深度解析Batch Normalization(批归一化)

©作者 | 初识CV
单位 | 海康威视
研究方向 | 计算机视觉
前言
这是 2015 年深度学习领域非常棒的一篇文献:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》,这个算法目前已经被大量的应用,最新的文献算法很多都会引用这个算法,进行网络训练。

论文标题:
Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift
论文链接:
https://arxiv.org/pdf/1502.03167.pdf
BN 的优点是:
1. 可以选择比较大的初始学习率,加快网络的收敛。实验结果表明,就算你使用小的学习率,收敛速度也会很快;
2. 减少正则化参数的 Dropout、L2 正则项参数的选择问题,BN 具有提高网络泛化能力的特性;
3. 不需要使用局部响应归一化层(局部响应归一化是 Alexnet 网络用到的方法),因为 BN 本身就是一个归一化网络层;
4. 可以把训练数据彻底打乱,防止每批训练的时候,某一个样本经常被挑选到,在 ImageNet 上提高 1% 的精度。
BN 的核心思想不是为了防止梯度消失或者防止过拟合,其核心是通过对系统参数搜索空间进行约束来增加系统鲁棒性,这种约束压缩了搜索空间,约束也改善了系统的结构合理性,这会带来一系列的性能改善,比如加速收敛,保证梯度,缓解过拟合等。

深入解析网络为什么需要Normalization
这里我们需要思考一个问题,我们知道在神经网络训练开始前,都要对输入数据进行归一化处理,那为什么需要归一化呢?归一化后有什么好处呢?
机器学习领域有个很重要的假设:IID 独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。因此,在把数据喂给机器学习模型之前,“白化(whitening)”是一个重要的数据预处理步骤,其中最典型白化方法是 PCA。白化一般包含两个目的:
1. 去除特征之间的相关性:独立;
2. 使得所有特征具有相同的均值和方差 :同分布。
每批训练数据的分布各不相同,那么网络需要在每次迭代中去学习适应不同的分布,这样将会大大降低网络的训练速度。对于深度网络的训练是一个非常复杂的过程,只要网络的前面几层发生微小的改变,那么这些微小的改变在后面的层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。

什么是Internal Covariate Shift(内部协变量转移)
大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如 transfer learning / domain adaptation 等。而 covariate shift 就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有 ,
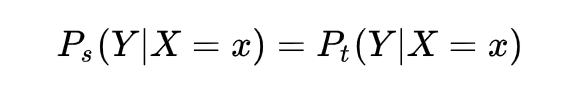
但是:

大家细想便会发现,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了 covariate shift 的定义。由于是对层间信号的分析,也即是“internal”的来由。
简单点说就是:对于深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数不停在变化,所以每个隐层都会面临 covariate shift 的问题,也就是在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”,Internal 指的是深层网络的隐层,是发生在网络内部的事情,而不是 covariate shift 问题只发生在输入层。
那么 Internal Covariate Shift 会导致什么问题呢?
1. 每个神经元的输入数据不再是“独立同分布”;
2. 上层参数需要不断适应新的输入数据分布,降低学习速度;
3. 下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止;
4. 每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。

详细剖析Batch Normalization
3.1 BN的设计思路
和激活函数层、卷积层、全连接层、池化层一样,BN 也属于网络的一层。前面的介绍中我们提到,由于网络的低层在训练的时候更新了参数,从而引起后面层输入数据分布的变化,这个时候我们可能就会想,如果在每一层输入的时候,再加个预处理操作那该有多好啊,比如网络第三层输入数据把它归一化至:均值 0、方差为 1,然后再输入第三层计算,这样我们就可以解决前面所提到的“Internal Covariate Shift”的问题了。
Paper 的想法就是:在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层。
说到神经网络输入数据预处理,最好的算法莫过于白化预处理。然而白化计算量太大了,很不划算,还有就是白化不是处处可微的,所以在深度学习中,其实很少用到白化。经过白化预处理后,数据满足以下两个条件:
1. 去除特征之间的相关性:独立;
2. 使得所有特征具有相同的均值和方差 :同分布。
如果数据特征维数比较大,要进行 PCA,也就是实现白化的第 1 个要求,是需要计算特征向量,计算量非常大,于是为了简化计算,作者忽略了第 1 个要求,仅仅使用了下面的公式进行预处理,也就是近似白化预处理:
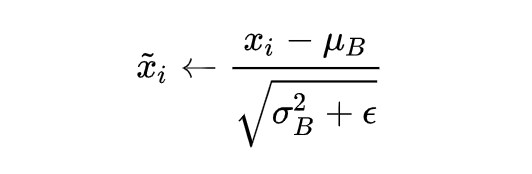
经过前面简单介绍,这个时候可能我们会想当然的以为:好像很简单的样子,不就是在网络中间层数据做一个归一化处理嘛,这么简单的想法,为什么之前没人用呢?
然而实现起来并不是那么简单的。如果仅仅使用上面的归一化公式,对网络某一层 A 的输出数据做归一化,然后送入网络下一层 B,这样是会影响到本层网络 A 所学习到的特征的。打个比方,比如我网络中间某一层学习到特征数据本身就分布在 S 型激活函数的两侧,你强制把它给我归一化处理、标准差也限制在了 1,把数据变换成分布于 s 函数的中间部分,这样就相当于我这一层网络所学习到的特征分布被你搞坏了,这可怎么办?于是文献使出了一招惊天地泣鬼神的招式:变换重构,引入了可学习参数 γ、β,这就是算法关键之处:
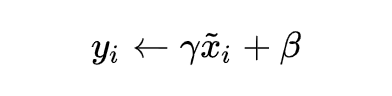
接下来让我们详细的来了解一下 BN 的训练过程和推理过程。
3.2 Training过程中BN
Batch Normalization 于 2015 年由 Google 提出,开 Normalization 之先河。其规范化针对单个神经元进行,利用网络训练时一个 mini-batch 的数据来计算该神经元 的均值和方差,因而称为 Batch Normalization。
其公式如下:

其中:
1. 输入为数值集合 ,可训练参数 , 是 mini-batch 的大小, 是均值, 是方差;
2. BN 的具体操作为:先计算 的均值和方差,之后将 集合的均值、方差变换为0、1(对应上式中 ),最后将 中每个元素乘以 再加 ,输出。 是可训练参数,参与整个网络的 BP;
3. 归一化的目的:将数据规整到统一区间,减少数据的发散程度,降低网络的学习难度。BN 的精髓在于归一之后,使用 作为还原参数,在一定程度上保留原数据的分布。
那 BN 中均值、方差通过哪些维度计算得到?
神经网络中传递的张量数据,其维度通常记为 [N, H, W, C],其中 N 是 batch_size,H、W 是行、列,C 是通道数。那么上式中 BN 的输入集合 B 就是下图中蓝色的部分:
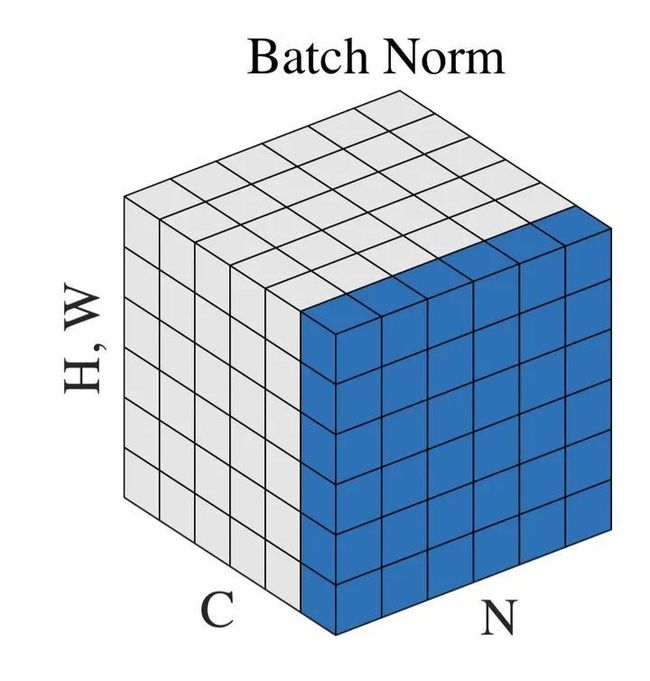
均值的计算,就是在一个批次内,将每个通道中的数字单独加起来,再除以 。举个例子:该批次内有 10 张图片,每张图片有三个通道RBG,每张图片的高、宽是 H、W,那么均值就是计算 10 张图片 R 通道的像素数值总和除以 ,再计算 B 通道全部像素值总和除以 ,最后计算 G 通道的像素值总和除以 。方差的计算类似。
可训练参数 的维度等于张量的通道数,在上述例子中,RBG 三个通道分别需要一个 和一个 ,所以 的维度等于 3。
为什么上述例子中可训练参数 的维度等于张量的通道数呢?
我们知道 BN 层是对于每个神经元做归一化处理,甚至只需要对某一个神经元进行归一化,而不是对一整层网络的神经元进行归一化。既然 BN 是对单个神经元的运算,那么在 CNN 中卷积层上要怎么搞?
假如某一层卷积层有 64 个特征图,每个特征图的大小是 ,这样就相当于这一层网络有 个神经元,如果采用 BN,就会有 个参数 ,这样岂不是太恐怖了。因此卷积层上的 BN 使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理。在 CNN 中我们可以把每个特征图看成是一个特征处理(一个神经元),因此在使用Batch Normalization时,mini-batch size 的大小就是:,于是对于每个特征图都只有一对可学习参数:,即共有 对可学习参数:。
3.3 Testing过程中的BN
实际测试时,我们依然使用下面的公式:
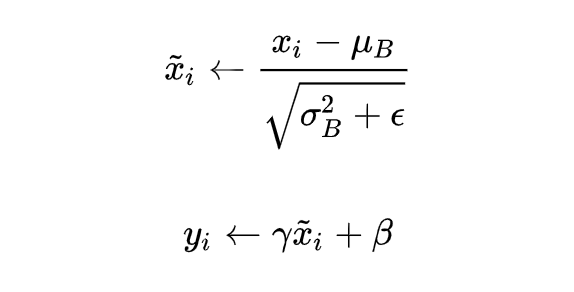
只是其中的 均值, 方差发生了改变,推理时,均值、方差是基于所有批次的期望计算所得,公式如下:

其中 表示 x 的期望。
这里的均值和方差已经不是针对某一个 Batch 了,而是针对整个数据集而言。因此,在训练过程中除了正常的前向传播和反向求导之外,我们还要记录每一个 Batch 的均值和方差,以便训练完成之后按照上式计算整体的均值和方差。最后测试阶段,BN 的使用公式就是:

上式可以通过下面两个式子得到:
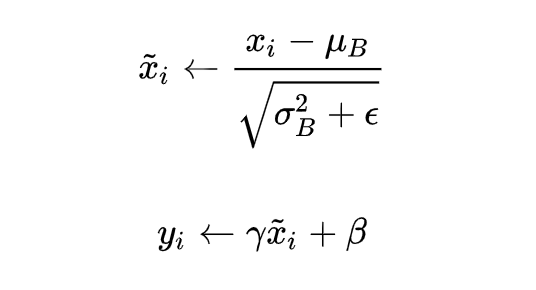

参考文献
[1] https://blog.csdn.net/hjimce/article/details/50866313
[2] https://arxiv.org/pdf/1502.03167.pdf
[3] https://zhuanlan.zhihu.com/p/93643523

送福利啦!
独家定制论文锦鲤卡套
限量 200 份
能否抢到全凭手速
扫码回复「卡套」
立即免费参与领取

现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
