NCL:Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning,代码解读

一、前言
1、背景

(1)用户-项目交互数据通常是稀疏或嘈杂的,并且它可能无法学习可靠的表示,因为基于图的方法可能更容易受到数据稀疏性的影响
(2)现有的基于 GNN 的 CF 方法依赖于显式交互链接来学习节点表示,而不能显式利用高阶关系或约束(例如,用户或项目相似性)来丰富图信息,尽管最近的几项研究利用对比学习来缓解交互数据的稀疏性,但它们通过随机抽样节点或损坏子图来构建对比对,缺乏构建针对推荐任务更有意义的对比学习任务的思考。
2、做出的贡献
提出NCL方法,主要从两方面考虑对比关系,
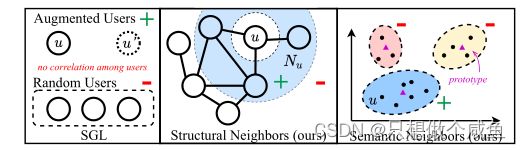
(1)结构邻居 : 通过高阶路径在结构上连接的节点
考虑图结构上的用户-用户邻居,商品-商品邻居的对比关系
(2)语义邻居 : 语义上相似的邻居,在图上可能不直接相邻。
从节点表征出发,聚类后,节点与聚类中心构成对比关系
二、模型构建

1、图协同过滤
这里其实就是lightGCN的传播机制,简单过一下:
GCN的消息传递
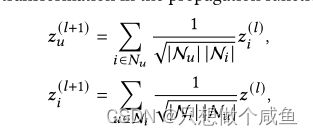
将每层的输出组合起来,形成结点的最终表示

然后就是预测,和BPR的损失函数
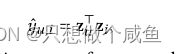
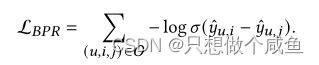
这一部分是基础,如果不熟悉的话可以回看往期的lightGCN介绍
2、结构邻居的对比学习
提出将每个用户(或项目)与他/她的结构邻居进行对比,这些邻居的表示通过GNN的层传播进行聚合。
交互图 G 是一个二分图,基于 GNN 的模型在图上的偶数次信息传播自然地聚合了同构结构邻居的信息,就可以从GNN模型的偶数层(如2,4,6)输出中得到同类邻居的表示,我们将用户自身的嵌入和偶数层GNN的相应输出的嵌入视为正对。基于InfoNCE[20],我们提出了结构对比学习目标来最小化它们之间的距离:

其中 ![]() 为GNN中层的归一化输出,为偶数。是softmax的温度超参数,同理。item的一样
为GNN中层的归一化输出,为偶数。是softmax的温度超参数,同理。item的一样
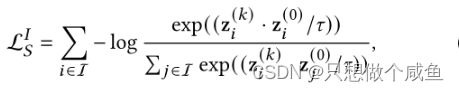
白话:当前结点与偶数层k的输出是正对,其他结点与偶数层k就是负对
完整的结构对比目标函数是上述两个损失的加权之和:
![]()
其中是一个超参数,以平衡结构对比学习中两个损失的权重。
3、语义邻居的对比学习
语义邻居是指图上无法到达但具有相似特征(商品节点)或偏好(用户节点)的节点。这部分通过聚类,将相似embedding对应的节点划分的相同的簇,用簇中心代表这个簇,这个中心称为原型。由于该过程无法进行端到端优化,使用 EM 算法学习提出的原型对比目标。聚类中GNN模型的目标是最大化下式(用户相关),简单理解就是让用户embedding划分到某个簇,其中θ为可学习参数,R为交互矩阵,c是用户u的潜在原型。同理也可以得到商品相关的目标式。

提出的原型对比学习目标基于InfoNCE来最小化以下函数:
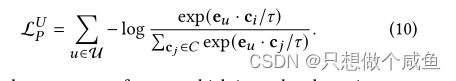
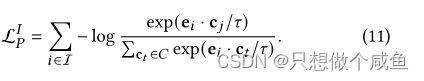
白话:当前结点与某一簇原型是正对,与其它簇原型就是负对
最终的原型对比目标是用户目标和项目目标的加权和:

4、优化器
将提出的两个对比学习损失作为补充,并利用多任务学习策略来联合训练传统的排序损失和提出的对比损失,公式如下,
![]()
实验效果:

三、pytoch代码实现
1、GNN传播部分
本质就是lightGCN
def forward(self):
ego_embeddings = torch.cat([self.embedding_dict['user_emb'], self.embedding_dict['item_emb']], 0)
all_embeddings = [ego_embeddings]
for k in range(self.layers):
ego_embeddings = torch.sparse.mm(self.sparse_norm_adj, ego_embeddings)
all_embeddings += [ego_embeddings]
lgcn_all_embeddings = torch.stack(all_embeddings, dim=1)
lgcn_all_embeddings = torch.mean(lgcn_all_embeddings, dim=1)
user_all_embeddings = lgcn_all_embeddings[:self.data.user_num]
item_all_embeddings = lgcn_all_embeddings[self.data.user_num:]
return user_all_embeddings, item_all_embeddings, all_embeddings输出user_embedding、item_embedding、all_embedding (这个是存储每层聚合的嵌入)
所对应的是BPR_loss,如下:
rec_loss = bpr_loss(user_emb, pos_item_emb, neg_item_emb)2、结构邻居的对比学习
initial_emb = emb_list[0] #初始embedding
context_emb = emb_list[self.hyper_layers*2] #对比偶数层
ssl_loss = self.ssl_layer_loss(context_emb,initial_emb,user_idx,pos_idx) #loss看一下loss
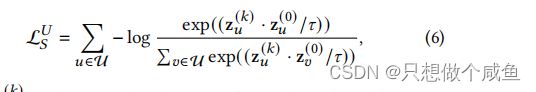
def ssl_layer_loss(self, context_emb, initial_emb, user, item):
context_user_emb_all, context_item_emb_all = torch.split(context_emb, [self.data.user_num, self.data.item_num]) #拆分偶数层的嵌入 U+I
initial_user_emb_all, initial_item_emb_all = torch.split(initial_emb, [self.data.user_num, self.data.item_num]) #拆分初始的嵌入 U+I
context_user_emb = context_user_emb_all[user] #获取当前批次的嵌入
initial_user_emb = initial_user_emb_all[user]
# 对输入数据进行标准化使得输入数据满足正态分布
norm_user_emb1 = F.normalize(context_user_emb) #当前偶数层批次
norm_user_emb2 = F.normalize(initial_user_emb) #当前初始化批次
norm_all_user_emb = F.normalize(initial_user_emb_all)# 全部用户
pos_score_user = torch.mul(norm_user_emb1, norm_user_emb2).sum(dim=1) # Zk * z0
ttl_score_user = torch.matmul(norm_user_emb1, norm_all_user_emb.transpose(0, 1))
pos_score_user = torch.exp(pos_score_user / self.ssl_temp) #分子
ttl_score_user = torch.exp(ttl_score_user / self.ssl_temp).sum(dim=1)#分母
ssl_loss_user = -torch.log(pos_score_user / ttl_score_user).sum()
#item同理
context_item_emb = context_item_emb_all[item]
initial_item_emb = initial_item_emb_all[item]
norm_item_emb1 = F.normalize(context_item_emb)
norm_item_emb2 = F.normalize(initial_item_emb)
norm_all_item_emb = F.normalize(initial_item_emb_all)
pos_score_item = torch.mul(norm_item_emb1, norm_item_emb2).sum(dim=1)
ttl_score_item = torch.matmul(norm_item_emb1, norm_all_item_emb.transpose(0, 1))
pos_score_item = torch.exp(pos_score_item / self.ssl_temp)
ttl_score_item = torch.exp(ttl_score_item / self.ssl_temp).sum(dim=1)
ssl_loss_item = -torch.log(pos_score_item / ttl_score_item).sum()
ssl_loss = self.ssl_reg * (ssl_loss_user + self.alpha * ssl_loss_item)
return ssl_loss3、语义邻居的对比学习
proto_loss = self.ProtoNCE_loss(initial_emb, user_idx, pos_idx)
def ProtoNCE_loss(self, initial_emb, user_idx, item_idx):
user_emb, item_emb = torch.split(initial_emb, [self.data.user_num, self.data.item_num])#拆分初始的嵌入 U+I
user2cluster = self.user_2cluster[user_idx]
user2centroids = self.user_centroids[user2cluster]
proto_nce_loss_user = InfoNCE(user_emb[user_idx],user2centroids,self.ssl_temp) * self.batch_size
item2cluster = self.item_2cluster[item_idx]
item2centroids = self.item_centroids[item2cluster]
proto_nce_loss_item = InfoNCE(item_emb[item_idx],item2centroids,self.ssl_temp) * self.batch_size
proto_nce_loss = self.proto_reg * (proto_nce_loss_user + proto_nce_loss_item)
return proto_nce_loss总结:
在这项工作中,提出了一种新的对比学习范式,称为邻域丰富的对比学习(NCL),以明确地将潜在的节点相关性捕获到对比学习中,用于图形协同过滤。分别从图结构和语义空间两个方面考虑用户(或项目)的邻居。
首先,为了利用交互图上的结构邻居,开发了一个新的结构对比目标,该目标可以与基于GNN的协同过滤方法相结合。
其次,为了利用语义邻域,通过对嵌入内容进行聚类,并将语义邻域合并到原型对比目标中,从而获得用户/项目的原型。对五个公共数据集的大量实验证明了所提出的NCL的有效性。
作为未来的工作,将把我们的框架扩展到其他推荐任务,例如顺序推荐。此外,我们还将考虑制定一个更统一的方案,以利用和利用不同种类的邻居。