论文阅读 - Domain-Aware Federated Social Bot Detection with Multi-Relational Graph Neural Networks-CCF C
目录
摘要
1 绪论
2 相关工作
3 方法
4 实验与评估
5 总结
论文链接:Domain-Aware Federated Social Bot Detection with Multi-Relational Graph Neural Networks | IEEE Conference Publication | IEEE Xplore
摘要
背景:社交网络已成为广泛流行的交流和社交工具,也是机器人发布恶意信息的理想平台。因此,社交机器人检测对于社交网络的安全至关重要。
gap: 现有方法几乎忽略了多个领域中机器人行为的差异。
本论文模型:作者首先提出了一种具有多关系图神经网络(DA-MRG)的领域感知检测方法来提高检测性能。
具体来说:(1)DA-MRG 构建具有用户特征和关系的多关系图 ——> 通过图嵌入获得用户表示;
(2) 并通过域感知分类器将机器人与人类区分开来;
(3)同时,考虑到不同社交网络中机器人行为之间的相似性,作者认为在它们之间共享数据可以提高检测性能。但是,需要严格保护用户的数据隐私;
(4)为了克服这个问题,作者对 DA-MRG 的联邦学习框架进行了研究,以实现不同社交网络之间的数据共享并同时保护数据隐私。
效果:在 TwiBot-20 上进行了广泛的实验,结果表明所提出的方法可以有效地实现联邦社交机器人检测。
1 绪论
背景: 如今,社交网络已成为人们交流和社交的必要平台,也是发布信息必不可少的。由于其广泛流行和开放性,它是机器人实现恶意目标的理想平台。这些机器人账号散布假新闻,宣扬极端意识形态[1],还试图模仿普通用户隐藏自己的行为。因此,社交网络迫切需要有效的机器人检测方法。
前人研究: 最近的工作通常从用户档案中提取特征,并采用神经网络(如 RNN 和 GNN)来获得用户呈现,这些呈现将适合二元分类器(人类与机器人)。
gap 1:根据我们的观察,不同领域的机器人总是具有不同的特征。
案例:如图1所示,政治领域的真实样本机器人习惯性地关注政治话题,其邻居也在同一领域。
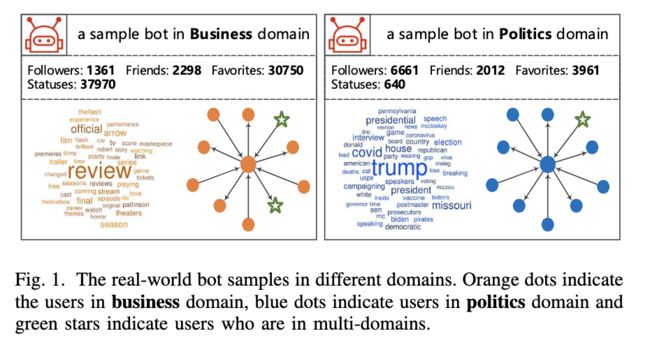
(不同领域的真实机器人样本。橙色圆点表示商业域用户,蓝色圆点表示政治域用户,绿色星表示多域用户)
案例分析:相比之下,商业领域中的示例机器人关注日常主题并与商业用户进行交互。因此,作者相信不同领域机器人的多样性可以帮助区分人类和机器人,这在现有方法中很少考虑。
gap 2: 除此之外,因为不同社交网络中的特定领域机器人总是具有相似的行为,在多个社交网络之间共享数据将提高检测方法的准确性;
问题:然而,由于数据隐私保护的要求,直接聚合来自所有社交网络的大量数据来实现集中训练几乎是不可能的。
解决方案:因此,有必要提高机器人检测方法在多个社交网络之间交换信息的能力,同时保护数据隐私。作为一种有效的方法,联邦学习已被提出来处理由数据隐私引起的数据孤岛问题[2],并取得了显著成就。然而,正如作者所知,它还没有被引入到社交网络中的机器人检测中。因此,作者的工作重点是处理联邦社交机器人检测。
总结:为了解决上述问题,我们提出了一种领域感知的联邦社交机器人检测方法。
首先,根据图1中的观察,获得基于多关系图神经网络的用户呈现,并设计领域感知分类器,以促进检测性能;
其次,采用联邦学习框架来平衡社交网络之间的数据共享和数据隐私保护;
使用真实数据集评估所提出的模型,结果表明模型优于可比较的基线模型;
值得注意的是,联邦学习框架中模型的检测性能可以达到与集中训练几乎相同的水平。
作者工作的主要贡献如下:
作者是第一个在社交网络中提出联邦机器人检测的人,它将联邦学习引入到社交机器人检测中,以便在不同社交网络之间共享数据,同时保护数据隐私;
作者构建多关系图并融合账户的领域感知知识以提高检测性能。此外,模型采用了联邦学习框架来克服数据隐私保护的挑战。
在 TwiBot-20 上进行了大量实验,结果表明所提出的方法可以有效提高社交机器人检测的准确性。模型在联邦学习框架中也实现了与集中训练和其他并行训练相当的性能。
本文的其余部分组织如下:
第二部分回顾了社交机器人检测和联邦学习的相关工作。模型的框架和组件在第三节中描述。数据集、实验设置和结果见第四节。最后,在第五节对本文进行总结。
2 相关工作
在本节中,简要回顾一下社交机器人检测、图神经网络和联邦学习的相关研究工作。
A. 社交机器人检测
早期的机器人检测方法从用户资料 [3]-[5]、推文 [6] 等中提取特征,并应用传统分类器(如随机森林模型 [7])来检测社交网络中的机器人;
此外,高等人 [8] 识别六个特征并采用增量聚类来实时区分垃圾邮件活动;
托马斯等人[9] 设计了一个实时系统来确定 Web 服务中的 URL 是否直接指向垃圾邮件内容;
上述所有这些都可以被认为是特征工程方法。
由于深度学习的突出成就,越来越多的基于神经网络的检测模型被提出。
库杜贡塔等人[10] 利用 LSTM 架构来检测机器人,并同时考虑推文上下文特征和来自用户元数据的上下文特征;
同样,魏等人 [11] 采用带有词嵌入的 BiLSTM 来捕获推文中的特征并将机器人与人类账户区分开来;
SpamGAN[12]是一个生成式对抗网络,依靠一组有限的标记数据和无标记数据 进行垃圾邮件检测;
SATAR [13],一种用于机器人检测的自我监督表示学习框架,共同利用特定用户的语义、属性和邻域信息;
最近,研究人员提出了通过具有多重关系的图结构的检测方法[14],[15];
阿里等人 [16] 首次尝试将图卷积网络应用于机器人检测;
冯等人 [14] 构建了一个异构信息网络,并利用关系 GNN 来获取用于机器人检测的用户表示。然而,这些方法几乎忽略了用户的领域信息,这对我们观察到的任务很重要。
B. 图神经网络
图神经网络(GNN)旨在基于消息传递机制在低维空间中生成节点的表示。
经典方法:如 GCN [17]、GraphSAGE [18] 和 GAT [19],通过聚合其邻居的特征来生成节点的表示。特别是 GraphSAGE 对邻居进行采样以拟合大图,而 GAT 采用注意力机制来衡量邻居的重要性。同时,一些工作[20]-[23]认为图的局部结构特征对于保存节点表示中的空间信息是有价值的。
考虑到图中节点和关系的不同类型,异构信息网络(HIN)和多关系图的 GNN 框架在社区检测和异常检测等各种应用中得到了广泛的研究并取得了显着的成功:
LUCE [24] 应用 HIN 对房屋实体之间的多重关系进行建模以用于房地产价格预测任务;
FRAUDRE [25] 以多关系图作为输入来预测欺诈者和普通用户的标签;
FinEvent [26] 采用一种用于社交事件检测的加权多关系图神经网络。
基于多关系图可以更明确地区分关系类型 [27]、[28] 的阐述,作者在社交机器人检测模型中构建了多关系图。
C. 联邦学习
针对日益增多的数据隐私问题,谷歌首先提出了联邦学习的概念,基于来自多个设备的数据集构建机器学习模型,同时实现数据隐私保护[29]、[30]。此外,杨等人[31] 对横向联邦学习、纵向联邦学习和联邦迁移学习的综合联邦学习框架进行了总结。
随着联邦学习的进步,研究人员提出了一些实用的算法,如 FedAvg、FedAMP、FedProx、FedNova 和 FedMV,并已应用于各个领域 [32]-[35]。
FedAvg [36] 是联邦学习的基本且经过充分研究的算法,其中全局模型是通过对在私人客户端数据集上训练的局部模型的参数进行平均来学习的;
FedProx[37]使用一个近似的术语来概括和重新参数化FedAvg;
FedAMP[38]提出利用联盟的周到的消息传递来促进具有类似数据的客户之间的配对协作;
FedNova [39] 是一种归一化平均方法,可消除客观不一致性,同时保持快速误差收敛;
FedMV [40] 为多视图数据提出了一个联合框架,其中参与者具有不同类型的本地数据可用性;
由于 FedAvg 的效率,在本文中,作者主要遵循 FedAvg 的思想来实现用于 bot 检测的联邦学习框架。
3 方法
A. 概览
在本节中,作者提出了一个名为 DA-MRG 的用于机器人检测的框架。
作者首先从初始用户特征和任务的原始图构建多关系图;
然后,设计了一个由一系列图嵌入层和语义注意层组成的用户表示学习模块,以获得每个用户的表示;
最后,作者提出域感知分类器来区分机器人和人类;
方法的整体架构如图 2 所示。此外,为 DA-MRG 引入了一个联邦学习框架,以实现多个参与者之间的联合训练。
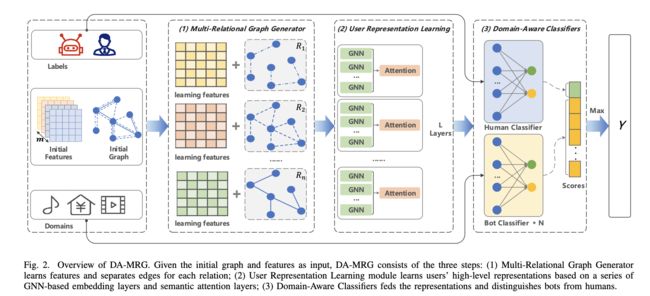
(DA-MRG 概述。给定初始图和特征作为输入,DA-MRG 包括三个步骤: (1) 多关系图生成器学习特征并为每个关系分离边; (2) 用户表示学习模块基于一系列基于 GNN 的嵌入层和语义注意层来学习用户的高级表示; (3) 领域感知分类器提供表示并将机器人与人类区分开来。)
B. 多关系图生成器
符号介绍:在社交网络中,作者可以根据用户之间的交互行为得到一个多关系图 G = {V,X,E,Y },其中 V = {v1,v2,...,vn} 是用户节点,X是所有用户节点的初始特征,n是用户数。![]() 是 vi 和 vj 之间的一条边,关系为 r ∈{1,...,R},表示用户 i 和用户 j 之间的交互行为。例如用户 i 关注用户 j 或用户 i 评论用户 j,Y 是所有用户的标签集。
是 vi 和 vj 之间的一条边,关系为 r ∈{1,...,R},表示用户 i 和用户 j 之间的交互行为。例如用户 i 关注用户 j 或用户 i 评论用户 j,Y 是所有用户的标签集。
然后,作者提出了一个多关系图生成器来为原始图 G 生成关系图 ![]() 。该生成器由边缘分离和特征学习组成。
。该生成器由边缘分离和特征学习组成。
边缘分离: 作者首先通过在整个图中保留用户之间的关系 r 来生成所有关系图![]() 。因此,Gr 中的边集是 Er;
。因此,Gr 中的边集是 Er;
作者将 Er 中每条边 ![]() 的两个节点添加到节点集 Vr 中,就像节点的特征和标签一样。关系图 Gr 可以表示为:
的两个节点添加到节点集 Vr 中,就像节点的特征和标签一样。关系图 Gr 可以表示为:
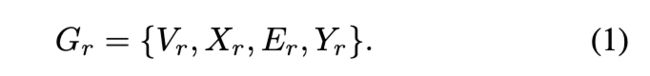
特征学习: 假设同一用户的特征对不同的关系图有不同的影响,作者独立地学习每个关系图的特征:
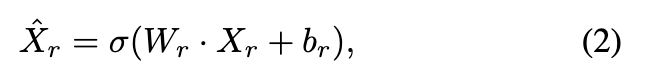
其中 Xr 是 Gr 中节点的初始特征,σ(·) 是非线性.
C. 用户表征学习模块
在本模块中,作者通过一系列的图嵌入层和语义注意层来获得每个用户的最终高级表示。
首先通过多个基于gnn的图嵌入层获得所有关系图中每个节点的表示;
然后,基于语义注意网络对每个节点的表示进行聚合,以实现最终的嵌入。
多关系图嵌入层:首先构建一个基于 GNN 的图嵌入层,以获得该模块中每个关系图 Gr 中特定节点的表示,如下所示:
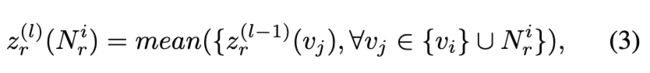
其中 ![]() 是 vi 在 Gr 中的 1 跳邻域的集合,
是 vi 在 Gr 中的 1 跳邻域的集合,![]() 是 vj 在第 (l − 1) 层 GNN 中的表示。使用节点特征
是 vj 在第 (l − 1) 层 GNN 中的表示。使用节点特征 ![]() 作为第 0 层的初始表示。然后,在第 l 层 GNN 中获得 vi 的表示,如下所示:
作为第 0 层的初始表示。然后,在第 l 层 GNN 中获得 vi 的表示,如下所示:
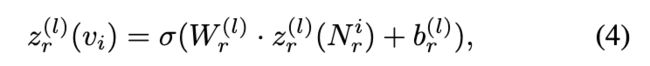
![]() 被用作基于 GNN 的嵌入层中 vi 的最终表示.
被用作基于 GNN 的嵌入层中 vi 的最终表示.
语义注意层: 每个用户节点在多个关系图中的表示是通过多个基于 GNN 的嵌入层获得的。考虑到关系的不同重要性,采用语义注意层来融合每个用户节点的所有表示。
首先,为关系 r 引入一个关系偏好向量![]() 。对于特定关系 r 中 vi 的表示
。对于特定关系 r 中 vi 的表示 ![]() ,分配给
,分配给 ![]() 的权重取决于
的权重取决于 ![]() 和
和 ![]() 之间的相似性。为了获得权重,我们首先将 d 维
之间的相似性。为了获得权重,我们首先将 d 维 ![]() 转换为 d' 维
转换为 d' 维 ![]()
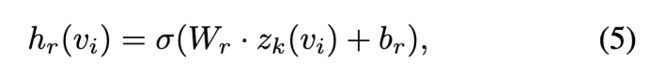
其中 σ(·) 是非线性的,在论文中使用 tanh。然后,计算 ![]() 和
和![]() 之间的相似度如下:
之间的相似度如下:
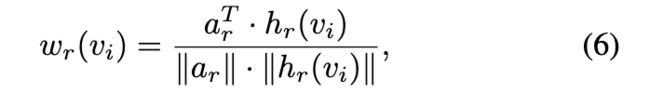
其中∥·∥是向量的L2归一化。分配给节点 vi 的关系 r 的权重使用 softmax 进行归一化,如下所示:
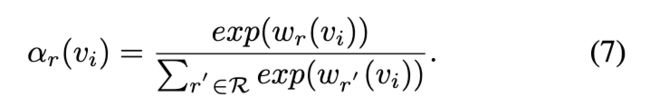
最后,融合节点 vi 在所有关系中的表示:
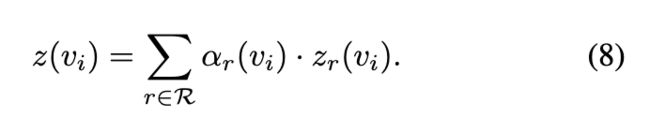
D. 领域感知分类器
在用户表示学习模块之后,获得每个用户节点 v 的最终高级表示 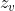 。通常,现有方法将检测任务视为二元分类,并将节点的表示馈送到多重全连接神经网络以获得预言:
。通常,现有方法将检测任务视为二元分类,并将节点的表示馈送到多重全连接神经网络以获得预言:
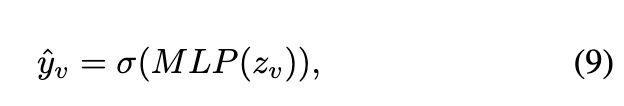
其中 σ(·) 表示激活函数,![]() 是节点 v 的预测标签。此外,交叉熵被用作优化器。
是节点 v 的预测标签。此外,交叉熵被用作优化器。
受观察到不同领域的社交机器人有明显差异的启发,作者提出了领域感知分类器来提高检测性能。
具体来说,首先为每个域 ![]() 训练一个机器人分类器:
训练一个机器人分类器:
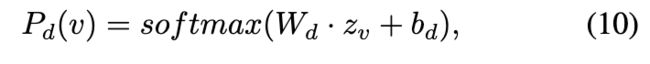
其中 ![]() 表示 v 在域 d 中的机器人概率。然后,获得 v 的机器人概率如下:
表示 v 在域 d 中的机器人概率。然后,获得 v 的机器人概率如下:
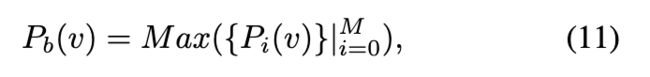
其中 M 是域的数量。同样,训练人类分类器
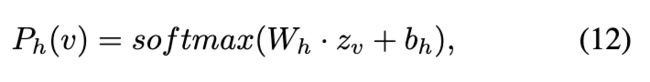
其中 ![]() 表示 v 的人类概率。因此,获得预测标签为
表示 v 的人类概率。因此,获得预测标签为![]() 并将最终预测的机器人概率确定为:
并将最终预测的机器人概率确定为:
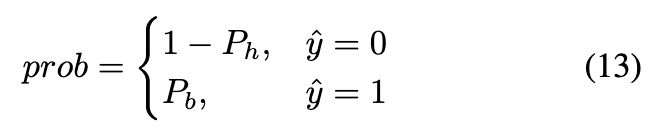
E. 联邦学习
由于数据隐私问题,无法从多个社交网络服务(SNS)收集数据以进行集中式模型训练。因此,作者引入了一个联邦学习框架来解决这个问题。每个参与模型训练的 SNS 从服务器下载全局模型,用自己的数据进行训练,并将训练好的模型上传到服务器,服务器聚合来自所有参与者的模型。
具体来说,假设每轮有 K 个 SNS 参与联邦学习,第 k 个参与者根据公式14 计算第 t 轮中模型的局部梯度:

其中 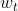 是第 t 轮从服务器下载的全局参数,每个参与者在本地更新自己的参数如下:
是第 t 轮从服务器下载的全局参数,每个参与者在本地更新自己的参数如下:
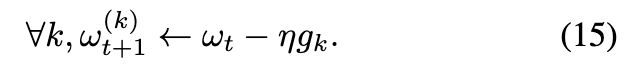
然后,服务器将从所有参与者上传的本地参数聚合为等式16:
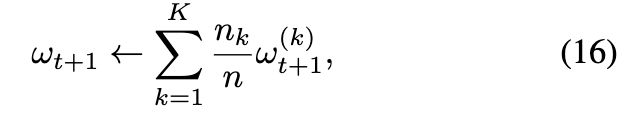
其中 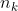 是第 k 个参与者的数据大小,
是第 k 个参与者的数据大小,![]() 分配给第 (t + 1) 轮的每个参与者。详情如图 3 所示。
分配给第 (t + 1) 轮的每个参与者。详情如图 3 所示。
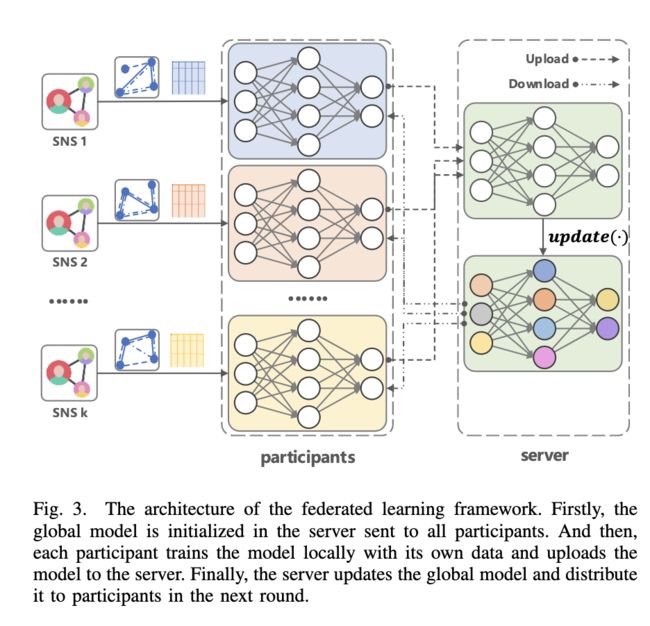
(联邦学习框架的架构。首先,全局模型在服务器中初始化并发送给所有参与者。然后,每个参与者使用自己的数据在本地训练模型并将模型上传到服务器。最后,服务器更新全局模型并将其分发给下一轮的参与者 )
联邦学习框架结合提出的模型 DA-MRG 来实现跨多个社交网络的社交机器人检测。作者专注于探索参与者的数量和每个参与者的数据量的影响。方法的整体过程如算法1所示:

4 实验与评估
A. 数据集
因为 DA-MRG 需要用户的多关系图,作者在 TwiBot-20 [41] 上评估方法,这是所知道的唯一具有用户关注关系的公开可用的机器人检测数据集。
该数据集包含 5,237 个人工帐户和 6,589 个机器人帐户及其属性项、推文和关注帐户;
除此之外,所有帐户通常可以分为四个领域:政治、商业、娱乐和体育;
B. 基线
首先,将提出的模型 DA-MRG 与一些现有的社交机器人检测方法进行比较。
Lee et al.[3]和Yang et al.[5]都使用带有用户特征的随机森林分类器来检测社交中的机器人;
Miller等人[4]从用户推文和属性中提取特征,并提出了一种改进的流聚类算法来识别bot账户;
Cresci等人[6]将用户的在线行为编码为数字DNA序列,并应用DNA分析技术来区分真正的和垃圾邮件账户;
Botometer [7] 是一种公共在线服务,它利用一千多个特征对账户进行分类;
Kudugunta等人[10],Wei等人[11]和SATAR[13]从用户推文、元数据等中提取特征,并利用循环神经网络发现bot账户;
Ali等人[16]和BotRGCN[14]基于用户关系构建图,利用图神经网络获取用户表示,以区分机器人和人类;
特别是,这些基线方法的结果来自 BotRGCN [14]。
同时,为了验证模型在 FedAvg 中的有效性,将框架与以下方法进行了比较:
本地训练:意味着通过自己的数据在每个参与者本地训练 DA-MRG,参与者之间没有任何交互。实验中每个参与者的数据是整个训练集的一个子集,生成为第 IV-C 节;
CDS [42] 是一种集中式机器学习策略,通过收集所有参与者的数据在中央服务器上训练 DA-MRG;
CIIL [42],[43] 在每个参与者本地训练模型,训练周期一致,并反复循环遍历所有参与者。
C. 实施细节
选择关注者和关注作为构建DA-MRG的多关系图;
此外,考虑到计算成本和模型中的参数数量,作者采用GraphSAGE[18]作为用户表示学习模块中的图神经网络。
此外,为了评估带有DA-MRG的联合学习框架,作者为每个参与者随机分配了一个独特的子集。
首先,将整个训练集平均分为 12 部分,并在 {4,8,12} 处测试参与者数量的训练效果;
然后,为了测试数据量的训练效果,将参与者的数量固定为 8,并将每个参与者的数据量从 100 增加到 2000。
评估方式:采用 Accuracy、F1-score 和 MCC 来估计在所有实验中的方法。
模型训练的常用参数设置为学习率 5e-4、batch size 256、dropout 0.3、L2 正则化权重 λ 3e -5 和最终嵌入的维度 32;
所有实验均在 64 核 Intel ( R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz,128GB RAM 和 Tesla P100-PICE GPU,16GB 内存。模型是使用 pytorch 1.8.1 作为后端实现的。
D. 实验结果
在本节中,首先评估 DA-MRG 在 TwiBot-20 [41] 上的检测性能,并研究领域感知分类器的有效性和关键实验设置的影响。然后,与其他训练策略相比,使用联邦学习框架估计模型的性能。在实验中,性能被报告为最好的结果。
1) 性能比较:表 I 中显示的结果表明 DA-MRG 在 TwiBot-20 上获得了比所有其他比较方法更好的准确度、F1-score 和 MCC。一般来说,基于深度学习的方法通常比基于特征工程和传统机器学习的方法表现更好。虽然都是基于图神经网络,但模型方法比 Ali 等人有明显的改进。[16]和BotRGCN [14],初步说明DA-MRG更好地利用账户的域信息进行机器人检测。
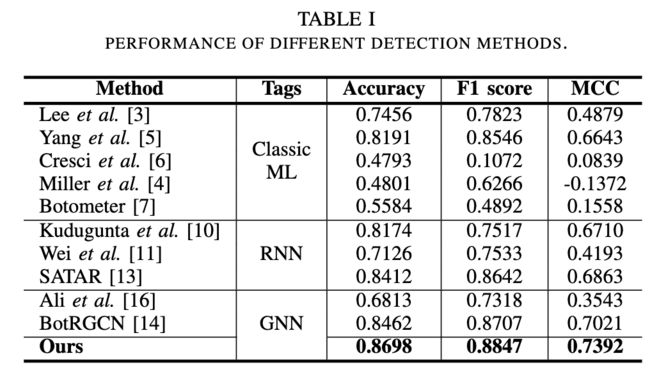
2)训练比率分析:模型在不同训练比率下的性能如图4所示。结果表明,随着训练比率的降低,模型性能略有下降,这意味着一小部分标记数据是模型足够了。该方法在 60% 的训练数据上优于所有其他比较方法
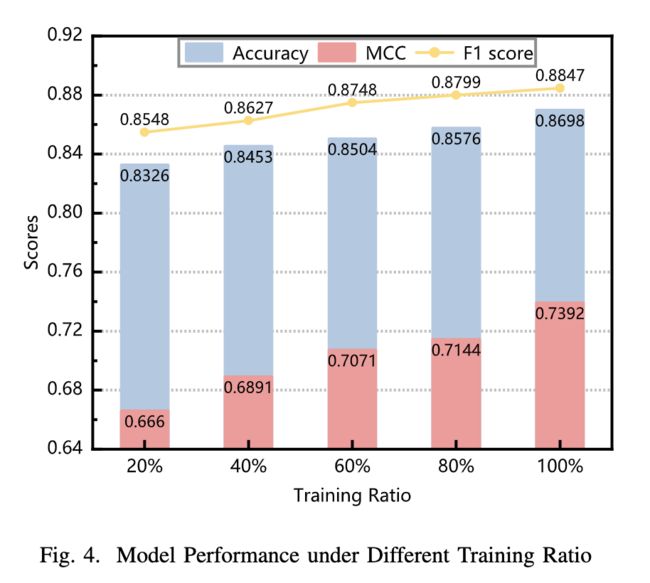
3)消融研究:与其他基于 GNN 的方法相比,该模型应用用户的域信息来辅助分类。因此,进行消融研究以评估该模块的有效性。图 5 中的结果表明,当删除域感知分类器时,所有指标都会有一些损失,尤其是 MCC。它表明域信息对于提高检测性能确实很有价值
4)参数敏感性:在本节中,研究参数如何影响预测性能。结果报告在图6中
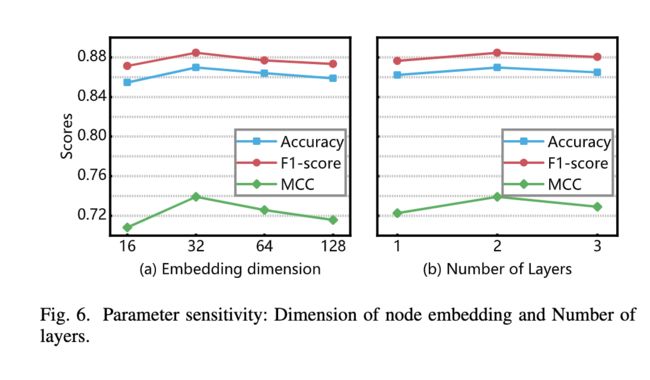
节点嵌入的维度。考虑到节点嵌入的维度决定了基于 GNN 的方法的表示能力,作者首先探讨了各种维度 {16、32、64、128、256} 的影响。图 6 (a) 表明结果在 32 维时达到最佳性能,然后随着维数的增加而退化。作者认为更大的维度可能会引入过多的无价值信息。
用户表示层数。将用户表示学习模块中的层数从 1 更改为 3,并评估其对预测性能的影响。如图 6 (b) 所示,2 层用户表示学习在我们的模型中可以获得更好的结果,而 3 层可能会面临过拟合。
5)联邦学习研究:在本节中,作者在两个实验中评估 DA-MRG 结合联邦学习框架的性能,固定参与者的数量并固定本地训练集的数据大小。
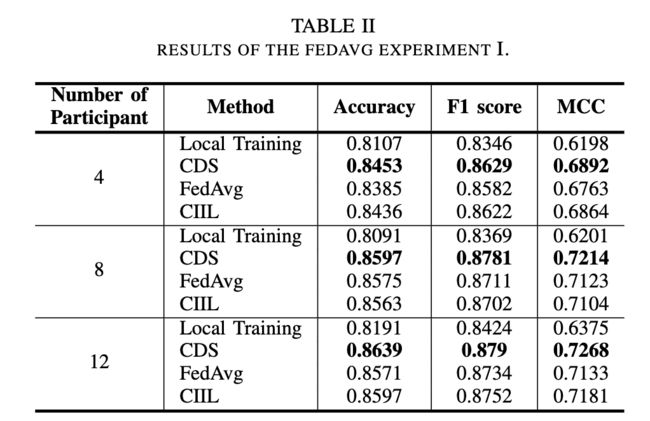
参加人数。表二的结果显示了增加参与者的预测效果。受限于每个参与者持有的恒定数据量,没有任何交互过程,本地训练总是有最不理想的结果。同时,CDS可以通过全球数据共享达到最佳的预测效果。一般来说,FedAvg 和 CIIL 的性能与 CDS 保持在一定水平,这意味着该方法可以很好地适应并行训练。
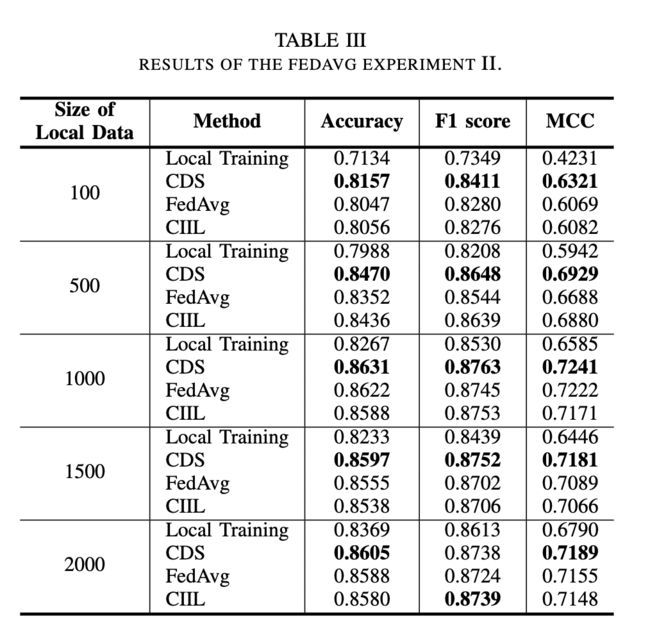
本地训练数据的大小。表 III 显示了增加每个参与者拥有的数据集大小的性能。与上一个实验类似,局部训练的表现是最差的。当本地数据量为 1000 时,其他三种方法都取得了最好的效果。但是,随着本地数据量的增加,特别是 FedAvg,预测性能下降。作者认为模型受到参与者之间重复数据的影响。
当数据量大于1500时,由于所有参与者的数据之和超过了训练数据的总量,参与者之间存在重复的数据。
两个实验都表明,通过跨多个社交网络的联邦学习来训练模型是一个合适的解决方案,与每个参与者的本地训练相比,它明显提高了性能。
5 总结
在本文中,作者首先提出了一种基于多关系图 DA-MRG 的域感知社交机器人检测方法,以区分机器人账户和人类账户。
首先,DA-MRG 使用用户之间的关系构建多关系图;
其次,该模型通过用户表示学习模块学习每个用户的高级表示,该模块由一系列图嵌入层和语义注意层组成;
最后,将演示文稿提供给领域感知机器人分类器;
作者进行了各种实验来评估模型,结果表明该方法可以获得更好的检测性能;
此外,还引入了联邦学习框架 FedAvg,以克服多个社交网络之间数据共享中的数据隐私问题。
然后,通过大量实验探索了 DA-MRG 与 FedAvg 的性能,并展示了解决数据孤岛问题的效率。