超越全系YOLO!旷视开源性能更强的YOLOX
本文转载自机器之心
编辑:杜伟、陈萍
在本文中,来自旷视的研究者提出高性能检测器 YOLOX,并对 YOLO 系列进行了经验性改进,将 Anchor-free、数据增强等目标检测领域先进技术引入 YOLO。获得了超越 YOLOv3、YOLOv4 和 YOLOv5 的 AP,而且取得了极具竞争力的推理速度。
随着目标检测技术的发展,YOLO 系列始终追寻可以实时应用的最佳速度和准确率权衡。学界人士不断提取当时最先进的检测技术(如 YOLOv2 的 anchor、YOLOv3 的残差网络),并对这些检测技术进行优化以实现最佳性能。目前,YOLOv5 在速度和准确率上有最好的权衡,在 COCO 数据集上以 13.7ms 的速度获得 48.2% AP。
然而,过去两年时间里,目标检测领域的主要进展集中在无锚点(anchor-free)检测器、先进的标签分配策略以及端到端的(NMS-free)检测器。但是,这些技术还没有集成到 YOLO 系列模型中,YOLOv4 、 YOLOv5 仍然还是基于 anchor 的检测器,使用手工分配策略进行训练。
近日,旷视的研究者将解耦头、数据增强、无锚点以及标签分类等目标检测领域的优秀进展与 YOLO 进行了巧妙地集成组合,提出了 YOLOX,不仅实现了超越 YOLOv3、YOLOv4 和 YOLOv5 的 AP,而且取得了极具竞争力的推理速度。

论文地址:https://arxiv.org/abs/2107.08430
项目地址:https://github.com/Megvii-BaseDetection/YOLOX
考虑到 YOLOv4、YOLOv5 在基于 anchor pipeline 中可能会出现一些过拟合,研究者选择 YOLOv3 作为起点(将 YOLOv3-SPP 设置为默认的 YOLOv3)。事实上,由于计算资源有限,以及在实际应用中软件支持不足,YOLOv3 仍然是业界应用最广泛的检测器之一。
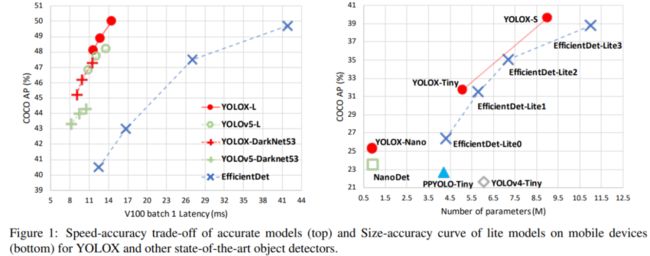
如下图 1 所示,通过将目标检测领域优秀进展与 YOLO 进行组合,研究者在图像分辨率为 640 × 640 的 COCO 数据集上将 YOLOv3 提升到 47.3% AP(YOLOX-DarkNet53),大大超过了目前 YOLOv3(44.3% AP,ultralytics version2)的最佳实践。
此外,当将网络切换到先进的 YOLOv5 架构,该架构采用先进的 CSPNet 骨干以及一个额外的 PAN 头,YOLOX-L 在 COCO 数据集、图像分辨率为 640 × 640 获得 50.0% AP,比 YOLOv5-L 高出 1.8% AP。研究者还在小尺寸上测试所设计的策略,YOLOX-Tiny 和 YOLOX-Nano(仅 0.91M 参数和 1.08G FLOPs)分别比对应的 YOLOv4-Tiny 和 NanoDet3 高出 10% AP 和 1.8% AP。
在 CVPR 2021 WAD 挑战赛的 Streaming Perception Challenge 赛道上,旷视提出的基于 YOLOX 模型(YOLOX-L)的 2D 实时目标检测系统在 Argoverse-HD 数据集上实现了 41.1 的 streaming AP。此外,研究者在推理时用到了 TensorRT 优化器,使得模型在高分辨输入(即 1440×2304)时实现了 30 fps 的推理速度。
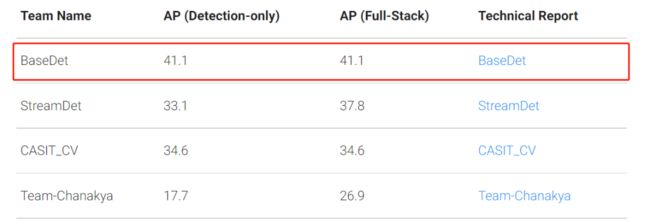
图源:https://eval.ai/web/challenges/challenge-page/800/overview
YOLOX-DarkNet53
研究者选择将 YOLOv3+Darknet53 作为基线模型,并基于它详细介绍了 YOLOX 的整个系统设计。
实现细节
从基线模型到最终模型,研究者的训练设置基本保持一致。他们在 COCO train2017 数据集上训练了 300 个 epoch 的模型并进行 5 个 epoch 的 warmup,使用随机梯度下降(SGD)来训练,学习率为 lr×BatchSize/64 ,初始学习率为 0.01,并使用了余弦(cosine)学习机制。权重衰减为 0.0005,SGD momentum 为 0.9。批大小默认为 128(8 个 GPU),其他批大小使用单个 GPU 训练也运行良好。输入大小以 32 步长从 448 均匀过渡到 832。FPS 和延迟在单个 Tesla V100 上使用 FP16-precision 和 batch=1 进行测量。
YOLOv3 基线模型
基线采用了 DarkNet53 骨干和 SPP 层的架构(在一些论文中被称作 YOLOv3-SPP)。与初始实现相比,研究者稍微改变了一些训练策略,添加了 EMA 权重更新、余弦学习机制、IoU 损失和 IoU 感知分支。他们使用 BCE 损失训练 cls 和 obj 分支,使用 IoU 损失训练 reg 分支。这些通用的训练技巧对于 YOLOX 的关键改进呈正交,因此将它们应用于基线上。此外,研究者还添加了 RandomHorizontalFlip、ColorJitter 和多尺度数据增强,移除了 RandomResizedCrop 策略。
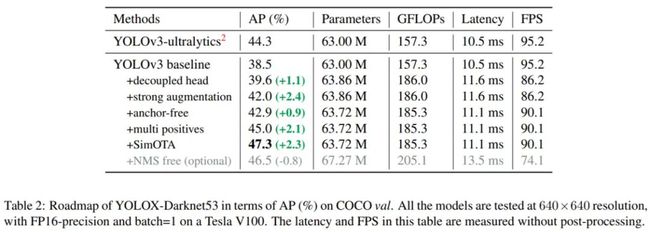
通过这些增强技巧,YOLOv3 基线模型在 COCO val 数据集上实现了 38.5% 的 AP,具体如下表 2 所示:
解耦头
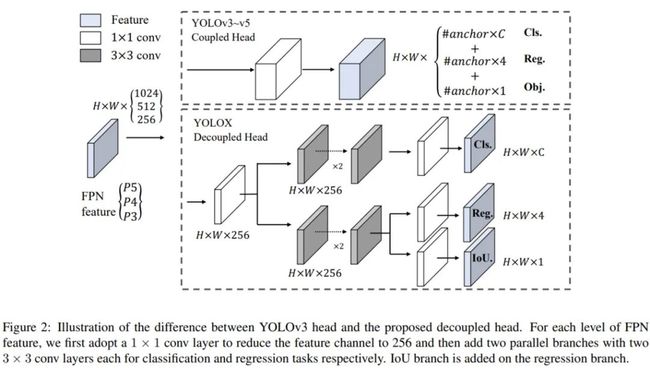
在目标检测中,分类与回归任务之间的冲突是一个众所周知的难题,因此用于分类和定位的解耦头被广泛用于大多数单阶段和双阶段检测器中。但是,随着 YOLO 系列模型骨干和特征金字塔(如 FPN 和 PAN)持续进化,它们的检测头依然处于耦合状态,YOLOv3 头与本文提出的解耦头之间的架构差异如下图 2 所示:
下图 3 为使用 YOLOv3 头和解耦头时的检测器训练曲线:
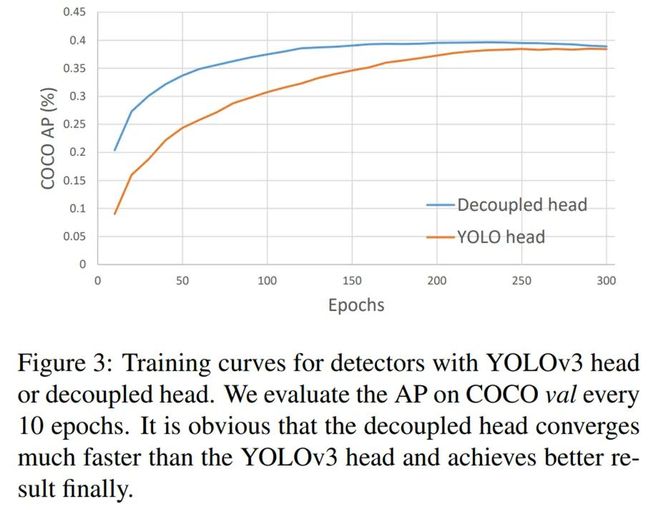
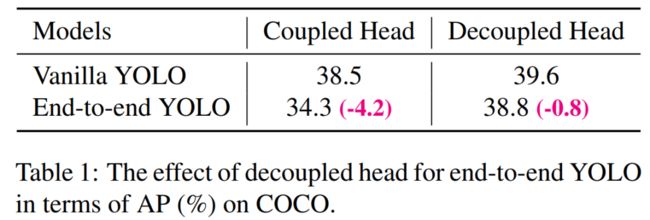
从下表 1 可以看到,使用耦合头时端到端性能降低了 4.2% 的 AP,而使用解耦头时仅仅降低了 0.8% AP。因此,研究者将 YOLO 检测头替换为一个轻量(lite)解耦头,由此极大地提升了收敛速度。
具体地,这个轻量解耦头包含一个 1 × 1 卷积层以减少通道维度,之后紧接着两个 3 × 3 卷积层的并行分支,具体架构参见上图 2。
研究者给出了在单个 Tesla V100 上,使用 batch=1 时的推理时间。如上表 2 所示,轻量解耦头可以带来 1.1 ms 的推理延时。
强(strong)数据增强策略
研究者在增强策略中加入了 Mosaic 和 MixUp 以提升 YOLOX 的性能,他们在模型中采用 MixUp 和 Mosaic 实现,并在最后 15 个 epoch 的训练中关闭。如上表 2 所示,基线模型实现了 42.0% 的 AP。在使用强数据增强策略之后,研究者发现 ImageNet 预训练不再具有更多增益,因此所有模型都从头开始训练。
无锚点(anchor-free)
YOLOv4 和 YOLOv5 都遵循 YOLOv3 的基于锚的初始 pipeline,然而锚机制存在许多已知的问题。过去两年,无锚检测器发展迅速。相关研究表明,无锚检测器的性能可以媲美基于锚的检测器。无锚点机制显著减少了实现良好性能所需的启发式调整和技巧(如 Anchor Clustering、Grid Sensitive)的设计参数数量,从而使得检测器变得更简单,尤其是在训练和解码阶段。
将 YOLO 转变为无锚点模式也非常简单。研究者将每个位置的预测从 3 降至 1,并使它们直接预测四个值,即两个 offset 以及预测框的高宽值。他们将每个目标的中心位置指令为正样本,并预定义一个尺度范围,以确定每个目标的 FPN 水平。这种改进减少了检测器的参数量和 GFLOP,并使其速度更快,与此同时获得了更好的性能,即 42.9% AP(具体如上表 2 所示)。
多个正样本
为了确保与 YOLOv3 的分配规则一致,上述无锚点版本仅为每个目标分配一个正样本(中心位置),同时忽略了其他高质量的预测。研究者将中心 3×3 区域分配为正样本,并命名为「中心采样」。如上表 2 示,检测器的性能提升至 45.0% AP,已经超越了当前 SOTA ultralytics/yolov3 版本的 44.3%AP。
SimOTA
先进标签分配(Advanced label assignment )是近年来目标检测领域中另一个重要进展。该研究将其作为候选标签分配策略。
但是在实践中,该研究发现通过 Sinkhorn-Knopp 算法解决 OT 问题会带来 25% 额外训练时间,这对于 300 epoch 来说代价非常高。因此,该研究将其简化为动态 top-k 策略,命名为 SimOTA,以获得近似解。
SimOTA 不仅减少了训练时间,同时避免了 SinkhornKnopp 算法中额外超参数问题。如表 2 所示,SimOTA 将检测器的 AP 从 45.0% 提高到 47.3%,比 SOTA ultralytics-YOLOv3 高出 3.0%。
端到端的 YOLO
该研究参考 PSS 添加了两个额外的卷基层、一对一的标签分配、stop gradient。这些使得检测器能够以端到端方式执行,但会略微降低性能和推理速度,如表 2 所示。该研究将其作为一个可选模块,但在最终的模型中并没有涉及。
在其他骨干网络的实验结果
除了 DarkNet53,该研究还在其他不同大小的骨干上测试了 YOLOX,结果表明 YOLOX 都实现了性能提升。
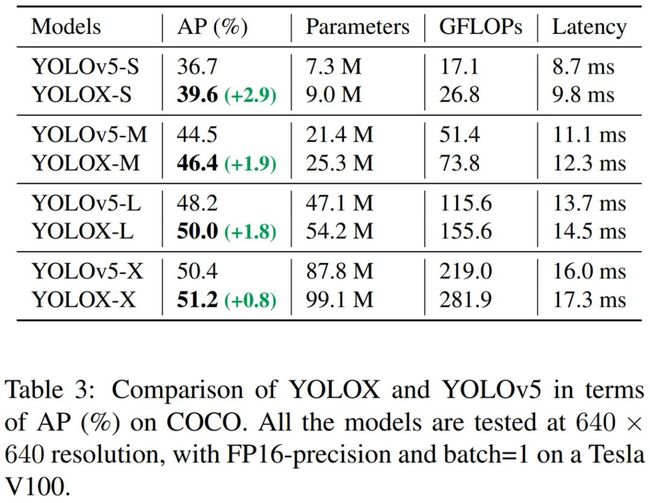
改进 YOLOv5 中的 CSPNet
为了公平的进行比较,该研究采用 YOLOv5 骨干,包括改进的 CSPNet、SiLU 激活函数、PAN 头。此外,该研究还遵循扩展规则来生成 YOLOXS、YOLOX-M、 YOLOX-L、YOLOX-X 模型。与 YOLOv5 在表 3 的结果相比,该模型在仅需非常少的额外推理耗时,取得了 3.0%~1.0% 的性能提升。
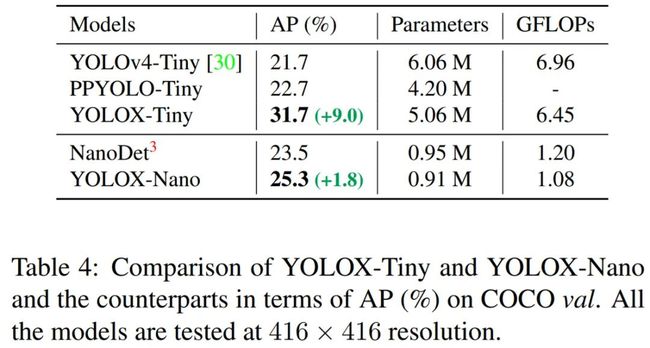
Tiny 和 Nano 检测器
该研究进一步将模型缩小为 YOLOX-Tiny,并与 YOLOv4-Tiny 进行比较。对于移动端设备,研究者采用深度卷积构建 YOLOX-Nano 模型,模型仅有 0.91M 参数量以及 1.08G FLOP。如表 4 所示,YOLOX 在更小的模型尺寸下表现良好。
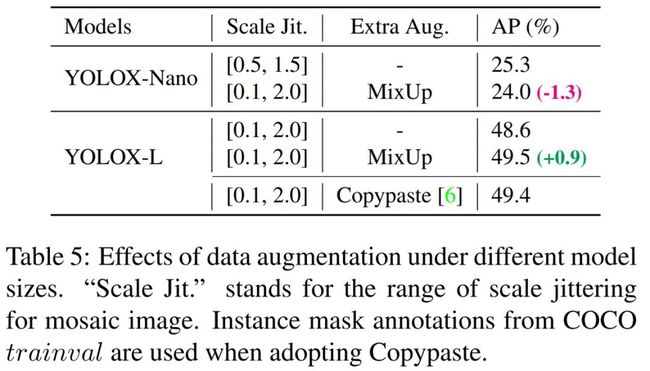
模型大小与数据增强
在实验中,所有模型都保持了几乎相同的学习进度和优化参数。然而,研究发现适当的数据增强策略因模型大小而异。如表 5 所示,YOLOX-L 采用 MixUp 能提高 0.9%AP,对于诸如 YOLOX-Nano 这种小型模型来说,最好是弱化增强。
具体来说,当训练诸如 YOLOX-S、 YOLOX-Tiny、YOLOX-Nano 这种小模型时,需要去除混合增强并弱化 mosaic(将扩展范围从 [0.1, 2.0] 降到 [0.5, 1.5])。这种改进将 YOLOX-Nano 的 AP 从 24.0% 提高到 25.3%。
与 SOTA 结果对比
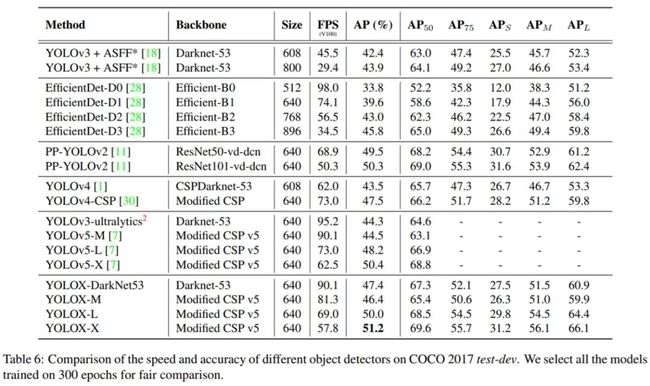
下表 6 为 YOLOX 与 SOTA 检测器的对比结果。在 COCO 2017 test-dev 数据集上进行了不同物体检测器的速度和准确率比较。研究者选择在 300 epoch 上训练所有模型并进行了公平比较。由结果可得,与 YOLOv3、YOLOv4、YOLOv5 系列进行比较,该研究所提出的 YOLOX 取得了最佳性能,获得 51.2%AP,高于其他模型,同时具有极具竞争力的推理速度。

备注:检测

目标检测交流群
扫码备注拉你入群。