一文尽览 | 开放世界目标检测的近期工作及简析!(基于Captioning/CLIP/伪标签/Prompt)...
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
后台回复【2D检测综述】获取鱼眼检测、实时检测、通用2D检测等近5年内所有综述!
目标检测是人工智能最突出的应用之一,也是深度学习最成功的任务之一。然而,尽管深度对象检测取得了巨大进步,例如 Faster R-CNN ,已经能取得非常不错的准确性,但训练此类模型需要昂贵且耗时的监督信号,他们都要靠人工标注获得。特别是,需要为每个ROI的对象类别手动标注至少数千个边界框。尽管之前很多机构已经完成了object detection上benchmark的建立,并且公开了这些有价值的数据集,例如 Open Images和 MSCOCO,这些数据集描述了一些有限的对象类别。但如果我们想吧将目标检测从 600 个类别扩展到 60000 个类别,那么我们需要 100 倍数据资源的标注,这使得把目标检测拓展到开放世界里变得遥不可及。然而,人类通过自然监督学会毫不费力地识别和定位物体,即探索视觉世界和倾听他人描述情况。我们人类具有终生学习的能力,我们捕捉到视觉信息后,会将它们与口语联系起来,从而产生了丰富的视觉和语义词汇,这些词汇不仅可以用于检测物体,而且可以用来拓展模型的表达能力。尽管在对象周围绘制边界框不是人类自然学习的任务,但他们可以使用少量例子快速学习它,并将其很好地泛化到所有类型的对象,而不需要每个对象类的示例。这就是open vocabulary object detection这一问题的motivation所在。
1. 基于captioning的信息抽取
Open-Vocabulary Object Detection Using Captions (CVPR 2021)
提出原因:人类通过自然监督,即探索视觉世界和倾听他人描述情况,学会了毫不费力地识别和定位物体。我们人类对视觉模式的终身学习,并将其与口语词汇联系起来,从而形成了丰富的视觉和语义词汇,不仅可以用于检测物体,还可以用于其他任务,如描述物体和推理其属性和可见性。人类的这种学习模式为我们实现开放世界的目标检测提供了一个可以学习的角度。
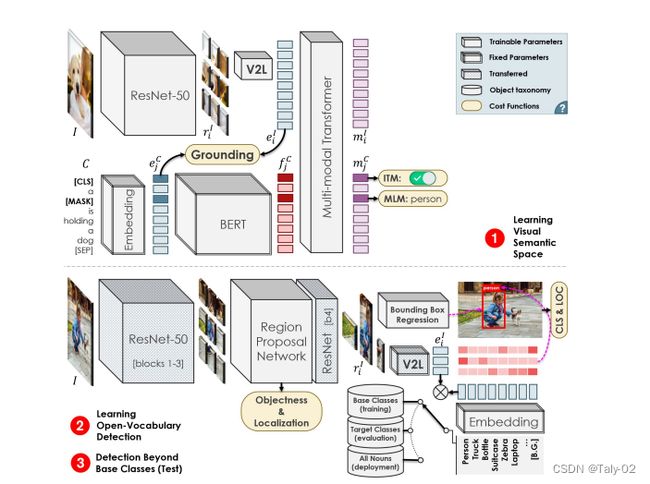
第一步:学习的视觉与文本的联系。通过训练一个现象变换层来把视觉空间的特征转换到文本空间,来充当一个V2L(Vision to Language)的模块,负责把视觉特征变换到文本空间去。输入的image-captioning对首先经过各自模态的encoder,图像则是细分得到每个区域的特征,然后进一步经过V2L变换。之后,两个模态的特征concat起来之后送入多模态的Transformer,得到的输出是视觉区域特征以及文本特征。损失函数则是惩罚不匹配的但是相似度高的图像-文本对。如上图文本encoder是一个预训练好的BERT,这样模型具有泛化能力,而图像encoder是常用的resnet50。
第二步:利用常规的目标检测框架:Faster R-CNN,进行模型训练。为了保证延续性,backbone采用上一阶段中训练好的resnet50,每个proposal的特征经过V2L变换之后与类别标签的文本特征计算相似度来进行分类。事实上就是把回归问题转换成了分类问题。
第三步:把要检测的新类别加入文本的特征向量中做匹配。
作者还比较了一下提出的OVD与之前相关的setting有什么不同:

作者还特地比了一下三种setting, OVD跟ZSD的区别应该就是在训练时,OVD可能会用到target类的embedding信息,当然可能只说这些embedding信息可能包含在一堆caption中, 谁也不知道里面有没有target信息,肯定不能给target类的bbox信息。而zero-shot完全没利用到,weakly supervised就更直接了,直接利用子集来训练,从而强化泛化能力。
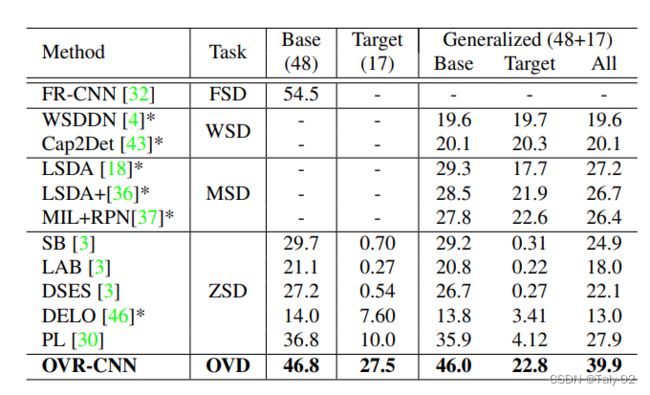
可以发现。相较于原有的zero-shot的detection,模型的泛化性能显然是更强的。根据上表,其实我们可以发现,ZSD的检测效果差(map不高),主要原因,我认为就是对于没有任何未知类的例子经过训练,OVD 应该是会有部分未知类通过image-caption dataset 训练课得知,因此从现有基类的特征其实很难推出新类。WSD 定位效果不好, 我个人分析认为,他从没有注释的图片很难学习到特征,就很难像OVD那样通过image-caption那样,至少有图像和文本方向的特征,再通过基类的相关有注释框的图片学习,就能很好的定位。mixed supervision,其实同样存在上面的缺陷,在基类上进行训练,然后使用弱监督学习转移到目标类,这些方法通常会在基类上降低性能相反,Visual grounding和Vision-language transformers 就是来帮助解决作者的设想,通过 Vision-language transformers 可以提取 文本和图像的特征,Visual grounding 则就是根据这些特征进行定位。
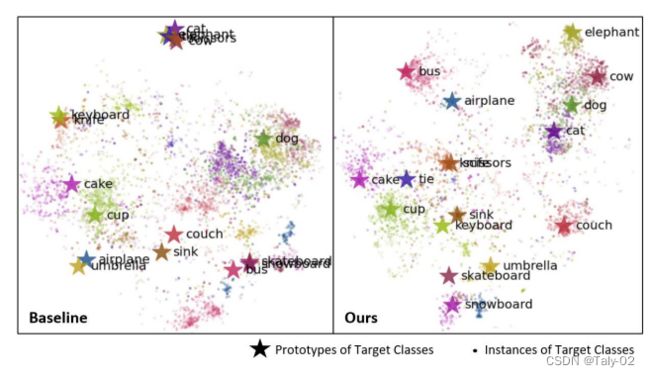
同时我们也发现,利用这种用image-captioning pair模式训练出来的特征,其中每个类别的特征更加显著,如下图和zero-shot obejct detection的baseline的对比:
2. 基于CLIP的蒸馏
CLIP是一种在大量图像和文本对上训练的神经网络。作为这种多模态训练的结果,CLIP可用于查找最能代表图像的文本片段,或查找给定文本查询的最合适图像。CLIP在image-level的分类上已经取得了非常令人印象深刻的效果。基于其巨大潜力,在目标检测上应用也显得理所当然了。
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation (ICLR 2022)
提出原因:现有的对象检测算法通常只学习检测检测数据集中存在的类别。增加检测词汇量的常用方法是收集带有更多标记类别的图像。有了如此丰富的词汇,为所有类别收集足够的训练示例变得相当具有挑战性。而对象类别自然地遵循长尾分布。为了为稀有类别找到足够的训练示例,需要大量的数据,这使得扩大检测词汇量的成本很高。另一方面,互联网上有丰富的成对图像-文本数据,尽管在学习图像级表示法方面取得了巨大的成功,但学习用于开放词汇表检测的对象级表示法仍然具有挑战性。
在这项工作中,我们考虑借用预训练的开放词汇分类模型中的知识来实现open vocabulary检测。整体的思路是把检测问题转换为proposal分类问题。看上图的中间,把每个类别的文本标签通过预训练的CLIP投影到多模态空间中得到类别文本向量,然后Inference的时候每个proposal的特征也投影到多模态空间中,再把proposal的特征和类别文本特征进行比对,就可以对proposal进行分类了。
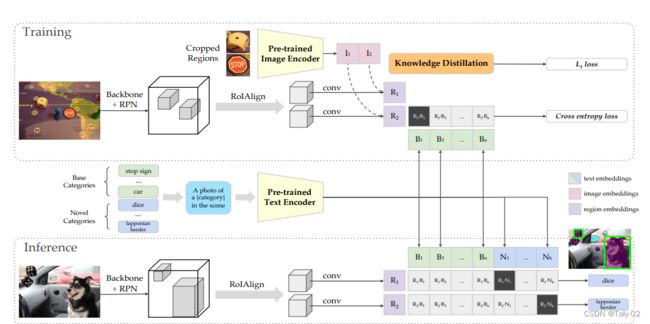
在训练阶段,论文提出首先进行图像的ROI裁剪。先将标注区域的图片裁剪出来,冉通过Pre-trained Image Encoder编码得到标注区域的image embeddings。第二阶段就是通过Mask R-CNN产生类别无关的region embeddings。那么怎么获得这些image embeddings和region embeddings呢?论文给出的答案是进行知识蒸馏。由于CLIP的模型太大,直接使用进来计算开销显然过大,所以本文选择映入蒸馏来获得一个相对较小的模型。基本类别转化成文本送入Pre-trained Text Encoder产生text embeddings,将region embeddings和text embeddings进行点积然后softmax归一化,监督信号是对应类别位置1,其余位置为0。
在推理阶段,首先将基本类别和新增类别转化成文本送入Pre-trained Text Encoder产生text embeddings(分别为绿色和蓝色部分),同时通过Mask R-CNN产生类别无关的region embeddings,然后将region embeddings和text embeddings进行点积然后softmax归一化,新增类别(蓝色部分)取最大值的类别为该区域的预测结果。
其中proposal特征的提取是通过用CLIP的模型进行蒸馏学习到的,如下图最右侧所示:
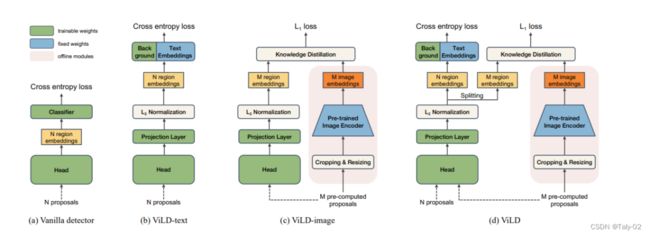
proposal经过head来得到proposal在多模态空间中的特征,其中ViLD-text是在文本模态上,使得proposal的特征逼近文本类别标签的多模态空间特征;而ViLD-image是在视觉模态上,使得proposal的特征逼近用proposal裁剪下的图片送入CLIP之后得到的多模态空间特征。

文本嵌入作为分类器(ViLD-文本):我们使用 CLIP 生成的文本嵌入评估 ViLD-文本,并将其与 (大型纯文本语料库)GloVe 文本embedding中对比。表 3 显示 ViLD-text 达到 10.1 APr,这显着使用 GloVe 优于 3.0 APr。这证明了使用文本嵌入的重要性 与图像联合训练。与 CLIP 相比,ViLD 文本实现了更高的 APc 和 APf裁剪区域,因为 ViLD 文本使用 CB 中的注释来对齐区域嵌入带有文本嵌入。APr 更糟,表明在 LVIS 中仅使用 866 个碱基类别确实不像 CLIP 那样泛化到新类别。
蒸馏图像embedding(ViLD-image):我们评估 ViLD-image,它从裁剪区域提案的图像嵌入,由 CLIP 的图像编码器推断,蒸馏权重为 1.0。实验表明,结合客观性的表现对其他方面没有帮助ViLD 的变体提高性能,所以我们只将它应用于 ViLD-image。在没有使用任何对象类别标签进行训练的情况下,ViLD-image的APr达到了11.2 APr ,而整体 AP的达到了11.5。这表明视觉蒸馏有效用于开放词汇检测,但在裁剪区域上的性能不如CLIP。
文本+视觉embedding (ViLD):ViLD 显示了使用文本嵌入 (ViLD-text) 将蒸馏损失 (ViLDimage) 与分类损失相结合的好处。我们在附录表 7 中探索了不同的超参数设置,并观察到两个AP之前存在trade-off,这表明 ViLD-text 和 ViLD-image 之间存在竞争。在上表中,我们比较ViLD 与其他方法。它的 APr 比 ViLD-text 高 6.0,比 ViLD-image 高 4.9,这一实验结果表明结合这两个学习目标可以提高新类别的表现。ViLD优于 Supervised-RFS 3.8 APr,表明我们的开放式词汇检测方法在尾部较少的类别,优于其他的全监督模型。
个人觉得这是open vocabulary object detection迈出的非常重要的一步。因为基于CLIP这样强大的预训练模型,才能使得object detection能够真正的面向open world。同时就结构来看,novel AP达到了27.6,相较于之前Zareian的方法,提高了将近五个点,也将这个领域的性能带到了新高度。
RegionCLIP: Region-based Language-Image Pretraining (CVPR 2022)
提出原因:CLIP在包括图像细粒度分类,OCR等分类下游任务表现优异,但在object detection这类recognize image region上表现比较差。这是存在domain shift:CLIP建立的是image-text pair,并不能准确定位图片上的region。而本文就是为了解决这个问题。本文提出了regionCLIP 通过建立region-text pair,并且在特征空间上对齐,来使模型在nlp的监督下,学习到region-level visual representation.

第一步:完成图像文本的预训练。利用CLIP预训练一个image-text level的 visual encoder和 language encoder。这里获得的visual encoder是作为teacher model的,作用是初始化和完成知识蒸馏;而由于模型的语言特征往往不会发生过大变换,所以language encoder在两个阶段中共享参数。
第二步,完成region-text pairs的构造。首先利用现成的从语言的预训练模型,从image-level的text中提取object性质的语料,把传统的label的pool转换成prompt 范式(cat→a photo of cat)。然后利用第一步中训练好的language encoder提取Semantic region representation。
训练的loss为:

就是文本图像对的对比学习加上image特征自己的对比学习,然后还有特征之间的distance这样更有注意分类。
实验结果来看:

相较于前文提到的OVR,从16.7提升到了35.2,相较于直接利用CLIP。也从22.5提升到了35.2。同时可以发现,如果采用RN50x4这种backbone,性能就可以提升到43.3,可见良好的特征提取还是对目标检测非常关键的。
3.基于伪标签的方法
Towards Open Vocabulary Object Detection without Human-provided Bounding Boxes (2021CVPR)
提出问题:无论是zero-shot还是open vocabulary的目标检测方法,在训练过程中仍然需要在基本对象类别上标注边界框。基本类别集覆盖的范围越广,检测器对新对象的性能越好。因此,检测器要在新对象上表现良好,就无法避免人为的边界框注释成本。当我们想要检测新类别的任意对象时,我们能否避免这种手动的边界框标签,并训练一个更通用的对象检测器,而不需要人工提供的实例级注释?本文给出了肯定的回答。
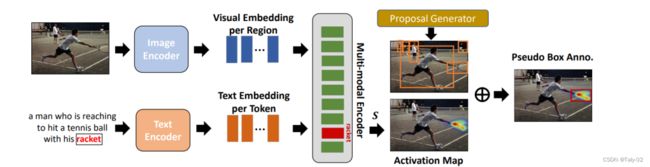
整个框架的输入同样是image-captioning的pair。我们使用图像和文本编码器来提取图像及其相应标题的visual和textual embeddings。然后通过图像与文本的交叉注意交互获得表征能力较强的representation。我们在预定义的对象词汇表中保留感兴趣的对象。对于embedding的caption中的每个感兴趣的对象(例如上图中的球拍),我们使用Grad-CAM将其激活图activation map 可视化到图像中。这张图显示了图像区域对target word最终表示的贡献。最后, 通过选择与activation map 重叠最大的 object proposal 作为 pseudo bouding box label.
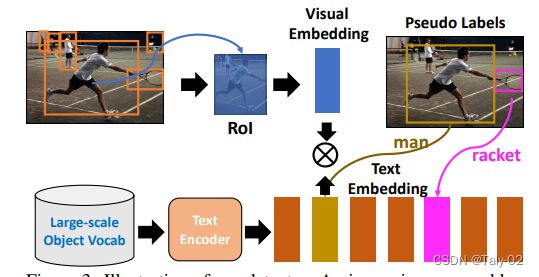
图像由特征提取器处理,然后是区域的proposal网络。然后,通过在区域建议上应用Rol pooling/Rol和alignment来计算基于区域的特征,并获得相应的可视化嵌入。在训练过程中鼓励同一对象的视觉和文本的embedding的相似性。
匹配的loss自然是交叉熵的形式:


性能同样达到了30.8,而base AP是46.1,相较于前任方法具有较为明显的提升。
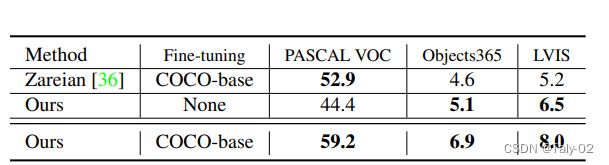
对广泛数据集的泛化能力对于开放词汇表对象检测器也很重要,因为这使得检测器可以直接作为一种开箱即用的方法使用。表2显示了检测器对不同数据集的泛化性能,其中我们的方法和基线都没有使用这些数据集进行训练。Objects365和LVIS拥有大量不同的对象类别,因此对这些数据集的评估结果将更有代表性地展示泛化能力。结果表明,我们的方法(没有微调)已经表现出比Zareian等人更好的性能。(使用finetune)在Objects365和LVIS上。
Grounded Language-Image Pre-training (CVPR 2022 oral)
提出原因:在概念上,object detection 与 phrase grounding 具有很大的相似性,它们都寻求对对象进行定位 (即学习到并能检测这种对象的类别),并将其与语义概念对齐。而本文建立region-text pair的过程是不需要任何人工标注的,所以从scalable角度来看是比较有意义的。
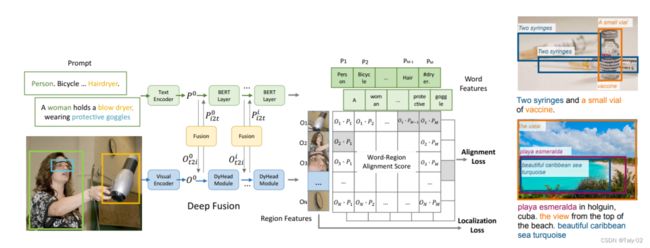
这份工作非常有意思。其目标非常宏大,就是将detection重构为phrase grounding,实现统一检测和分类的统一。
由于detection可以同时接受图像和文本输入。例如将COCO中的80个类别作为文本输入。、通过大量的图像-文本数据扩展visual concept。而同时使用detection和grounding数据集,可以使得预训练的grounding可以为无包围框标注的图像-文本对数据生成伪标签。通过GLIP进行迁移学习:一个模型完成多个任务。能做detection也能做grounding。整体框架非常简单,跟clip差不多。->其中图像表征O不再是全图,而是检测器生成的proposal,文本特征则为一个个短语。GLIP只是将检测模型中的分类头预测的classifiacation score替换为CLIP中的alignment score.
具体到论文的方法。对于模型的输入,GLIP 开天辟地地对目标检测任务进行了重新定义,作者认为,目标检测实际上可以重新定义,可以是做吧任何一张训练中的image,其上出现的所有样本的标签在分散之后拼接成一句话,从而把目标检测任务重新转换为短语定位任务。通过这种方式,所有的目标检测数据集都可转化为短语定位数据集。然后,通过对文字和图片分别进行编码,并对这些word-region pair进行对比学习,从而获得了对齐后的文字与图片各自的特征。然后引入“深度融合”(deep fusion)的概念:区别于前期融合(early fusion)和后期融合(late fusion),深度融合对两个模态的特征向量计算交叉注意力(cross attention),从而让模型可以在较浅的模型阶段就开始进行跨模态的特征学习。

作者首先完成了zero-shot的迁移学习。然后又对使用标准设置的fine-tuning预训练模型的经典范式进行了评测。作者加入了一个额外的baseline:在 Objects365[6]上预训练的 DyHead。由于Objects365 完全包含了COCO 80个类别。因此,作者以“零样本”的方式评估在 Objects365 上训练的 Dy-Head:在inference期间, Dy-Head不是从 365 个类别进行预测,而是被限制为仅从 COCO 80 个类别进行预测。总体而言,GLIP模型实现了强大的零样本和监督性能。零样本GLIP模型达到甚至超过了监督模型的性能。最好的GLIP-T达到46.7 AP,超越Faster RCNN;GLIP-L 达到 49.8 AP,超过 DyHead-T。在监督设置下,最好的GLIP-T比标准Dy-Head(55.2 vs 49.7)带来 5.5 AP 的改进。借助 Swin-Large 主干,GLIP-L 在 COCO 上超过了当前的SoTA,在2017val上达到 60.8 AP,test-dev性能达到61.5AP。相对之前的SoTA模型(如EMA),GLIP没有一些诸如mix-up和soft-NMS这些后处理的额外操作。
4.基于Prompt的方法
Learning to prompt for open-vocabulary object detection with vision-language model (CVPR 2022)
提出原因:在之前提到的ViLD的实现中,它们将基类的文本描述(称为prompt)提供给CLIP的文本编码器,以生成类文本的embedding。然后利用嵌入对目标建议进行分类,并监督检测器的训练。要执行开放集对象检测,基类文本嵌入将被基类和新类的embedding所取代。prompt设计,也称为prompt工程,在这个过程中至关重要,因为我们观察到其中的微小变化将最终对检测性能产生明显的积极或消极影响。设计合适的提示需要专业的领域知识和精心的文字调整。为了避免这种高端且相当费力的需求,另一种方法是使用连续表示自动学习提示符的上下文,我们将其命名为prompt的表征学习。本文就是完成这一步骤。
在图像中,visual embedding of positive proposals与对应的类嵌入之间定义了postive的loss;而负损失定义在visual embedding of negative proposals和所有类别嵌入之间。采用不同的定制正的proposal集合(a < IoU(GT, Pos P) < B)学习不同的提示表示,并最终进行整合。
概率计算表现为:


在本文中,论文提出了一种名为检测提示 (detection prompt, DetPro) 的新方法来学习提示表示,在使用预训练视觉语言模型 (OVOD-VLM) 的开放词汇对象检测设置中。最近有一些工作专注于即时表示学习,例如 CoOp,其目标是基于预训练的视觉语言模型提高图像分类的准确性。直接将 CoOP 应用到 OVOD-VLM 中是不现实的:因为图像分类只需要识别输入图像的正确标签,而目标检测需要检测器区分前景和背景,并将前景中的区域提案分类为不同的对象类别。因此,我们引入了一种新的检测提示(DetPro)来自动学习 OVOD-LVM 中基于正面和负面的prompts representation。Prompt learning in object detection 面临两个关键问题:1)negative proposals 尽管对目标检测非常重要,但不对应于特定的对象类,因此不能轻易地包含到 prompt learning 过程中。2)不同于图像分类中的物体 由于图像居中且大,积极建议中的对象通常与不同级别的上下文相关联,因此无法为这些建议学习一个提示上下文充足的。为了解决这些问题,论文引入了
包含negative proposal的背景解释方案,优化了embedding,使得negative proposal远离所有其他类的embedding;
提出了a context grading scheme with tailored positive proposals,它根据不同的积极建议集相应地定制提示表示学习 到不同的上下文级别。
书壤土,其实非常简单,就是在Image和Text的head后加入两个映射层,使得模型更加灵活。

相较于无比强大的ViLD,DetPro在检测和分割上都展现出来了一定的优势。
5.直接拓展标签的方法
Detecting Twenty-thousand Classes using Image-level Supervision (ECCV 2022)
提出原因:现有的大多数弱监督检测技术[13,22,36,59,67]都使用弱标记数据来监督检测的定位和分类子问题。由于图像分类数据没有框标签,这些方法开发了基于模型预测的各种标签到框分配技术,以获得监督。不幸的是,这种基于预测的分配需要良好的初始检测,这导致了一个鸡与蛋的问题——我们需要一个好的检测器来进行良好的标签分配,但我们需要很多box来训练一个好的检测器。首先观察到存在明显的长尾效应,所以需要基于文本的label来拓展性能,才能让模型具有较好的泛化性能,能处理open world的各种复杂情景。所以能从有限的类别中拓展到更多的类别,对于目标检测器的泛化能力提升非常有意义。

本文做的是large-vocabulary detection方向的研究,与general detection和weakly-supervised detection的区别在于,其训练集中包含一部分有检测标注的数据和一部分只有image-level标注的数据,其测试集中包含novel class。我们的方法在使用分类数据时,通过单独监督分类子问题,完全绕过了基于预测的标签分配过程。这也使我们的方法能够学习新类的检测器,这将是不可能预测和分配的。

本文提出的方法也采用了经典的两阶段范式,在第一阶段采用直接提取RPN的方法,第二阶段对做细化的具体类别进行assign和识别。而实质上的检测是在第一阶段就可以完成的,而我们的目标是使得分类的分支具备检测出novel class的能力。因此本文提出了基于image-supervised loss 的Detic。如果对于一个特定类别,其训练数据存在检测的标注,则按照正常的两阶段的端到端模型进行训练。而当训练数据只有类别标签的时候,而没有具体的RPN标注,则按照最大似然的理论,则可以把RPN中面积最大的那个检测框里的特征拿去学分类分支。损失函数采用了BCE的loss。那么为什么不采用交叉熵的损失函数呢?这是因为由于分类中一直会加入新的类别,所以类别数目是不确定的,利用交叉熵这个时候就显得有些不合理了,所以对每个类采用BCE。
实际上就转化为了匹配问题:

来看实验结果:
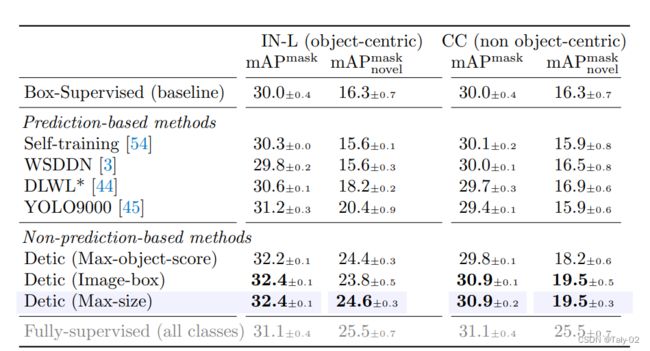
论文比较了一些基于prediction-based的方法,这些方法将图像标签分配给基于预测的proposal。self-training将 Box-Supervised 的预测分配为具有固定分数threshold(0.5) 的offline伪标签。其他基于预测的方法使用不同的损失来在线将预测分配给图像标签。有关实施细节,请参阅附录 E。对于 DLWL [44],我们实现了一个不包括自举的简化版本,并将其称为 DLWL。上表展示了论文提出的不是prediction-based的方法的结果。在两个图像全监督数据集,我们提出的更简单的所有变体 方法优于基于复杂预测的对应方法。在新类上,相较于Detic, 在ImageNet上,论文提出的基于最佳预测的方法提供了约4.2 点,带来了较为显着的增益。从实验结果来看,论文提出的方法的确做到了”Detecting Twenty-thousand Classes“
Learning Object-Language Alignments for Open-Vocabulary Object Detection
提出原因:现有的大多数开放词汇表对象检测工作(全部或部分依赖于接ground-truth数据,然而,这是不可扩展的,因为注释接地数据甚至比注释对象检测数据更昂贵。为了降低开放词汇表对象检测的注释成本,最近的一些工作转而通过裁剪图像从面向分类的模型中提取视觉区域特征。它们的性能受到预训练模型的限制,该模型被训练为全局图像-文本匹配而不是区域-单词匹配。因此本文提出新的方法完成区域和单词的匹配。

在本文中,论文提出了一个简单而有效的端到端视觉和语言框架,用于open vocabulary的目标检测,称为 VLDet,它直接从图像文本对训练对象检测器,而不依赖昂贵的基础注释或提取面向分类的视觉的模型。笔者理解论文的主要insight是,从图像-文本对中提取region-word对可以表述为一个集合的matching问题,该问题可以通过找到区域和单词之间具有最小全局匹配成本的二分匹配来有效解决。具体来说,我们将图像区域特征视为一个集合,将词嵌入视为另一个集合,并将点积相似度作为区域词对齐分数。为了找到最低成本,最优二分匹配将强制每个图像区域在图像-文本对的全局监督下与其对应的词对齐。通过用最佳区域词对齐损失代替目标检测中的分类损失,论文提出的方法可以帮助将每个图像区域与相应的词匹配并完成目标检测任务。
从图像-文本对学习对象语言对齐。由于图像文本对数据的低成本,假设图像-文本数据集涵盖了更多种类的对象,我们有动力增加检测器的词汇量。然而,目标检测需要更细粒度的区域词对进行训练。关键的挑战是如何找到区域集和单词集之间的对应关系。我们不再为每张图像生成伪的边界框和标签,而是提出将区域-词对齐问题表述为最优二部匹配问题。我们进一步将图像-文本对视为特殊的区域-单词对。我们通过将整个图像视为一个特殊区域并将来自文本编码器的整个captioning特征视为一个特殊词来提取图像的 RoI 特征。对于图像,我们将其captioning视为正样本,将同一小batch中的其他captioning视为负样本。同样的,由于采用了匹配的模式,整个框架的loss同样采用了BCE loss:
来看实验性能:

上表展示了了针对open vocabulary COCO 数据集的不同方法的性能。可以看出,我们的模型在新类上表现最好,表明使用图像文本对的二分匹配损失的优越性。Base-only 方法表示使用完全监督的 COCO base-category 检测数据训练的 Faster R-CNN,CLIP 的embeddings作为分类器头。虽然 CLIP 具有对新类的泛化能力,但它只达到了 1.3 mAP。尽管 ViLD 和 RegionCLIP 使用 CLIP 提取区域proposal特征,但它们在新类别上的表现不如我们的方法,这是open vocabulary对象检测设置中的主要指标。这些蒸馏方法需要来自预训练 CLIP 模型的图像编码器和文本编码器来学习图像区域和词汇表之间的匹配。因此,它们在新类别上的表现受到预训练模型的限制,该模型是为全局图像-文本匹配而不是区域-单词匹配而训练的。

在分割上的表现同样很不错。
往期回顾
从原理到实战 | 扩展卡尔曼滤波器(含代码)


【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称