TensorFlow2.3 - mnist手写数字识别-CNN卷积神经网络
导入模块
from PIL import Image
import tensorflow as tf
import numpy as np
import os
import cv2
model_path = './tf_model/'
epoch_num = 30
CNN模型代码
模型定义的前半部分主要使用Keras.layers提供的Conv2D(卷积)与MaxPooling2D(池化)函数。
CNN的输入是维度为 (image_height, image_width, color_channels)的张量,mnist数据集是黑白的,因此只有一个color_channel(颜色通道),一般的彩色图片有3个(R,G,B),熟悉Web前端的同学可能知道,有些图片有4个通道(R,G,B,A),A代表透明度。对于mnist数据集,输入的张量维度就是(28,28,1),通过参数input_shape传给网络的第一层。
class CNN(object):
def __init__(self):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.summary()
self.model = model
model.summary()用来打印我们定义的模型的结构。
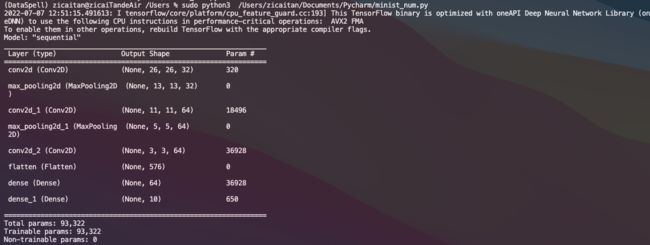
我们可以看到,每一个Conv2D和MaxPooling2D层的输出都是一个三维的张量(height, width, channels)。height和width会逐渐地变小。输出的channel的个数,是由第一个参数(例如,32或64)控制的,随着height和width的变小,channel可以变大(从算力的角度)。
模型的后半部分,是定义输出张量的。layers.Flatten会将三维的张量转为一维的向量。展开前张量的维度是(3, 3, 64) ,转为一维(576)的向量后,紧接着使用layers.Dense层,构造了2层全连接层,逐步地将一维向量的位数从576变为64,再变为10。
后半部分相当于是构建了一个隐藏层为64,输入层为576,输出层为10的普通的神经网络。最后一层的激活函数是softmax,10位恰好可以表达0-9十个数字。
数据处理
6万张训练图片,1万张测试图片
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
像素值映射到 0 - 1 之间
train_images, test_images = train_images / 255.0, test_images / 255.0
self.train_images, self.train_labels = train_images, train_labels
self.test_images, self.test_labels = test_images, test_labels
所以数据处理类定义如下:
class DataSource(object):
def __init__(self):
# mnist数据集存储的位置,如何不存在将自动下载
# data_path = os.path.abspath(os.path.dirname(__file__)) + '/../data_set_tf2/mnist.npz'
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 6万张训练图片,1万张测试图片
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
# 像素值映射到 0 - 1 之间
train_images, test_images = train_images / 255.0, test_images / 255.0
self.train_images, self.train_labels = train_images, train_labels
self.test_images, self.test_labels = test_images, test_labels
训练
class Train:
def __init__(self):
self.cnn = CNN()
self.data = DataSource()
def train(self):
check_path = './checkpoint/cp-{epoch:04d}.ckpt'
# period 每隔5epoch保存一次
save_model_cb = tf.keras.callbacks.ModelCheckpoint(check_path, save_weights_only=True, verbose=1, period=2)
self.cnn.model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
self.cnn.model.fit(self.data.train_images, self.data.train_labels, epochs=epoch_num, callbacks=[save_model_cb])
test_loss, test_acc = self.cnn.model.evaluate(self.data.test_images, self.data.test_labels)
print("准确率: %.4f,共测试了%d张图片 " % (test_acc, len(self.data.test_labels)))
在执行python train.py后,会得到以下的结果:
_________________________________________________________________
WARNING:tensorflow:`period` argument is deprecated. Please use `save_freq` to specify the frequency in number of batches seen.
Epoch 1/5
1875/1875 [==============================] - 60s 32ms/step - loss: 0.1528 - accuracy: 0.9538
Epoch 2/5
1875/1875 [==============================] - 54s 29ms/step - loss: 0.0485 - accuracy: 0.9849
Epoch 3/5
1875/1875 [==============================] - 54s 29ms/step - loss: 0.0356 - accuracy: 0.9890
Epoch 4/5
1875/1875 [==============================] - 55s 29ms/step - loss: 0.0269 - accuracy: 0.9922
Epoch 5/5
1874/1875 [============================>.] - ETA: 0s - loss: 0.0211 - accuracy: 0.9931
Epoch 5: saving model to ./ckpt/cp-0005.ckpt
1875/1875 [==============================] - 56s 30ms/step - loss: 0.0211 - accuracy: 0.9931
313/313 [==============================] - 3s 8ms/step - loss: 0.0317 - accuracy: 0.9913
准确率: 0.9913,共测试了10000张图片
可以看到,在第一轮训练后,识别准确率达到了0.9538,5轮之后,使用测试集验证,准确率达到了0.9931
在第五轮时,模型参数成功保存在了./ckpt/cp-0005.ckpt。接下来我们就可以加载保存的模型参数,恢复整个卷积神经网络,进行真实图片的预测了。
图片预测
class Predict(object):
def __init__(self):
latest = tf.train.latest_checkpoint('./ckpt')
self.cnn = CNN()
# 恢复网络权重
self.cnn.model.load_weights(latest)
def predict(self, image_path):
# 以黑白方式读取图片
img = Image.open(image_path).convert('L')
img = np.reshape(img, (28, 28, 1)) / 255.0
# pred_img = cv2.resize(img, (28, 28))
img = np.array(img)
img = img.reshape(28, 28, 1)
x = np.array([1 - img])
y = self.cnn.model.predict(x)
# 因为x只传入了一张图片,取y[0]即可
# np.argmax()取得最大值的下标,即代表的数字
print(image_path)
print(y[0])
print(' -> Predict digit', np.argmax(y[0]))
主函数
if __name__ == "__main__":
app = Train()
app.train()
predict = Predict()
list = os.listdir("./test")
for i in list:
predict.predict("./test/"+i)
把预测文件放在test文件夹下面即可进行数字预测。