yolo学习之自适应anchor
一、前言
参考:
(1条消息) yolov5的anchor详解_anny_jra的博客-CSDN博客_yolov5 自动anchor
(1条消息) YOLOv5模型网络结构简单理解及详解anchor设置_aabbcccddd01的博客-CSDN博客_yolov5网络结构详解
YOLOv5中autoanchor.py的def metric(k)的r = wh[:, None] / k[None]的理解_Taylor不想被展开的博客-CSDN博客
目标检测 YOLOv5 anchor设置 - 知乎 (zhihu.com)
yolov5 自适应 anchor - 贝壳里的星海 - 博客园 (cnblogs.com)
yolov5 anchors设置详解_高祥xiang的博客-CSDN博客_yolov5自适应锚框
这个参考链接我觉得非常棒!
我这里不再详细去看。我这里主要是对anchor_t这个阈值设置进行理解和学习
coco数据集中的gt的长宽比最大为为1:4,即anchor_t设置为4
二、check_anchors()内metric()函数
def check_anchors(dataset, model, thr=4.0, imgsz=640):
"""在train.py中调用,计算BPR确定是否需要改变anchors 需要就调用K-means重新计算anchors
args: dataset -> 自定义数据集LoadImagesAndLabels返回的数据集
model -> 初始化的模型
thr -> 超参数,界定anchor与label匹配程度的阈值,anchor与标签框的比例范围为(1/thr, thr),在此范围内算是满足要求
imgsz -> 输入图片尺寸,默认640"""
# Check anchor fit to data, recompute if necessary
# 打印字符串:autoanchor:Analyzing anchors...
prefix = colorstr('autoanchor: ')
print(f'\n{prefix}Analyzing anchors... ', end='')
# 取出模型最后一层,即Detect层
m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
# dataset.shapes.max(1, keepdims=True) = 每张图片的较长边
# shapes: 将数据集图片的最长边缩放到img_size, 较小边相应缩放,得到新的所有数据集图片
shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
# 产生随机数scale [2501, 1]
scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
# 将GT的归一化坐标缩放为基于图片大小为shapes * scale的坐标
wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
def metric(k): # compute metric
"""根据wh计算anchor是否满足要求,即anchor与标签框的比值要在(1/thr, thr)
args:k -> 一般传入的是anchors的宽高 [M, 2],也可传入GT的宽高wh: [N, 2],M为anchor的数量,作者M取9,N为GT的数量
return:bpr -> best possible recall 最多能被召回(通过thr)的gt框数量/所有gt框数量,小于0.98 才会用k-means计算anchor
aat -> anchors above threshold 每个target平均有多少个anchors
"""
r = wh[:, None] / k[None]
# x:高宽比和宽高比的最小值,无论r大于1,还是小于等于1,最后统一结果都要小于1 [N, M]
x = torch.min(r, 1. / r).min(2)[0] # ratio metric
best = x.max(1)[0] # best_x
aat = (x > 1. / thr).float().sum(1).mean() # anchors above threshold
bpr = (best > 1. / thr).float().mean() # best possible recall
return bpr, aat从这里看到是说:
thr(即anchor_t)是界定anchor和gt label匹配程度的阈值,anchor与标签框的比例范围为(1/thr, thr),在此范围内算是满足要求。
这个超参数是一个界定anchor和gt label的匹配程度的阈值!这9类anchor的宽高和gt框的宽高之间的差距。
r = wh[:, None] / k[None]这个就是gt label的宽和高,分别除以当前已有anchor的宽和高。(这个除是经过广播机制后才可以进行的,否则维度不匹配!),
这个gt label的宽和高与anchor的宽和高越接近,越匹配,则其比值越接近1!
当然注意:会有大于1的情况,比如新的一批数据shape为100*100,但是我们的anchor中有一个
(w,h) =(140,300)这时相除r中就会出现小于1的数,如果shape为1000*1000,则r就会出现大于1的数!
x = torch.min(r, 1. / r).min(2)[0]这个x就是高宽比和宽高比的最小值。x的shape[N, 9]
x:高宽比和宽高比的最小值,无论r大于1,还是小于等于1,最后统一结果都要小于1 。其实要想获得小于1的结果,也可以先判断gt label的宽w1和高h1与anchor的宽w2和高h2,相除前,判断w1和w2的大小,总是拿小的除以大的;判断h1和h2的大小,总是拿小的除以大的。这样跟
r = wh[:, None] / k[None]
torch.min(r, 1. / r)的做法是一样的!
best = x.max(1)[0]这里的best也就是对本来小于的x求x中的最大值,best的shape是[N]
1)变量wh用来存储训练数据中所有gt框的宽高,是一个shape为(N,2)的tensor,N为gt框的总的个数
2)输入k是一个shape为 (9,2) 表示 anchors的宽和高两个维度
3)通过anchor和wh来计算bpr,aat(anchors above threshold) 两个指标,来判断是否满足
- bpr(best possible recall): 最多能被召回的gt框数量 / 所有gt框数量
- 最大值为1 越大越好 小于
- 0.98就需要使用k-means + 遗传进化算法选择出与数据集更匹配的anchors框。
wh[:, None]的shape是[N, 2]变[N, 1, 2]
k[None]的shape是[9,2]变[1, 9, 2]
gt_height / anchor_height
gt_width / anchor_width
有可能大于1,也可能小于等于1
x = torch.min(r, 1. / r).min(2)[0]无论r大于1,还是小于等于1最后统一结果都要小于1
x的shape[N,9]
best的shape是[N],表示9个anchors长宽与GT长宽比值最接近1的比值
wh(gt)的shape是[N, 2]表示N个gt box和和宽高这2个维度
k(anchor)的shape是[9,2]表示YOLOv5中的9种anchor和宽高这2个维度
r = wh[:, None] / k[None] 表示
先扩展维度
wh[:, None]的shape是[N, 2]变[N, 1, 2]
k[None]的shape是[9,2]变[1, 9, 2]
gt_height / anchor_height
gt_width / anchor_width
有可能大于1,也可能小于等于1
r的shape是[N,9,2]。9是YOLOv5中的9种anchor
x = torch.min(r, 1. / r).min(2)[0]
无论r大于1,还是小于等于1最后统一结果都要小于1
x的shape[N,9]
best的shape是[N],表示9个anchors长宽与GT长宽比值最接近1的比值
注意:
1、None用以添加维度,所有GT的wh[:, None],[N, 2]->[N, 1, 2],所有anchor的wh即k[None] [M, 2]->[1, M, 2]
2、r:GT的宽高与anchor的宽高的比值,即h/h_a, w/w_a,r.shape=(N, M, 2),r中元素有可能大于1,也可能小于等于1
3、为什么要添加维度:原来的维度是[N, 2]、[M, 2],无法相除,因为不满足广播机制,但是增加维度后就可以满足了广播原则的条件
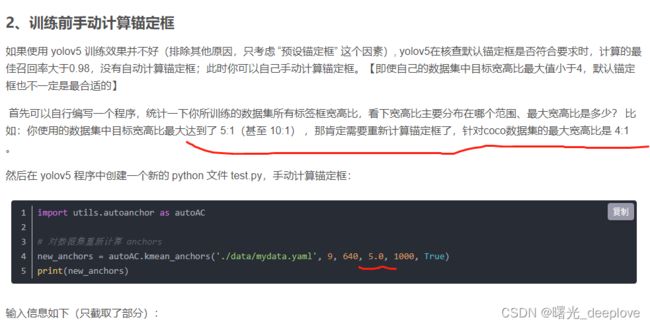
根据以上链接也可以看到:我们在自己的数据集上训练时需要提前估算出该数据集的最大宽高比,
设置anchors_t(其他的fintune.yaml文件中都有体现),否则会计算bgr以及kmeans_anchor中的遗传算法不准确!!!
v5中的labels.jpg就有体现:
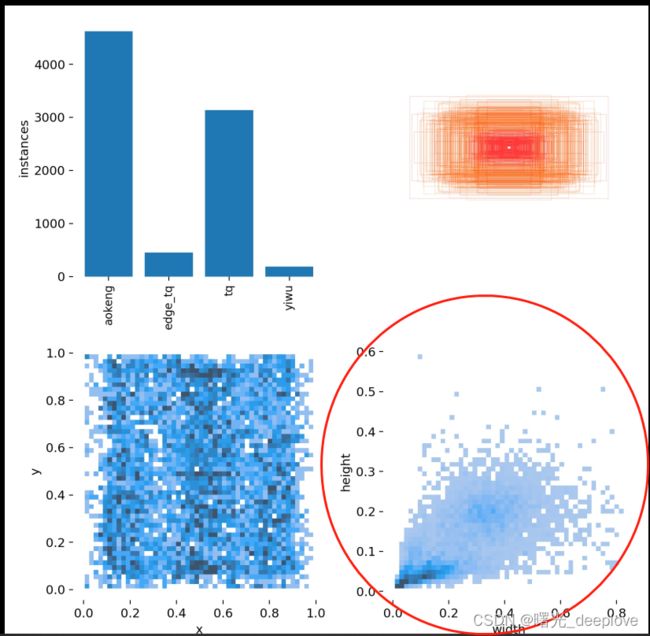
可以看到我们的数据集的gt中的最大宽高比绝对不是跟coco一样的1:4
注意:
此外从上面的代码也得到领悟,微调时,首先会加载一个前面训练好的模型model,然后根据这个model直接拿到其中含有的anchor,这个anchor就是上次训练模型所使用的anchor。那么针对现在需要微调的几张图,根据bgr和att,判断是否需要重新聚类获取新的anchor。我这边理解,如果不需要聚类那么是最好的,说明这个anchor对于旧的数据和新的待微调的数据都是适用的,如果
重新聚类了,那就很麻烦了,说明前面的anchor对当前带微调数据不适用,这样只在待微调数据上聚类出来的anchor,虽然可以很好用在待微调数据上,但是这个anchor却对旧数据没法再适用,会得不偿失,没法泛化旧数据了!!!