论文笔记 A brief introduction to weakly supervised learning - 2017
2017 A brief introduction to weakly supervised learning
南大
周志华National science review(IF 17.3), 2017 (Citations 815)
ABSTRACT
This article reviews some research progress of weakly supervised learning, focusing on three typical types of weak supervision: (See the introduction for a more detailed explanation)
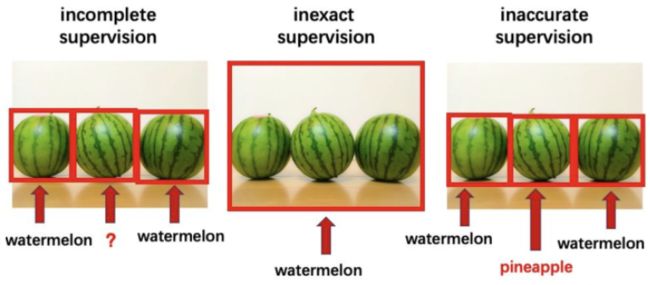
- incomplete supervision, where only a subset of training data is given with labels;
- inexact supervision, where the training data are given with only coarse-grained labels;
- inaccurate supervision, where the given labels are not always ground-truth.
INTRODUCTION
Typically, there are three types of weak supervision.
- incomplete supervision, i.e. only a (usually small) subset of training data is given with labels while the other data remain unlabeled.
For example, in image categorization the ground-truth labels are given by human annotators; it is easy to get a huge number of images from the Internet, whereas only a small subset of images can be annotated due to the human cost.
- inexact supervision, i.e. only coarse-grained labels are given.
It is desirable to have every object in the images annotated; however, usually we only have image-level labels rather than object-level labels.
- inaccurate supervision, i.e. the given labels are not always ground-truth.
Such a situation occurs, e.g. when the image annotator is careless or weary, or some images are difficult to categorize.
INCOMPLETE SUPERVISION
Incomplete supervision concerns the situation in which we are given a small amount of labeled data, which is insufficient to train a good learner, while abundant unlabeled data are available.
Formally, the task is to learn f : X ↦ Y f: \mathcal{X} \mapsto \mathcal{Y} f:X↦Y from a training data set D = ( x 1 , y 1 ) , . . . , ( x l , y l ) , x l + 1 , . . . , x m D = {(x_1, y_1), . . . , (x_l , y_l ), x_{l +1}, . . . , x_m } D=(x1,y1),...,(xl,yl),xl+1,...,xm.
There are two major techniques for this purpose:
incomplete supervision { active learning (With human intervention) semi-supervised learning (Without human intervention) \text{incomplete supervision}\left\{ \begin{aligned} &\text{active learning (With human intervention)}\\ &\text{semi-supervised learning (Without human intervention)} \end{aligned} \right. incomplete supervision{active learning (With human intervention)semi-supervised learning (Without human intervention)
- active learning;
Active learning assumes that there is an‘oracle’, such as a human expert, that can be queried to get ground-truth labels for selected unlabeled instances.
selection criteria of actie learning { informativeness representativeness \text{selection criteria of actie learning} \left\{ \begin{aligned} &\text{informativeness}\\ &\text{representativeness} \end{aligned} \right. selection criteria of actie learning{informativenessrepresentativeness
- semi-supervised learning.
In contrast, semi-supervised learning attempts to automatically exploit unlabeled data in addition to labeled data to improve learning performance, where no human intervention is assumed.
semi-supervised learning { (pure) semi-supervised learning tranductive learning \text{semi-supervised learning}\left\{ \begin{aligned} &\text{(pure) semi-supervised learning}\\ &\text{tranductive learning}\\ \end{aligned} \right. semi-supervised learning{(pure) semi-supervised learningtranductive learning
Actually, in semi-supervised learning there are two basic assumptions, i.e. the cluster assumption and the manifold assumption; both are about data distribution. The former assumes that data have inherent cluster structure, and thus, instances falling into the same cluster have the same class label. The latter assumes that data lie on a manifold, and thus, nearby instances have similar predictions. The essence of both assumptions lies in the belief that similar data points should have similar outputs, whereas unlabeled data can be helpful to disclose which data points are similar.
four major categories of semi-supervised learning { generative methods graph-based methods low-density separation methods disagreement-based methods. \text{four major categories of semi-supervised learning}\left\{ \begin{aligned} &\text{generative methods}\\ &\text{graph-based methods}\\ &\text{low-density separation methods}\\ &\text{disagreement-based methods.}\\ \end{aligned} \right. four major categories of semi-supervised learning⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧generative methodsgraph-based methodslow-density separation methodsdisagreement-based methods.
INEXACT SUPERVISION
Formally, the task is to learn f : X ↦ Y f: \mathcal{X} \mapsto \mathcal{Y} f:X↦Y from a training data set D = { ( X 1 , y 1 ) , . . . , ( X m , y m ) } D = \{(X_1, y_1), ..., (X_m, y_m)\} D={(X1,y1),...,(Xm,ym)}, where X i = { x i 1 , . . . , x i m i } ⊆ X X_i = \{x_{i1}, . . . , x_{im_i} \}\subseteq \mathcal{X} Xi={xi1,...,ximi}⊆X is called a bag, x i j ∈ X ( j ∈ { 1 , . . . , m i } ) x_{i j}\in X (j∈ \{1, ..., m_i\}) xij∈X(j∈{1,...,mi}) is an instance, m i m_i mi is the number of instances in X i X_i Xi, and y i ∈ Y = { Y , N } y_i\in \mathcal{Y} = \{Y, N\} yi∈Y={Y,N}. Xi is a positive bag, i.e. y i = Y y_i = Y yi=Y, if there exists x i p x_{i p} xip that is positive, while p ∈ { 1 , . . . , m i } p\in \{1, ..., m_i\} p∈{1,...,mi} is unknown. The goal is to predict labels for unseen bags. This is called multi-instance learning.