python3深度学习---第五章学习笔记:tensorflow卷积神经网络Conv2D
因为第5章的代码较多,且零散,所以对代码进行了一些调整和归纳,将零散的代码归为函数使用
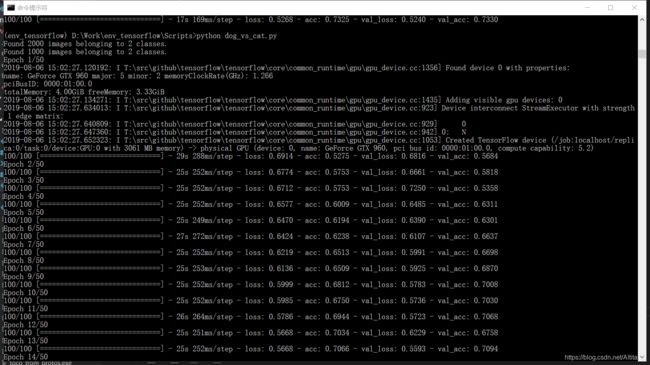
第一节MNIST的卷积网络实现很简单,因为数据集已经集成在keras里了,而在第二节准备数据集的时候遇到了点小问题,首先书中提供的链接已经不存在了,毕竟是2年前的书了。所以就自己在kaggle上找数据集,而我下载下来的数据集又和书中的不太一样,1、目录结构不一样,2、文件名不规范,而且书中处理数据集的方法有点像命令式的方式,感觉较繁琐,所以自己写了两个函数来处理,这样可以帮助更好的理清思路,建议用GPU跑. 我的是gtx9604G显卡,跑50个epoch需要21分钟左右,虽然不快,但也比CPU好太多,大概是cpu的25倍
import os,shutil
#tensorflow本身已集成keras,但也可以额外安装,此步是为了兼容两种情况
try:
from keras import layers
from keras import models
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
except Exception as e:
import tensorflow as tf
layers = tf.keras.layers
models = tf.keras.models
ImageDataGenerator = tf.keras.preprocessing.image.ImageDataGenerator
optimizers = tf.keras.optimizers
import matplotlib.pyplot as plt
original_dataset_dir = r'D:\Work\datasets\dogs_vs_cats\train'#原始数据集解压目录
base_dir = r'D:\Work\datasets\cats_and_dogs_small' #提取的小批量图片的保存目录
def mk_dir(*path):
try:
full_path = ''
for sub_path in path:
full_path = os.path.join(full_path, sub_path )
os.makedirs( full_path )#递归创建多层文件夹
return full_path
except Exception as e:
print('创建失败,检查文件夹是否已存在')
print( full_path )
return full_path
def copy_img( train_validation_test, dogs_or_cats,how_num ):
'''
train_validation_test字符串 ,表示要建立的是训练、验证或者是测试目录
dogs_or_cats字符串,意思为是狗还是猫
how_num元组,表示拷贝量从多少到多少,例如0,1000
'''
filename = ''.join([dogs_or_cats[:-1] , '.{}.jpg']) #dogs_or_cats[:-1]因为原始文件名是dog.25.jpg这样的,所以要先删除dogs、cats后面的‘s’
fnames = [ filename.format( str(i) ) for i in range( how_num[0],how_num[1] ) ]
full_path = mk_dir( base_dir,train_validation_test,dogs_or_cats )
print( '全路径:{}'.format(full_path ) )
file_count = 0
for fname in fnames:
try:
src = os.path.join( original_dataset_dir, dogs_or_cats, fname )
dst = os.path.join(full_path ,fname )
shutil.copyfile( src,dst )
file_count = file_count + 1
except FileNotFoundError as FNFerr:#跳过原文件夹里不存在的文件
#print( FNFerr )
#print( '不存在文件:{}'.format( fname ) )
continue
print( '共成功复制--{}样本{}份'.format(dogs_or_cats,file_count) )
def re_name(file_path, file_iter ,dog_or_cat ):
'''
要求:原始数据集存放目录下已划分好狗和猫的图片文件目录,分别为目录dogs ,目录cats
file_path: 原始数据的存放目录
file_iter: 原始数据存放目录里的所有文件的文件名列表
dog_or_cat:要重命名的是‘dog’or‘cat’的文件
'''
count = 0
for filename in file_iter:
try:
os.rename( os.path.join( file_path, dog_or_cat+'s', filename) ,
os.path.join( file_path, dog_or_cat+'s', '{}.{}.jpg'.format(dog_or_cat,count))#
)
except FileExistsError as err:
continue
finally:
count += 1
print ('重命名文件:{}个'.format(count))
def sort_fnames_list( ls ):
'''字符串列表按中间数字排序
例如: ['dog.17.jpg','dog.117.jpg'] 列表,按数字序号排序
'''
for i in range( len( ls ) ):
ls[i] = ls[i].split('.')
ls[i][1] = int( ls[i][1] )
ls.sort()
for i in range( len(ls) ):
ls[i] = '.'.join( [ ls[i][0] , str( ls[i][1] ) , ls[i][2] ] )
return ls
def create_small_data( ):
'''分步拷贝文件'''
# 1: 规整化文件名,因为我下载的数据集很多文件名不规则.如你的训练文件已经规范,则省略
file_path = r'D:\Work\datasets\dogs_vs_cats\train'#你的训练文件目录
dog_filenames =os.listdir( os.path.join(file_path ,'dogs') )
dog_filenames = sort_fnames_list( dog_filenames )
re_name(file_path,dog_filenames ,'dog')
cat_filenames =os.listdir(os.path.join( file_path ,'cats') )
cat_filenames = sort_fnames_list( cat_filenames )
re_name(file_path,cat_filenames ,'cat')
#2:拷贝小批量dogs图片文件
copy_img( 'train','dogs', (0,1000))
copy_img( 'validation','dogs',( 1000,1500 ) )
copy_img( 'test','dogs',( 1500,2000 ) )
#3:拷贝小批量cats图片
copy_img( 'train','cats',(0,1000) )
copy_img( 'validation','cats',( 1000,1500 ) )
copy_img( 'test','cats',( 1500,2000 ) )
def create_model( ):
'''创建一个如下的固定模型'''
model = models.Sequential()
model.add( layers.Conv2D( 32, (3,3),activation= 'relu' ,input_shape=(150,150,3) ) )
model.add( layers.MaxPooling2D( (2,2) ) )
model.add( layers.Conv2D( 64,(3,3),activation = 'relu' ) )
model.add( layers.MaxPooling2D( (2,2) ) )
model.add( layers.Conv2D( 128,(3,3),activation = 'relu' ) )
model.add( layers.MaxPooling2D( (2,2) ) )
model.add( layers.Conv2D( 128,(3,3),activation = 'relu' ) )
model.add( layers.MaxPooling2D( (2,2) ) )
model.add( layers.Flatten() )
model.add( layers.Dropout( 0.5 ) ) #优化全链接层
model.add( layers.Dense( 512,activation = 'relu' ) )
model.add( layers.Dense( 1,activation = 'sigmoid' ) )
return model
def get_dirs( ):
return {
'train': r'D:\Work\datasets\cats_and_dogs_small\train',
'validation':r'D:\Work\datasets\cats_and_dogs_small\validation',
'test':r'D:\Work\datasets\cats_and_dogs_small\test'
}
def data_generator( dir,target_size=(150,150) ,batch_size=20, class_mode ='categorical',training = False ):
'''
dir : 包含分类子目录的数据目录,目录下的子目录就是“分类名”
target_size:目标图片被缩放成的统一大小
batch_size:每次抽取数据样本的数量
class_mode:categorical", "binary", "sparse", "input" 或 None 之一。
默认:"categorical"。决定返回的标签数组的类型:
training:默认为False,及默认不使用数据增强,只有训练图像识别时才使用True,使用增强图像数据技术
'''
if training:
generator = ImageDataGenerator(
rescale = 1./255,
rotation_range=40, #图像随机旋转的角度范围
width_shift_range=0.2,#图像水平移动的比例
height_shift_range=0.2,
shear_range=0.2,#随机错切得比例
zoom_range=0.2,#随机缩放的比例
horizontal_flip=True,
fill_mode='nearest', #默认的变形填充空白模式
)
else:
generator = ImageDataGenerator( rescale = 1./255)
generator = generator.flow_from_directory(
dir,
target_size = target_size,
batch_size = batch_size,
class_mode = class_mode
)
return generator
if __name__=='__main__':
#create_small_data() #如数据已调整好,就不需要
model = create_model()
model.compile( #配置训练模型
loss = 'binary_crossentropy',
optimizer = optimizers.RMSprop( lr=1e-4 ),
metrics = ['acc']
)
#用于训练的数据图像预处理,得到预处理的生成器
train_generator = data_generator(
dir = get_dirs()['train'], #目录下的子目录即为类别
target_size=(150,150),
batch_size = 32,
class_mode='binary',
training = True, #训练模式,开启图像数据增强
)
#用于验证的图像 预处理
validation_generator = data_generator(
dir=get_dirs()['validation'],
target_size=( 150,150 ),
batch_size= 32,
class_mode='binary'
)
#开始训练数据
history = model.fit_generator(
train_generator,
steps_per_epoch = 100,
epochs = 50,
validation_data = validation_generator,
validation_steps = 100
)
model.save( 'dogs_and_cats_small_1.h5' )
#画图
acc = history.history[ 'acc' ]
val_acc = history.history ['val_acc' ]
loss = history.history['loss' ]
val_loss = history.history['val_loss']
epochs = range( 1, len(acc) +1 )
plt.plot( epochs,acc,'bo',label='Training ACC' )
plt.plot( epochs,val_acc,'b',label='Validation Acc' )
plt.title( "Training and Validation Accuracy" )
plt.legend()
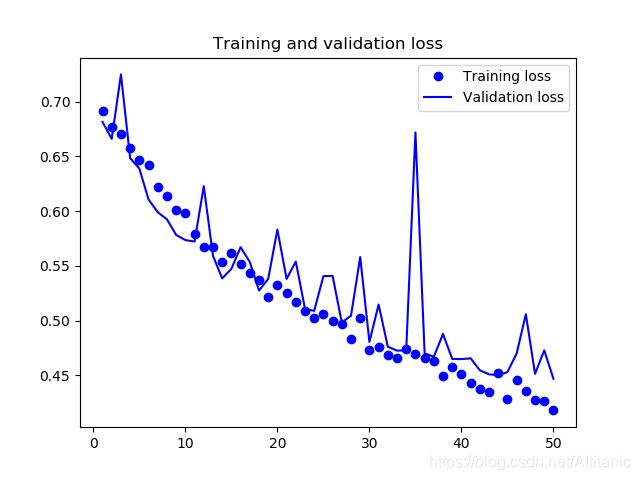
plt.figure()
plt.plot( epochs, loss, 'bo',label = 'Training loss' )
plt.plot( epochs, val_loss,'b',label = 'Validation loss' )
plt.title( 'Training and validation loss' )
plt.legend()
plt.show() 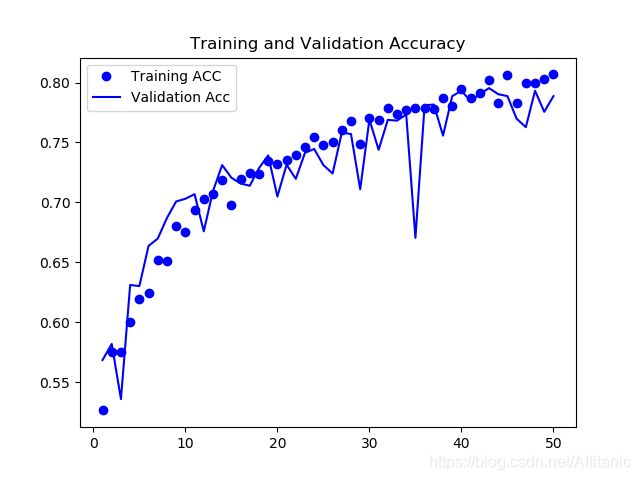
欢迎大家留言讨论