GridSearchCV调参过程展示 + 模型融合
由于调参过程展示这块容易忘,所以就索性直接在这记录一下,具体代码和效果如下(调参顺序可以不按以下顺序,建议先调学习率,然后确定学习率调整弱学习器个数,调参技巧可以查看我的此篇博客:机器学习-XGBoost_醉翁之意不在酒~的博客-CSDN博客_xgboost基学习器):
一、对scale_pos_weight、min_child_weight、max_delta_step调参
start = time.time()
params = {
'scale_pos_weight':[1,2,3],
'min_child_weight':[1,2,3],
'max_delta_step' : [1,2,3]
}
Grid_xgb_test5 = GridSearchCV(XGBClassifier(eval_metric='auc'),param_grid=params,cv=5)
Grid_xgb_test5.fit(x_train,y_train)
end = time.time()
print('程序运行时间:%.2f分' %((end - start)/60))means = Grid_xgb_test5.cv_results_['mean_test_score']
params = Grid_xgb_test5.cv_results_['params']
for i in range(len(means)):
print('训练过程分数及参数:',means[i],params[i] )
print('\n最好的分数以及参数:',Grid_xgb_test5.best_score_,Grid_xgb_test5.best_params_)
二、选择确定好的参数对弱学习器进行调参
在调下一个参数时要把上面已经调好的参数确定下来进行训练,此处学习率是已经经过调整后选择的。
start = time.time()
params = {
'n_estimators':[460,500,510,550,600,1000],
'learning_rate':[0.1]
}
Grid_xgb_test1 = GridSearchCV(XGBClassifier(eval_metric='auc',max_delta_step=2,min_child_weight=3,scale_pos_weight=1),param_grid=params,cv=5)
Grid_xgb_test1.fit(x_train,y_train)
end = time.time()
print('程序运行时间:%.2f分' %((end - start)/60))means = Grid_xgb_test1.cv_results_['mean_test_score']
params = Grid_xgb_test1.cv_results_['params']
for i in range(len(means)):
print('训练过程分数及参数:',means[i],params[i])
print('\n最好的分数以及参数:',Grid_xgb_test1.best_score_,Grid_xgb_test1.best_params_) 
三、对树的深度调参
树的深度越大模型复杂度越高,一般为3-10之间。
start = time.time()
params = {
'max_depth':range(4,10)
}
Grid_xgb_test2 = GridSearchCV(XGBClassifier(learning_rate=0.1,n_estimators=500,max_delta_step=2,min_child_weight=3,scale_pos_weight=1,eval_metric='auc'),param_grid=params,cv=5)
Grid_xgb_test2.fit(x_train,y_train)
end = time.time()
print('程序运行时间:%.2f分' %((end - start)/60))means = Grid_xgb_test2.cv_results_['mean_test_score']
params = Grid_xgb_test2.cv_results_['params']
for i in range(len(means)):
print('训练过程分数及参数:',means[i],params[i] )
print('\n最好的分数以及参数:',Grid_xgb_test2.best_score_,Grid_xgb_test2.best_params_)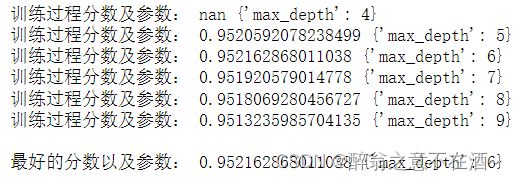
后面省略了,接下来介绍调参完后另外的提升思路!
四、模型混合
选取已经训练好的模型,然后混合训练,此处选择的为2个xgboost模型和一个lightgbm模型。
clf1 = XGBClassifier(
reg_alpha = 9,
booster='gbtree',
objective='reg:logistic',
scale_pos_weight = 1,
n_estimators = 500,
learning_rate = 0.1,
max_depth = 6,
colsample_bylevel=0.5,
colsample_bytree=1,
subsample=0.8,
eval_metric='auc',
max_delta_step = 2,
min_child_weight=3
)
#用下采样数据调整的模型
clf2 = XGBClassifier(
reg_lambda = 1,
reg_alpha = 7,
booster='gbtree',
objective='reg:logistic',
scale_pos_weight = 3,
n_estimators = 390,
learning_rate = 0.1,
max_depth = 6,
colsample_bylevel = 0.8,
colsample_bytree = 0.5,
subsample = 1,
eval_metric='auc'
)
clf3 = LGBMClassifier(
num_iterations=500,
learning_rate=0.1,
metric='auc',
)
eclf = VotingClassifier(estimators=[
('XGB1', clf1), ('XGB2', clf2), ('LGB',clf3)], voting='soft')
eclf.fit(x_train,y_train)
五、对混合模型分配权重
同样可以对各个模型的权重进行调参,如下所示:
start = time.time()
params = {'weights':[
[1,1,1],
[1,2,1],
[2,1,1],
[1,1,2],
[2,2,1],
[2,1,2],
[1,2,2]
]}
Grid_eclf = GridSearchCV(eclf,param_grid=params,cv=5)
Grid_eclf.fit(x_train,y_train)
end = time.time()
print('程序运行时间:%.2f分' %((end - start)/60))means = Grid_eclf.cv_results_['mean_test_score']
params = Grid_eclf.cv_results_['params']
for i in range(len(means)):
print('训练过程分数及参数:',means[i],params[i] )
print('\n最好的分数以及参数:',Grid_eclf.best_score_,Grid_eclf.best_params_)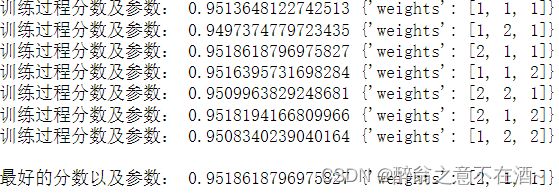
六、选择权重进行训练
eclf_end = VotingClassifier(estimators=[
('XGB1', clf1), ('XGB2', clf2), ('LGB',clf3)], voting='soft',weights=[2,1,1])
eclf_end.fit(x_train,y_train)如此文档有助于你请点个赞万分感谢∧_∧!