论文阅读之Virtual-to-real Deep Reinforcement Learning
目录
- 论文意义
- 具体思路
-
- 强化学习算法的选择
- 测试有效性
- 网络架构
- 反馈设计
- 实验结果分析
-
- 仿真训练
- 实验测试。
-
- 实验对照
- 虚拟环境测试
- 真实环境测试
- 实验分析
- 实验结论
- 不足之处(个人意见)
论文意义
规划机器人的运动,从当前位置移动到目标位置。
传统方法:基于激光测绘来获得一个全局障碍图(“Simultaneous localization and
mapping: part i),然后对机器人的行为进行规划。
但是问题主要有二:建立全局障碍图比较耗时;对用于测绘的设备精度要求较高。
由于可见光与wifi定位技术的发展,移动机器人可以获得一个实时的相对位置。但在没有全局障碍图的情况下,仅仅有实时位置仍然很难做出全局规划路线。本文提出了,用异步深度强化学习算法来训练机器人在没有障碍图的情况下,仅仅使用十维的稀疏特征值与实时位置就能输出机器人的线速度与角速度,能够从当前位置移动到目标位置。
具体思路
强化学习算法的选择
选用了ADDPG(异步DDPG算法)
因为DQN,NAF,DDPG都利用了经验回放原则,这一类离线学习算法的主要问题是采样效率低,难以大规模采样。
而异步多线程的A3C算法需要多个并行仿真环境,这使其不适用于一些特定的仿真引擎(V-REP)。
另外,DQN不能运用于连续控制,NAF虽然可以运用于连续控制但其参数比DDPG多,所以最终选择了DDPG算法并扩展成异步。
测试有效性
利用开源环境gym中的小例子——Pendulum-v0,测试DDPG与ADDPG采集样本的效率。结果如下:

网络架构

首先是14维的输入特征向量,其中有10维是激光探测器的输入信息,另外两维是上一时刻的线速度与角速度,最后两维是机器人的实时位置。对于Actor网络而言,输入经过三个全连接层后,分别用sigmoid函数与tanh函数激活,因为线速度保证非负,最后融合成二维输出动作action。
反馈设计
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3pW7sWZK-1599651499250)(C:\Users\么么哒\AppData\Roaming\Typora\typora-user-images\1591532665581.png)]](http://img.e-com-net.com/image/info8/b6041a8c37864b919a5ea004a9d2b3b5.jpg)
即如果这一步导致回合结束,那么reward不进行衰减,使用原始reward。
实验结果分析
仿真训练
环境模拟器使用的是V-REP。两个环境模拟图如下所示:

这两个环境都是模拟了10*10 平方的室内环境,白色的代表障碍物,黑点选用的是斑龟机器人,环境2相对来说障碍物更加紧凑,学习起来更为困难。在单一的Geforce GTX 1080 GPU上用Adam优化器训练近20h的结果如下:
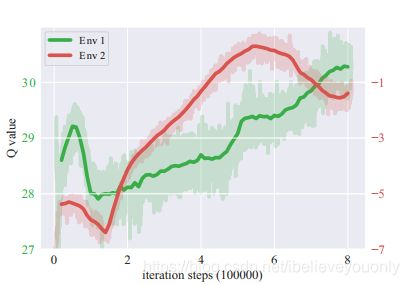
环境1与2使用不同的y轴,y轴代表的是每个批次q的均值。由于环境2更容易碰撞,所以其q值要小于环境1。
环境1训练出来的称为model1,同理,环境2的称为model。
实验测试。
使用基于Turtlebot的Kobuki机器人, Intel Core i7-4700 CPU ,SICK TiM551(激光测距) 进行虚拟环境与真实环境的测试。

实验对照
一共有四个模型可以对比:其一为可以建立全局障碍图的机器人1;其二为与ADDPG模型类似,也只从10个特定方向进行激光采样,随后被扩充为810维的拥有局部障碍图的机器人2;其三为环境1训练出来的机器人3;其四为环境2训练出来的机器人4。
虚拟环境测试
实验目标:机器人能依次通过1-10一共10个目标位置,且为了便于评价,机器人会依次经过五次。实验结果如下:

除了机器人2,其他机器人都能顺利完成测试任务。机器人1拥有全局障碍图,只是用做对比,机器人3与4训练环境与本次测试环境不一致,但仍然能够出色完成任务,表现了极强的适应力,相比之下,机器人2虽然也是同样是10维采样,但由于却乏强化学习算法的支撑,没有能够自主完成测试。为了更好的评价模型,还使用了其他的性能指标。

上述三张图依次代表了控制频率(每分钟命令输出次数)、移动时间、移动距离。由此可见,机器人3与4的控制频率很高,查询路径很快。
真实环境测试
由于机器人3路径规划不如机器人4平滑,故真实环境测试仅仅只对比了机器人2与机器人4。测试目标为机器人在复杂的室内环境能够依次通过0-9的目标位置。结果如下:
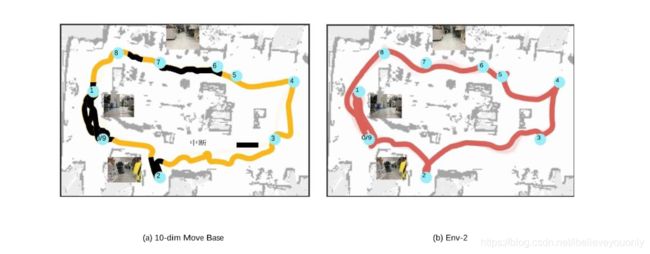
结果还是机器人4能够出色完成测试任务。
实验分析
在仿真测试与真实环境测试中,经过强化学习训练的机器人能够在未知环境中通过测试任务,适应能力比较强,但是训练后的机器人还是一定程度上收到原始训练环境的影响,对比机器人3、4,4会对障碍更加敏感。
此外,强化学习训练的机器人预测路径比较曲折,因为其没有预测能力也没有存储历史信息。
(时序信息(attention,LSTM))
实验结论
本文的目的不是为了取代基于地图的导航机器人,因为在大型复杂户外环境中,基于地图的机器人总是能给出一条可靠的路线,而强化学习模型很难做到。但是在一些相对比较固定的室内场所,这种强化学习模型还是有可取之处的。
(无地图导航,陌生险恶环境)
不足之处(个人意见)
- 测试时只使用了一种定位方法(激光测距,SICK TiM551 )
- 真实环境中并未测试环境1训练的模型的结果,所训练的机器人是否真的可以应用于真实通用环境还是只是为了满足测试所修改过的伪真实环境
- 训练一个符合要求的机器人耗时多少?文中提到的20h并未说模型可以收敛。