房天下网站二手房爬虫、数据清洗及可视化(python)
房天下网站二手房爬虫、数据清洗及可视化(python)
爬虫代码
###爬取完的数据存入MangoDB中,需自行下载MangoDB
import requests, json, threading
from bs4 import BeautifulSoup
import numpy as np
import re
from tqdm import trange
from pymongo import MongoClient as Client
city = ['北京', '上海', '广东', '深圳', '沈阳', '大连']
e_city = ['beijing', 'shanghai', 'guangdong', 'shenzheng', 'shenyang', 'dalian']
eshouse = ['https://esf.fang.com/house/i3{}/', 'https://sh.esf.fang.com/house/i3{}/',
'https://gz.esf.fang.com/house/i3{}/', 'https://sz.esf.fang.com/house/i3{}/',
'https://sy.esf.fang.com/house/i3{}/', 'https://dl.esf.fang.com/house/i3{}/']
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/64.0.3282.186 Safari/537.36'}
is_craw = {}
proxies = []
def write_to_mongo(ips, city):
'''将数据写入mongoDB'''
client = Client(host='localhost', port=27017)
db = client['fs_db']
coll = db[city + '_good']
for ip in ips:
coll.insert_one({'name': ip[0], \
'price': ip[1],
'addresses': ip[2],
'areas': ip[3],
'eq': ip[4]})
client.close()
def read_from_mongo(city):
client = Client(host='localhost', port=27017)
db = client['fs_db']
coll = db[city + '_good']
li = coll.find()
client.close()
return li
class Consumer(threading.Thread):
def __init__(self, args):
threading.Thread.__init__(self, args=args)
def run(self):
global is_craw
url_demo, i, city_id, lock = self._args
print("{}, 第{}页".format(city[city_id], i))
url = url_demo.format(i)
soup = get_real(url)
names = []
for name in soup.select('.tit_shop'):
names.append(name.text.strip())
addresses = []
for item in soup.find_all('p', attrs={'class': 'add_shop'}):
address = item.a.text + " " + item.span.text
addresses.append(address.replace('\t', '').replace('\n', ''))
es = []
for item in soup.find_all('p', attrs={'class': 'tel_shop'}):
es.append(item.text.replace('\t', '').replace('\n', ''))
moneys = []
for money in soup.find_all("span", attrs={"class": 'red'}):
moneys.append(money.text.strip())
areas = []
for area in soup.find_all('dd', attrs={'class': 'price_right'}):
areas.append(area.find_all('span')[-1].text)
houses = []
for idx in range(len(names)):
try:
item = [names[idx], moneys[idx], addresses[idx], areas[idx], es[idx]]
print(item)
houses.append(item)
except Exception as e:
print(e)
lock.acquire()
write_to_mongo(houses, e_city[city_id])
lock.release()
print("线程结束{}".format(i))
def dict2proxy(dic):
s = dic['type'] + '://' + dic['ip'] + ':' + str(dic['port'])
return {'http': s, 'https': s}
def get_real(url):
resp = requests.get(url, headers=header)
soup = BeautifulSoup(resp.content, 'html.parser', from_encoding='gb18030')
if soup.find('title').text.strip() == '跳转...':
pattern1 = re.compile(r"var t4='(.*?)';")
script = soup.find("script", text=pattern1)
t4 = pattern1.search(str(script)).group(1)
pattern1 = re.compile(r"var t3='(.*?)';")
script = soup.find("script", text=pattern1)
t3 = re.findall(pattern1, str(script))[-2]
url = t4 + '?' + t3
HTML = requests.get(url, headers=header)
soup = BeautifulSoup(HTML.content, 'html.parser', from_encoding='gb18030')
elif soup.find('title').text.strip() == '访问验证-房天下':
pass
return soup
def read_proxies():
client = Client(host='localhost', port=27017)
db = client['proxies_db']
coll = db['proxies']
# 先检测,再写入,防止重复
dic = list(coll.find())
client.close()
return dic
def craw():
lock = threading.Lock()
for idx in trange(len(e_city)):
url = eshouse[idx]
soup = get_real(url.format(2))
try:
page_number = int(soup.find('div', attrs={'class': 'page_al'}).find_all('span')[-1].text[1:-1])
pages = list(range(1, page_number + 1))
except:
pages = list(range(1, 101))
url_demo = url
ts = []
# pages = [1, 2, 3]
while len(pages) != 0:
for i in range(10):
t = Consumer((url_demo, pages.pop(), idx, lock))
t.start()
ts.append(t)
if len(pages) == 0:
break
for t in ts:
t.join()
ts.remove(t)
if __name__ == '__main__':
craw()
数据清洗代码
import csv
import pandas as pd
try:
df = pd.read_csv(r'shenyang_good.csv', encoding='utf-8')
except:
df = pd.read_csv(r'shenyang_good.csv', encoding='gbk')
df.drop_duplicates(subset=None, keep='first', inplace=True)
out = open('清洗后城市二手房数据.csv', 'a', newline='')
csv_write = csv.writer(out, dialect='excel')
# csv_write.writerow(['城市', '名称', '地址', '单价', '总价', '规格',
# '面积', '层段', '总层数', '朝向', '建房时期', '介绍'])
old_addresses = []
old_areas = []
old_eq = []
old_name = []
old_price = []
for index in df['addresses']:
old_addresses.append(index)
for index in df['areas']:
old_areas.append(index)
for index in df['eq']:
old_eq.append(index)
for index in df['name']:
old_name.append(index)
for index in df['price']:
old_price.append(index)
for index in range(len(old_addresses)):
try:
city = '沈阳'
name, address = old_addresses[index].split(' ')
yuan = old_areas[index][:-3:]
price = old_price[index][:-1:]
intro = old_name[index]
specs, rate, totals, toward, buildTime, people = old_eq[index].split('|')
rate = rate[:-1:]
layer, total = totals.split('(')
total = total[1:-2:]
buildTime = buildTime[:4:]
csv_write.writerow([city, name, address, yuan, price, specs, rate,
layer, total, toward, buildTime, intro])
except:
continue
print('清洗完成!')
可视化代码
##1.堆叠柱状图代码
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType
import pandas as pd
try:
df = pd.read_csv(r'清洗后城市二手房数据.csv', encoding='utf-8')
except:
df = pd.read_csv(r'清洗后城市二手房数据.csv', encoding='gbk')
city_lst = ['北京', '上海', '广州', '深圳', '沈阳', '大连'] # 城市
city = [] # 城市
buildTime = [] # 建房时期
new_buildTime = [[[], []] for i in range(6)]
data1 = []
data2 = []
for index in df['城市']:
city.append(index)
for index in df['建房时期']:
buildTime.append(index)
for index in range(len(city)):
for num in range(len(city_lst)):
if city[index] == city_lst[num]:
if int(buildTime[index]) >= 2008:
new_buildTime[num][1].append(buildTime[index])
else:
new_buildTime[num][0].append(buildTime[index])
for g in range(len(new_buildTime)):
value1 = len(new_buildTime[g][0])
value2 = len(new_buildTime[g][1])
result1 = {'value': value1, 'percent': '%.2f' % (value1/(value1+value2))}
result2 = {'value': value2, 'percent': '%.2f' % (value2/(value1+value2))}
data1.append(result1)
data2.append(result2)
print(data1)
print(data2)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(city_lst)
.add_yaxis("2008年以前建房", data1, stack="stack1", category_gap="50%")
.add_yaxis("2008年以后建房", data2, stack="stack1", category_gap="50%")
.set_series_opts(
label_opts=opts.LabelOpts(
position="right",
formatter=JsCode(
"function(x){return Number(x.data.percent * 100).toFixed() + '%';}"
),
)
)
.render("不同城市2008年前后建房数量-堆叠柱状图.html")
)
##效果图

##2. 3D柱状图代码
from pyecharts.charts import Pie, Bar, Line, Scatter3D, Bar3D
from tqdm import trange
from pymongo import MongoClient as Client
import csv
from pyecharts import options as opts
def draw():
with open("清洗后城市二手房数据.csv", 'r') as f:
reader = csv.reader(f)
data = list(reader)
Bar3D().add(
series_name="",
data=[[item[0], item[4], item[6]]for item in data],
xaxis3d_opts=opts.Axis3DOpts(
name='城市',
type_='category'
),
yaxis3d_opts=opts.Axis3DOpts(
name='每平方米价格'
),
zaxis3d_opts=opts.Axis3DOpts(
name='面积'
)).render("不同城市价格对应房屋规格3D.html")
if __name__ == '__main__':
draw()
##效果图

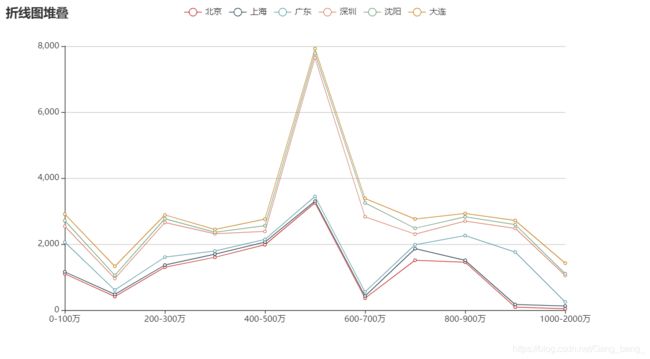
##3.折线图代码
import pyecharts.options as opts
from pyecharts.charts import Line
import pandas as pd
try:
df = pd.read_csv(r'清洗后城市二手房数据.csv', encoding='utf-8')
except:
df = pd.read_csv(r'清洗后城市二手房数据.csv', encoding='gbk')
city_lst = ['北京', '上海', '广州', '深圳', '沈阳', '大连'] # 城市
city = [] # 城市
price = [] # 建房时期
new_buildTime = [[[], [],[],[],[],[]] for i in range(6)]
data1 = []
data2 = []
data3 = []
data4 = []
data5 = []
data6 = []
for index in df['城市']:
city.append(index)
for index in df['总价']:
price.append(index)
for index in range(len(city)):
for num in range(len(city_lst)):
if city[index] == city_lst[num]:
if str(city[index]) == "北京":
new_buildTime[num][0].append(price[index])
elif str(city[index]) == "上海":
new_buildTime[num][1].append(price[index])
elif str(city[index]) == "广东":
new_buildTime[num][2].append(price[index])
elif str(city[index]) == "深圳":
new_buildTime[num][3].append(price[index])
elif str(city[index]) == "沈阳":
new_buildTime[num][4].append(price[index])
elif str(city[index]) == "大连":
new_buildTime[num][5].append(price[index])
for g in range(len(new_buildTime)):
data1.append(new_buildTime[g][0])
data2.append(new_buildTime[g][1])
data3.append(new_buildTime[g][2])
data4.append(new_buildTime[g][3])
data5.append(new_buildTime[g][4])
data6.append(new_buildTime[g][5])
x_data = ["0-100万", "100-200万", "200-300万", "300-400万", "400-500万", "500-600万",'600-700万','700-800万','800-900万','900-1000万','1000-2000万']
(
Line()
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="北京",
stack="总量",
y_axis=new_buildTime[0][0],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="上海",
stack="总量",
y_axis=new_buildTime[1][1],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="广东",
stack="总量",
y_axis=new_buildTime[2][2],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="深圳",
stack="总量",
y_axis=new_buildTime[3][3],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="沈阳",
stack="总量",
y_axis=new_buildTime[4][4],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="大连",
stack="总量",
y_axis=new_buildTime[5][5],
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="折线图堆叠"),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
yaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter="{value}"),
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("不同城市房价对比-折线图.html")
)
##效果图
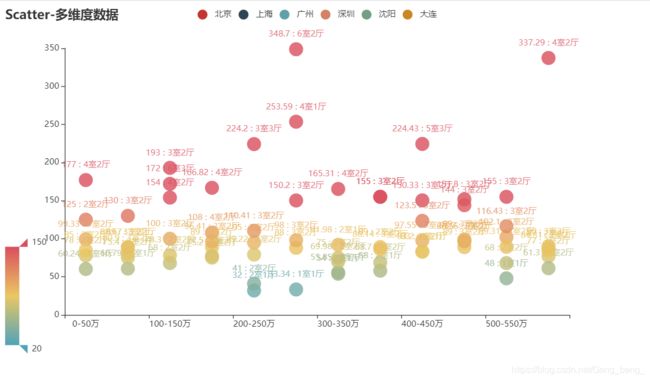
##4.多维散点图代码
from pyecharts import options as opts
from pyecharts.charts import Scatter
from pyecharts.commons.utils import JsCode
from pyecharts.faker import Faker
import pandas as pd
import pyecharts as pyec
try:
df = pd.read_csv(r'清洗后城市二手房数据.csv', encoding='utf-8')
except:
df = pd.read_csv(r'清洗后城市二手房数据.csv', encoding='gbk')
city_lst = ['北京', '上海', '广州', '深圳', '沈阳', '大连'] # 城市
city = [] # 城市
guige = [] # 规格
area = [] #面积
new_guige = [[[],[],[],[],[],[]] for i in range(6)]
new_area = [[[],[],[],[],[],[]] for i in range(6)]
for index in df['城市']:
city.append(index)
for index in df['规格']:
guige.append(index)
for index in df['面积']:
area.append(index)
for index in range(len(city)):
for num in range(len(city_lst)):
if city[index] == city_lst[num]:
if str(city[index]) == "北京":
new_guige[num][0].append(guige[index])
new_area[num][0].append(area[index])
elif str(city[index]) == "上海":
new_guige[num][1].append(guige[index])
new_area[num][1].append(area[index])
elif str(city[index]) == "广州":
new_guige[num][2].append(guige[index])
new_area[num][2].append(area[index])
elif str(city[index]) == "深圳":
new_guige[num][3].append(guige[index])
new_area[num][3].append(area[index])
elif str(city[index]) == "沈阳":
new_guige[num][4].append(guige[index])
new_area[num][4].append(area[index])
elif str(city[index]) == "大连":
new_guige[num][5].append(guige[index])
new_area[num][5].append(area[index])
y_data = ["1室1厅", "1室0厅", "1室2厅", "1室3厅", "1室4厅", "2室0厅",'2室1厅','2室2厅','2室3厅','2室4厅',
"3室0厅",'3室1厅','3室2厅','3室3厅','3室4厅',"4室0厅",'4室1厅','4室2厅','4室3厅','4室4厅',
"5室0厅",'5室1厅','5室2厅','5室3厅','5室4厅',"6室0厅",'6室1厅','6室2厅','6室3厅','6室4厅']
x_data = ['0-50万','50-100万','100-150万','150-200万','200-250万','250-300万','300-350万','350-400万','400-450万','450-500万','500-550万','550-600万']
c = (
Scatter()
.add_xaxis(x_data)
.add_yaxis(
"北京",
[list(z) for z in zip(new_area[0][0],new_guige[0][0])],
# 标记的大小
symbol_size=20,
#标签配置项
label_opts=opts.LabelOpts(
formatter=JsCode(
# 构造回调函数
"function(params){return params.value[1] +' : '+ params.value[2];}"
) #params.value[1]对应y轴Faker.values() : params.value[2]对应y轴Faker.choose()
),
)
.add_yaxis(
"上海",
[list(z) for z in zip(new_area[1][1],new_guige[1][1])],
# 标记的大小
symbol_size=20,
#标签配置项
label_opts=opts.LabelOpts(
formatter=JsCode(
# 构造回调函数
"function(params){return params.value[1] +' : '+ params.value[2];}"
) #params.value[1]对应y轴Faker.values() : params.value[2]对应y轴Faker.choose()
),
)
.add_yaxis(
"广州",
[list(z) for z in zip(new_area[2][2],new_guige[2][2])],
# 标记的大小
symbol_size=20,
#标签配置项
label_opts=opts.LabelOpts(
formatter=JsCode(
# 构造回调函数
"function(params){return params.value[1] +' : '+ params.value[2];}"
) #params.value[1]对应y轴Faker.values() : params.value[2]对应y轴Faker.choose()
),
)
.add_yaxis(
"深圳",
[list(z) for z in zip(new_area[3][3],new_guige[3][3])],
# 标记的大小
symbol_size=20,
#标签配置项
label_opts=opts.LabelOpts(
formatter=JsCode(
# 构造回调函数
"function(params){return params.value[1] +' : '+ params.value[2];}"
) #params.value[1]对应y轴Faker.values() : params.value[2]对应y轴Faker.choose()
),
)
.add_yaxis(
"沈阳",
[list(z) for z in zip(new_area[4][4],new_guige[4][4])],
# 标记的大小
symbol_size=20,
#标签配置项
label_opts=opts.LabelOpts(
formatter=JsCode(
# 构造回调函数
"function(params){return params.value[1] +' : '+ params.value[2];}"
) #params.value[1]对应y轴Faker.values() : params.value[2]对应y轴Faker.choose()
),
)
.add_yaxis(
"大连",
[list(z) for z in zip(new_area[5][5],new_guige[5][5])],
# 标记的大小
symbol_size=20,
#标签配置项
label_opts=opts.LabelOpts(
formatter=JsCode(
# 构造回调函数
"function(params){return params.value[1] +' : '+ params.value[2];}"
) #params.value[1]对应y轴Faker.values() : params.value[2]对应y轴Faker.choose()
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="Scatter-多维度数据"),
# 提示框配置项
tooltip_opts=opts.TooltipOpts(
formatter=JsCode(
# 构造回调函数
"function (params) {return params.name + ' : ' + params.value[2];}"
) #params.name对应x轴的Faker.choose() : params.value[2]对应y轴Faker.choose()
),
# 视觉映射配置项
visualmap_opts=opts.VisualMapOpts(
#颜色映射
type_="color",
max_=150,
min_=20,
dimension=1 ## 组件映射维度
),
)
.render("不同城市价格对应房屋规格-多维散点图.html")
)
##效果图
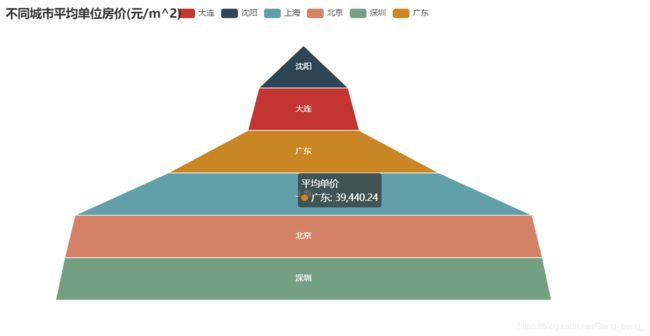
##5.漏斗图代码
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Funnel
try:
df = pd.read_csv(r'清洗后城市二手房数据.csv', encoding='utf-8')
except:
df = pd.read_csv(r'清洗后城市二手房数据.csv', encoding='gbk')
df.drop_duplicates(subset=None, keep='first', inplace=True)
city = []
unit_price = []
for index in df['城市']:
city.append(index)
for index in df['单价']:
unit_price.append(index)
last_city = list(set(city))
new_unit_price = [[] for i in range(len(last_city))]
last_unit_price = []
for i in range(len(unit_price)):
for j in range(len(last_city)):
if city[i] == last_city[j]:
new_unit_price[j].append(int(unit_price[i]))
for index in new_unit_price:
result = sum(index)/len(index)
last_unit_price.append('%.2f' % result)
c = (
Funnel()
.add(
"平均单价",
[list(z) for z in zip(last_city, last_unit_price)],
sort_="ascending",
label_opts=opts.LabelOpts(position="inside"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="不同城市平均单位房价(元/m^2)"))
.render("不同城市的平均单位房价-漏斗图.html")
)
##效果图
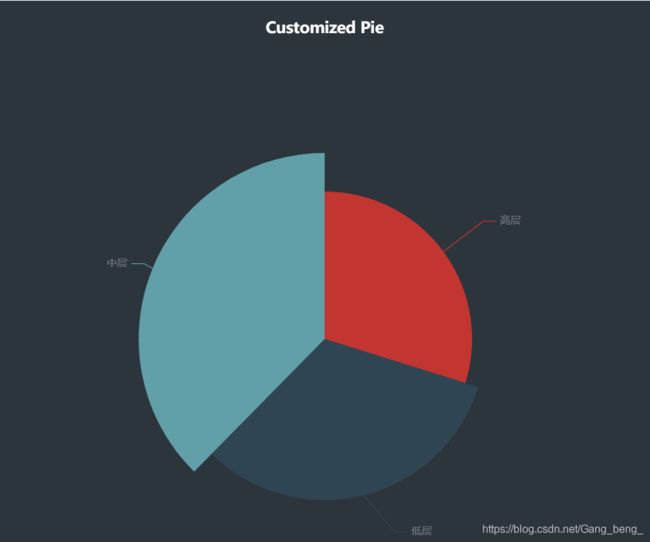
##6.饼状图代码
import pandas as pd
df=pd.read_csv(r'D:\清洗后城市二手房数据.csv',encoding='gbk')
df.drop(df[df['层段'].str.contains('层段')].index, inplace=True)
data_heigh=df['层段']
lst_height_value=data_heigh.value_counts().keys().tolist()
lst_counts=data_heigh.value_counts().tolist()
import pyecharts.options as opts
from pyecharts.charts import Pie
def get_pie():
x_data = lst_height_value
y_data = lst_counts
data_pair = [list(z) for z in zip(x_data, y_data)]
data_pair.sort(key=lambda x: x[1])
c=(
Pie(init_opts=opts.InitOpts(width="1600px", height="800px", bg_color="#2c343c"))
.add(
series_name="层段信息",
data_pair=data_pair,
rosetype="radius",
radius="55%",
center=["50%", "50%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="Customized Pie",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#fff"),
),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a}
{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"),
)
)
return c
if __name__ == '__main__':
get_pie().render('所有城市楼盘的层段分析-饼状图.html')
##效果图
数据集
链接:链接:https://pan.baidu.com/s/1qN00fxxo9wi1tF5wiqj4ZQ
提取码:uvy3