机器学习的4种经典模型总结
机器学习(Machine Learning)是人工智能的一个分支,也是人工智能的一种实现方法。机器学习的核心是“使用算法解析数据,从中学习,然后对新数据做出决定或预测”,机器学习的概念就是通过输入海量训练数据对模型进行训练,使模型掌握数据所蕴含的潜在规律,进而对新输入的数据进行准确的分类或预测。
机器学习的经典模型有很多,篇幅所限,本文将介绍四种常用的机器学习模型的基本概念、模型特点和主要应用场景,供大家学习参考。
本文主要提及的机器学习模型包括:
·隐马尔科夫
·条件随机场
·最大熵模型
· 逻辑斯谛回归
下面我们将具体展开介绍。
1.隐马尔科夫
Hidden Markov Model(HMM),隐马尔科夫模型是统计模型,它可以用来描述一个含有隐含未知参数的马尔可夫过程。其中马尔可夫过程的特点是下一时刻的状态只与当前状态有关,与上一时刻的状态无关。隐马尔科夫模型的难点是从可观测的参数中确定该过程的隐含参数,然后利用这些参数进行分析。
隐马尔科夫模型的精髓在于通过建立“隐藏“变量,将观测变量的时序相关性抽象到隐藏变量上。在日常生活中,我们常称这种感觉为”第六感“。在机器学习中,我们称这种感觉为“隐马尔科夫模型”。

隐马尔科夫模型注意点:
·HMM只依赖于每一个状态和它对应的观察对象
序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。
·目标函数和预测目标函数不匹配:
HMM学到的是状态和观察序列的联合分布P(Y,X),而预测问题中,我们需要的是条件概率
P(YIX)。
隐马尔科夫模型可以用来解决三大问题:
第一种是计算概率:已知整个模型和观测序列,计算出现该观测序列的概率。
第二种是学习问题:已知观测序列和模型,调整模型参数使出现观测序列的概率最大。
第三种是预测问题:已知整个模型和观测序列,推算隐状态序列。
2. 条件随机场
条件随机场是机器学习领域比较复杂的一个算法模型,原因在于其涉及到的定义多(概率图模型、团等概率)、数学上近似完美。
条件随机场(CRF)由Lafferty等人于2001年提出,结合了最大熵模型和隐马尔可夫模型的特点,是一种无向图模型,常用于标注或分析序列资料,如自然语言文字或是生物序列。
基本概念:
X:X = (x1, x2, x3, …, xn) 表示输入的序列,也称为观测值,例如句子中所有单词。
Y:Y = (y1, y2, y3, …, yn) 表示输出的序列,也称为状态值,例如句子中每一个单词的词性。
随机场:随机场是一种图模型,包含结点的集合和边的集合,结点表示一个随机变量,而边表示随机变量之间的依赖关系。如果按照某一种分布随机给图中每一个结点赋予一个值,则称为随机场。
马尔科夫随机场:马尔科夫性质指某一个时刻 t 的输出值只和 t-1 时刻的输出有关系,和更早的输出没有关系。马尔科夫随机场则是一种特殊的随机场,其假设每一个结点的取值只和相邻的结点有关系,和不相邻结点无关。
条件随机场 CRF:CRF 是一种特殊的马尔科夫随机场,CRF 假设模型中只有 X (观测值) 和 Y (状态值)。在 CRF 中每一个状态值 yi 只和其相邻的状态值有关,而观测值 x 不具有马尔科夫性质。注意观测序列 X 是作为一个整体影响 Y 计算,如下图所示。
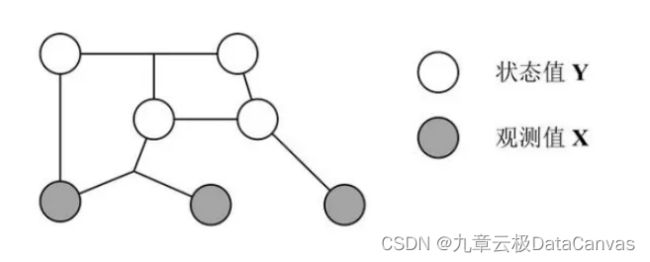
适用场景及主要应用领域:
条件随机场是一类最适合预测任务的判别模型,其中相邻的上下文信息或状态会影响当前预测。CRF 在命名实体识别、词性标注、基因预测、降噪和对象检测问题等方面都有应用。
3. 最大熵模型
先给出熵的定义:
$H§ = - \sum {p(x){{\log }_2}p(x)} $
对于任意一个随机变量X,它的不确定性越大,它的熵也就越大(这是合乎常理的,如果一件事越是让人琢磨不透,那么当有人把正确信息告诉你,你就越会感觉这信息的价值有多大)。
最大熵模型的基本思想是,学习概率模型时,在所有可能的概率模型中,熵最大的模型是最好的模型。
若模型要满足一些约束条件时,则最大熵原理就是在满足已知条件的概率模型集合中,找到熵最大的模型。因而最大熵模型指出,在预测一个样本或者一个事件的概率分布时,首先应当满足所有的约束条件,进而对未知的情况不做任何的主观假设。在这种情况下,概率分布最均匀,预测的风险最小,因此得到的概率分布的熵是最大。
最大熵模型的优点:
·最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型,作为经典的分类模型时准确率较高。
·可以灵活地设置约束条件,通过约束条件的多少可以调节模型对未知数据的适应度和对已知数据的拟合程度
最大熵模型的缺点:
·由于约束函数数量和样本数目有关系,导致迭代过程计算量巨大,实际应用比较难。
4. 逻辑斯谛回归
逻辑斯谛回归是经典的分类方法,它属于对数线性模型,原理是根据现有的数据对分类边界线建立回归公式,以此进行分类。
下图给出了文本情感分类中,分别使用二分类和多分类逻辑斯蒂回归,对样本“dessert was great”的情感极性进行推理(分类)的样例:
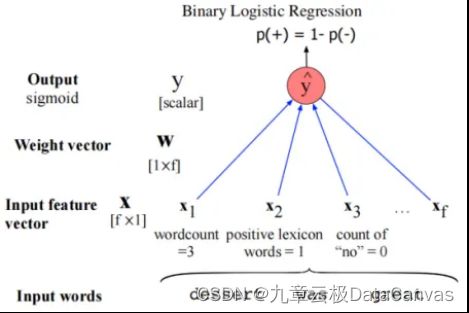
二分类逻辑斯蒂回归示例
LR优点:
·适合需要得到一个分类概率的场景。
·计算代价不高,容易理解实现。LR在时间和内存需求上相当高效。它可以应用于分布式数据,并且还有在线算法实现,用较少的资源处理大型数据。
·LR对于数据中小噪声的鲁棒性很好,并且不会受到轻微的多重共线性的特别影响。(严重的多重共线性则可以使用逻辑回归结合L2正则化来解决,但是若要得到一个简约模型,L2正则化并不是最好的选择,因为它建立的模型涵盖了全部的特征。)
LR缺点:
·容易欠拟合,分类精度不高。
·数据特征有缺失或者特征空间很大时表现效果并不好。
适用场景及主要应用领域:
逻辑斯蒂回归(LR)属于对数线性模型,可以用于解决二分类或多分类问题的分类模型,对应的输入为实例特征向量,输出为实例属于不同类别的概率。和感知机不同,它能更准确的量化分类问题,究竟属于哪个具体类别。
LR是解决工业规模问题最流行的算法。在工业应用上,如果需要分类的数据拥有很多有意义的特征,每个特征都对最后的分类结果有或多或少的影响,那么最简单最有效的办法就是将这些特征线性加权,一起参与到决策过程中。比如预测广告的点击率,从原始数据集中筛选出符合某种要求的有用的子数据集等等。