不得不看!降低Transformer复杂度的方法
每天给你送来NLP技术干货!
作者 | Chilia
整理 | NewBeeNLP
首先来看一下原始Transformer的复杂度
self-attention复杂度
记:序列长度为n,一个位置的embedding大小为d。例如(32,512,768)的序列,n=512,d=768.
首先,得到的QKV都是大小为 的。
相似度计算 : 与 运算,得到 矩阵,复杂度为
softmax计算: 对每行做softmax复杂度为 ,则n行的复杂度为
乘上V加权: 与运算,得到矩阵,复杂度为
多头selfattention复杂度
Attention操作复杂度:首先经过"切头",把输出变成 长度,就是 和 的运算,由于h为常数,复杂度为
之后的softmax和乘V加权同上。
之后,还需要把这些头拼接起来,经过一层线性映射之后输出。concat操作拼起来形成nxd的矩阵,然后经过输出线性映射,保证输出也是的,所以是与计算,复杂度为
故最后的复杂度为:
1. Sparse Transformer
论文:Generating Long Sequences with Sparse Transformers
地址:https://arxiv.org/pdf/1904.10509.pdf
Sparse Attention是为了解决Transformer模型随着长度n的增加,Attention部分所占用的内存和计算呈平方增加的问题。原始Transformer的复杂度为 , 而sparse transformer试图把此复杂度降低为 .这样,就可以处理上千长度的输入,层数可以达到上百层。
1.1 Intuition
Transformer的Decoder部分是一个 自回归(AR) 模型。对于图像生成任务,可以把图像的像素点按照从上到下从左到右的方式当成一个序列,然后在序列上去做自回归。
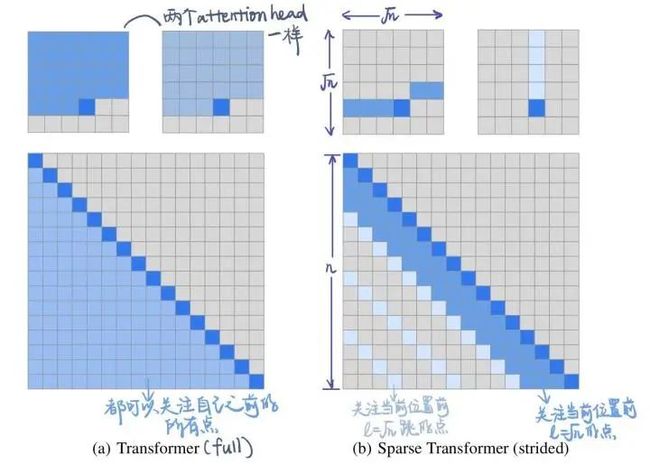
论文中首先构造了一个128层的full-attention transformer网络,并在Cifar10图像生成问题上进行了训练。如下图所示,底部的黑色部分表示尚未生成到的部分,白色凸显的部分则是当前步骤注意力权重高的地方。

(a)中是transformer中比较低层layer的注意力,可以看到,低层次的时候主要关注的还是 局部区域 的部分。
(b)在第19层和20层,Attention学习到了横向和纵向的规律。
(c)还有可能学习到和数据本身相关的attention。比如下图,第二列第二张学习到了鸟的边缘。
(d) 64-128层的注意力是高度稀疏的,只有极少的像素点有较高的注意力。
无论如何,注意力权重高的地方只占一小部分,这就为 稀疏注意力 提供了数据上的支持。作为解决注意力平方问题的早期论文,本文从图像生成的问题上揭示了attention的原罪,那就是其实不需要那么 密集 的注意力。
1.2 Factorized Self-attention
Sparse Transformer就是把full self-attention 分解 成若干个小的、复杂度低的self-attention。这个过程叫做factorization。
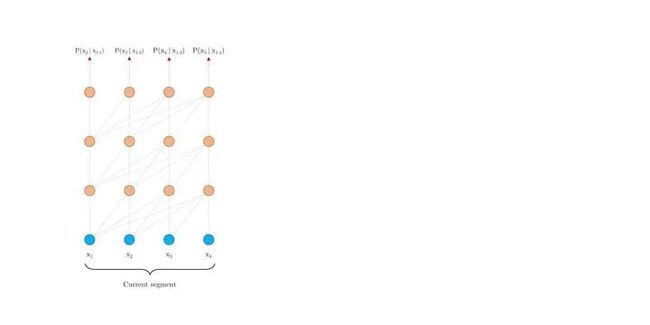
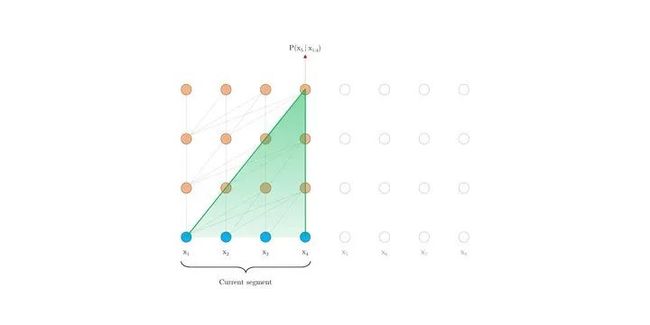
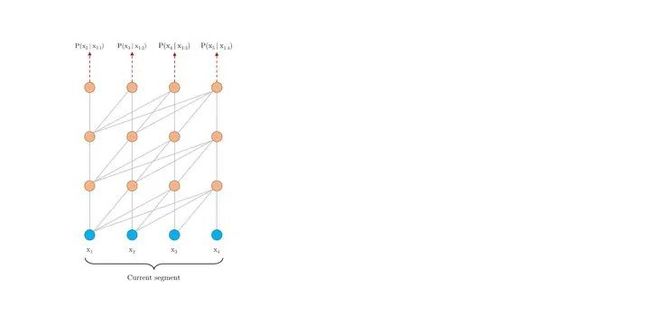
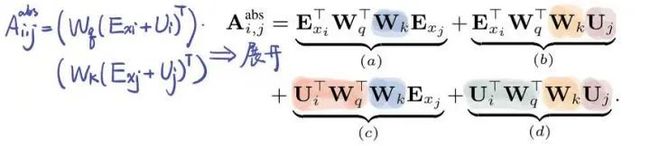
定义集合 , 这个集合中的每个元素还是集合,表示第i位input可以关注的位置。对于full-attention, 显然就是 {j:j 每个位置的attention现在就变成了下图公式。其实没多大变化,只不过以前可以关注自己之前的所有位置,现在只能关注到一些特定的位置而已。 对于factorized self-attention,使用p个sparse注意力头,每个sparse注意力头有着不同的关注列表,第m个注意力头的关注列表记作 为了保证sparse注意力头的高效性( efficiency ), 我们必须要保证 是 复杂度的。 同时,为了保证sparse注意力头是有效( valid )的,我们需要保证每个位置都可以经过一些路径attend到 之前所有位置 (毕竟,这样才属于"factorize" full -attention)。同时这个路径长度不超过p+1,这样保证所有原本在全注意力上能够传递的信号在稀疏注意力的框架下仍然可以有效传递。 当p = 2时,即两个注意力头的时候,文章给出了如下两种可以的sparse attention方法,能够满足上文所述的efficiency和valid条件。 (1)strided attention 一个注意力头只能关注当前位置前 个位置 另一个注意力头只能关注当前位置前面隔 "跳"的位置 这样相当于关注当前行、当前列的信息,就如之前看的图像生成例子中的(b)一样。所以,这种注意力机制比较适用于图像。 (2)fixed attention Ai(1) = {j: floor(j/l) = floor(i/l)} Ai(2) = {j: j mod l ∈ {t, t+1, ..., l}},其中t=l-c且c是超参数。 一般情况下,l取值为{128, 256}, c取值为{8, 16, 32}。这种模式非常适合于NLP问题,因为一般一句话的最后一个hidden state(下图浅蓝色)包含了整句话最多的意思。另外一个注意力头也可以关注到当前位置的前面每个token。 稀疏注意力的组合 一个直接的方法是在不同的层使用不同稀疏机制。这样每个层的不同机制”交织(interleave)“在一起。 另一种方式则是在每个层使用 组合 的稀疏注意力,组合的方法则是把经过不同稀疏注意力机制的输出concat起来,就像普通的多头一样。 深度残差Transformer 深层次的Transformer训练起来十分困难,因为使用残差的方式会比较好。除了我们熟悉的transformer层内的layernorm之外,还增加了 层间 的残差连接,可以处理上百层的层。 论文:Longformer: The Long-Document Transformer 地址:https://arxiv.org/pdf/2004.05150.pdf BERT模型能处理的最大序列长度是512. 这是因为普通transformer的时间复杂度是随着序列长度n而平方增长的。如果我们想要处理更长的序列该怎么办呢? 最简单的方法就是直接截断成512长度的。这点普遍用于文本分类问题。 截成多个长度为512的序列段(这些序列段可以互相overlapping),每个都输入给Bert获得输出,然后将多段的输出拼接起来。 两个阶段去解决问题,就像搜索里面的召回 - 排序一样。一般用于Question-Answer问题,第一个阶段去选择相关文档,第二个阶段去找到对应的answer。 无论哪种方式,毫无疑问都会带来损失:截断会带来损失,两阶段会带来cascading error。如果能直接处理长序列就好了。 Longformer将局部attention和全局attention结合起来,局部attention用来捕捉局部信息,一般用于 底层 (就像上文sparse attention中看到的,底层attention主要关注局部信息,是十分稀疏的)。全局attention则捕捉全局信息,用于 高层 ,目的在于综合所有的信息,从而得到一个好的representation。 滑动窗口的大小为w,那么每个位置只attend前后w/2个位置。将模型多层叠加起来之后, 高层 的每个位置都可以关注到input的每个位置(就像卷积的感受野一样,这里可以有全局感受野)。一个 层的transformer,最上层的感受野是 的。 这样,每一层的计算复杂度就是而不是的了。 另外,每一层的w其实可以不同,鉴于越高层需要的全局信息越多,可以在层级较高的时候把w调大。来达到模型效率(efficiency)和模型表达能力(representation capacity)的平衡。 引入dilated window的目的是为了再避免增加计算量的情况下继续增大感受野,类似空洞卷积。一个window有着大小为d的gap,那么最高层的感受野就是 的。 对于多头注意力,可以让有些头不用dilation,专注于关注 局部 信息;有些头用dilation,关注 更远 的信息。另外,底层不适合用dilated sliding window, 因为底层需要去学习局部的信息;高层可以适当的使用少量的dilated window,以降低参数量。 究竟要选择哪种attention方式,其实是和任务有关的。对于MLM任务,或许只关注局部信息就足够了,所以使用滑窗是可以的;但是对于分类任务,BERT模型把整句话的信息都集中在了[CLS]中,所以 [CLS]应该能够关注到所有位置 。对于QA,我们将question和document拼接起来送入transformer中,由于每个位置都需要去比较看是否贴近 question ,所以理应所有位置都能关注到question的每个token,因此question的每个token需要具有全局注意力。 这里的”全局注意力“指的是,某个位置上的token可以关注所有其他位置,所有其他位置也都可以关注这个token。具体要选择那个位置赋予全局注意力,是和任务的性质有关的。 其实transformer-XL并不是解决transformer复杂度问题的,而是用来解决长文本的long-term dependency问题。但是transformer-XL在推理阶段可以达到比vanilla transformer快1800倍的加速,所以在这里也一并介绍了。 由于BERT等transformer模型的最长输入长度只有512,在处理长文本的时候只能像我们上文说的那样,截成若干个512长度的片段(segment),依次输入到BERT中训练,如下图所示。这样导致的问题就是,数据最多只能关注到自己所在片段的那512个token,段和段之间的信息丢失了。 在测试阶段,以文本生成这种 自回归任务 为例,需要依次取时间片为L = 512 的分段,然后将整个片段提供给模型后预测一个结果。在下个时间片时再将这个分段向 右移一个单位 ,这个新的片段也将通过整个网络的计算后得到一个值。Transformer的这个特性导致其预测阶段的 计算量是非常大的 。 Transformer-XL的核心包括两部分:片段循环(segment-level recurrence)和相对位置编码(relative positional encoding) 在训练阶段,上一个segment的隐藏状态会被 缓存下来 ,然后在计算当前段的时候再重复使用上一个segment的隐层状态。因为上个片段的特征在当前片段进行了 重复使用 ,这也就赋予了Transformer-XL建模更长期的依赖的能力。 长度为的连续两个segment表示为 和 。的隐层节点的状态表示为,其中是隐层节点的维度。的隐层节点的状态的计算过程为: 其中表示stop-gradient,表示这一部分并不参与BP的计算, 表示两个隐层节点在长度维度进行拼接。 不要被这个复杂的公式吓到!其实它想表达的意思很简单,就是每次在算一个segment的self-attention时,用当前这个segment的每个token当成Query向量,然后当前这个segment+上一个segment的每个token当成Key和Value向量,Query去关注Key和Value。这样,就把两个原本割裂的segment用attention给”粘合“了起来。记segment长度为N,那么一个L层的网络,最上面的层可以关注到的”感受野“就是O(N*L). 训练阶段如下: 除了能够关注到更远的位置以外,另一个好处 推理速度 的提升。Transformer的自回归架构每次只能前进一个time step,而Transfomer-XL的推理过程直接复用上一个片段的表示而不是从头计算,每次可以前进一个 segment长度 。其实这是一个空间换时间的方法。在原先transformer的方法中,推理时每次都只移动一个time step,因此只需要记录上一个segment的最后一个hidden state。现在则需要记录上一个segment的所有hidden state。推理阶段如下: Transformer的位置编码是以segment为单位的,表示为,第个元素表示的是在这个segment中第个元素的位置编码,表示的是能编码的最大长度,即segment长度。对于不同的segment来说,它们的位置编码是完全相同的,我们完全没法确认它属于哪个segment或者它在分段之前的输入数据中的相对位置。 为了解决这个问题,可以采用相对位置编码的方式。其思想是:一个位置在i的query向量去关注位置j的key向量,我们并不需要知道i和j是什么,真正重要的是i-j这个 相对距离 。所以,使用一个相对位置偏差的embedding矩阵 来进行位置偏差的编码。之后,我们需要把这个描绘相对位置的embedding融入到传统transformer的attention计算中去。 那么,如何做到这样的融合呢? 位置i的向量 作为query,要去和位置j的向量 计算注意力权重( 作为key),使用 绝对位置 的计算公式如下。其中,E表示embedding,U代表绝对位置编码。 将相对位置编码融入attention计算之后: 可以发现做了如下的几处改进: 1) 被拆分成 和 ,也就是说输入序列和位置编码不再共享权值。(蓝色和浅黄色部分) 2)绝对位置编码换成了相对位置编码 (棕色)。 3)引入了两个新的可学习的参数 和 来替换Transformer中的query向量 。表明 对于所有的query位置对应的query位置向量是相同的。因为我们已经把相对位置编码融入了key端,那么query端就不再需要位置编码了。(红色和绿色部分) 最近文章 EMNLP 2022 和 COLING 2022,投哪个会议比较好? 一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA 阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果 投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。 方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。 记得备注呦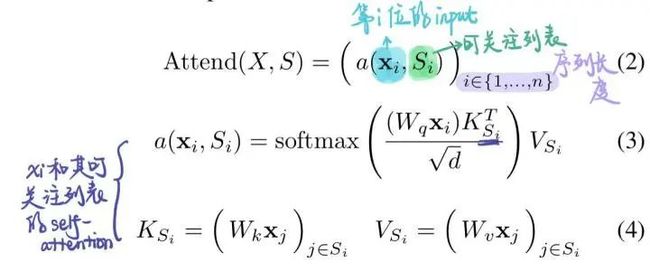
两种可能的sparse attention方法

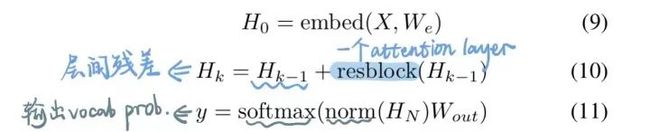

2. Longformer
2.1 问题提出
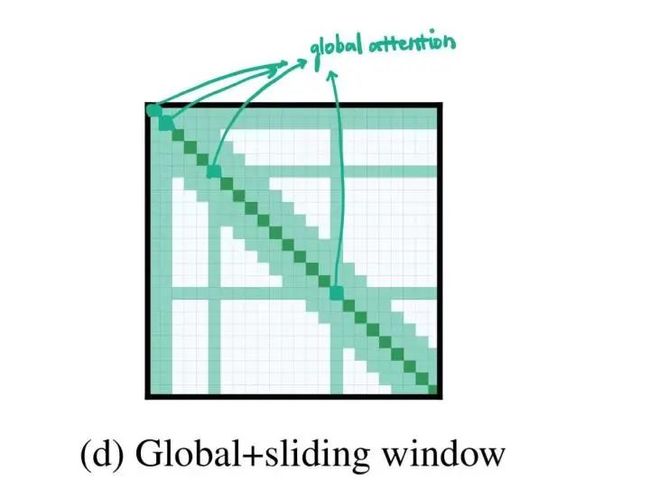
2.2 局部和全局attention的结合
Sliding window
Dilated Sliding Window

2.3 Global Attention
3. Transformer-XL
3.1 问题的提出
3.2 Transformer XL
3.2.1 Segment-Level Recurrence with State Reuse


3.2.2 相对位置编码
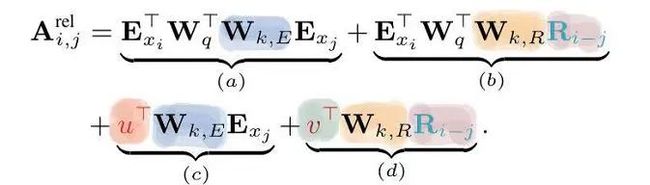
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】

整理不易,还望给个在看!