Pytorch的model.train() & model.eval() & torch.no_grad() & 为什么测试的时候不调用loss.backward()计算梯度还要关闭梯度
使用PyTorch进行训练和测试时一定注意要把实例化的model指定train/eval
model.train()
启用 BatchNormalization 和 Dropout
告诉我们的网络,这个阶段是用来训练的,可以更新参数。
model.eval()
不启用 BatchNormalization 和 Dropout。告诉我们的网络,这个阶段是用来测试的
在train模式下,dropout网络层会按照设定的参数p设置保留激活单元的概率(保留概率=p); batchnorm层会继续计算数据的mean和var等参数并更新。
在val模式下,dropout层会让所有的激活单元都通过,而batchnorm层会停止计算和更新mean和var,直接使用在训练阶段已经学出的mean和var值。
nn.Module内部有一个self.training参数,调用model.eval()后,这个参数会被设为False,nn.Dropout操作就是识别这个参数来判断是training还是eval的
训练完train_datasets之后,model要来测试样本了。在model(test_datasets)之前,需要加上model.eval(). 框架会自动把BN和DropOut固定住,不会取平均,而是用训练好的值,不然的话,一旦test的batch_size过小,很容易就会被BN层导致生成图片颜色失真极大!!!!
bn_layer = nn.BatchNorm2d(num_features=3) inputs = torch.randn(8, 3, 20, 20) bn_layer.eval() bn_outputs = bn_layer(inputs)但是开了model.eval(),并不会影响模型梯度的计算
即因为我们是测试阶段才会开model.eval() , 所以开了之后没人再会去用loss.backward()
但是model.eval()不影响模型梯度的计算,即使这个时候用了loss.backward(),是可以正常更新参数的
import torch import torch.nn as nn class model(nn.Module): def __init__(self, b): super(model, self).__init__() self.b = b def forward(self, x): y = torch.pow(x, 2) return y x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) b = torch.tensor([1.0, 1.0, 0.0], requires_grad=True) model = model(b) model.eval() # model.eval()不影响梯度的计算 # with torch.no_grad(): # with torch.no_grad()会使得y的梯度计算参数为False y = model(x) print(y.requires_grad) y.backward(torch.ones_like(x)) # pytorch无法进行tensor对tensor的求导,因此此处需要添加一个参数,得到一个标量,通过标量对tensor的求导,来计算想要的结果。 print(x.grad)
torch.no_grad()
torch.no_grad也是用在测试的时候,即和model.eval()用在一个地方,先model.eval()再torch.no_grad()
torch.no_grad() 是一个上下文管理器,负责关掉跟踪(反向)梯度计算,节省eval的时间和显存占用
不会追踪计算步骤,即构建计算图就不会记录torch.no_grad()包住的部分,那么也就不会计算它们的梯度。即虽然你进行了乘法操作,但是没有记录这个操作,所以梯度返传的时候就不会算这一步的梯度。
说torch.no_grad()关闭梯度计算的说法也是对的,因为torch.no_grad包住的非叶子节点的requires_grad属性变为了False,只要requires_grad=False就不会计算梯度。当然在inference的时候本身也不会调用loss.backward()计算梯度,而如果你想调用你也是调用不了的。只是这不是inference的时候用torch.no_grad能减少显存占用的原因。
被torch.no_grad()包裹起来的部分不会被追踪梯度,虽然仍可以前向传播进行计算得到输出,但计算过程(grad_fn)不会被记录,也就不能反向传播更新参数。具体地,对非叶子节点来说
- 非叶子节点的requires_grad属性变为了False
- 非叶子节点的grad_fn属性变为了None
这样便不会计算非叶节点的梯度。因此,虽然叶子结点(模型各层的可学习参数)的requires_grad属性没有改变(依然为True),也不会计算梯度,grad属性为None,且如果使用loss.backward()会报错(因为第一个非叶子节点(loss)的requires_grad属性为False,grad_fn属性为None)。因此,模型的可学习参数不会更新。
只进行inference时,model.eval()是必须使用的,否则会影响结果准确性。 而torch.no_grad()并不是强制的,只影响运行效率
如果不在意显存大小和计算时间的话,仅仅使用
model.eval()已足够得到正确的validation的结果;而with torch.zero_grad()则是更进一步加速和节省gpu空间(因为不用计算和存储gradient),从而可以更快计算,也可以跑更大的batch来测试model.eval()模式不会影响各层的gradient计算行为,即gradient计算和存储与training模式一样,只是不进行反传(backprobagation)
而with torch.no_grad()则主要是用于停止autograd模块的工作,以起到加速和节省显存的作用,具体行为就是停止gradient计算,从而节省了GPU算力和显存,但是并不会影响dropout和batchnorm层的行为。
为什么测试的时候不调用loss.backward()计算梯度还要torch.no_grad()关闭梯度计算
显然这不是多余的。因为实验完全可以证明,即使不调用loss.backward(), 测试的时候关闭梯度计算的显存会少很多。
这是因为在训练过程中由于loss.backward() 会将计算图释放,从而释放显存空间。而在测试的时候没有这一机制,因此有可能随着测试的进行中间变量越来越多,从而容易导致out of memory的发生。
使用torch.no_grad()的话,对包住的代码块直接不会构建计算图,也就不会计算梯度。因此 可以帮助节省内存空间。
所以能够帮助节省空间是储在计算图上(即每个tensor的grad_fn值),而不是每个节点的梯度值上,因为就算不加torch.no_grad, 你不调用loss.backward(), 每个点也是没有梯度的。
这也就能符合pytorch官方文档的话了
torch.no_grad() impacts the autograd engine and deactivate it. It will reduce memory usage and speed up computations but you won’t be able to backprop实验展示被with torch.no_grad()包住的代码,不用跟踪反向梯度计算
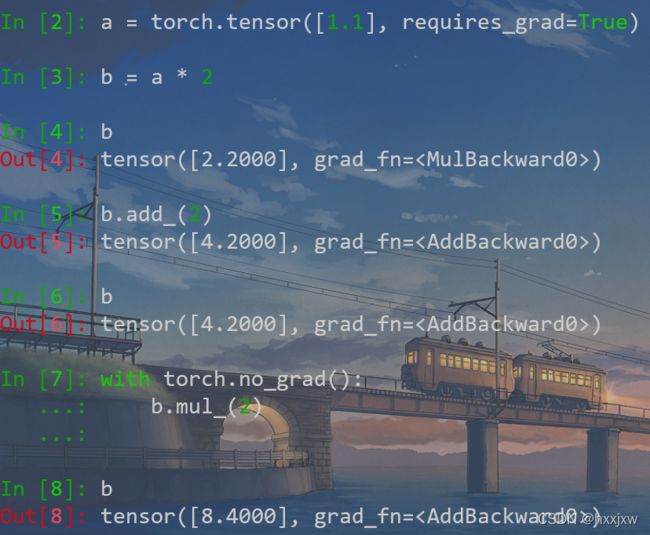
b = a * 2后输出tensor([2.2000], grad_fn=
) 可以看到梯度函数是MulBackward0,表示乘法的反向梯度函数 b.add_(2)后输出tensor([4.2000], grad_fn=
) 表明是add的反向梯度函数 但是被torch.no_grad()包住后的b.mul_(2) 却输出tensor([8.4000], grad_fn=
) 可以看到没有跟踪乘法的梯度,还是上面的加法的梯度函数,不过乘法是执行了的