基于深度学习的手势识别系统(Python代码,UI界面版)
摘要:本文详细介绍基于深度学习的手势识别系统,在介绍手势识别算法原理的同时,给出了_P__y__t__h__o__n_的实现代码以及_P__y__Q__t_的UI界面。手势识别采用了基于MediaPipe的改进SSD算法,进行手掌检测后对手部关节坐标进行关键点定位;在系统界面中可以选择手势图片、视频进行检测识别,也可通过电脑连接的摄像头设备进行实时识别手势;可对图像中存在的多个手势进行姿势识别,可选择任意一个手势显示结果并标注,实时检测速度快、识别精度较高。博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。本博文目录如下:
文章目录
- 前言
- 1. 效果演示
- 2. 手势识别原理介绍
-
- 2.1 研究现状
- 2.2 Mediapipe深度学习框架
- 2.3 手势识别原理
- 2.4 代码实现演示
- 下载链接
- 结束语
?点击跳转至文末所有涉及的完整代码文件下载页?
代码介绍及演示视频链接:https://www.bilibili.com/video/BV12a411v7vr(正在更新中,欢迎关注博主B站视频)
前言
随着计算机性能的发展,人机交互越来越频繁。在工程应用方面,计算机通过对手势的分析理解,可以进一步开发出相应的远程操控系统,在疫情当下,可以更好的实现零接触操作。同时通过手势也可以进一步了解人的表情与情感,例如在警匪影片中,通过手势的微小变化,对罪犯的阐述进行分析判断,但这只是更深层次的系统设想。
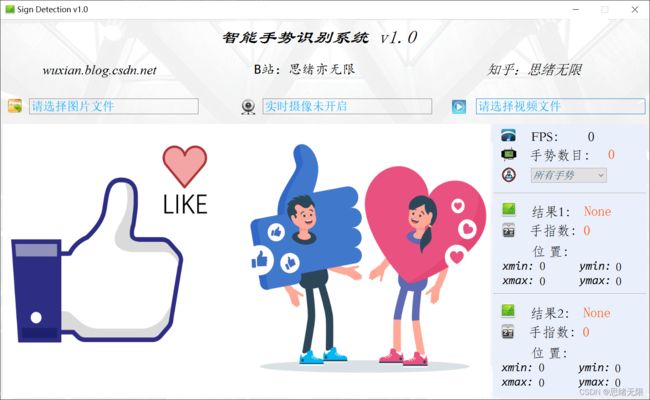
手势识别是个计划已久的项目,通过手势可以传达很多信息,从而实现很多好玩的事情,比如石头剪刀布、切水果等游戏。网上也有一些相关手势识别的博客或代码,不过很少有人对其进行详细介绍,为了便于演示和交付用户使用,我们将其开发成一个可以展示的完整软件,方便选择文件和实时检测。对此这里给出博主设计的界面,关注过的朋友可能清楚我的简约风,功能上也满足了图片、视频和摄像头的识别检测,希望大家可以喜欢,初始界面如下图:
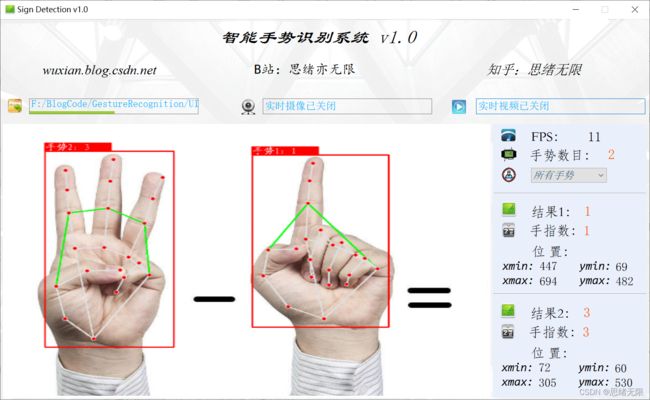
检测手势时的界面截图(点击图片可放大)如下图,可识别画面中存在的多个手势,也可开启摄像头或视频检测:
详细的功能演示效果参见博主的B站视频或下一节的动图演示,觉得不错的朋友敬请点赞、关注加收藏!系统UI界面的设计工作量较大,界面美化更需仔细雕琢,大家有任何建议或意见和可在下方评论交流。
- 效果演示
=======
手势识别系统借助深度学习算法,开发有选择图片识别、视频识别以及摄像画面识别,结果的可视化显示功能,这里给出几张动图供大家参考。
(一)选择手势图片识别
可点击手势识别系统中的图片选择按钮,即可弹出图片文件选择窗口,选中文件后自动显示识别结果;对于多个手势,可通过下拉框选择单独显示结果。本功能的界面展示如下图所示:
(二)手势视频识别效果展示
对于视频文件同样可以通过对应的视频选择按钮,选中可用的视频后自动利用算法对视频帧进行逐个识别,此时对算法和设备的实时性要求较高,但系统同样能够保持高的检测速度。效果如下图所示:
(三)摄像头检测效果展示
在真实场景中,我们往往利用设备摄像头获取实时画面,同时需要对画面中的手势进行识别,因此本文考虑到此项功能。如下图所示,点击摄像头按钮后系统进入准备状态,系统显示实时画面并开始检测画面中的手势,识别结果展示如下图:
- 手势识别原理介绍
===========
2.1 研究现状
目前现阶段手势识别的研究方向主要分为:基于穿戴设备的手势识别和基于视觉方法的手势识别。基于穿戴设备的手势识别主要是通过在手上佩戴含有大量传感器的手套获取大量的传感器数据,并对其数据进行分析。该种方法相对来虽然精度比较高,但是由于传感器成本较高很难在日常生活中得到实际应用,同时传感器手套会造成使用者的不便,影响进一步的情感分析,所以此方法更多的还是应用在一些特有的相对专业的仪器中。而本博客更多的还是将关注点放在基于视觉方法的手势研究中,在此特地以Mediapipe的框架为例,方便读者更好的复现和了解相关领域。
基于视觉方法的手势识别主要分为静态手势识别和动态手势识别两种。从文字了解上来说,动态手势识别肯定会难于静态手势识别,但静态手势是动态手势的一种特殊状态,我们可以通过对一帧一帧的静态手势识别来检测连续的动态视频,进一步分析前后帧的关系来完善手势系统。在本博客中向大家推荐一篇比较基础的中文期刊帮助大家简单了解:
由解迎刚老师发表在计算机工程与应用上的《基于视觉的动态手势识别研究综述》,论文从传感开始介绍,然后在介绍了相关检测算法,将手势识别分为了手势检测与分割、手势追踪、特征提取、手势分类与识别四个方面来介绍1。还有许多手势识别的英文综述可供大家参考,感兴趣的可以了解一下。
2.2 Mediapipe深度学习框架
Mediapipe深度学习框架的官网是https://google.github.io/mediapipe/,大家可以直接通过本博客访问其网站。MediaPipe 是一款由 Google Research 开发并开源的多媒体机器学习模型应用框架。首先在官网首页我们就可以直接看到MediaPipe能干的有:
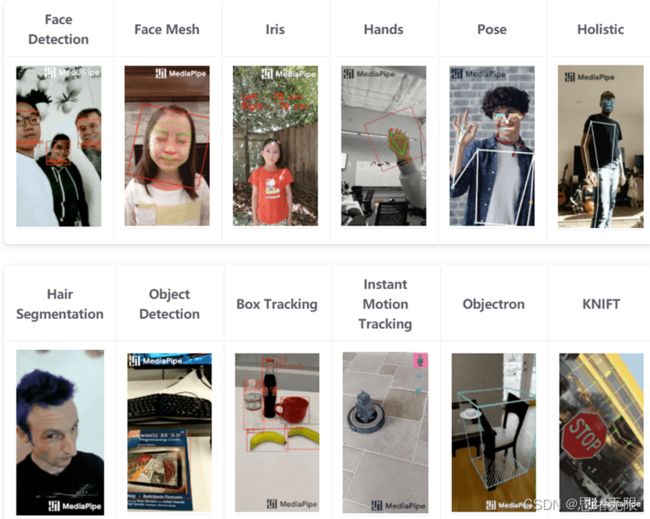
从左到右分别是人脸检测,人脸关键点检测,瞳孔检测、手势识别、身体姿态识别、全身的动作识别,更难的像发丝检测、简单的目标检测、追踪和实时物体控制,3D物体检测和标志标牌检测。然后MediaPipe支持的语言有如下:
![]()
2.3 手势识别原理
在官方的网址上可以知道,MediaPipe的手势识别算法主要分为两个部分,第一个部分是手掌识别模型,第二个是手部关键点标记模型。
MediaPipe在训练手掌模型中,使用的是单阶段目标检测算法SSD。同时利用三个操作对其进行了优化:1.NMS;2.encoder-decoder feature extractor;3.focal loss。NMS主要是用于抑制算法识别到了单个对象的多个重复框,得到置信度最高的检测框;encoder-decoder feature extractor主要用于更大的场景上下文感知,甚至是小对象(类似于retanet方法);focal loss是有RetinaNet上提取的,主要解决的是正负样本不平衡的问题,这对于开放环境下的目标检测是一个可以涨点的技巧。利用上述技术,MediaPie在手掌检测中达到了95.7%的平均精度。在没有使用2和3的情况下,得到的基线仅为86.22%。增长了9.48个点,说明模型是可以准确识别出手掌的。而至于为啥做手掌检测器而不是手部,主要是作者认为训练手部检测器比较复杂,可学习到的特征不明显,所以做的是手掌检测器。
MediaPipe通过对整个图像进行手掌检测后,使用手部关键点模型通过回归对被检测手部区域内的21个三维手部关节坐标进行精确的关键点定位,即直接进行坐标预测。标记点如图所示:

在此我们就简单的介绍了MediaPipe,接下来我们将通过代码来使用python调用MediaPipe实现手势识别。主要从三个方面来写这个脚本:第一个如果识别静态照片的手势;第二个如何识别视频流中的手势;第三个如果实时识别摄像头图像。
2.4 代码实现演示
实现代码前首先进行依赖安装,这里需要安装python-opencv和MediaPipe,可使用以下命令:
pip install opencv-python
pip install mediapipe
首先是引入库文件,这里主要用到的是一个mediapipe的sdk包和opencv的包。其他的numpy、time、math都是python和深度学习的基础包,不多介绍。
import mediapipe as mp
import cv2
import numpy as np
import time
import math
接下来我们将通过mediapipe的sdk来引入我们需要的手势识别的API,其代码如下:
mp_drawing = mp.solutions.drawing_utils #点和线的样式
mp_drawing_styles = mp.solutions.drawing_styles #点和线的风格
mp_hands = mp.solutions.hands # 手势识别的API
然后我们将预设一张手势识别的图片,可以填入相对路径和绝对路径。并预设一组数字,用于后期的手势分析。
IMAGE_List = ['jpgDet.jpg'] # 图片列表
gesture = [0,1,2,3,4,5] # 预设数字
以下就是手势识别的主程序,也就是主要核心内容。通过mediapipe的api我们可以分析出检测到的是左手还是右手,并获取相应手的21个关键点坐标。
with mp_hands.Hands(
static_image_mode = True, # False表示为图像检测模式
max_num_hands = 2, # 最大可检测到两只手掌
model_complexity = 0, # 可设为0或者1,主要跟模型复杂度有关
min_detection_confidence = 0.5, # 最大检测阈值
) as hands:
for idx ,file in enumerate(IMAGE_List):
image = cv2.flip(cv2.imread(file),1) # 读取图片
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB) # 将其标为RGB格式
t0 = time.time()
results =hands.process(image) # 使用API处理图像图像
'''
results.multi_handedness
包括label和score,label是字符串"Left"或"Right",score是置信度
results.multi_hand_landmarks
results.multi_hand_landmrks:被检测/跟踪的手的集合
其中每只手被表示为21个手部地标的列表,每个地标由x、y和z组成。
x和y分别由图像的宽度和高度归一化为[0.0,1.0]。Z表示地标深度
以手腕深度为原点,值越小,地标离相机越近。
z的大小与x的大小大致相同。
'''
t1 = time.time()
fps = 1 / (t1 - t0) # 实时帧率
# print('++++++++++++++fps',fps)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # 将图像变回BGR形式
dict_handnumber = {} # 创建一个字典。保存左右手的手势情况
if results.multi_handedness: # 判断是否检测到手掌
if len(results.multi_handedness) == 2: # 如果检测到两只手
for i in range(len(results.multi_handedness)):
label = results.multi_handedness[i].classification[0].label # 获得Label判断是哪几手
index = results.multi_handedness[i].classification[0].index # 获取左右手的索引号
hand_landmarks = results.multi_hand_landmarks[index] # 根据相应的索引号获取xyz值
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS, #用于指定地标如何在图中连接。
mp_drawing_styles.get_default_hand_landmarks_style(), # 如果设置为None.则不会在图上标出关键点
mp_drawing_styles.get_default_hand_connections_style()) # 关键点的连接风格
gesresult = ges(hand_landmarks) # 传入21个关键点集合,返回数字
dict_handnumber[label] = gesresult # 与对应的手进行保存为字典
else: # 如果仅检测到一只手
label = results.multi_handedness[0].classification[0].label # 获得Label判断是哪几手
hand_landmarks = results.multi_hand_landmarks[0]
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS, #用于指定地标如何在图中连接。
mp_drawing_styles.get_default_hand_landmarks_style(), # 如果设置为None.则不会在图上标出关键点
mp_drawing_styles.get_default_hand_connections_style()) # 关键点的连接风格
gesresult = ges(hand_landmarks) # 传入21个关键点集合,返回数字
dict_handnumber[label] = gesresult # 与对应的手进行保存为字典
if len(dict_handnumber) == 2: # 如果有两只手,则进入
# print(dict_handnumber)
leftnumber = dict_handnumber['Right']
rightnumber = dict_handnumber['Left']
'''
显示实时帧率,右手值,左手值,相加值
'''
s = 'FPS:{0}
Righthand Value:{1}
Lefthand Value:{2}
Add is:{3}'.format(int(fps),rightnumber,leftnumber,str(leftnumber+rightnumber)) # 图像上的文字内容
elif len(dict_handnumber) == 1 : # 如果仅有一只手则进入
labelvalue = list(dict_handnumber.keys())[0] # 判断检测到的是哪只手
if labelvalue == 'Right': # 左手,不知为何,模型总是将左右手搞反,则引入人工代码纠正
number = list(dict_handnumber.values())[0]
s = 'FPS:{0}
Righthand Value:{1}
Lefthand Value:0
Add is:{2}'.format(int(fps),number,number)
else: # 右手
number = list(dict_handnumber.values())[0]
s = 'FPS:{0}
Lefthand Value:{1}
Righthand Value:0
Add is:{2}'.format(int(fps),number,number)
else:# 如果没有检测到则只显示帧率
s = 'FPS:{0}
'.format(int(fps))
y0,dy = 50,25 # 文字放置初始坐标
# image = cv2.flip(image,1) # 反转图像
for i ,txt in enumerate(s.split('
')): # 根据
来竖向排列文字
y = y0 + i*dy
cv2.putText(image,txt,(50,y),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0),3)
cv2.imshow('MediaPipe Gesture Recognition',image) # 显示图像
cv2.imwrite('save/{0}.jpg'.format(idx),image)
if cv2.waitKey(5) & 0xFF == 27:
break
运行以上代码,通过读取一张手势图片,调用算法对画面中的手势进行识别,其中手指数目、画面帧率、手势结果等信息标记在图像中,如下图所示:

视频识别在代码结构上与图片识别是一致的,主要的原理就是通过cv2.VideoCapture()函数将视频读取成每一帧,并对每一帧图像进行检测,返回结果。以下我直接贴出源码,相关注释与图片识别相同。定义好cv2.VideoCapture函数,传入视频路径,并预设好手势列表。
cap = cv2.VideoCapture('GesDet.mp4') # 视频路径
gesture = [0,1,2,3,4,5] # 预设数字
使用while循环去遍历每一帧图像,并使用imshow来展示检测结果。注意这里的static_image_mode参数要设置为False。
with mp_hands.Hands(
static_image_mode = False, # False表示为视频流检测
max_num_hands = 2, # 最大可检测到两只手掌
model_complexity = 0, # 可设为0或者1,主要跟模型复杂度有关
min_detection_confidence = 0.5, # 最大检测阈值
min_tracking_confidence = 0.5 # 最小追踪阈值
) as hands:
while True: # 判断相机是否打开
success ,image = cap.read() # 返回两个值:一个表示状态,一个是图像矩阵
if image is None:
break
image.flags.writeable = False # 将图像矩阵修改为仅读模式
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
t0 = time.time()
results =hands.process(image) # 使用API处理图像图像
'''
results.multi_handedness
包括label和score,label是字符串"Left"或"Right",score是置信度
results.multi_hand_landmarks
results.multi_hand_landmrks:被检测/跟踪的手的集合
其中每只手被表示为21个手部地标的列表,每个地标由x、y和z组成。
x和y分别由图像的宽度和高度归一化为[0.0,1.0]。Z表示地标深度
以手腕深度为原点,值越小,地标离相机越近。
z的大小与x的大小大致相同。
'''
t1 = time.time()
fps = 1 / (t1 - t0) # 实时帧率
# print('++++++++++++++fps',fps)
image.flags.writeable = True # 将图像矩阵修改为读写模式
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # 将图像变回BGR形式
dict_handnumber = {} # 创建一个字典。保存左右手的手势情况
if results.multi_handedness: # 判断是否检测到手掌
if len(results.multi_handedness) == 2: # 如果检测到两只手
for i in range(len(results.multi_handedness)):
label = results.multi_handedness[i].classification[0].label # 获得Label判断是哪几手
index = results.multi_handedness[i].classification[0].index # 获取左右手的索引号
hand_landmarks = results.multi_hand_landmarks[index] # 根据相应的索引号获取xyz值
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS, #用于指定地标如何在图中连接。
mp_drawing_styles.get_default_hand_landmarks_style(), # 如果设置为None.则不会在图上标出关键点
mp_drawing_styles.get_default_hand_connections_style()) # 关键点的连接风格
gesresult = ges(hand_landmarks) # 传入21个关键点集合,返回数字
dict_handnumber[label] = gesresult # 与对应的手进行保存为字典
else: # 如果仅检测到一只手
label = results.multi_handedness[0].classification[0].label # 获得Label判断是哪几手
hand_landmarks = results.multi_hand_landmarks[0]
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS, #用于指定地标如何在图中连接。
mp_drawing_styles.get_default_hand_landmarks_style(), # 如果设置为None.则不会在图上标出关键点
mp_drawing_styles.get_default_hand_connections_style()) # 关键点的连接风格
gesresult = ges(hand_landmarks) # 传入21个关键点集合,返回数字
dict_handnumber[label] = gesresult # 与对应的手进行保存为字典
if len(dict_handnumber) == 2: # 如果有两只手,则进入
# print(dict_handnumber)
leftnumber = dict_handnumber['Right']
rightnumber = dict_handnumber['Left']
'''
显示实时帧率,右手值,左手值,相加值
'''
s = 'FPS:{0}
Righthand Value:{1}
Lefthand Value:{2}
Add is:{3}'.format(int(fps),rightnumber,leftnumber,str(leftnumber+rightnumber)) # 图像上的文字内容
elif len(dict_handnumber) == 1 : # 如果仅有一只手则进入
labelvalue = list(dict_handnumber.keys())[0] # 判断检测到的是哪只手
if labelvalue == 'Left': # 左手,不知为何,模型总是将左右手搞反,则引入人工代码纠正
number = list(dict_handnumber.values())[0]
s = 'FPS:{0}
Righthand Value:{1}
Lefthand Value:0
Add is:{2}'.format(int(fps),number,number)
else: # 右手
number = list(dict_handnumber.values())[0]
s = 'FPS:{0}
Lefthand Value:{1}
Righthand Value:0
Add is:{2}'.format(int(fps),number,number)
else:# 如果没有检测到则只显示帧率
s = 'FPS:{0}
'.format(int(fps))
y0,dy = 50,25 # 文字放置初始坐标
image = cv2.flip(image,1) # 反转图像
for i ,txt in enumerate(s.split('
')): # 根据
来竖向排列文字
y = y0 + i*dy
cv2.putText(image,txt,(50,y),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0),3)
cv2.imshow('MediaPipe Gesture Recognition',image) # 显示图像
# cv2.imwrite('save/{0}.jpg'.format(t1),image)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
相机实时检测相比于前面两种,主要是cv2.VideoCapture()中,我们传入的不在是文件路径,而是一个一个的数字,以电脑自带摄像头为例,我们传入参数0。如果有多个相机也可传入相应的相机代号。
cap = cv2.VideoCapture(0) # 0代表电脑自带摄像头
读取视频或摄像头画面进行识别的过程,与前面读取图片文件相似,通过循环读取画面帧逐个识别手势,并标记在画面中,运行结果如下图所示:
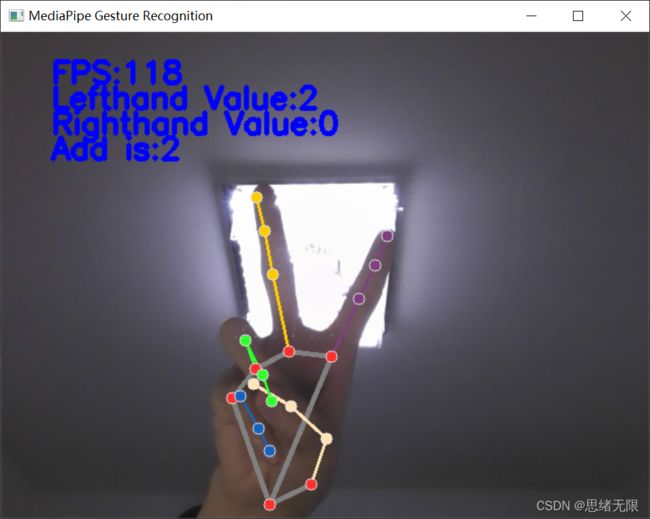
在使用了MediaPipe的手势识别后,我发现难得不是对于手势关键点的检测,MediaPipe的手势识别,在CPU上基本可以达到实时的标准,更难的应该是对手势的判断,对关键点的理解,这里我也观摩了很多其他博主的文章,对于不同方法得到的准确度也不一样,这值得我们更多的去思考。对于手势更准的判断,我们可以将其应用在很多的工程实例中。
打开QtDesigner软件,拖动以下控件至主窗口中,调整界面样式和控件放置,性别识别系统的界面设计如下图所示:
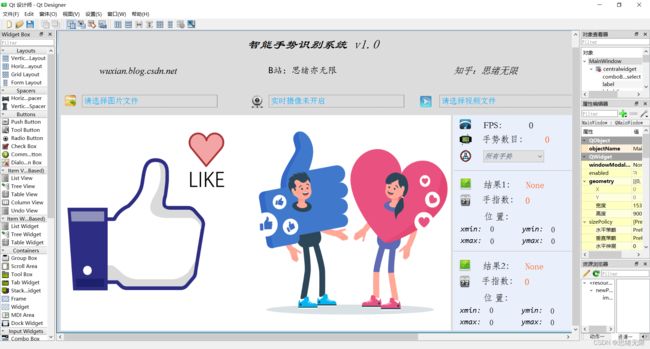
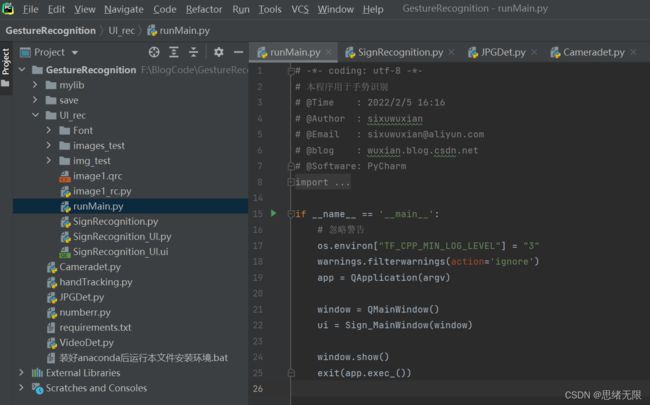
控件界面部分设计好,接下来利用PyUIC工具将.ui文件转化为.py代码文件,通过调用界面部分的代码同时加入对应的逻辑处理代码。博主对其中的UI功能进行了详细测试,最终开发出一版流畅得到清新界面,就是博文演示部分的展示,完整的UI界面、测试图片视频、代码文件,以及Python离线依赖包(方便安装运行,也可自行配置环境),均已打包上传,感兴趣的朋友可以通过下载链接获取。
下载链接
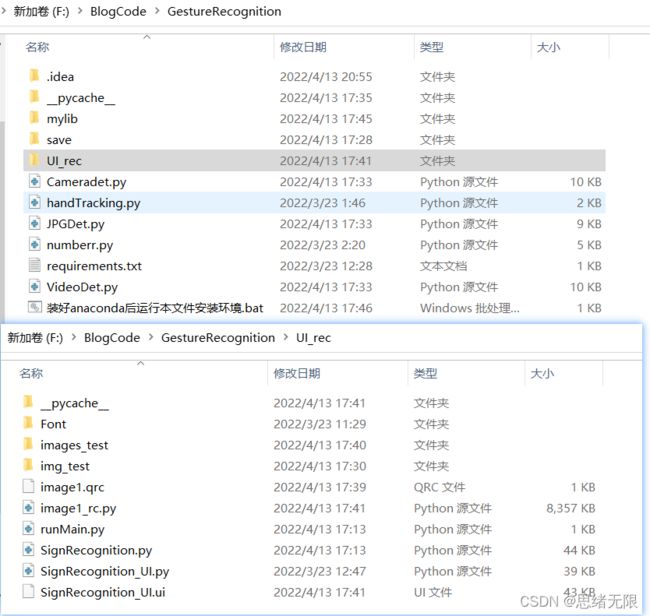
若您想获得博文中涉及的实现完整全部程序文件(包括测试图片、视频,_py, UI_文件等,如下图),这里已打包上传至博主的面包多平台和_CSDN_下载资源。本资源已上传至面包多网站和_CSDN_下载资源频道,可以点击以下链接获取,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
在文件夹下的资源显示如下,其中包含了Python的离线依赖包,读者可在正确安装Anaconda和Pycharm软件后,点击bat文件进行安装,详细演示也可见本人B站视频。
注意:本资源已经过调试通过,下载后可通过_Pycharm_运行;运行界面的主程序为_runMain.py_,测试图片可运行_JPGDet.py_,测试视频文件可运行_VideoDet.py_,测试摄像头识别可运行_Cameradet.py_,为确保程序顺利运行,请配置Python依赖包的版本如下:
Python版本:3.8,请勿使用其他版本,详见requirements.txt文件;
absl-py==1.0.0
attrs==21.4.0
certifi==2021.10.8
cvzone==1.5.6
cycler==0.11.0
fonttools==4.29.1
kiwisolver==1.3.2
matplotlib==3.5.1
mediapipe==0.8.9.1
numpy==1.22.3
opencv-contrib-python==4.5.5.62
opencv-python==4.5.5.64
packaging==21.3
Pillow==9.0.1
protobuf==3.19.4
pyparsing==3.0.7
PyQt5==5.15.6
PyQt5-Qt5==5.15.2
PyQt5-sip==12.9.1
python-dateutil==2.8.2
six==1.16.0
wincertstore==0.2
完整资源下载链接1:https://mianbaoduo.com/o/bread/mbd-YpmXlZ9s
完整资源下载链接2:博主在CSDN下载频道的完整资源下载页
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
参考资料:
- https://blog.csdn.net/weixin_45930948/article/details/115444916
- https://cloud.tencent.com/developer/article/1492209
- 王如斌,窦全礼,张淇,周诚.基于MediaPipe的手势识别用于挖掘机遥操作控制[J/OL].土木建筑工程信息技术:1-8[2022-03-31].
- 解迎刚,王全. 基于视觉的动态手势识别研究综述[J]. 计算机工程与应用, 2021, 57(22):10. ??