Linux网络编程 - 基于标准 I/O函数的套接字(socket)编程
引言
我们前面的博文中采用的都是默认数据通信手段 read & write 函数以及Linux系统调用的 I/O 函数 recv & send 等。其实我们还可以使用 学习C语言时掌握的标准 I/O 函数进行数据收发操作。在网络数据交换时使用标准 I/O 函数也是可以的。
一 标准 I/O 函数的优点
本文将介绍利用标准 I/O 函数在网络编程中进行收发数据的使用方法。常见的标准 I/O 函数有:fopen、fclose、feof、fgetc、fputc、fgets、fputs、fread、fwrite 等。这些标准 I/O 函数也都是 C 语言标准库中用于文件操作的函数。
【标准I/O函数 博文链接】
【C语言进阶】文件数据操作详解
C语言重点篇:近万字总结文件操作函数
1.1 标准 I/O 函数的两个优点
- 标准 I/O 函数的两大优点
- 标准 I/O 函数具有良好的移植性(Portability)。
- 标准 I/O 函数有缓冲,可以利用缓冲提高性能。
不仅标准 I/O 函数,所有标准函数具有良好的移植性。因为,为了支持所有操作系统(编译器),这些函数都是按照 ANSI C 标准定义的。当然,这并不局限于网络编程,而是适用于所有编程领域。
接下来讨论标准 I/O 函数的第二个优点。使用标准 I/O 函数时会得到额外的缓冲支持。这种表达方式也许会带来一些混乱,因为之前讲过,创建套接字时操作系统会准备 I/O 缓冲。造成更大混乱之前,先说明这两种缓冲之间的关系。创建套接字时,操作系统将生成用于 I/O 的缓冲。此缓冲在执行 TCP 协议时发挥着非常重要的作用。此时若使用准备 I/O 标准,将得到额外的另一缓冲的支持,如下图 1 所示。
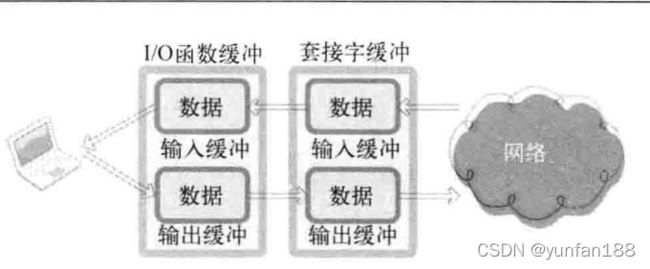 图1 缓冲的关系
图1 缓冲的关系
从图 1 中可以看出,使用标准 I/O 函数传输数据时,经过2个缓冲。例如,通过 fputs 函数传输字符串 “Hello” 时,首先将数据传递到标准 I/O 函数的缓冲。然后数据将移动到套接字输出(发送)缓冲,最后将字符串发送到对方主机。
既然知道了两个缓冲的关系,接下来再说明各自的用途。设置缓冲的主要目的是为了提高性能,但套接字中缓冲主要是为了实现 TCP 协议而设立的。例如,TCP 传输中丢失传输数据时将再次传递,而再次发送数据则意味着在某地保存了数据。存在什么地方呢?存在套接字的输出(发送)缓冲中。与之相反,使用标准 I/O 函数缓冲的主要目的是为了提高性能。
“使用缓冲可以大大提高性能吗?”
实际上,缓冲并非在所有情况下都能带来卓越的性能。但需要传输的数据越多,有无缓冲带来的性能差异越大。可以通过如下两种角度说明性能的提高。
- 传输的数据量
- 数据向输出(发送)缓冲移动的次数
比较一个字节的数据发送10次(10个数据包)的情况和累计10个字节发送一次的情况。发送数据时使用的数据包中含有头结构信息。头结构信息与数据大小无关,是按照一定的格式填入的。即使假设该头结构信息占用40个字节(实际更大),需要传递的数据量也存在较大差别。
- 1个字节 10次:(40+1) × 10 = 410 字节
- 10个字节 1次:(40+10)× 1 = 50 字节
另外,为了发送数据,向套接字输出(发送)缓冲移动数据也会消耗不少时间,这是因为标准 I/O 缓冲是在用户进程空间,而套接字缓冲是在内核空间,数据从用户进程缓冲空间移动到内核缓冲空间,这其实是一个数据复制过程。
1.2 标准 I/O 函数和系统 I/O 函数之间的性能对比
接下来分别利用标准 I/O 函数和系统 I/O 函数编写文件复制程序,以此来检验缓冲提供性能的程度。
编程实例:首先是利用系统 I/O 函数复制文件的示例。
- syscpy.c
#include
#include
#define BUF_SIZE 3
int main(int argc, char *argv[])
{
int fd1, fd2; //文件描述符
int len;
char buf[BUF_SIZE];
fd1 = open("news.txt", O_RDONLY);
fd2 = open("cpy.txt", O_WRONLY|O_CREAT|O_TRUNC);
while((len = read(fd1, buf, sizeof(buf))) > 0)
write(fd2, buf, len);
close(fd1);
close(fd2);
return 0;
} 上述示例是基于 read & write 函数的文件复制程序。复制对象仅限于文本文件,并且是300M字节以上的文件!因为只用这样才能明显感觉到性能差异。文件名为 news.txt,大家可以适当修改文件内容并测试。
编程实例:采用标准 I/O 函数复制文件示例。
- stdcpy.c
#include
#define BUF_SIZE 3
int main(int argc, char *argv[])
{
FILE *fp1; //文件指针
FILE *fp2; //文件指针
char buf[BUF_SIZE] = {0};
fp1 = fopen("news.txt", "r");
fp2 = fopen("news.txt", "w");
while(fgets(buf, BUF_SIZE, fp1) != NULL)
fputs(buf, fp2);
fclose(fp1);
fclose(fp2);
return 0;
} 上述示例利用示例 syscpy.c 中复制的文件再次进行复制。该示例利用 fgets & fputs 函数复制文件,因此是一种基于缓冲的复制。最后你会发现,采用标准 I/O 函数复制300M文件所需的时间远低于采用系统 I/O 函数的方式。其实现在300M字节并非大数据,即便如此,在单纯的文件复制操作中也会有如此大的差异。可以想象,在实际网络环境中将产生更大的区别。
1.3 标准 I/O 函数的几个缺点
- 标准 I/O 函数的几个缺点
- 不容易进行双向通信。
- 有时可能需要频繁调用 fflush 函数。
- 需要以 FILE 结构体指针的形式返回文件描述符。
假设我们已掌握了 C 语言中的绝大部分文件 I/O 操作相关知识。打开文件时,如果希望同时进行读写操作,则应以 r+、w+、a+ 模式打开。但因为缓冲的缘故,每次切换读写工作状态时应调用 fflush 函数。这也会影响基于缓冲的性能提高。而且,为了使用标准 I/O 函数,需要 FILE 结构体指针(以下简称 “FILE指针”)。而创建套接字时默认返回文件描述符,因此需要将文件描述符转化为 FILE 指针。
【关于 fflush 函数的用法】
fflush()函数总结
二 使用标准 I/O 函数
如上所述,创建套接字时返回文件描述符,而为了使用标准 I/O 函数,只能将其转换为 FILE 结构体指针。先介绍其转换方法。
2.1 利用 fdopen 函数转换文件描述符为 FILE 结构体指针
可以通过创建 fdopen 函数将创建套接字时返回的文件描述符转换为标准 I/O 函数中使用的 FILE 结构体指针。
- fdopen() — 将文件描述符转换为 FILE 结构体指针。
#include
FILE *fdopen(int fildes, const char *mode);
/*参数说明
fildes: 需要转换的文件描述符。
mode: 将要创建的 FILE 结构体的模式(mode)信息。
*/
//返回值: 成功时返回转换后的 FILE 结构体指针,失败时返回 NULL 【文件打开模式(mode)】
- r:打开文本文件,用于读。流被定位于文件的开始。
- r+:打开文本文件,用于读写。流被定位于文件的开始。
- w:将文件长度截断为零,或者创建文本文件,用于写。流被定位于文件的开始。
- w+:打开文件,用于读写。如果文件不存在就创建它,否则将截断它。流被定位于文件的开始。
- a:打开文件,用于追加 (在文件尾写)。如果文件不存在就创建它。流被定位于文件的末尾。
- a+:打开文件,用于追加 (在文件尾写)。如果文件不存在就创建它。读文件的初始位置是文件的开始,但是输出总是被追加到文件的末尾。
上面的参数 mode 的所有字符串也可以包含字符 'b' 作为最后一个字符,或者插入到上面提到的任何双字符的字符串的两个字符中间。例如,"rb"、"rb+"、"wb"、"wb+"、"ab"、"ab+"。这里的字符 'b',表示的是二进制文件,以区别于文本文件。
编程实例:下面通过简单示例给出 fdopen 函数的使用方法。
- fdopen.c
#include
#include
int main(int argc, char *argv[])
{
FILE *fp;
int fd = open("data.txt", O_WRONLY|O_CREAT|O_TRUNC); //创建文件并返回文件描述符
if(fd == -1)
{
fputs("file open error!", stderr);
return -1;
}
fp = fdopen(fd, "w");
fputs("Network C programming\n", fp);
fclose(fp);
return 0;
} - 代码说明
- 第7行:使用 open 系统调用函数创建文件并返回文件描述符。
- 第14行:调用 fdopen 函数将文件描述符转换为 FILE 指针。此时向第二个参数传递了 "w",因此返回写模式的 FILE 指针。
- 第15行:利用第14行获取到的 FILE 指针调用标准输出函数 fputs,向 data.txt 文件写入字符串内容。
- 第16行:利用 FILE 指针关闭文件。此时完全关闭,因此无需再调用 close 函数关闭文件描述符。而且调用 fclose 函数后,文件描述符也变成毫无意义的整数。
- 运行结果
[wxm@centos7 stdio]$ gcc fdopen.c -o fdopen
[wxm@centos7 stdio]$ ./fdopen
[wxm@centos7 stdio]$ ls
data.txt fdopen fdopen.c
[wxm@centos7 stdio]$ cat data.txt
Network C programming
此示例中需要注意的是,文件描述符转换为 FILE 指针,并可以通过该指针调用标准 I/O 函数。
2.2 利用 fileno 函数将 FILE 指针转换为文件描述符
接下来介绍与 fdopen 函数提供相反功能的函数 fileno,该函数在有些情况下非常有用。
- fileno() — 将 FILE 结构体指针转换为文件描述符。
#include
int fileno(FILE *stream);
/*参数说明
stream: 将FILE指针转换为文件描述符。
*/
//返回值: 成功时返回转换后的文件描述符,失败时返回-1。 此函数的功能也很简单,向该函数传递 FILE 指针参数时返回相应的文件描述符。
编程实例:下面示例给出 fileno 函数的使用方法。
- fileno.c
#include
#include
int main(int argc, char *argv[])
{
FILE *fp;
int fd = open("data.txt", O_WRONLY|O_CREAT|O_TRUNC);
if(fd == -1)
{
fputs("file open error!", stderr);
return -1;
}
printf("First file descripor: %d\n", fd);
fp = fdopen(fd, "w");
fputs("TCP/IP SOCKET PROGRAMMING\n", fp);
printf("Second file descripor: %d\n", fileno(fp));
fclose(fp);
return 0;
} - 代码说明
- 第14行:输出第7行返回的文件描述符整数值。
- 第15、17行:第15行调用 fdopen 函数将文件描述符转换为 FILE 指针,第17行调用 fileno 函数再次转换回文件描述符,并输出该整数值。
- 运行结果
[wxm@centos7 stdio]$ gcc fileno.c -o fileno
[wxm@centos7 stdio]$ ./fileno
First file descripor: 3
Second file descripor: 3
[wxm@centos7 stdio]$ cat data.txt
TCP/IP SOCKET PROGRAMMING
从上面的运行结果可知,第14行和第17行输出的文件描述符值相同,证明 fileno 函数正确转换了文件描述符。
三 运用标准 I/O 函数实现回声服务器端/客户端
上面介绍了标准 I/O 函数的优缺点,同时介绍了文件描述符 与 FILE 指针互相转换的方法。下面将其运用于套接字编程。虽然是套接字操作,但并没有需要另外说明的内容,只需简单应用这些标准 I/O 函数。
接下来将之前的回声服务器端和客户单程序修改为基于标准 I/O 函数的数据交换形式,更改对象如下。
- 回声服务器端:echo_server.c ——> echo_stdserv.c
- 回声客户端:echo_client.c ——> echo_stdclient.c
- 获取回声服务器端和客户端程序代码,请参见下面博文链接(第3节内容)
Linux网络编程 - 基于TCP的服务器端/客户端(1)
无论是服务器端还是客户端,更改方式并无差异。只需调用 fdopen 函数并使用标准 I/O 函数替换掉系统 I/O 函数 read/write。
3.1 回声服务器端:echo_stdserv.c
#include
#include
#include
#include
#include
#include
#define BUF_SIZE 1024
void error_handling(char *message);
int main(int argc, char *argv[])
{
int serv_sock, clnt_sock;
char message[BUF_SIZE];
int str_len, i;
struct sockaddr_in serv_adr; //服务器端地址信息变量
struct sockaddr_in clnt_adr; //客户端地址信息变量
socklen_t clnt_adr_sz;
FILE *readfp, *writefp; //声明读写模式FILE指针变量
if(argc!=2) {
printf("Usage: %s \n", argv[0]);
exit(1);
}
serv_sock=socket(PF_INET, SOCK_STREAM, 0);
if(serv_sock==-1)
error_handling("socket() error");
memset(&serv_adr, 0, sizeof(serv_adr));
serv_adr.sin_family=AF_INET;
serv_adr.sin_addr.s_addr=htonl(INADDR_ANY);
serv_adr.sin_port=htons(atoi(argv[1]));
if(bind(serv_sock, (struct sockaddr*)&serv_adr, sizeof(serv_adr))==-1)
error_handling("bind() error");
if(listen(serv_sock, 5)==-1)
error_handling("listen() error");
clnt_adr_sz=sizeof(clnt_adr);
for(i=0; i<5; i++) //为处理5个客户端连接而添加的循环语句,共调用5次accept函数,依次向5个客户端提供服务
{
clnt_sock=accept(serv_sock, (struct sockaddr*)&clnt_adr, &clnt_adr_sz); //受理客户端连接请求,并返回新的套接字文件描述符
if(clnt_sock==-1)
error_handling("accept() error");
else
printf("Connected client %d\n", i+1);
//@override
readfp = fdopen(clnt_sock, "r"); //将套接字文件描述符转换为以只读模式的FILE指针
writefp = fdopen(clnt_sock, "w"); //将套接字文件描述符转换为以只写模式的FILE指针
while(!feof(readfp))
{
fgets(message, BUF_SIZE, readfp); //接收客户端发来的消息
fputs(message, writefp); //回送客户端发来的消息
fflush(writefp); //刷新输出缓冲区,注意并不是刷新套接字的输出(发送)缓冲
//而是刷新标准I/O函数的输出缓冲
}
fclose(readfp);
fclose(writefp);
/*while((str_len=read(clnt_sock, message, BUF_SIZE))!=0) //接收客户端发来的消息
write(clnt_sock, message, str_len); //回送客户端发来的消息
close(clnt_sock); //关闭与客户端进行数据交互的套接字
*/
}
close(serv_sock); //关闭服务器端的监听套接字
return 0;
}
void error_handling(char *message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
} - 程序说明
重点关注 @override 部分的代码,原来的代码注释掉了。
上述示例中需要注意的是第56行的while循环语句。调用基于字符串的 fgets、fputs函数提供服务,并在第60行调用 fflush 函数。标准 I/O 函数为了提高性能,内部提供了额外的缓冲。因此,若不调用 fflush 函数则无法保证立即将数据移动到套接字发送缓冲区,然后从套接字发送缓冲传输给客户端。
3.2 回声客户端:echo_stdclient.c
#include
#include
#include
#include
#include
#include
#define BUF_SIZE 1024
void error_handling(char *message);
int main(int argc, char *argv[])
{
int sock;
char message[BUF_SIZE];
int str_len;
struct sockaddr_in serv_adr;
FILE *readfp, *writefp; //声明读写模式FILE指针变量
if(argc!=3) {
printf("Usage: %s \n", argv[0]);
exit(1);
}
sock=socket(PF_INET, SOCK_STREAM, 0); //创建客户端TCP套接字
if(sock==-1)
error_handling("socket() error");
memset(&serv_adr, 0, sizeof(serv_adr));
serv_adr.sin_family=AF_INET;
serv_adr.sin_addr.s_addr=inet_addr(argv[1]);
serv_adr.sin_port=htons(atoi(argv[2]));
if(connect(sock, (struct sockaddr*)&serv_adr, sizeof(serv_adr))==-1) //调用connect函数,向服务器端发起连接请求
error_handling("connect() error!");
else
puts("Connected...........");
//@override
readfp = fdopen(sock, "r"); //将套接字文件描述符转换为以只读模式的FILE指针
writefp = fdopen(sock, "w"); //将套接字文件描述符转换为以只写模式的FILE指针
while(1)
{
fputs("Input message(Q to quit): ", stdout); //标准输出
fgets(message, BUF_SIZE, stdin); //标准输入
if(!strcmp(message,"q\n") || !strcmp(message,"Q\n")) //如果输入字符q或Q,则退出循环体
break;
//@override
fputs(message, writefp); //向服务器端发送字符串消息
fflush(writefp); //刷新输出缓冲区,注意并不是刷新套接字的输出(发送)缓冲
//而是刷新标准I/O函数的输出缓冲
fgets(message, BUF_SIZE, readfp); //接收来自服务器端的消息
/*
write(sock, message, strlen(message)); //向服务器端发送字符串消息
str_len=read(sock, message, BUF_SIZE-1); //接收来自服务器端的消息
message[str_len]= '\0'; //在字符数组尾部添加字符串结束符'\0'
*/
printf("Message from server: %s", message); //输出接收到的消息字符串
}
//close(sock); //关闭客户端套接字
//@override
fclose(readfp);
fclose(writefp);
return 0;
}
void error_handling(char *message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
} - 程序说明
重点关注 @override 部分的代码,原来的代码注释掉了。
我们可以注意到,在 echo_client.c 程序中需要将接收到的数据先转换为字符串,然后才能输出(数据的尾部插入字符串结束符 '\0' ),但在 echo_stdclient.c 程序中并没有这一过程。这是因为,使用标准 I/O 函数后可以按字符串单位进行数据交换。同样的第52行中调用 fflush 函数,刷新输出流缓冲,是为了立即将输出缓冲的数据移到套接字发送缓冲,然后从套接字发送缓冲传输给服务器端。
- 运行结果
- 回声服务器端:echo_stdserv.c
[wxm@centos7 echo_tcp]$ gcc echo_stdserv.c -o stdserv
[wxm@centos7 echo_tcp]$ ./stdserv 9190
Connected client 1
- 回声客户端:echo_stdclient.c
[wxm@centos7 echo_tcp]$ gcc echo_stdclient.c -o stdclient
[wxm@centos7 echo_tcp]$ ./stdclient 127.0.0.1 9190
Connected...........
Input message(Q to quit): Hello~
Message from server: Hello~
Input message(Q to quit): Good morning~
Message from server: Good morning~
Input message(Q to quit): Good bye~
Message from server: Good bye~
Input message(Q to quit): Q
上述示例的运行结果与之前的 echo_server.c 和 echo_client.c 程序的运行结果并无差异。以上就是标准 I/O 函数在套接字(socket)编程中的使用方法,因为需要编写额外的代码,所以并不像想象中那么常用。但某些情况下也是非常有用的,而且可以再次复习标准 I/O 函数,对大家还是非常有益的。
四 习题
1、请说明标准I/O函数的2个优点。它为何拥有这2个优点?
- 优点1:标准 I/O 函数具有良好的移植性(Portability)。因为这些标准 I/O 函数都是按照 ANSI C标准定义的,支持所有的操作系统(编译器)。
- 优点2:标准 I/O 函数有缓冲,可以利用缓冲提高性能。因为当待传输的数据比较多时,有缓冲的 I/O 可以暂存一部分数据,当数据在传输过程中丢失需要重传时,可以立即从缓冲重新移动数据到套接字的发送缓冲中,提高了传输效率。
2、利用标准 I/O 函数传输数据时,下面的想法是错误的:
“调用 fputs 函数传输数据时,调用后应立即开始发送!”
为何说上述想法是错误的?为了达到这种效果应添加哪些处理过程?
答:因为通过标准输出函数传输的数据并不是直接传递到套接字发送缓冲中的,而是先保存在标准输出函数的缓冲中,然后再调用 fflush,将标准输出函数缓冲中的数据移动到套接字发送缓冲中,这其实是一个复制过程,然后再由套接字发送缓冲将数据传输给通信对端。
因此,即使调用 fputs 函数,也不能立即发送数据。如果想保障数据传输的时效性,必须经过 fflush 函数的调用过程。
参考
《TCP-IP网络编程(尹圣雨)》第15章 - 套接字和标准 I/O
《TCP/IP网络编程》课后练习答案第二部分15~18章 尹圣雨