【转载】SPSS数据分析中出现的常见问题总结
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/m0_37752335/article/details/77526766
总结最近数据分析过程中遇到的一些问题的思考
1.问卷中多选题的录入与分析
2.数据分析流程的第一步:对所分析的样本数据本身的特征结构进行预分析
3.根据数据中的某个因素的几个水平来分析数据总体的差异性。
4.根据数据中的变量之间的相关性,了解数据的内部关系,并建立模型。
5.数据的降维处理。
6.结构方程模型的运用。
7.时间序列的分析,主要运用在经济模型中。
8.面板数据的处理。
* 在接单的过程中发现,SPSS主要适用于横截面数据的处理,大多数集中在问卷调查的分析上 *
* 对于时间序列的分析主要使用Eviews和Stata两个软件,面板数据的处理集中于Stata *
* 由于SPSS软件单机处理数据量受到限制,可以处理数据量不大的机器学习算法,所以个人认为处理机器学习的问题用Python处理 *
问卷中多选题的录入与分析
对于多选题的录入,常见的方法有两种:多重二分法和多重分类法。多重二分法 是指对每一个选项都定义一个变量,这些变量都是只有两个取值,分别代表选择和未选择。多重分类法就是将多选题当做单选题来选,每一个变量空格填写其中的一次选项的选择,最保险的做法就是多选题有多少个选项,就设置多少个变量
多重二分法适用于多选题选项个数不多的多选题,多重分类法适用于多选题选项数量多且有些选项几乎不被选上的情况
设定多选题变量集
由于多选题在SPSS中被判定为一个一个零散的变量,需要人为将整个多选题设置为一道多选题,此时在SPSS中的操作为:分析-多重响应-定义变量集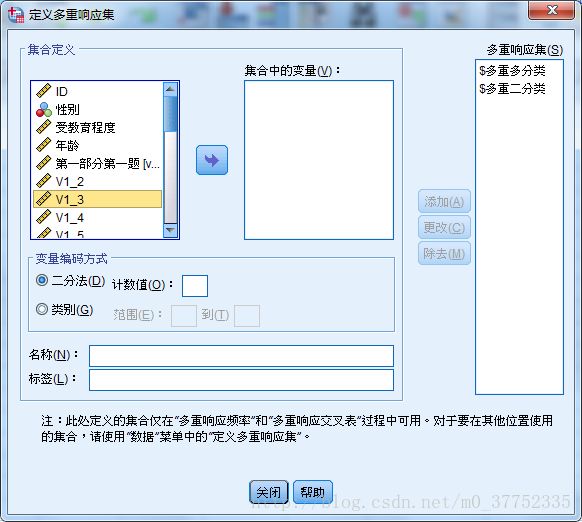
将需要组成多选题的变量选进集合中的变量,对于多重二分类问题在变量编码方式上选择二分法,计数值填写表示选中的值;对于多重多分类问题选择类别,范围填写实际问卷中的数值范围。最后将多选题的名称,对多项题解释说明的标签填写完毕后,点击添加按键,完成多选题的定义。
多选题的分析处理
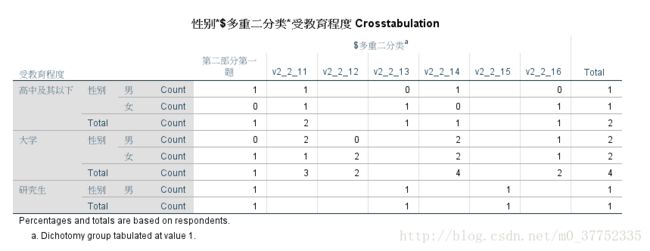
通过分析多选题中每个选项被选择频率和交叉表格。通过使用频率分析和交叉表格分析:SPPS操作为分析 - 多重响应 - 频率或交叉表格。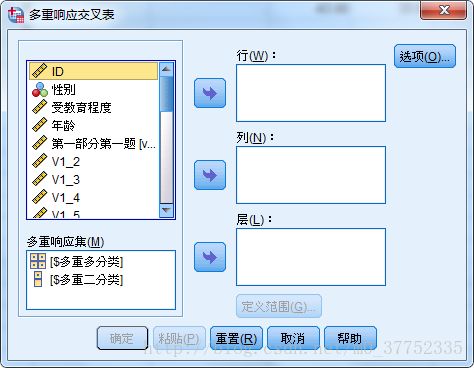
频率分析
将定义好的多重二分类多选题选入表格,并设置缺失值为在二分集内按照列表顺序排除的个案,如果是多重多分类问题,缺失值设置为在类别内按照列表顺序排除个案。
* 交叉表格分析 *
在交叉表格分析中,将问题的影响因素放入行中(例如性别的影响,学院的影响等),将多选题(多响应集)放入列,将额外层级放入层(如年级,学历等)。然后分别点击行与层内的变量,点击定义范围为其范围设定区间,如性别变量1代表男,2代表女,范围就是(1,2)。
频数分析结果
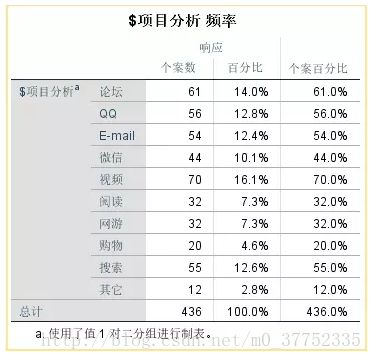
由于是多选题,一个人会选择多个观点,所以总计显示的是总观点数,其中一个观点数目/总观点数就是响应百分比,其中一个观点数目/总人数就是个案百分比。
交叉表格结果
数据分析流程的第一步:对所分析的样本数据本身的特征结构进行预分析
1.对于数值型数据,可以从数据的直方图中初步了解这个变量的数据分布形式,对于检验数据是否符合正态分布可以使用SPSS软件中的PP图和QQ图进行直观上的初步检验,进一步可以通过非参数检验中的K-S检验,通过显著性水平来检验数据是否符合正态分布性质。
直方图 在SPSS中的操作:图形 - 图形构建器
或者通过:分析 - 描述统计 - 频率
通过分析菜单中的统计描述,可以完成数值型数据的初步统计描述,包括百分位数、集中趋势、离散趋势、分布(偏度、峰度)、直方图,箱线图也是很重要描述数据分布的一种统计图表。
STEP1绘制带有正态曲线的直方图通过对比直方图与正态曲线的拟合程度,判定数据序列的分布形态是否接近正态分布。
STEP2 通过绘制Q-Q图与P-P图来从图形上检验数据是否服从正态分布。SPSS中的操作为:分析 - 描述统计 - P-P图或者Q-Q图。
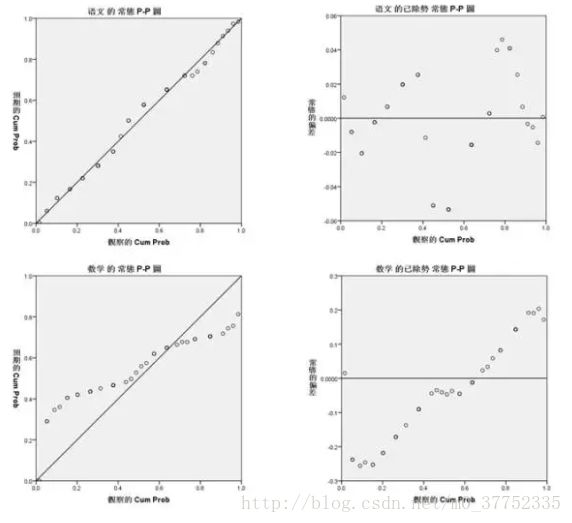
左侧两幅图中,语文成绩的散点分布与斜线拟合的较好,数学成绩的散点严重偏离斜线。右侧两幅图中,描述的是数据分布与正态分布的差值,可见语文成绩与正态分布的偏差较小,而数学成绩与正态分布的偏差较大。故此,语文成绩偏差较小,可认为是基本符合正态分布。
STEP3 通过非参数检验K-S正态检验,从定量的角度对数据的分布进行甄别。在SPSS中的操作为:分析 - 非参数检验 - 旧对话框 - 1样本K-S。
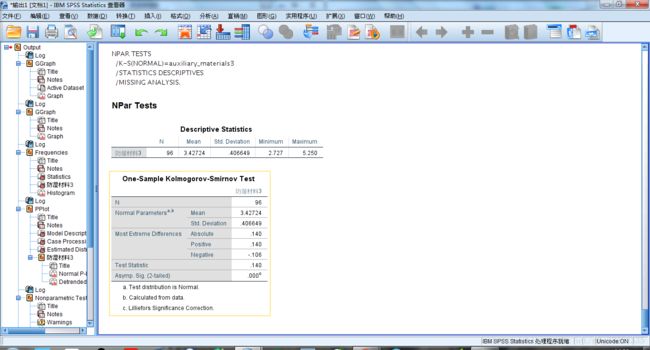
2.对于分类型数据 而言数据的分布主要是对各个类别取值分别进行频数和比例计算,在进一步计算所需的一些相对数指标。
SPSS软件中可以用到的功能:
1.频率过程:针对单个分类变量输出频数表,从中得到频数,百分比,累计百分比,众数,条形图,饼图。
2.交叉表过程:其强项在于两个或者多个分类变量的联合描述,可以产生二维至n维列联表,并计算相应的行/列/合计百分比,行/列汇总指标。
3.多重响应子菜单:适用于对于多选题的频数分析和交叉表分析。
根据数据中的某个因素的几个水平来分析数据总体的差异性
针对连续型变量的统计推断中,t-test和Anova analyse是最常用的两种方法
中心极限定理 假设有一个已知服从正态分布的总体N(u,σ^2),现对其进行抽样研究,每次抽样的样本量固定为n,这样对每一个样本均可以计算出其均数x,由于这种抽样可以进行无线多次,这些样本均数就会构成一个分布。统计学家发现,该分布正好是服从N(u,σ^2/n),为了区分样本所在总体的标准差,通常称样本均数的标准差为样本均数的标准误,简称均数标准误。即使是从偏态总体随机抽样,当n足够大时,均数x 也近似正态分布,也就是说样本容量为n的样本均数x 出现在置信区间的概率为0.95.
t-test
由于实际数据中并不知道总体的方差,通过s/√n来估计总体标准差。
SPSS中t-test的相应功能主要集中在比较均值的子菜单中。
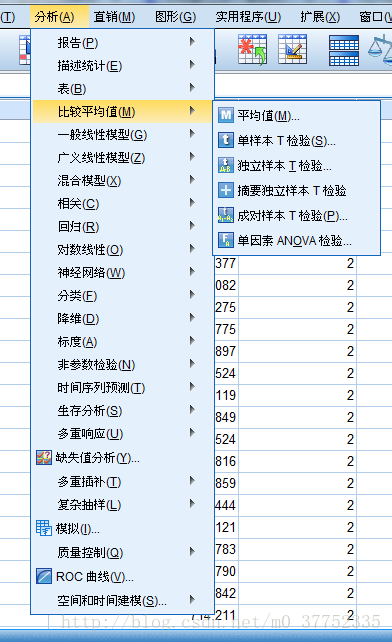
1.单样本t检验过程:进行样本均数与已知均数的比较。
2.独立样本t检验过程:进行两相互独立样本均数差别的比较,通常所说的两组资料的t检验。
3.配对样本t检验过程:进行配对资料的均数比较。
单样本t-test过程
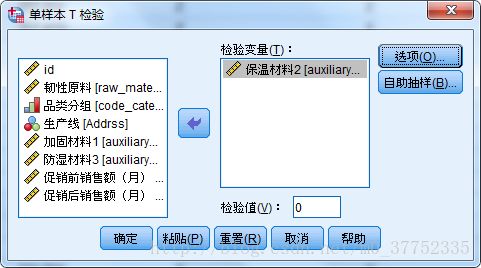
一组样本数据的均值与一个常数进行比较,判断是否存在显著差异。中心极限定理中说明,只要样本容量n足够大,均数也近似服从正态分布,所以t-test的限制条件比较少。
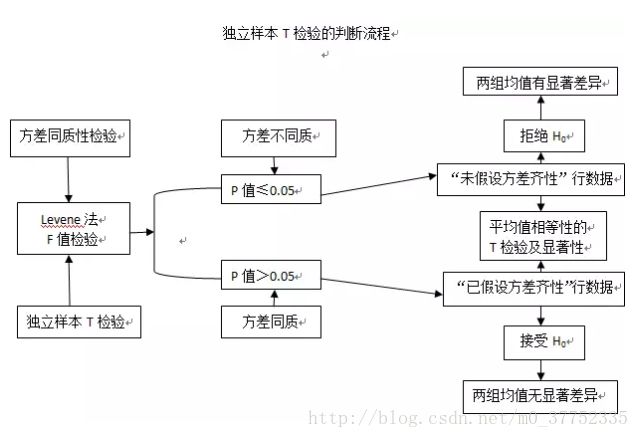
独立样本t-test
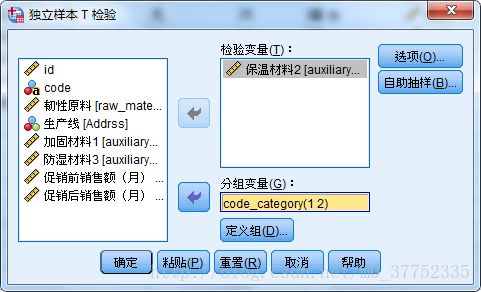
通过一个分组变量(性别),分成两个相互独立的样本,然后比较两个独立样本的均值是否存在显著差异。t-test的本质就是两两比较。
两个独立样本t检验的原假设为两个总体均值之间不存在显著性差异,需分两步完成:1.利用F检验进行两个总体方差的同质性判断;2.根据方差的同质性的判断,决定t统计量的自由度和计算公式,进而对t检验的结果给与恰当的判断。
配对样本t-test
1.一组样本处理前后
2.一组样本两种处理方法
配对t检验的基本原理是为每对数据求差值,如果两种处理实际上没有差异,则差值的总体均数应当为0。
在SPSS中的操作为:分析 - 比较平均值 - 成对样本t检验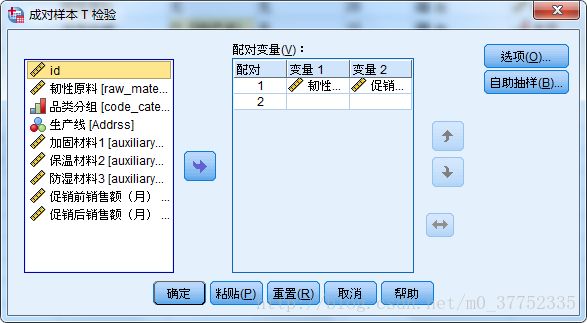
Anova analyse
Anova analyse和t-test的不同:
t-test可以解决单样本、两样本时的均数比较问题,Anova analyse所涉及的问题其实就是在单一处理因素之下,多个不同水平之间连续型观察值的比较,目的是通过对多个样本的研究来判断这些样本是否来自同一个总体。如果假设检验拒绝了多个样本来自同一个总体的假设,研究者将更加关心这几个样本到底来自于几个不同的总体,t-test则无法做到。
t-test适用于对两个样本均数的比较,Anova analyse适用于多个样本均数的比较。
方差分析的理论基础:将总变异分解为由研究因素所造成的部分和由抽样误差所造成的部分,通过比较来自于不同部分的变异,借助F检验做出推断。
Anova analyse分析的基本思路:
总变异(离差平方和)=组内变异+组间变异
组内变异来自于各组随机变异的和
组间变异来自于随机变异和处理因素导致的变异
所以通过比较组间变异与组内变异,若组间变异远大于组内变异则说明确实存在处理因素的影响。
通过构造F统计量,通过样本的数据来检验是否存在处理因素的影响。
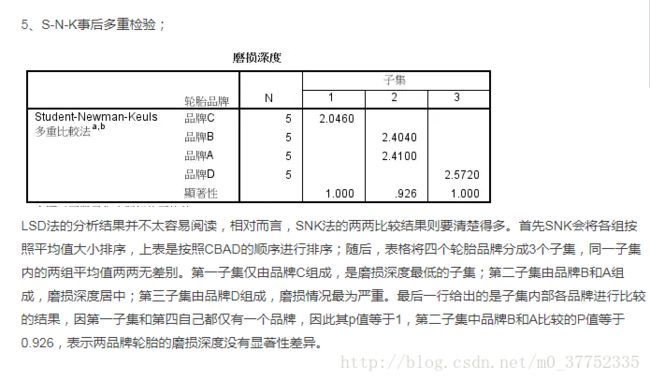
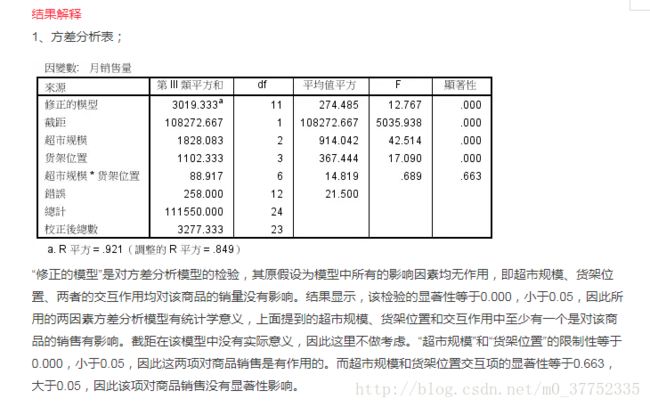
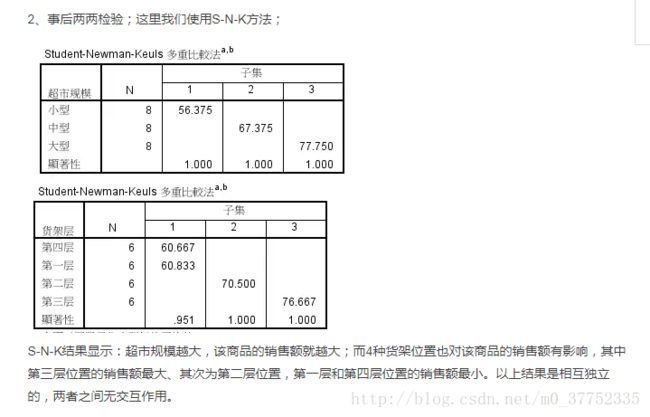
如果假设检验拒绝了原假设,可以得出多个样本不是来自同一个总体的结论。但是到底这些样本来自几个不同的总体。这次假设检验还不能回答这个问题,需要进一步进行单因素不同水平间的多重比较。
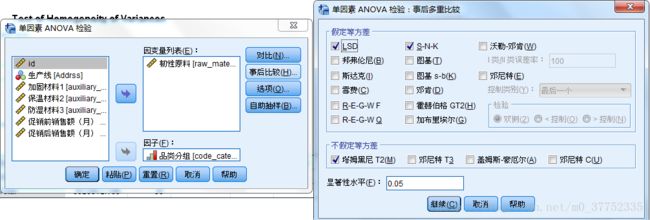
单因素Anova analyse在SPSS中的操作:分析 - 比较平均值 - 单因素Anova检验

1.因变量列表中选入需要检验的变量,可以选入多个,系统会依此检验。
2.因子选入需要研究的单因素(只能选入一个)
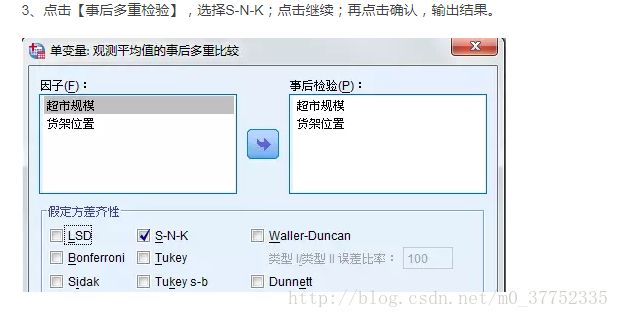
3.事后比较中假定等方差中选择LSD与S-N-K两个选项,不假定等方差选择T2。样本数量不同时候的事后检验选择雪费。
4.选项中选择方差同质性检验与平均图。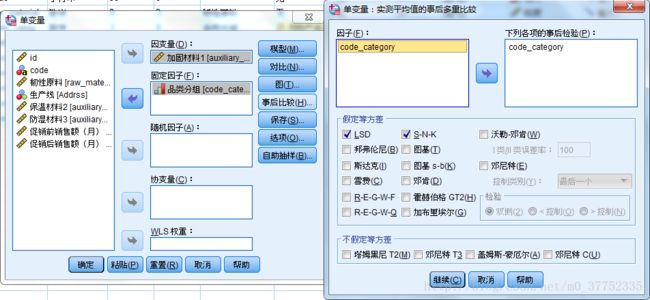
https://mp.weixin.qq.com/s?__biz=MjM5MTI5MDgxOA==&mid=2650097668&idx=1&sn=c5a0c947f11d3f1e1bdec9f7abcd3c5e&chksm=beb62ca989c1a5bf594599e44ed8aded1abd575801b1722cd9567b5bd71b6bbde9676b431776&scene=21#wechat_redirect
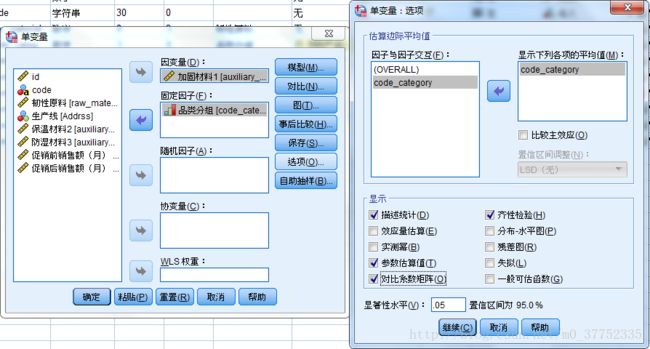
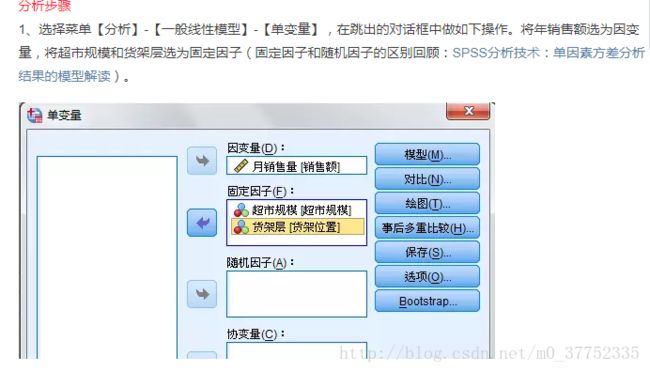
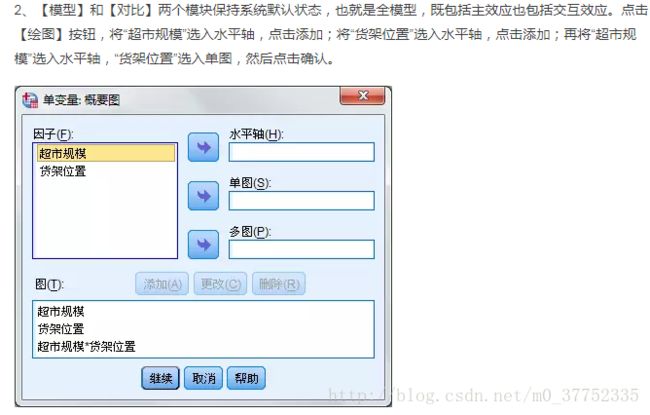
两因素Anova analyse在SPSS中的操作:分析 - 一般线性模型 - 单变量
固定因子指样本中将因子的各种情况都出现过,随机因子指样本中并没有将各种情况都列出
含随机因素的方差分析
固定因子与随机因子的区别
固定因素指的是该因素在样本中所有可能的水平都出现了。换言之,该因素的所有可能水平仅此几种,针对该因素而言,从样本的分析结果中就可以得知所有水平的状况,无需进行外推。比如要研究三种促销手段的效果有无差别,所有样本只会是三种促销方式之一,不存在第4种促销手段的问题,则此时该因素就被认为是固定因素。
随机因素指的是该因素所有可能的取值在样本中没有全部出现。换言之,目前在样本中的这些水平是从总体中随机抽样而来,如果重复本研究,则可能得到的因素水平会和现在完全不同,这时,研究者显然希望得到的是一个能够“泛化”,即对所有可能出现的水平均适用的结果。例如研究广告类型和投放的城市对产品销量是否有影响,在设计中随机抽取了20个城市进行研究,显然,研究者希望分析结果能够外推到所有类型的城市,此时就涉及将结果外推到抽样未包括的城市中的问题,在这种情况下,城市就应当是一个随机因素。
在SPSS中的操作为:分析 - 一般线性模型 - 单变量
因变量选入需要研究的变量
固定因子选入所有可能的水平都出现的因子。
随机因子选入所有可能的取值在样本中没有全部出现