o2o优惠卷使用预测(天池)(项目练习_6)
目录
-
-
-
- 1.项目摘要说明
- 2.数据分析
- 3.特征构建部分
- 4.模型部分
-
-
1.项目摘要说明
项目目的:对于数据分析的练习
数据来源:天池大数据竞赛平台
源码.数据集以及字段说明 链接:
地址:–https://tianchi.aliyun.com/competition/entrance/231593/information
—
本项目摘要:
- 利用天猫阿里云天池提供的o2o场景相关的丰富数据(收集用户在某个平台下,时间维度为2016.01.01-2016.06.30的真实线上线下消费行为),首先对数据集进行数据研究分析及可视化,再对其进行数据预处理和特征工程加工,然后对训练集进行分割,用来进行交叉训练,利用随机森林、GBDT及Xgboost等算法对训练集进行训练及建模,对训练集进行训练预测之后,最后对测试集进行预测(预测集为在7月领取优惠卷的用户),预测他们在领取优惠卷后15天内使用优惠卷的概率,最终评价标准为AUC(Area Under Curve)平均值
2.数据分析
导入需要使用的工具包
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import folium
import pandas as pd
import webbrowser
from pyecharts import options as opts
from pyecharts.charts import Page, Pie, Bar, Line, Scatter, Scatter3D
import warnings
warnings.filterwarnings("ignore")
读取数据(这里仅使用线下训练集数据)
off_train = pd.read_csv('./ccf_offline_stage1_train.csv')
off_train.head() #显示前五行
off_train.isnull().sum()[off_train.isnull().sum()!=0]#查看空值情况
| User_id | Merchant_id | Coupon_id | Discount_rate | Distance | Date_received | Date | |
|---|---|---|---|---|---|---|---|
| 0 | 1439408 | 2632 | NaN | NaN | 0.0 | NaN | 20160217.0 |
| 1 | 1439408 | 4663 | 11002.0 | 150:20 | 1.0 | 20160528.0 | NaN |
| 2 | 1439408 | 2632 | 8591.0 | 20:1 | 0.0 | 20160217.0 | NaN |
| 3 | 1439408 | 2632 | 1078.0 | 20:1 | 0.0 | 20160319.0 | NaN |
| 4 | 1439408 | 2632 | 8591.0 | 20:1 | 0.0 | 20160613.0 | NaN |
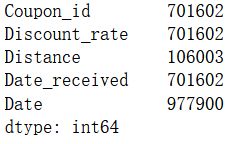
数据维度、总用户数和店铺数
可视化
j1m1 = off_train[(off_train['Date_received'].notnull()) & (off_train['Date'].notnull())].shape[0]
j0m1 = off_train[(off_train['Date_received'].isnull()) & (off_train['Date'].notnull())].shape[0]
j1m0 = off_train[(off_train['Date_received'].notnull()) & (off_train['Date'].isnull())].shape[0]
a = (Pie().add("juanmai",
[list(z) for z in zip(['有优惠券购买商品', '无优惠券购买商品', '有优惠券不购买商品']
,[j1m1,j0m1,j1m0])])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
a.render_notebook()
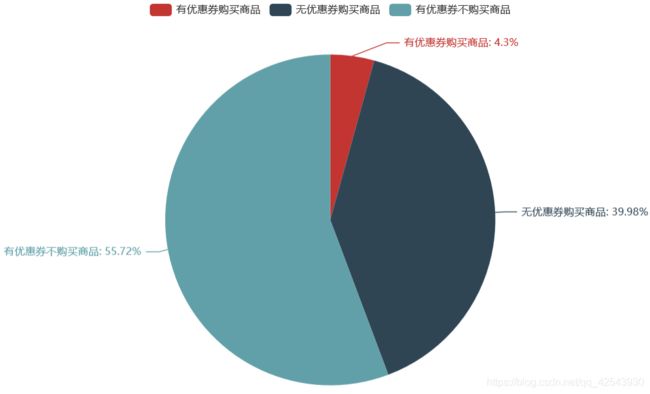
大部分人(701602)购买商品却没有使用优惠券,也有很多人(977900)有优惠券但却没有使用,真正使用优惠券购买商品的人(75382)很少!所以,优惠券的精准投放很重要。
#消费月份
x1=pd.DatetimeIndex(pd.to_datetime(off_train['Date'], format='%Y%m%d')).month.dropna().value_counts().sort_index().index.tolist()
x=[str(int(i)) for i in x1] #pyehchart需要字符类型
q = (Bar(init_opts=opts.InitOpts(width="600px",height="400px"))
.add_xaxis(x)
.add_yaxis('每月消费数量',pd.DatetimeIndex(date_buy_dt).month.dropna().value_counts().sort_index().tolist(),
color='#48A43F',
# areastyle_opts=opts.AreaStyleOpts(opacity=0.5)
)
.set_global_opts(xaxis_opts=opts.AxisOpts(name='month',name_location = "center",name_gap= 40))
)
q.render_notebook()
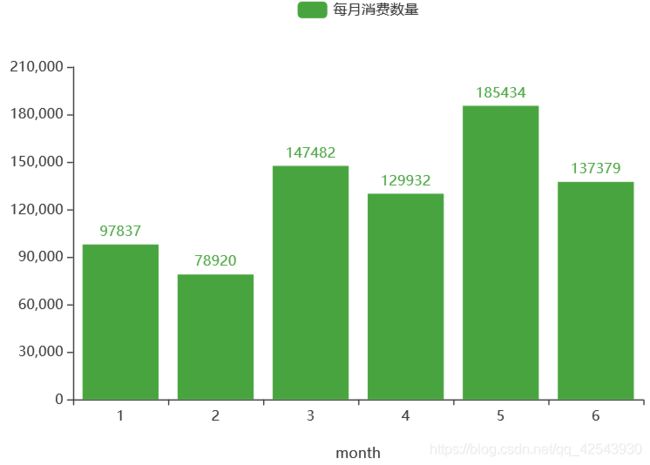
3月份-6月份的销售量比1、2月份高很多,需考虑是商户采取的运营策略导致的销量提高还是受季节影响。
off_copy1 = off_train.copy()
off_copy1['Date_received'] = pd.to_datetime(off_copy1['Date_received'],format='%Y%m%d')
off_copy1 = off_copy1.sort_values(by = 'Date_received')
off_copy1 = off_copy1.drop_duplicates(subset=['User_id'],keep='first')
off_copy1['receiver_mon'] = off_copy1['Date_received'].apply(lambda x:x.month)
#用户新增月份
x1=off_copy1['receiver_mon'].value_counts().sort_index().index.tolist()
x=[str(int(i)) for i in x1] #pyehchart需要字符类型
q = (Line(init_opts=opts.InitOpts(width="1000px",height="400px"))
.add_xaxis(x)
.add_yaxis('每月用户新增',off_copy1['receiver_mon'].value_counts().sort_index().tolist(),
color = '#AED54C',
is_smooth=True,
areastyle_opts=opts.AreaStyleOpts(opacity=0.5)
)
.set_global_opts(xaxis_opts=opts.AxisOpts(name='month',name_location = "center",name_gap= 40))
)
q.render_notebook()
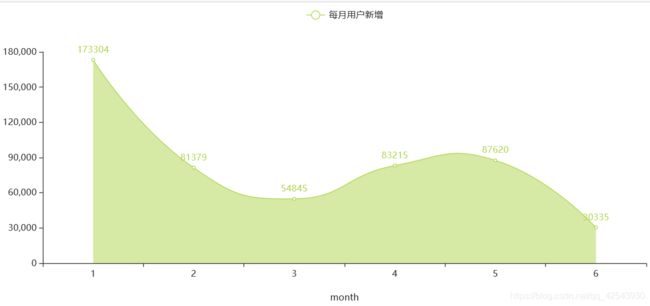
off_copy2 = off_train.copy()
off_copy2['Date_received'] = pd.to_datetime(off_copy1['Date_received'],format='%Y%m%d')
off_copy2['receiver_week'] = off_copy2['Date_received'].apply(lambda x:x.dayofweek+1)
#一周用户消费数
x1=off_copy2['receiver_week'].value_counts().sort_index().index.tolist()
x=[str(int(i)) for i in x1] #pyehchart需要字符类型
q = (Line(init_opts=opts.InitOpts(width="1000px",height="400px"))
.add_xaxis(x)
.add_yaxis('一周用户消费数',off_copy2['receiver_week'].value_counts().sort_index().tolist(),
color = '#F7BA0B',
is_smooth=True,
areastyle_opts=opts.AreaStyleOpts(opacity=0.5)
)
.set_global_opts(xaxis_opts=opts.AxisOpts(name='周几',name_location = "center",name_gap= 40))
)
q.render_notebook()
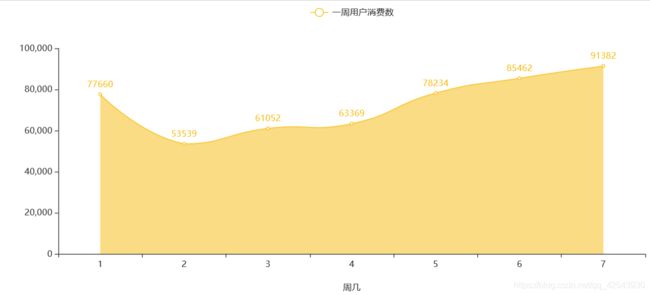
off_copy3 = off_train.copy()
off_copy3['Date'] = pd.to_datetime(off_copy3['Date'],format='%Y%m%d')
off_copy3 = off_copy3.dropna(axis = 0,subset=['Date'])
off_copy3['Date_mon'] = off_copy3['Date'].apply(lambda x:x.month)
last_ = off_copy3.groupby('User_id').Date_mon.max().tolist()
fist_ = off_copy3.groupby('User_id').Date_mon.min().tolist()
num_consum = off_copy3.groupby('User_id').User_id.value_counts().values.tolist()
data_tulpe = list(zip(last_, fist_,num_consum))
name=["用户最近消费时间","用户最早消费时间","用户消费次数"]
scatter3D=Scatter3D(init_opts = opts.InitOpts(width='600px',height='400px')) #初始化
scatter3D.add(name,data_tulpe,xaxis3d_opts=opts.Axis3DOpts(
name='用户最近消费时间',
type_="value",
# textstyle_opts=opts.TextStyleOpts(color="#fff"),
),yaxis3d_opts=opts.Axis3DOpts(
name='用户最早消费时间',
type_="value",
# textstyle_opts=opts.TextStyleOpts(color="#fff"),
),zaxis3d_opts=opts.Axis3DOpts(
name='用户消费次数',
type_="value",
# textstyle_opts=opts.TextStyleOpts(color="#fff"),
),
grid3d_opts=opts.Grid3DOpts(
width=100, depth=100
))
scatter3D.set_global_opts(title_opts=opts.TitleOpts(title="散点图"),
visualmap_opts=opts.VisualMapOpts(
range_color=Faker.visual_color #颜色映射
))
scatter3D.render_notebook()
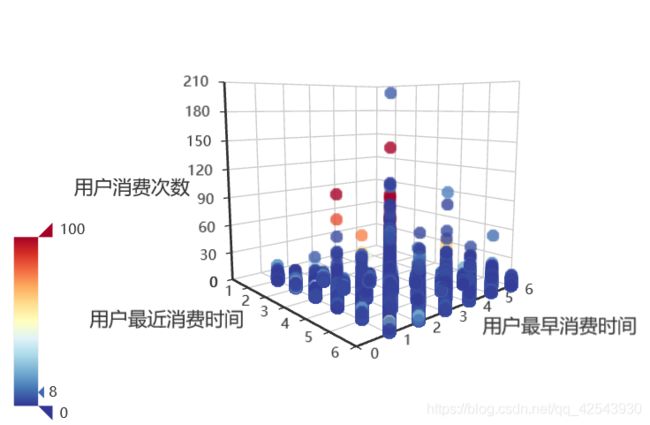
3.特征构建部分
# In[] null,na 特殊处理
def null_process_offline(dataset, predict=False):
dataset.Distance.fillna(11, inplace=True)
dataset.Distance = dataset.Distance.astype(int)
dataset.Coupon_id.fillna(0, inplace=True)
dataset.Coupon_id = dataset.Coupon_id.astype(int)
dataset.Date_received.fillna(date_null, inplace=True)
dataset[['discount_rate_x', 'discount_rate_y']] = dataset[dataset.Discount_rate.str.contains(':') == True][
'Discount_rate'].str.split(':', expand=True).astype(int)
dataset['discount_rate'] = 1 - dataset.discount_rate_y / dataset.discount_rate_x
dataset.discount_rate = dataset.discount_rate.fillna(dataset.Discount_rate).astype(float)
if predict:
return dataset
else:
dataset.Date.fillna(date_null, inplace=True)
return dataset
def null_process_online(dataset):
dataset.Coupon_id.fillna(0, inplace=True)
# online.Coupon_id = online.Coupon_id.astype(int)
dataset.Date_received.fillna(date_null, inplace=True)
dataset.Date.fillna(date_null, inplace=True)
return dataset
# In[] 生成交叉训练集
def data_process(off_train, on_train, off_test):
# train feature split
# 交叉训练集一:收到券的日期大于4月14日和小于5月14日
time_range = ['2016-04-16', '2016-05-15']
dataset1 = off_train[(off_train.Date_received >= time_range[0]) & (off_train.Date_received <= time_range[1])].copy()
dataset1['label'] = 0
dataset1.loc[
(dataset1.Date != date_null) & (dataset1.Date - dataset1.Date_received <= datetime.timedelta(15)), 'label'] = 1
# 交叉训练集一特征offline:线下数据中领券和用券日期大于1月1日和小于4月13日
time_range_date_received = ['2016-01-01', '2016-03-31']
time_range_date = ['2016-01-01', '2016-04-15']
feature1_off = off_train[(off_train.Date >= time_range_date[0]) & (off_train.Date <= time_range_date[1]) | (
(off_train.Coupon_id == 0) & (off_train.Date_received >= time_range_date_received[0]) & (
off_train.Date_received <= time_range_date_received[1]))]
# 交叉训练集一特征online:线上数据中领券和用券日期大于1月1日和小于4月13日[on_train.date == 'null' to on_train.coupon_id == 0]
feature1_on = on_train[(on_train.Date >= time_range_date[0]) & (on_train.Date <= time_range_date[1]) | (
(on_train.Coupon_id == 0) & (on_train.Date_received >= time_range_date_received[0]) & (
on_train.Date_received <= time_range_date_received[1]))]
# 交叉训练集二:收到券的日期大于5月15日和小于6月15日
time_range = ['2016-05-16', '2016-06-15']
dataset2 = off_train[(off_train.Date_received >= time_range[0]) & (off_train.Date_received <= time_range[1])]
dataset2['label'] = 0
dataset2.loc[
(dataset2.Date != date_null) & (dataset2.Date - dataset2.Date_received <= datetime.timedelta(15)), 'label'] = 1
# 交叉训练集二特征offline:线下数据中领券和用券日期大于2月1日和小于5月14日
time_range_date_received = ['2016-02-01', '2016-04-30']
time_range_date = ['2016-02-01', '2016-05-15']
feature2_off = off_train[(off_train.Date >= time_range_date[0]) & (off_train.Date <= time_range_date[1]) | (
(off_train.Coupon_id == 0) & (off_train.Date_received >= time_range_date_received[0]) & (
off_train.Date_received <= time_range_date_received[1]))]
# 交叉训练集二特征online:线上数据中领券和用券日期大于2月1日和小于5月14日
feature2_on = on_train[(on_train.Date >= time_range_date[0]) & (on_train.Date <= time_range_date[1]) | (
(on_train.Coupon_id == 0) & (on_train.Date_received >= time_range_date_received[0]) & (
on_train.Date_received <= time_range_date_received[1]))]
# 测试集
dataset3 = off_test
# 测试集特征offline :线下数据中领券和用券日期大于3月15日和小于6月30日的
time_range = ['2016-03-16', '2016-06-30']
feature3_off = off_train[((off_train.Date >= time_range[0]) & (off_train.Date <= time_range[1])) | (
(off_train.Coupon_id == 0) & (off_train.Date_received >= time_range[0]) & (
off_train.Date_received <= time_range[1]))]
# 测试集特征online :线上数据中领券和用券日期大于3月15日和小于6月30日的
feature3_on = on_train[((on_train.Date >= time_range[0]) & (on_train.Date <= time_range[1])) | (
(on_train.Coupon_id == 0) & (on_train.Date_received >= time_range[0]) & (
on_train.Date_received <= time_range[1]))]
# get train feature
ProcessDataSet1 = get_features(dataset1, feature1_off, feature1_on)
ProcessDataSet2 = get_features(dataset2, feature2_off, feature2_on)
ProcessDataSet3 = get_features(dataset3, feature3_off, feature3_on)
return ProcessDataSet1, ProcessDataSet2, ProcessDataSet3
def get_features(dataset, feature_off, feature_on):
dataset = get_offline_features(dataset, feature_off)
return get_online_features(feature_on, dataset)
# In[] 定义获取feature的函数
def get_offline_features(X, offline):
# X = X[:1000]
print(len(X), len(X.columns))
temp = offline[offline.Coupon_id != 0]
coupon_consume = temp[temp.Date != date_null]
coupon_no_consume = temp[temp.Date == date_null]
user_coupon_consume = coupon_consume.groupby('User_id')
X['weekday'] = X.Date_received.dt.weekday
X['day'] = X.Date_received.dt.day
'''user features'''
# 优惠券消费次数
temp = user_coupon_consume.size().reset_index(name='u2')
X = pd.merge(X, temp, how='left', on='User_id')
# X.u2.fillna(0, inplace=True)
# X.u2 = X.u2.astype(int)
# 优惠券不消费次数
temp = coupon_no_consume.groupby('User_id').size().reset_index(name='u3')
X = pd.merge(X, temp, how='left', on='User_id')
# 使用优惠券次数与没使用优惠券次数比值
X['u19'] = X.u2 / X.u3
# 领取优惠券次数
X['u1'] = X.u2.fillna(0) + X.u3.fillna(0)
# 优惠券核销率
X['u4'] = X.u2 / X.u1
# 普通消费次数
temp = offline[(offline.Coupon_id == 0) & (offline.Date != date_null)]
temp1 = temp.groupby('User_id').size().reset_index(name='u5')
X = pd.merge(X, temp1, how='left', on='User_id')
# 一共消费多少次
X['u25'] = X.u2 + X.u5
# 用户使用优惠券消费占比
X['u20'] = X.u2 / X.u25
# 正常消费平均间隔
temp = pd.merge(temp, temp.groupby('User_id').Date.max().reset_index(name='max'))
temp = pd.merge(temp, temp.groupby('User_id').Date.min().reset_index(name='min'))
temp = pd.merge(temp, temp.groupby('User_id').size().reset_index(name='len'))
temp['u6'] = ((temp['max'] - temp['min']).dt.days / (temp['len'] - 1))
temp = temp.drop_duplicates('User_id')
X = pd.merge(X, temp[['User_id', 'u6']], how='left', on='User_id')
# 优惠券消费平均间隔
temp = pd.merge(coupon_consume, user_coupon_consume.Date.max().reset_index(name='max'))
temp = pd.merge(temp, temp.groupby('User_id').Date.min().reset_index(name='min'))
temp = pd.merge(temp, temp.groupby('User_id').size().reset_index(name='len'))
temp['u7'] = ((temp['max'] - temp['min']).dt.days / (temp['len'] - 1))
temp = temp.drop_duplicates('User_id')
X = pd.merge(X, temp[['User_id', 'u7']], how='left', on='User_id')
# 15天内平均会普通消费几次
X['u8'] = X.u6 / 15
# 15天内平均会优惠券消费几次
X['u9'] = X.u7 / 15
# 领取优惠券到使用优惠券的平均间隔时间
temp = coupon_consume.copy()
temp['days'] = (temp.Date - temp.Date_received).dt.days
temp = (temp.groupby('User_id').days.sum() / temp.groupby('User_id').size()).reset_index(name='u10')
X = pd.merge(X, temp, how='left', on='User_id')
# 在15天内使用掉优惠券的值大小
X['u11'] = X.u10 / 15
# 领取优惠券到使用优惠券间隔小于15天的次数
temp = coupon_consume.copy()
temp['days'] = (temp.Date - temp.Date_received).dt.days
temp = temp[temp.days <= 15]
temp = temp.groupby('User_id').size().reset_index(name='u21')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户15天使用掉优惠券的次数除以使用优惠券的次数
X['u22'] = X.u21 / X.u2
# 用户15天使用掉优惠券的次数除以领取优惠券未消费的次数
X['u23'] = X.u21 / X.u3
# 用户15天使用掉优惠券的次数除以领取优惠券的总次数
X['u24'] = X.u21 / X.u1
# 消费优惠券的平均折率
temp = user_coupon_consume['discount_rate'].mean().reset_index(name='u45')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户核销优惠券的最低消费折率
temp = user_coupon_consume['discount_rate'].min().reset_index(name='u27')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户核销优惠券的最高消费折率
temp = user_coupon_consume['discount_rate'].max().reset_index(name='u28')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户核销过的不同优惠券数量
temp = coupon_consume.groupby(['User_id', 'Coupon_id']).size()
temp = temp.groupby('User_id').size().reset_index(name='u32')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户领取所有不同优惠券数量
temp = offline[offline.Date_received != date_null]
temp = temp.groupby(['User_id', 'Coupon_id']).size().reset_index(name='u47')
X = pd.merge(X, temp, how='left', on=['User_id', 'Coupon_id'])
# 用户核销过的不同优惠券数量占所有不同优惠券的比重
X['u33'] = X.u32 / X.u47
# 用户平均每种优惠券核销多少张
X['u34'] = X.u2 / X.u47
# 核销优惠券用户-商家平均距离
temp = offline[(offline.Coupon_id != 0) & (offline.Date != date_null) & (offline.Distance != 11)]
temp = temp.groupby('User_id').Distance
temp = pd.merge(temp.count().reset_index(name='x'), temp.sum().reset_index(name='y'), on='User_id')
temp['u35'] = temp.y / temp.x
temp = temp[['User_id', 'u35']]
X = pd.merge(X, temp, how='left', on='User_id')
# 用户核销优惠券中的最小用户-商家距离
temp = coupon_consume[coupon_consume.Distance != 11]
temp = temp.groupby('User_id').Distance.min().reset_index(name='u36')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户核销优惠券中的最大用户-商家距离
temp = coupon_consume[coupon_consume.Distance != 11]
temp = temp.groupby('User_id').Distance.max().reset_index(name='u37')
X = pd.merge(X, temp, how='left', on='User_id')
# 优惠券类型
discount_types = [
'0.2', '0.5', '0.6', '0.7', '0.75', '0.8', '0.85', '0.9', '0.95', '30:20', '50:30', '10:5',
'20:10', '100:50', '200:100', '50:20', '30:10', '150:50', '100:30', '20:5', '200:50', '5:1',
'50:10', '100:20', '150:30', '30:5', '300:50', '200:30', '150:20', '10:1', '50:5', '100:10',
'200:20', '300:30', '150:10', '300:20', '500:30', '20:1', '100:5', '200:10', '30:1', '150:5',
'300:10', '200:5', '50:1', '100:1',
]
X['discount_type'] = -1
for k, v in enumerate(discount_types):
X.loc[X.Discount_rate == v, 'discount_type'] = k
# 不同优惠券领取次数
temp = offline.groupby(['User_id', 'Discount_rate']).size().reset_index(name='u41')
X = pd.merge(X, temp, how='left', on=['User_id', 'Discount_rate'])
# 不同优惠券使用次数
temp = coupon_consume.groupby(['User_id', 'Discount_rate']).size().reset_index(name='u42')
X = pd.merge(X, temp, how='left', on=['User_id', 'Discount_rate'])
# 不同优惠券不使用次数
temp = coupon_no_consume.groupby(['User_id', 'Discount_rate']).size().reset_index(name='u43')
X = pd.merge(X, temp, how='left', on=['User_id', 'Discount_rate'])
# 不同打折优惠券使用率
X['u44'] = X.u42 / X.u41
# 满减类型优惠券领取次数
temp = offline[offline.Discount_rate.str.contains(':') == True]
temp = temp.groupby('User_id').size().reset_index(name='u48')
X = pd.merge(X, temp, how='left', on='User_id')
# 打折类型优惠券领取次数
temp = offline[offline.Discount_rate.str.contains('\.') == True]
temp = temp.groupby('User_id').size().reset_index(name='u49')
X = pd.merge(X, temp, how='left', on='User_id')
'''offline merchant features'''
# 商户消费次数
temp = offline[offline.Date != date_null].groupby('Merchant_id').size().reset_index(name='m0')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家优惠券被领取后核销次数
temp = coupon_consume.groupby('Merchant_id').size().reset_index(name='m1')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商户正常消费笔数
X['m2'] = X.m0.fillna(0) - X.m1.fillna(0)
# 商家优惠券被领取次数
temp = offline[offline.Date_received != date_null].groupby('Merchant_id').size().reset_index(name='m3')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家优惠券被领取后核销率
X['m4'] = X.m1 / X.m3
# 商家优惠券被领取后不核销次数
temp = coupon_no_consume.groupby('Merchant_id').size().reset_index(name='m7')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商户当天优惠券领取次数
temp = X[X.Date_received != date_null]
temp = temp.groupby(['Merchant_id', 'Date_received']).size().reset_index(name='m5')
X = pd.merge(X, temp, how='left', on=['Merchant_id', 'Date_received'])
# 商户当天优惠券领取人数
temp = X[X.Date_received != date_null]
temp = temp.groupby(['User_id', 'Merchant_id', 'Date_received']).size().reset_index()
temp = temp.groupby(['Merchant_id', 'Date_received']).size().reset_index(name='m6')
X = pd.merge(X, temp, how='left', on=['Merchant_id', 'Date_received'])
# 商家优惠券核销的平均消费折率
temp = coupon_consume.groupby('Merchant_id').discount_rate.mean().reset_index(name='m8')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家优惠券核销的最小消费折率
temp = coupon_consume.groupby('Merchant_id').discount_rate.max().reset_index(name='m9')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家优惠券核销的最大消费折率
temp = coupon_consume.groupby('Merchant_id').discount_rate.min().reset_index(name='m10')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家优惠券核销不同的用户数量
temp = coupon_consume.groupby(['Merchant_id', 'User_id']).size()
temp = temp.groupby('Merchant_id').size().reset_index(name='m11')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家优惠券领取不同的用户数量
temp = offline[offline.Date_received != date_null].groupby(['Merchant_id', 'User_id']).size()
temp = temp.groupby('Merchant_id').size().reset_index(name='m12')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 核销商家优惠券的不同用户数量其占领取不同的用户比重
X['m13'] = X.m11 / X.m12
# 商家优惠券平均每个用户核销多少张
X['m14'] = X.m1 / X.m12
# 商家被核销过的不同优惠券数量
temp = coupon_consume.groupby(['Merchant_id', 'Coupon_id']).size()
temp = temp.groupby('Merchant_id').size().reset_index(name='m15')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家领取过的不同优惠券数量的比重
temp = offline[offline.Date_received != date_null].groupby(['Merchant_id', 'Coupon_id']).size()
temp = temp.groupby('Merchant_id').count().reset_index(name='m18')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家被核销过的不同优惠券数量占所有领取过的不同优惠券数量的比重
X['m19'] = X.m15 / X.m18
# 商家被核销优惠券的平均时间
temp = pd.merge(coupon_consume, coupon_consume.groupby('Merchant_id').Date.max().reset_index(name='max'))
temp = pd.merge(temp, temp.groupby('Merchant_id').Date.min().reset_index(name='min'))
temp = pd.merge(temp, temp.groupby('Merchant_id').size().reset_index(name='len'))
temp['m20'] = ((temp['max'] - temp['min']).dt.days / (temp['len'] - 1))
temp = temp.drop_duplicates('Merchant_id')
X = pd.merge(X, temp[['Merchant_id', 'm20']], how='left', on='Merchant_id')
# 商家被核销优惠券中的用户-商家平均距离
temp = coupon_consume[coupon_consume.Distance != 11].groupby('Merchant_id').Distance
temp = pd.merge(temp.count().reset_index(name='x'), temp.sum().reset_index(name='y'), on='Merchant_id')
temp['m21'] = temp.y / temp.x
temp = temp[['Merchant_id', 'm21']]
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家被核销优惠券中的用户-商家最小距离
temp = coupon_consume[coupon_consume.Distance != 11]
temp = temp.groupby('Merchant_id').Distance.min().reset_index(name='m22')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家被核销优惠券中的用户-商家最大距离
temp = coupon_consume[coupon_consume.Distance != 11]
temp = temp.groupby('Merchant_id').Distance.max().reset_index(name='m23')
X = pd.merge(X, temp, how='left', on='Merchant_id')
"""offline coupon features"""
# 此优惠券一共发行多少张
temp = offline[offline.Coupon_id != 0].groupby('Coupon_id').size().reset_index(name='c1')
X = pd.merge(X, temp, how='left', on='Coupon_id')
# 此优惠券一共被使用多少张
temp = coupon_consume.groupby('Coupon_id').size().reset_index(name='c2')
X = pd.merge(X, temp, how='left', on='Coupon_id')
# 优惠券使用率
X['c3'] = X.c2 / X.c1
# 没有使用的数目
X['c4'] = X.c1 - X.c2
# 此优惠券在当天发行了多少张
temp = X.groupby(['Coupon_id', 'Date_received']).size().reset_index(name='c5')
X = pd.merge(X, temp, how='left', on=['Coupon_id', 'Date_received'])
# 优惠券类型(直接优惠为0, 满减为1)
X['c6'] = 0
X.loc[X.Discount_rate.str.contains(':') == True, 'c6'] = 1
# 不同打折优惠券领取次数
temp = offline.groupby('Discount_rate').size().reset_index(name='c8')
X = pd.merge(X, temp, how='left', on='Discount_rate')
# 不同打折优惠券使用次数
temp = coupon_consume.groupby('Discount_rate').size().reset_index(name='c9')
X = pd.merge(X, temp, how='left', on='Discount_rate')
# 不同打折优惠券不使用次数
temp = coupon_no_consume.groupby('Discount_rate').size().reset_index(name='c10')
X = pd.merge(X, temp, how='left', on='Discount_rate')
# 不同打折优惠券使用率
X['c11'] = X.c9 / X.c8
# 优惠券核销平均时间
temp = pd.merge(coupon_consume, coupon_consume.groupby('Coupon_id').Date.max().reset_index(name='max'))
temp = pd.merge(temp, temp.groupby('Coupon_id').Date.min().reset_index(name='min'))
temp = pd.merge(temp, temp.groupby('Coupon_id').size().reset_index(name='count'))
temp['c12'] = ((temp['max'] - temp['min']).dt.days / (temp['count'] - 1))
temp = temp.drop_duplicates('Coupon_id')
X = pd.merge(X, temp[['Coupon_id', 'c12']], how='left', on='Coupon_id')
'''user merchant feature'''
# 用户领取商家的优惠券次数
temp = offline[offline.Coupon_id != 0]
temp = temp.groupby(['User_id', 'Merchant_id']).size().reset_index(name='um1')
X = pd.merge(X, temp, how='left', on=['User_id', 'Merchant_id'])
# 用户领取商家的优惠券后不核销次数
temp = coupon_no_consume.groupby(['User_id', 'Merchant_id']).size().reset_index(name='um2')
X = pd.merge(X, temp, how='left', on=['User_id', 'Merchant_id'])
# 用户领取商家的优惠券后核销次数
temp = coupon_consume.groupby(['User_id', 'Merchant_id']).size().reset_index(name='um3')
X = pd.merge(X, temp, how='left', on=['User_id', 'Merchant_id'])
# 用户领取商家的优惠券后核销率
X['um4'] = X.um3 / X.um1
# 用户对每个商家的不核销次数占用户总的不核销次数的比重
temp = coupon_no_consume.groupby('User_id').size().reset_index(name='temp')
X = pd.merge(X, temp, how='left', on='User_id')
X['um5'] = X.um2 / X.temp
X.drop(columns='temp', inplace=True)
# 用户在商店总共消费过几次
temp = offline[offline.Date != date_null].groupby(['User_id', 'Merchant_id']).size().reset_index(name='um6')
X = pd.merge(X, temp, how='left', on=['User_id', 'Merchant_id'])
# 用户在商店普通消费次数
temp = offline[(offline.Coupon_id == 0) & (offline.Date != date_null)]
temp = temp.groupby(['User_id', 'Merchant_id']).size().reset_index(name='um7')
X = pd.merge(X, temp, how='left', on=['User_id', 'Merchant_id'])
# 用户当天在此商店领取的优惠券数目
temp = offline[offline.Date_received != date_null]
temp = temp.groupby(['User_id', 'Merchant_id', 'Date_received']).size().reset_index(name='um8')
X = pd.merge(X, temp, how='left', on=['User_id', 'Merchant_id', 'Date_received'])
# 用户领取优惠券不同商家数量
temp = offline[offline.Coupon_id == offline.Coupon_id]
temp = temp.groupby(['User_id', 'Merchant_id']).size().reset_index()
temp = temp.groupby('User_id').size().reset_index(name='um9')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户核销优惠券不同商家数量
temp = coupon_consume.groupby(['User_id', 'Merchant_id']).size()
temp = temp.groupby('User_id').size().reset_index(name='um10')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户核销过优惠券的不同商家数量占所有不同商家的比重
X['um11'] = X.um10 / X.um9
# 用户平均核销每个商家多少张优惠券
X['um12'] = X.u2 / X.um9
'''other feature'''
# 用户领取优惠券次数
temp = X.groupby('User_id').size().reset_index(name='o1')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户不同优惠券领取次数
temp = X.groupby(['User_id', 'Coupon_id']).size().reset_index(name='o2')
X = pd.merge(X, temp, how='left', on=['User_id', 'Coupon_id'])
# 用户此次之后/前领取的优惠券次数
X['o3'] = 1
X['o3'] = X.sort_values(by=['User_id', 'Date_received']).groupby('User_id').o3.cumsum() - 1
X['o4'] = 1
X['o4'] = X.sort_values(by=['User_id', 'Date_received'], ascending=False).groupby('User_id').o4.cumsum() - 1
# 用户此次之后/前领取的每种优惠券次数
X['o5'] = 1
temp = X.sort_values(by=['User_id', 'Coupon_id', 'Date_received'])
X['o5'] = temp.groupby('User_id').o5.cumsum() - 1
X['o6'] = 1
temp = X.sort_values(by=['User_id', 'Coupon_id', 'Date_received'], ascending=False)
X['o6'] = temp.groupby('User_id').o6.cumsum() - 1
# 用户领取优惠券平均时间间隔
temp = pd.merge(X, X.groupby('User_id').Date_received.max().reset_index(name='_max'))
temp = pd.merge(temp, temp.groupby('User_id').Date_received.min().reset_index(name='_min'))
temp = pd.merge(temp, temp.groupby('User_id').size().reset_index(name='_len'))
temp['o7'] = (temp._max - temp._min).dt.days / (temp._len - 1)
temp.drop_duplicates('User_id', inplace=True)
X = pd.merge(X, temp[['User_id', 'o7']], how='left', on='User_id')
# 用户领取不同商家的优惠券次数
temp = X.groupby(['User_id', 'Merchant_id']).size().reset_index(name='o8')
X = pd.merge(X, temp, how='left', on=['User_id', 'Merchant_id'])
# 用户领取的不同商家数
temp = X.groupby(['User_id', 'Merchant_id']).size()
temp = temp.groupby('User_id').size().reset_index(name='o9')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户当天领取的优惠券次数
temp = X.groupby(['User_id', 'Date_received']).size().reset_index(name='o10')
X = pd.merge(X, temp, how='left', on=['User_id', 'Date_received'])
# 用户当天不同优惠券领取次数
temp = X.groupby(['User_id', 'Coupon_id', 'Date_received']).size().reset_index(name='o11')
X = pd.merge(X, temp, how='left', on=['User_id', 'Coupon_id', 'Date_received'])
# 用户领取优惠券类别数
temp = X.groupby(['User_id', 'Coupon_id']).size()
temp = temp.groupby('User_id').size().reset_index(name='o12')
X = pd.merge(X, temp, how='left', on='User_id')
# 商家被领取的优惠券次数
temp = X.groupby('Merchant_id').size().reset_index(name='o13')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家优惠券的种类数
temp = X.groupby(['Merchant_id', 'Coupon_id']).size().reset_index(name='o14')
X = pd.merge(X, temp, how='left', on=['Merchant_id', 'Coupon_id'])
# 商家被领取优惠券不同用户数
temp = X.groupby(['Merchant_id', 'User_id']).size()
temp = temp.groupby('Merchant_id').size().reset_index(name='o15')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 商家优惠券所有种类数
temp = X.groupby(['Merchant_id', 'Coupon_id']).size()
temp = temp.groupby('Merchant_id').size().reset_index(name='o16')
X = pd.merge(X, temp, how='left', on='Merchant_id')
# 用户领取优惠券的时间间隔
temp = X.sort_values(by=['User_id', 'Date_received']).groupby('User_id')
X['o17'] = temp.Date_received.diff().dt.days
X['o18'] = temp.Date_received.diff(-1).dt.days.abs()
print(len(X), len(X.columns))
return X
def get_online_features(online, X):
# temp = online[online.Coupon_id == online.Coupon_id]
# coupon_consume = temp[temp.Date == temp.Date]
# coupon_no_consume = temp[temp.Date != temp.Date]
# 用户线上操作次数
temp = online.groupby('User_id').size().reset_index(name='on_u1')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户线上点击次数
temp = online[online.Action == 0].groupby('User_id').size().reset_index(name='on_u2')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户线上点击率
X['on_u3'] = X.on_u2 / X.on_u1
# 用户线上购买次数
temp = online[online.Action == 1].groupby('User_id').size().reset_index(name='on_u4')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户线上购买率
X['on_u5'] = X.on_u4 / X.on_u1
# 用户线上领取次数
temp = online[online.Coupon_id != 0].groupby('User_id').size().reset_index(name='on_u6')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户线上领取率
X['on_u7'] = X.on_u6 / X.on_u1
# 用户线上不消费次数
temp = online[(online.Date == date_null) & (online.Coupon_id != 0)]
temp = temp.groupby('User_id').size().reset_index(name='on_u8')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户线上优惠券核销次数
temp = online[(online.Date != date_null) & (online.Coupon_id != 0)]
temp = temp.groupby('User_id').size().reset_index(name='on_u9')
X = pd.merge(X, temp, how='left', on='User_id')
# 用户线上优惠券核销率
X['on_u10'] = X.on_u9 / X.on_u6
# 用户线下不消费次数占线上线下总的不消费次数的比重
X['on_u11'] = X.u3 / (X.on_u8 + X.u3)
# 用户线下的优惠券核销次数占线上线下总的优惠券核销次数的比重
X['on_u12'] = X.u2 / (X.on_u9 + X.u2)
# 用户线下领取的记录数量占总的记录数量的比重
X['on_u13'] = X.u1 / (X.on_u6 + X.u1)
print(len(X), len(X.columns))
print('----------')
return X
if __name__ == '__main__':
start = datetime.datetime.now()
print(start.strftime('%Y-%m-%d %H:%M:%S'))
cpu_jobs = os.cpu_count() - 1
date_null = pd.to_datetime('1970-01-01', format='%Y-%m-%d')
# 源数据null处理
off_train = null_process_offline(off_train, predict=False)
on_train = null_process_online(on_train)
off_test = null_process_offline(off_test, predict=True)
# 获取训练特征集,测试特征集
ProcessDataSet1, ProcessDataSet2, ProcessDataSet3 = data_process(off_train, on_train, off_test)
# 源数据处理后的数据保存为文件
# dataset_1 = get_offline_features(dataset1, feature1_off)
# ProcessDataSet1 = get_online_features(feature1_on, dataset_1)
ProcessDataSet1.to_csv('./dataset/ProcessDataSet1.csv', index=None)
# dataset_2 = get_offline_features(dataset2, feature2_off)
# ProcessDataSet2 = get_online_features(feature2_on, dataset_2)
ProcessDataSet2.to_csv('./dataset/ProcessDataSet2.csv', index=None)
# dataset_3 = get_offline_features(dataset3, feature3_off)
# ProcessDataSet3 = get_online_features(feature3_on, dataset_3)
ProcessDataSet3.to_csv('./dataset/ProcessDataSet3.csv', index=None)
4.模型部分
import warnings
warnings.filterwarnings("ignore")
import datetime
import os
import time
from concurrent.futures import ProcessPoolExecutor
from math import ceil
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier, ExtraTreesClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, GridSearchCV, StratifiedKFold
from sklearn.metrics import accuracy_score, classification_report, roc_auc_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from xgboost.sklearn import XGBClassifier
import xgboost as xgb
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import log_loss, roc_auc_score, auc, roc_curve
from sklearn import metrics
dataset1 = pd.read_csv('./dataset/ProcessDataSet1.csv')
dataset2 = pd.read_csv('./dataset/ProcessDataSet2.csv')
dataset3 = pd.read_csv('./dataset/ProcessDataSet3.csv')
dataset1.drop_duplicates(inplace=True)
dataset2.drop_duplicates(inplace=True)
dataset3.drop_duplicates(inplace=True)
dataset12 = pd.concat([dataset1, dataset2], axis=0)
dataset12.fillna(0, inplace=True)
dataset3.fillna(0, inplace=True)
predict_dataset = dataset3[['User_id', 'Coupon_id', 'Date_received']].copy()
predict_dataset.Date_received = pd.to_datetime(predict_dataset.Date_received, format='%Y-%m-%d')
predict_dataset.Date_received = predict_dataset.Date_received.dt.strftime('%Y%m%d')
Xdataset12 = dataset12.drop(
columns=['User_id', 'Merchant_id', 'Discount_rate', 'Date_received', 'discount_rate_x', 'discount_rate_y',
'Date', 'Coupon_id', 'label'], axis=1)
Xdataset3 = dataset3.drop(
columns=['User_id', 'Merchant_id', 'Discount_rate', 'Date_received', 'discount_rate_x', 'discount_rate_y',
'Coupon_id'], axis=1)
#分割训练数据
X_train, X_test, y_train, y_test = train_test_split(Xdataset12, dataset12.label, test_size=0.2, random_state=0)
AUC画图函数
def auc_curve(y,prob):
#y真实prob预测
fpr,tpr,threshold = roc_curve(y,prob) ###计算真阳性率和假阳性率
roc_auc = auc(fpr,tpr) ###计算auc的值
plt.figure()
lw = 2
plt.figure(figsize=(10,10))
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.3f)' % roc_auc) ###假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('AUC')
plt.legend(loc="lower right")
plt.show()
随机森林模型
#对各参数网格搜索:
param_test1 = {'n_estimators':[5,10,20,30]}
gsearch1 = GridSearchCV(estimator = RandomForestClassifier(min_samples_split=100,
min_samples_leaf=20,max_depth=8,random_state=10),
param_grid = param_test1, scoring='roc_auc',cv=2)
gsearch1.fit(X_train,y_train)
print(gsearch1.best_params_, gsearch1.best_score_)
param_test1 = {'n_estimators':[5,10,20,30]}
gsearch1 = GridSearchCV(estimator = RandomForestClassifier(min_samples_split=100,
min_samples_leaf=20,max_depth=8,random_state=10),
param_grid = param_test1, scoring='roc_auc',cv=2)
gsearch1.fit(X_train,y_train)
print(gsearch1.best_params_, gsearch1.best_score_)
param_test2 = {'max_depth':[1,2,3,5,7,9,11,13]}#, 'min_samples_split':[100,120,150,180,200,300]}
gsearch2 = GridSearchCV(estimator = RandomForestClassifier(n_estimators=50, min_samples_split=100,
min_samples_leaf=20,max_features='sqrt' ,oob_score=True, random_state=10),
param_grid = param_test2, scoring='roc_auc',iid=False, cv=5)
gsearch2.fit(x_train,y_train)
print( gsearch2.best_params_, gsearch2.best_score_)
rf1 = RandomForestClassifier(n_estimators= 50, max_depth=2, min_samples_split=100, min_samples_leaf=20,max_features='sqrt' ,oob_score=True, random_state=10)
rf1.fit(x_train,y_train)
print( rf1.oob_score_)
y_predprob = rf1.predict_proba(x_test)[:,1]
print( "AUC Score (Train): %f" % metrics.roc_auc_score(y_test, y_predprob))
param_test3 = {'min_samples_split':[80,100,120,140], 'min_samples_leaf':[10,20,30,40,50,100]}
gsearch3 = GridSearchCV(estimator = RandomForestClassifier(n_estimators= 50, max_depth=2,
max_features='sqrt' ,oob_score=True, random_state=10),
param_grid = param_test3, scoring='roc_auc',iid=False, cv=5)
gsearch3.fit(x_train,y_train)
print( gsearch3.best_params_, gsearch3.best_score_)
param_test4 = {'max_features':[3,5,7,9,11]}
gsearch4 = GridSearchCV(estimator = RandomForestClassifier(n_estimators= 50, max_depth=2, min_samples_split=80,
min_samples_leaf=10 ,oob_score=True, random_state=10),
param_grid = param_test4, scoring='roc_auc',iid=False, cv=5)
gsearch4.fit(x_train,y_train)
print( gsearch4.best_params_, gsearch4.best_score_)
最优参数
rf0 = RandomForestClassifier(n_estimators = 150, max_depth = 8,min_samples_split = 1000, min_samples_leaf = 30, max_features = 'auto', random_state = 12)
rf0.fit(X_train,y_train)
y_predprob = rf0.predict_proba(X_test)[:,1]
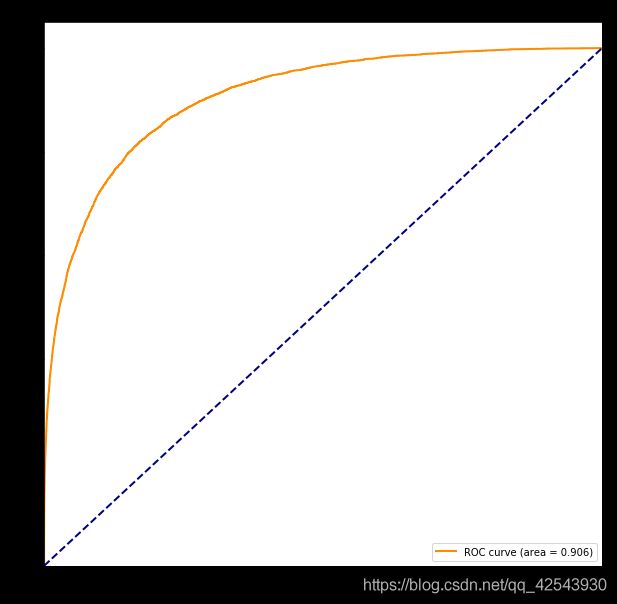
auc_curve(y_test, y_predprob)
画出ROC曲线并计算AUC值
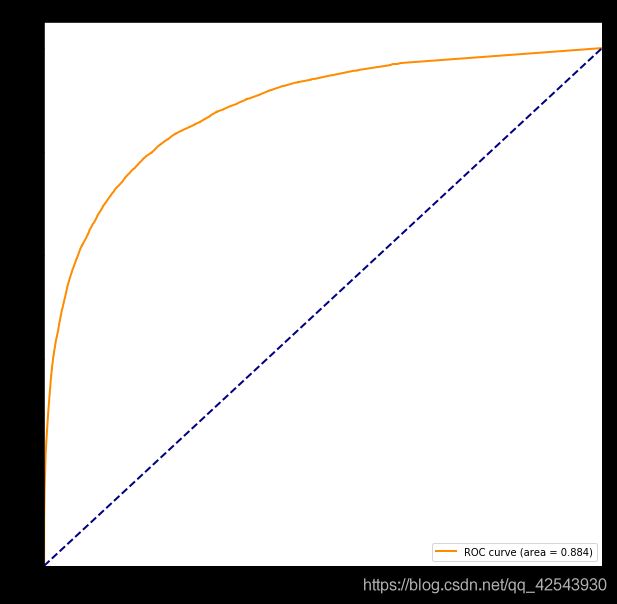
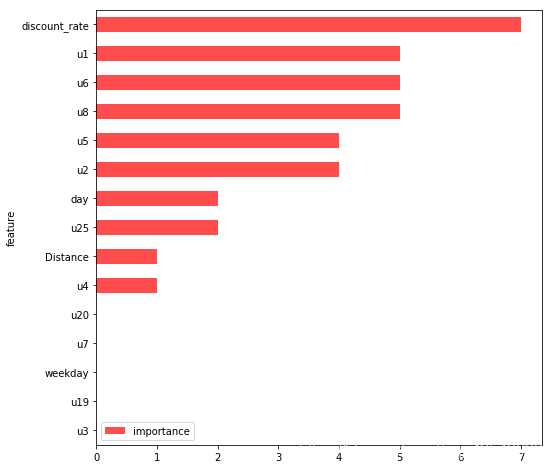
重要性排序
importances_values = rf0.feature_importances_[0:15]
importances = pd.DataFrame(importances_values, columns=["importance"])
feature_data = pd.DataFrame(X_train.columns[0:15], columns=["feature"])
importance = pd.concat([feature_data, importances], axis=1)
importance = importance.sort_values(["importance"], ascending=True)
importance["importance"] = (importance["importance"] * 1000).astype(int)
importance = importance.sort_values(["importance"])
importance.set_index('feature', inplace=True)
importance.plot.barh(color='r', alpha=0.7, rot=0, figsize=(8, 8))
plt.show()
XGB模型
#转为DMatrix格式
X_train, X_test, y_train, y_test = train_test_split(Xdataset12, dataset12.label, test_size=0.2, random_state=0)
train_dmatrix = xgb.DMatrix(X_train, label=y_train)
test_dmatrix = xgb.DMatrix(X_test, label=y_test)
cpu_jobs = os.cpu_count() - 1
params = {'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'gamma': 0.1,
'min_child_weight': 1.1,
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.01,
# 'tree_method': 'gpu_hist',
# 'n_gpus': '-1',
'seed': 0,
'nthread': cpu_jobs,
# 'predictor': 'gpu_predictor'
}
cvresult = xgb.cv(params, train_dmatrix, num_boost_round=5000, nfold=2, metrics='auc', seed=0, callbacks=[
xgb.callback.print_evaluation(show_stdv=False),
xgb.callback.early_stop(50)
])
num_round_best = cvresult.shape[0] - 1
print('Best round num: ', num_round_best)
# 使用优化后的num_boost_round参数训练模型
watchlist = [(train_dmatrix, 'train')]
model1 = xgb.train(params, train_dmatrix, num_boost_round=num_round_best, evals=watchlist)
model1.save_model('./model/xgb_model')
params['predictor'] = 'cpu_predictor'
model = xgb.Booster(params)
model.load_model('./model/xgb_model')
y_predprob = model.predict(test_dmatrix)
auc_curve(y_test, y_predprob)