selenium 实战模拟登陆
首先下载selenium模块,pip install selenium,下载一个浏览器驱动程序(我这里使用谷歌)。
#需要用到的所有包
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from time import sleep
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
from lxml import etree首先实现登陆去哪儿网,这部分没什么难点,需要注意的是一个滑块验证
我们可以定位小滑块和滑动轨道,通过location和size方法获取他们位置和宽度高度,用法如下
huakuai = browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div[1]/div[3]/div/div[5]/div/div/div[3]/div[3]')
huakuai_left_right = huakuai.location
huakuai_height_widtht = huakuai.size
# print(huakuai_left_right,huakuai_height_widtht)
guidao = browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div[1]/div[3]/div/div[5]/div/div/div[3]/div[2]')
guidao_left_rihgt = guidao.location
guigao_height_widtht = guidao.size
# print(guidao_left_rihgt,guigao_height_widtht)
length = guigao_height_widtht['width'] - huakuai_height_widtht['width']以字典形式返回

#需要滑行的长度就可以算出来(实际长度需要加上左右边框各1)
length=guigao_height_widtht['width']-huakuai_height_widtht['width']from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from time import sleep
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
from lxml import etree
aa = input('出发地址:')
bb = input('目的地:')
cc = input('出发日期(注意格式例如 2022-03-28):')
# 无头浏览器
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument('--disable-gpu')
s = Service("chromedriver.exe")
browser = webdriver.Chrome(service=s, options=option)
# browser = webdriver.Chrome(service=s)
# 规避检测
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
browser.get('https://user.qunar.com/passport/login.jsp?ret=https%3A%2F%2Fwww.qunar.com%2F%3Fex_track%3Dauto_4e0d874a')
browser.maximize_window()
sleep(1)
browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div[1]/div[1]/div[2]').click()
sleep(1)
username = browser.find_element(By.ID, 'username')
password = browser.find_element(By.ID, 'password')
sleep(1)
username.send_keys('账号')
sleep(1)
password.send_keys('密码')
sleep(1)
browser.find_element(By.XPATH, '//*[@id="agreement"]').click()
sleep(1)
browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div[1]/div[3]/div/div[3]').click()
sleep(1)
huakuai = browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div[1]/div[3]/div/div[5]/div/div/div[3]/div[3]')
huakuai_left_right = huakuai.location
huakuai_height_widtht = huakuai.size
# print(huakuai_left_right,huakuai_height_widtht)
guidao = browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div[1]/div[3]/div/div[5]/div/div/div[3]/div[2]')
guidao_left_rihgt = guidao.location
guigao_height_widtht = guidao.size
# print(guidao_left_rihgt,guigao_height_widtht)
length = guigao_height_widtht['width'] - huakuai_height_widtht['width']
# 动作连实例化,破解滑块验证码
action = ActionChains(browser)
# 点击长按指定的标签
action.click_and_hold(huakuai)
action.move_by_offset(length + 2, 0).perform()
# perform()立即执行动作连操作
# 释放动作链
action.release().perform()
sleep(1)以上就是实现模拟登陆的代码,接下来实现爬取火车票数据,大致步骤如图

需要注意的是,我们在传递出发地址之后,需要模拟点击搜索的第一个地址(目的地同理)
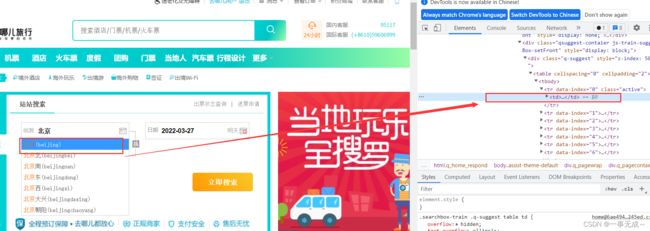
日期默认是后一天的日期,我们则需要删除默认日期在传递我们想要的日期,这里要用selenium中的键盘事件,导入Keys类,下面是常用的键盘事件
Keys.BACK_SPACE # 回退键
(BackSpace)Keys.TAB# 制表键
(Tab)Keys.ENTER# 回车键
(Enter)Keys.SHIFT# 大小写转换键
(Shift)Keys.CONTROL# Control键
(Ctrl)Keys.ALT# ALT键
(Alt)Keys.ESCAPE # 返回键
(Esc)Keys.SPACE # 空格键
(Space)Keys.PAGE_UP# 翻页键上
(Page Up)Keys.PAGE_DOWN # 翻页键下
(Page Down)Keys.END# 行尾键
(End)Keys.HOME# 行首键(Home)具体步骤实现:
browser.find_element(By.XPATH, '//*[@id="js_nva_cgy"]/li[3]/a').click()
sleep(2)
browser.find_element(By.XPATH, '//*[@id="js-con"]/div[1]/form/div[1]/div[1]/div[1]/div/div/input').send_keys(aa)
sleep(1)
browser.find_element(By.XPATH,
'//*[@id="js-con"]/div[1]/form/div[1]/div[1]/div[1]/div/div/div[5]/div/table/tbody/tr[1]').click()
sleep(1)
browser.find_element(By.XPATH, '//*[@id="js-con"]/div[1]/form/div[1]/div[1]/div[2]/div/div/input').send_keys(bb)
sleep(1)
browser.find_element(By.XPATH,
'//*[@id="js-con"]/div[1]/form/div[1]/div[1]/div[2]/div/div/div[5]/div/table/tbody/tr[1]').click()
sleep(1)
ff = browser.find_element(By.XPATH, '//*[@id="js-con"]/div[1]/form/div[1]/div[2]/div/div/div[1]/input')
for i in range(10):
ff.send_keys(Keys.BACK_SPACE)
ff.send_keys(cc)
ff.click()
sleep(1)
browser.find_element(By.XPATH, '//*[@id="js-con"]/div[1]/form/div[2]/div/span/button').click()
sleep(1)div/span/button').click()sleep(1)至此得到搜索结果 如图

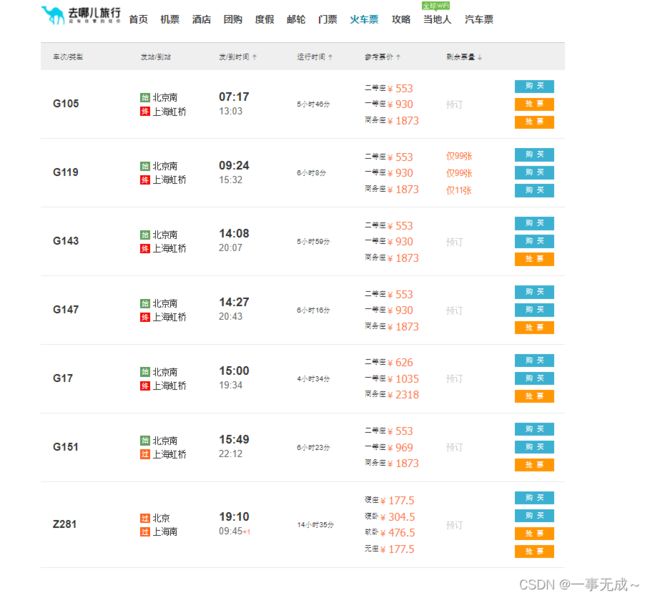
然后对此页面爬取相关信息,我只做了车次,出发时间和运行时间的抓取,其他数据原理也一样
具体分析:
我们可以发现每辆车的相关信息都在一个li标签内,首先获得所有的li标签,然后使用循环遍历对每一个li标签,同时进行存储与打印输出。


append()方法用在列表中,Python文件的write()方法将str写入文件,列表不行
page = browser.page_source
tree = etree.HTML(page)
li = tree.xpath('//*[@id="list_listInfo"]/ul[2]/li')
n = 0
fp = open('./火车票数据', 'w', encoding='utf-8')
for i in li:
n = n + 1
all_data = []
c = i.xpath('.//div/div[1]/h3/text()')
all_data.append(c[0])
l = i.xpath('.//div/div[3]/time[1]/text()')
all_data.append(l[0])
d = i.xpath('.//div/div[4]/time/text()')
all_data.append(d[0])
all_data = str(all_data)
fp.write(all_data + '\n')
print("第{}趟列车{} 出发时间为{} 运行时间为{}".format(n, c[0], l[0], d[0]))
browser.save_screenshot('./火车票.png')最终效果


完整代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from time import sleep
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
from lxml import etree
aa = input('出发地址:')
bb = input('目的地:')
cc = input('出发日期(注意格式例如 2022-03-28):')
# 无头浏览器
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument('--disable-gpu')
s = Service("chromedriver.exe")
browser = webdriver.Chrome(service=s, options=option)
# browser = webdriver.Chrome(service=s)
# 规避检测
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
browser.get('https://user.qunar.com/passport/login.jsp?ret=https%3A%2F%2Fwww.qunar.com%2F%3Fex_track%3Dauto_4e0d874a')
browser.maximize_window()
sleep(1)
browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div[1]/div[1]/div[2]').click()
sleep(1)
username = browser.find_element(By.ID, 'username')
password = browser.find_element(By.ID, 'password')
sleep(1)
username.send_keys('账号')
sleep(1)
password.send_keys('密码')
sleep(1)
browser.find_element(By.XPATH, '//*[@id="agreement"]').click()
sleep(1)
browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div[1]/div[3]/div/div[3]').click()
sleep(1)
huakuai = browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div[1]/div[3]/div/div[5]/div/div/div[3]/div[3]')
huakuai_left_right = huakuai.location
huakuai_height_widtht = huakuai.size
# print(huakuai_left_right,huakuai_height_widtht)
guidao = browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div[1]/div[3]/div/div[5]/div/div/div[3]/div[2]')
guidao_left_rihgt = guidao.location
guigao_height_widtht = guidao.size
# print(guidao_left_rihgt,guigao_height_widtht)
length = guigao_height_widtht['width'] - huakuai_height_widtht['width']
# 动作连实例化,破解滑块验证码
action = ActionChains(browser)
# 点击长按指定的标签
action.click_and_hold(huakuai)
action.move_by_offset(length + 2, 0).perform()
# perform()立即执行动作连操作
# 释放动作链
action.release().perform()
sleep(1)
browser.find_element(By.XPATH, '//*[@id="js_nva_cgy"]/li[3]/a').click()
sleep(2)
browser.find_element(By.XPATH, '//*[@id="js-con"]/div[1]/form/div[1]/div[1]/div[1]/div/div/input').send_keys(aa)
sleep(1)
browser.find_element(By.XPATH,
'//*[@id="js-con"]/div[1]/form/div[1]/div[1]/div[1]/div/div/div[5]/div/table/tbody/tr[1]').click()
sleep(1)
browser.find_element(By.XPATH, '//*[@id="js-con"]/div[1]/form/div[1]/div[1]/div[2]/div/div/input').send_keys(bb)
sleep(1)
browser.find_element(By.XPATH,
'//*[@id="js-con"]/div[1]/form/div[1]/div[1]/div[2]/div/div/div[5]/div/table/tbody/tr[1]').click()
sleep(1)
ff = browser.find_element(By.XPATH, '//*[@id="js-con"]/div[1]/form/div[1]/div[2]/div/div/div[1]/input')
for i in range(10):
ff.send_keys(Keys.BACK_SPACE)
ff.send_keys(cc)
ff.click()
sleep(1)
browser.find_element(By.XPATH, '//*[@id="js-con"]/div[1]/form/div[2]/div/span/button').click()
sleep(1)
page = browser.page_source
tree = etree.HTML(page)
li = tree.xpath('//*[@id="list_listInfo"]/ul[2]/li')
n = 0
fp = open('./火车票数据', 'w', encoding='utf-8')
for i in li:
n = n + 1
all_data = []
c = i.xpath('.//div/div[1]/h3/text()')
all_data.append(c[0])
l = i.xpath('.//div/div[3]/time[1]/text()')
all_data.append(l[0])
d = i.xpath('.//div/div[4]/time/text()')
all_data.append(d[0])
all_data = str(all_data)
fp.write(all_data + '\n')
print("第{}趟列车{} 出发时间为{} 运行时间为{}".format(n, c[0], l[0], d[0]))
browser.save_screenshot('./火车票.png')