原银行构建极速统一的数据分析架构的业务需求。
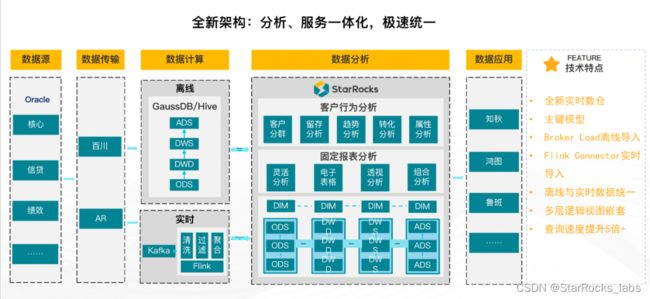
(中原银行基于 StarRocks 的实时数仓建设)
目前,中原银行使用 StarRocks 完成了固定报表迁移、知秋系统改造与实时数仓建设,极大提高了银行的数据导入、查询与分析效率。迁移完成后,固定报表查询效率提升为原来的 2.7 倍,所需时间下降到 3 秒以内;原耗时排行 top10 的报表,查询效率优化了 10 倍以上,同时还实现了自助客户行为分析。更值得一提的是,实时数仓架构将中原银行的离线数据和实时数据进行了统一,极大减少了数据的冗余,同时支持秒级导入与查询,提高了业务的时效性和多样性。
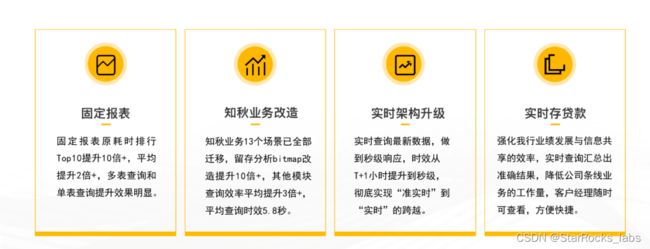
(中原银行基于 StarRocks 的业务价值提升)
众安保险是中国首家互联网保险公司,不设任何分支机构,完全通过互联网展业。截至 2021 年底,众安保险服务超过 5 亿用户,累计出具约 427 亿张保单。
众安专注于应用新技术重塑保险价值链。在“保险+科技”双轮驱动下,众安将自身沉淀的保险科技能力和先进的商业模式向行业输出,将数据作为支撑整体数字化路径的基石,从看见到预见、从名单到客户、从运营到创新,每一个环节和每一次升级都离不开数据赋能。
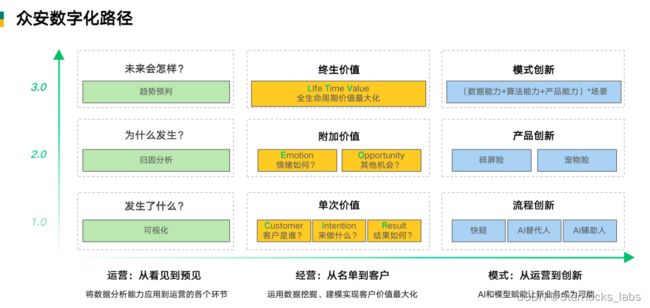
(众安保险的数字化路径)
在数字化转型的进程中,多场景融合的精细化分析是数字化转型破局的关键,但众安遇到了一些困难,包括单一场景分析遭遇瓶颈、多场景数据分散严重和数据能力缺乏向业务层拓展。针对这些问题,众安建立了“集智平台”。目前在众安保险内部各业务线和部门,超过 3000人 都在使用集智平台,平均日活可达 2000+。
集智上线后采⽤的是 ClickHouse,但随着使⽤平台的⽤户⽇渐增多,业务⽅需要查询的数据量也越来越⼤,业务场景变得复杂后,很多特定场景 ClickHouse 的表现都不够理想:在多并发场景的查询性能下降严重、多表关联查询性能⽋佳、排查运维成本较⾼、需要借助第三方工具等。针对实时场景,集智平台在使⽤ ClickHouse 的 Replacing 引擎中也遇到了查询慢、不⽀持数据的删除、只能对同一分⽚上同一分区的数据去重等痛点。
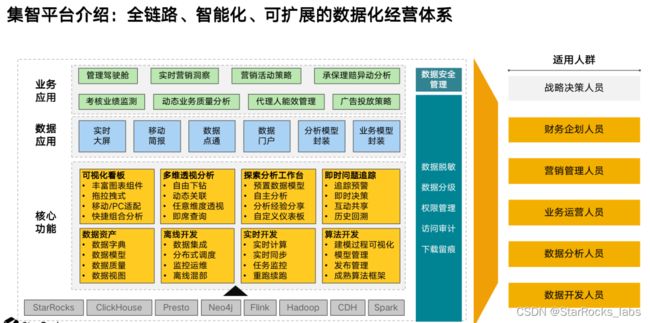
(众安保险集智平台介绍)
基于以上情况,集智平台需要进行新的 OLAP 技术选型。经过选型评测发现,StarRocks 支持高并发,部分场景可支持高达1万以上的 QPS,TP99 可以控制在1秒以内。StarRocks 通过 CBO 优化,可以自动选择性能最优的查询计划,多表关联性能的表现也更好。
因此,众安保险在集智平台引入了 StarRocks,支撑理赔风险洞察、精细化运营分析、营销实时效果追踪等方面的应用,赋能战略决策人员、财务企划人员、营销管理人员、数据运营人员、数据分析人员。为了提升集智在查询加载方面的性能,同时将 StarRocks 极速查询及高并发相关能力更好地赋能给业务,集智在产品侧深度集成了 StarRocks,用户可以在平台上快速完成一站式的统一实时看板搭建。

通过引入 StarRocks,众安保险集智平台解决了极速查询和高并发等数据问题,提升了集智平台整体的数据支持能力和市场竞争力。以保险产品中线上渠道投放场景为例,当保险产品开始对外发售前后,市场人员会将产品投放到多个渠道进行推广曝光,通过经营的核心报表实时核算每个渠道的投放成本以及其对应的 ROI,根据数据表现情况实时调整投放策略,控制渠道营销流程中的获客单价和投放费用。因此数据反馈的快慢也会决定业务人员在定位问题、调整策略等事件上是否占据最佳时机。
通过中原银行、众安保险这两个案例可以看到,作为新一代极速全场景 MPP 数据库, StarRocks 具有可伸缩性、高可用、高性能、优秀的性价比等优势,在提升企业的业务价值方面深具潜力。
极速统一3.0 助力数据要素价值充分释放
大数据技术应用于企业级数据基础设施已不鲜见,而金融行业在实践层面一直走在行业前列,它们在数据湖、融合数仓等典型的技术场景不断探索,逐步将先进的大数据生态技术应用到风险控制、运营管理、信贷查询、信用卡征信和财务分析等业务场景。
比如中国银行就于 2021 年投产上线数据湖平台,希望为中国银行统一数据分析层、展现层、数据沙箱等探索提供平台支撑,沉淀和深度挖掘全行数据资产。中国建设银行则早早把数据仓库和数据湖作为数据底座,不同于不少企业基于 Hadoop 体系的湖仓建设,通过一体化架构设计、一体化湖仓直访、一体化数据视图、一体化资产管理,形成了具有自身特色的湖仓技术体系。
通过对金融、游戏、制造等行业的深入洞察和技术共创,过去一年, StarRocks 不断打磨产品的功能、性能、稳定性,修改了 80 多万行代码,发布了近 50 个版本。而在今年 9 月的 StarRocks Summit Asia 2022 上,StarRocks 社区正式发布了StarRocks 极速数据湖分析,开启极速统一 3.0 时代。

(StarRocks 2.4 在 SSB单表、SSB多表、TPC-H三个标准测试集下,相比于去年同期,性能提升了50%-80%。在物化视图、资源隔离、Query Cache、自动化数据分布、导入优化等各个核心功能均有重大突破)
StarRocks 认为,极速数据湖分析就是为用户提供性能堪比数据仓库的数据湖分析。在整个架构层面,当前 StarRocks 的数据湖分析已经具备了存算分离、弹性伸缩的能力。在存储层,数据支持按照 Apache Hive、Apache Iceberg、Apache Hudi 等主流表格式维护在对象存储之上。在计算层,从查询生命周期来说,StarRocks 的无状态计算节点 compute node,已经可以负责从扫描到聚合的全部计算任务;在控制层,FE 统一接入各类主流数据湖的元数据,并对湖上查询请求进行统一调度和规划。用户通过 StarRocks 进行数据湖分析,一方面能够享受存算分离、弹性伸缩等前沿技术带来的降本增效,另一方面,无需数据导入即可享受到堪比数仓分析的极速性能体验,更加敏捷地从数据湖中获取灵感和洞见,驱动业务增长。
人民银行今年发布的《金融科技发展规划(2022-2025年)》中提出了八大重点任务,明确到 2025 年,金融科技整体水平与核心竞争力实现跨越式提升,数据要素价值充分释放、数字化转型高质量推进、金融科技治理体系日臻完善、关键核心技术应用更为深化、数字基础设施建设更加先进。其中,数据库一直是金融行业持续创新的重点领域,涌现出了大批的热点技术和产品。而数据库产品无论选择哪条技术路线,目的都是要满足高可用、容灾、数据一致性、业务连续性和系统可扩展等方面的要求。
面对金融级高要求,基于“极速统一”的数据分析新范式打造出的 MPP 数据库 StarRocks,可以全面提升数据处理和分析的性能,将复杂分散的既有架构融合为简单一致的崭新架构。 相信随着金融行业数字化转型的持续加速,StarRocks 必将应对更多的复杂查询、高并发、实时分析等场景,帮助用户实现数据价值最大化。