SpringCloud05—服务容错保护:Spring Cloud Hystrix
- 5.服务容错保护:Spring Cloud Hystrix
- 5.1 产生来源
- 5.2 快速入门
- 5.3 使用详解
- 5.3.1 创建请求命令
- 5.4 定义服务降级
- 5.5 异常处理
- 5.5.1 异常传播
- 5.5.2 异常获取
- 5.6 命令名称、分组以及线程池的划分
- 5.6.1 通过继承HystrixCommand来实现命令的设置,分组以及线程池的划分
- 5.6.2 使用注解设置命令,分组以及对线程池的划分
- 5.7 请求缓存
- 5.7.1 开启请求缓存的功能
- 5.7.2 清理失效缓存
- 5.7.3 使用注解实现请求缓存
- 1.设置请求缓存
- 2.定义缓存Key
- 3.缓存清理
- 5.8 请求合并
- 5.8.1 通过继承HystrixCommand实现请求的合并
- 5.8.2 使用注解实现请求合并
- 5.8.3 请求合并的额外开销
上一篇:《SpringCloud04—客户端负载均衡 SpringCLoud Ribbon》
5.服务容错保护:Spring Cloud Hystrix
5.1 产生来源
在微服务架构中,存在着那么多的服务单元,若一个单元出现故障,就很容易因依赖关系而引发故障的蔓延,最终导致整个系统的瘫痪,这样的架构相较传统架构更加不稳定。为了解决这样的问题,产生了断路器等一系列的服务保护机制。
断路器模式源于Martin Fowler的Circuit Breaker一文。“断路器”本身是一种开关装置,用于在电路上保护线路过载,当线路中有电器发生短路时,“断路器”能够及时切断故障电路,防止发生过载、发热甚至起火等严重后果。
在分布式架构中,断路器模式的作用也是类似的,当某个服务单元发生故障(类似用电器发生短路)之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个错误响应,而不是长时间的等待。这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延。
针对上述问题,Spring Cloud Hystrix实现了断路器线程隔离等一系列服务保护功能。
它也是基于Netflix 的开源框架 Hystrix实现的,该框架的目标在于通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Hystrix具备服务降级、服务熔断、线程和信号隔离、请求缓存、请求合并以及服务监控等强大功能。
5.2 快速入门

这里我们需要启动的工程如下:
- eureka-server工程:服务注册中心,端口为1112。
- hello-service工程:HELLO一SERVICE 的服务单元,两个实例启动端口分别为8081和8082。
- ribbon-consume 工程:使用Ribbon实现的服务消费者,端口为9000。
在未加入断路器之前,关闭8081的实例,发送GET请求到http://localhost:9000/ribbon-consumer,可以获得下面的输出:

下面我们开始引入Spring Cloud Hystrix
- 在ribbon-consumer 工程的 pom.xml 的 dependency节点中引入 spring-cloud-starter-hystrix依赖:
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-netflix-hystrix-dashboardartifactId> <version>2.2.6.RELEASEversion> dependency> <dependency> <groupId>com.netflix.hystrixgroupId> <artifactId>hystrix-javanicaartifactId> <version>1.5.18version> dependency> - 在ribbon-consumer工程的主类RibbonConsumerApplication中使用@EnableCircuitBreaker注解开启断路器功能:
@EnableCircuitBreaker @MapperScan("com.cloud.ribbonconsumer.mapper") @EnableDiscoveryClient @SpringBootApplication public class RibbonConsumerApplication { @Bean @LoadBalanced RestTemplate restTemplate() { return new RestTemplate(); } public static void main(String[] args) { SpringApplication.run(RibbonConsumerApplication.class, args); } } - 改造服务消费方式,新增HelloService类,注入RestTemplate实例。然后,将在ConsumerController中对RestTemplate的使用迁移到helloservice函数中,最后,在helloservice函数上增加@HysstrixCommand注解来指定回调方法:
HelloService
HelloServiceImplpublic interface HelloService { String getHelloService(); }import com.cloud.ribbonconsumer.service.HelloService; import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.springframework.web.client.RestTemplate; @Service public class HelloServiceImpl implements HelloService { @Autowired RestTemplate restTemplate; @Override @HystrixCommand(fallbackMethod = "helloFallBack") public String getHelloService() { return restTemplate.getForEntity("http://HELLO-SERVICE/hello", String.class).getBody(); } public String helloFallBack() { return "服务中断"; } } - 修改ConsumerController类,注入上面实现的 HelloService 实例,并在helloConsumer中进行调用:
import com.cloud.ribbonconsumer.service.HelloService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RestController; @RestController public class ConsumerController { @Autowired HelloService helloService; @RequestMapping(value = "ribbon-consumer", method = RequestMethod.GET) public String helloConsumer() { return helloService.getHelloService(); } }
下面,我们来验证一下通过断路器实现的服务回调逻辑,重新启动之前关闭的8081端口的Hello-Service,确保此时服务注册中心、两个Hello-Service 以及 RIBBON-CONSUMER均已启动,访问http://localhost:9000/ribbon-consumer可以轮询两个HELLO-SERVICE并返回一些文字信息。
此时我们继续断开8081的HELLO-SERVICE,然后访问http://localhost:9000/ribbon-consumer,当轮询到8081服务端时,输出内容为error,不再是之前的错误内容,Hystrix的服务回调生效。
除了通过断开具体的服务实例来模拟某个节点无法访问的情况之外,我们还可以模拟一下服务阻塞(长时间未响应)的情况。
5.3 使用详解
在“快速入门”一节中我们已经使用过Hystrix中的核心注解@HystrixCommand,通过它创建了HystrixCommand的实现,同时利用fallback属性指定了服务降级的实现方法。然而这些还只是Hystrix使用的一小部分,在实现一个大型分布式系统时,往往还需要更多高级的配置功能。接下来我们将详细介绍Hystrix各接口和注解的使用方法。
5.3.1 创建请求命令
Hystrix命令就是我们之前所说的HystrixCommand,它用来封装具体的依赖服务调用逻辑。
我们可以通过继承的方式来实现,比如:
import com.cloud.ribbonconsumer.po.User;
import com.netflix.hystrix.HystrixCommand;
import org.springframework.web.client.RestTemplate;
public class UserCommand extends HystrixCommand<User> {
private RestTemplate restTemplate;
private Long id;
public UserCommand(Setter setter, RestTemplate restTemplate, Long id) {
super(setter);
this.restTemplate = restTemplate;
this.id = id;
}
@Override
protected User run() throws Exception {
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers", User.class, id);
}
}
通过上面实现的UserCommand,我们既可以实现请求的同步也可以实现异步执行
- 同步执行: User u=new UserCommand(restTemplate,1L).excute();
- 异步执行: Future futureUser=new UserCommand(restTemplate,1L)。queue();
异步执行的时候可以对返回的futureUser调用get方法来获取结果。
另外,也可以通过@HystrixcCommand注解来更为优雅地实现 Hystrix命令的定义,比如:
import com.cloud.ribbonconsumer.po.User;
import com.cloud.ribbonconsumer.service.HelloService;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
@Service
public class HelloServiceImpl implements HelloService {
@Autowired
RestTemplate restTemplate;
@Override
@HystrixCommand
public User getUserById(Long id) {
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id);
}
}
虽然@HystrixCommand注解可以非常优雅地定义Hystrix 命令的实现,但是如上定义的getUserById方式只是同步执行的实现,若要实现异步执行则还需另外定义,比如:
@Override
@HystrixCommand
public Future<User> getUserByIdAsync(String id) {
return new AsyncResult<User>(){
@Override
public User invoke(){
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id);
}
};
}
5.4 定义服务降级
fallback是 Hystrix命令执行失败时使用的后备方法,用来实现服务的降级处理逻辑。在HystrixCommand中可以通过重载getFallback ()方法来实现服务降级逻辑, Hystrix会在run ()执行过程中出现错误、超时、线程池
拒绝、断路器熔断等情况时,执行getFallback ()方法内的逻辑,比如我们可以用如下方式实现服务降级逻辑:
- 1.继承HystrixCommand
import com.cloud.ribbonconsumer.po.User;
import com.netflix.hystrix.HystrixCommand;
import org.springframework.web.client.RestTemplate;
public class UserCommand extends HystrixCommand<User> {
private RestTemplate restTemplate;
private Long id;
public UserCommand(Setter setter, RestTemplate restTemplate, Long id) {
super(setter);
this.restTemplate = restTemplate;
this.id = id;
}
@Override
protected User run() throws Exception {
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id);
}
@Override
protected User getFallback() {
return new User();
}
}
- 2.在 HystrixObservableCommand实现的Hystrix命令中,我们可以通过重载resumewithFallback 方法来实现服务降级逻辑。该方法会返回一个Observable对象,当命令执行失败的时候,Hystrix 会将observable中的结果通知给所有的订阅者。
若要通过注解实现服务降级只需要使用@HystrixCommand 中的fallbackMethod参数来指定具体的服务降级实现方法,如下所示:import com.cloud.ribbonconsumer.po.User; import com.cloud.ribbonconsumer.service.HelloService; import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.springframework.web.client.RestTemplate; @Service public class HelloServiceImpl implements HelloService { @Autowired RestTemplate restTemplate; @Override @HystrixCommand(fallbackMethod = "defaultUser") public User getUserById(Long id) { return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id); } public User defaultUser() { return new User(); } }
在使用注解来定义服务降级逻辑时,我们需要将具体的Hystrix命令与fallback实现函数定义在同一个类中,并且fallbackMethod的值必须与实现fallback方法的名字相同。由于必须定义在一个类中,所以对于fallback 的访问修饰符没有特定的要求,定义为private、protected、public均可。
在实际使用时,我们需要为大多数执行过程中可能会失败的Hystrix命令实现服务降级逻辑,但是也有一些情况可以不去实现降级逻辑,如下所示。
- 执行写操作的命令:当Hystrix命令是用来执行写操作而不是返回一些信息的时候,通常情况下这类操作的返回类型是void或是为空的Observable,实现服务降级的意义不是很大。当写入操作失败的时候,我们通常只需要通知调用者即可。
- 执行批处理或离线计算的命令:当Hystrix命令是用来执行批处理程序生成一份报告或是进行任何类型的离线计算时,那么通常这些操作只需要将错误传播给调用者,然后让调用者稍后重试而不是发送给调用者一个静默的降级处理响应。
不论Hystrix命令是否实现了服务降级,命令状态和断路器状态都会更新,并且我们可以由此了解到命令执行的失败情况。
5.5 异常处理
5.5.1 异常传播
在HystrixCommand实现的run()方法中抛出异常时,除了HystrixBadRequest-Exception之外,其他异常均会被ystrix认为命令执行失败并触发服务降级的处理逻辑,所以当需要在命令执行中抛出不触发服务降级的异常时来使用它。
而在使用注册配置实现Hystrix命令时,它还支持忽略指定异常类型功能,只需要通过
设置@HystrixCommand注解的ignoreExceptions参数,比如:
@HystrixCommand(ignoreExceptions = {HystrixBadRequestException.class})
public User getUserById(Long id) {
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id);
}
如上面代码的定义,当getUserById方法抛出了类型为BadRequestException的异常时,Hystrix会将它包装在Hystri xBadRequestException中抛出,这样就不会触发后续的fallback 逻辑。
5.5.2 异常获取
使用注解配置方式可以很简单的实现异常的获取。只需要在fallback实现方法的参数中增加Throwable e对象的定义,这样在方法内部就可以获取触发服务降级的具体异常内容了,比如:
@HystrixCommand(fallbackMethod = "fallback1")
public String getUserInfo() {
throw new RuntimeException("getUserInfo command failed");
}
String fallback1(Throwable e) {
assert "getUserInfo command failed".equals(e.getMessage()) : "降级服务仍然异常";
return null;
}
5.6 命令名称、分组以及线程池的划分
5.6.1 通过继承HystrixCommand来实现命令的设置,分组以及线程池的划分
public class UserCommand extends HystrixCommand<User> {
private RestTemplate restTemplate;
private Long id;
public UserCommand() {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("CommandGroupKey"))
.andCommandKey(HystrixCommandKey.Factory.asKey("CommandKey"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("ThreadPoolKey")));
}
}
从上面Setter的使用中可以看到,我们并没有直接设置命令名称,而是先调用了withGroupKey来设置命令组名,然后才通过调用andCommandKey来设置命令名。
这是因为在Setter的定义中,只有withGroupKey静态函数可以创建Setter的实例,所以GroupKey是每个Setter必需的参数,而CommandKey则是-一个 可选参数。
通过设置命令组,Hystrix会根据组来组织和统计命令的告警、仪表盘等信息。那么为什么一定要设置命令组呢?
因为除了根据组能实现统计之外,Hystrix命令默认的线程划分也是根据命令分组来实现的。默认情况下,Hystrix会让相同组名的命令使用同一个线程池,所以我们需要在创建Hystrix命令时为其指定命令组名来实现默认的线程池划分。如果Hystrix的线程池分配仅仅依靠命令组来划分,那么它就显得不够灵活了,所以Hystrix还提供了HystrixThreadPoolKey 来对线程池进行设置,通过它我们可以实现更细粒度的线程池划分
如果在没有特别指定HystrixThreadPoolKey的情况下,依然会使用命令组的方式来划分线程池。通常情况下,尽量通过HystrixThreadPoolKey的方式来指定线程池的划分,而不是通过组名的默认方式实现划分,因为多个不同的命令可能从业务逻辑上来看属于同一个组,但是往往从实现本身上需要跟其他命令进行隔离。
5.6.2 使用注解设置命令,分组以及对线程池的划分
@HystrixCommand(commandKey = "getUdserInfo", groupKey = "UserGroup", threadPoolKey = "getUserInfoThread", fallbackMethod = "fallback1")
public String getUserInfo() {
throw new RuntimeException("getUserInfo command failed");
}
5.7 请求缓存
当系统用户不断增长时,每个微服务需要承受的并发压力也越来越大。在分布式环境下,通常压力来自于对依赖服务的调用,因为请求依赖服务的资源需要通过通信来实现,这样的依赖方式比起进程内的调用方式会引起一部分的性能损失,同时HTTP相比于其他高性能的通信协议在速度上没有任何优势,所以它有些类似于对数据库这样的外部资源进行读写操作,在高并发的情况下可能会成为系统的瓶颈。
既然如此,我们很容易地可以联想到,类似数据访问的缓存保护是否也可以应用到依赖服务的调用上呢?
答案显而易见,在高并发的场景之下,Hystrix中提供了请求缓存的功能,我们可以方便地开启和使用请求缓存来优化系统,达到减轻高并发时的请求线程消耗、降低请求响应时间的效果。
5.7.1 开启请求缓存的功能
Hystrix请求缓存的使用非常简单,我们只需要在实现HystrixCommand或HystrixObservableCommand时,通过重载getCacheKey ()方法来开启请求缓存,比如:
import com.cloud.ribbonconsumer.po.User;
import com.netflix.hystrix.HystrixCommand;
import com.netflix.hystrix.HystrixCommandGroupKey;
import com.netflix.hystrix.HystrixCommandKey;
import com.netflix.hystrix.HystrixThreadPoolKey;
import org.springframework.web.client.RestTemplate;
public class UserCommand extends HystrixCommand<User> {
private RestTemplate restTemplate;
private Long id;
public UserCommand(Setter setter, RestTemplate restTemplate, Long id) {
super(setter);
this.restTemplate = restTemplate;
this.id = id;
}
@Override
protected User run() throws Exception {
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id);
}
@Override
protected User getFallback() {
return new User();
}
@Override
protected String getCacheKey() {
//根据id置入缓存
return String.valueOf(id);
}
}
在上面的例子中,我们通过在getCacheKey方法中返回的请求缓存key值(使用了传入的获取User对象的id值),就能让该请求命令具备缓存功能。此时,当不同的外部请求处理逻辑调用了同一个依赖服务时,Hystrix 会根据getCacheKey方法返回的值来区分是否是重复的请求,如果它们的cacheKey相同,那么该依赖服务只会在第一个请求到达时被真实地调用一次,另外一个请求则是直接从请求缓存中返回结果,所以通过开启请求缓存可以让我们实现的Hystrix 命令具备下面几项好处:
- 减少重复的请求数,降低依赖服务的并发度。
- 在同一用户请求的上下文中,相同依赖服务的返回数据始终保持一致。
- 请求缓存在run()和construct()执行之前生效,所以可以有效减少不必要的线程开销。
5.7.2 清理失效缓存
使用请求缓存时,如果只是读操作,那么就不需要考虑缓存中的内容是否正确的问题,但是如果请求中还有更新的写操作,那么缓存中的数据就需要我们在进行写操作时进行及时的处理以防止读操作的请求命令获取到失效的数据
在Hystrix中,我们可以通过HystrixRequestCache.clear()方法来进行缓存清理,如下所示:
import com.cloud.ribbonconsumer.po.User;
import com.netflix.hystrix.*;
import com.netflix.hystrix.strategy.concurrency.HystrixConcurrencyStrategyDefault;
import org.springframework.web.client.RestTemplate;
public class UserGetCommand extends HystrixCommand<User> {
private RestTemplate restTemplate;
private Long id;
private static final HystrixCommandKey GETTTER_KEY = HystrixCommandKey.Factory.asKey("CommandKey");
public UserGetCommand(RestTemplate restTemplate, Long id) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("GetSetGet"))
.andCommandKey(HystrixCommandKey.Factory.asKey("GETTTER_KEY"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("ThreadPoolKey")));
this.restTemplate = restTemplate;
this.id = id;
}
@Override
protected User run() throws Exception {
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id);
}
@Override
protected User getFallback() {
return new User();
}
@Override
protected String getCacheKey() {
//根据id置入缓存
return String.valueOf(id);
}
public static void flushCache(Long id) {
//刷新缓存,根据id进行清理
HystrixRequestCache.getInstance(GETTTER_KEY, HystrixConcurrencyStrategyDefault.getInstance()).clear(String.valueOf(id));
}
}
import com.cloud.ribbonconsumer.po.User;
import com.netflix.hystrix.*;
import org.springframework.web.client.RestTemplate;
public class UserPostCommand extends HystrixCommand<User> {
private RestTemplate restTemplate;
private User user;
private static final HystrixCommandKey CommandKey = HystrixCommandKey.Factory.asKey("CommandKey");
public UserPostCommand(RestTemplate restTemplate, User user) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("GetSetGet")));
this.restTemplate = restTemplate;
this.user = user;
}
@Override
protected User run() throws Exception {
//写操作
User r = restTemplate.postForObject("http://user-service/users", user, User.class);
//刷新缓存,清理缓存中失效的user
UserGetCommand.flushCache(user.getId());
return r;
}
@Override
protected User getFallback() {
return new User();
}
}
该示例中主要有两个请求命令:
- UserGetCommand 用于根据id获取User 对象
- UserPostCommand用于更新User对象。
当我们对UserGetCommand命令实现了请求缓存之后,那么势必需要为UserPostCommand命令实现缓存的清理,以保证User被更新之后,Hystrix请求缓存中相同缓存Key的结果被移除,这样在下一次获取User的时候不会从缓存中获取到未更新的结果。
我们可以看到,在上面UserGetCommand的实现中,增加了一个静态方法flushCache,该访法通过HystrixRequestCache.getInstance (GETTER_ KEY, HystrixConcurrency-StrategyDefault. getInstance())方法从默认的Hystrix并发策略中根据GETTER_ KEY获取到该命令的请求缓存对象HystrixRequestCache的实例,然后再调用该请求缓存对象实例的clear方法,对Key为更新User的id值的缓存内容进行清理。
而在UserPostCommand 的实现中,在run 方法调用依赖服务之后,增加了对UserGetCommand中静态方法flushCache的调用,以实现对失效缓存的清理。
5.7.3 使用注解实现请求缓存
| 注解 | 描述 | 属性 |
|---|---|---|
| @CacheResult | 该注解用来标记请求命令返回的结果应该被缓存,它必须与@HystrixCommand注解结合使用 | cacheKeyMethod |
| @CacheRemove | 该注解用来让请求命令的缓存失效,失效的缓存根据定义的Key决定 | commandKey,cacheKeyMethod |
| @CacheKey | 该注解用来在请求命令的参数上标记,使其作为缓存的Key值,如果没有标注则会使用所有参数。如果同时还使用了@CacheResult和@CacheRemove注解的cacheKeyMethod方法指定缓存Key的生成,那么该注解将不会起作用 | value |
下面我们从几个方面的实例来看看这几个注解的具体使用方法。
1.设置请求缓存
通过注解为请求命令开启缓存功能非常简单,如下例所示,我们只需添加@CacheResult注解即可。当该依赖服务被调用并返回User对象时,由于该方法被@CacheResult注解修改,所以Hystrix 会将该结果置入请求缓存中,而它的缓存Key值会使用所有的参数,也就是这里Long类型的id值。
@CacheResult
@HystrixCommand
public User getUserById(Long id) {
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id);
}
2.定义缓存Key
当使用注解来定义请求缓存时,若要为请求命令指定具体的缓存Key生成规则,我们可以使用@CacheResult和@CacheRemove 注解的cacheKeyMethod方法来指定具体的生成函数;也可以通过使用@CacheKey注解在方法参数中指定用于组装缓存Key的元素。
使用cacheKeyMethod方法的示例如下,它通过在请求命令的同-一个类中定义一个专门生成Key的方法,并用@CacheResult注解的cacheKeyMethod方法来指定它即可。它的配置方式类似于@HystrixCommand服务降级fallbackMethod的使用。
@CacheResult(cacheKeyMethod = "getUserByIdCacheKey")
@HystrixCommand(ignoreExceptions = {HystrixBadRequestException.class})
public User getUserById(Long id) {
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id);
}
private Long getUserByIdCacheKey(Long id) {
return id;
}
通过@CacheKey注解实现的方式更加简单,具体示例如下所示。但是在使用@CacheKey注解的时候需要注意,它的优先级比cacheKeyMethod的优先级低,如果已经使用了cacheKeyMethod指定缓存Key的生成函数,那么@CacheKey 注解不会生效。
@CacheResult
@HystrixCommand
public User getUserById(@CacheKey("id") Long id) {
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id);
}
3.缓存清理
在之前的例子中,我们已经通过@CacheResult注解将请求结果置入Hystrix的请求缓存之中。若该内容调用了update 操作进行了更新,那么此时请求缓存中的结果与实际结果就会产生不一致 (缓存中的结果实际上已经失效了),所以我们需要在update类型的操作上对失效的缓存进行清理。
在Hystrix 的注解配置中,可以通过@CacheRemove注解来实现失效缓存的清理,比如下面的例子所示:
@CacheResult
@HystrixCommand
public User getUserById(@CacheKey("id") Long id) {
return restTemplate.getForObject("http://HELLO-SERVICE/getUsers/{1}", User.class, id);
}
@CacheRemove(commandKey = "getUserById")
@HystrixCommand
public void update(@CacheKey("id") User user) {
User r = restTemplate.postForObject("http://user-service/users", user, User.class);
}
需要注意的是,@CacheRemove注解的comnandKey属性是必须要指定的,它用来指明需要使用请求缓存的请求命令,因为只有通过该属性的配置,Hytrix才能找到正确的请求命令缓存位置。
5.8 请求合并
5.8.1 通过继承HystrixCommand实现请求的合并
微服务架构中的依赖通常通过远程调用实现,而远程调用中最常见的问题就是通信消耗与连接数占用。在高并发的情况之下,因通信次数的增加,总的通信时间消耗将会变得不那么理想。同时,因为依赖服务的线程池资源有限,将出现排队等待与响应延迟的情况。为了优化这两个问题,Hystrix 提供了HystrixCollapser来实现请求的合并,以减少通信消耗和线程数的占用。
HystrixCollapser实现了在HystrixCommand之前放置-一个合并处理器, 将处于一个很短的时间窗(默认10毫秒)内对同–依赖服务的多个请求进行整合并以批量方式发起请求的功能(服务提供方也需要提供相应的批量实现接口)。通过HystrixCollapser的封装,开发者不需要关注线程合并的细节过程,只需关注批量化服务和处理。下面我们从HystrixCollapser的使用实例中对其合并请求的过程一探究竟。
假设当前微服务USER-SERVICE提供了两个获取User的接口。
- /users/ {id}:根据id返回User对象的GET请求接口。
- /users?ids={ids}:根据ids返回User对象列表的GET请求接口,其中ids为以逗号分隔的id集合。
@Service
public class UserServiceImpl implements UserService {
@Autowired
private RestTemplate restTemplate;
@Override
public User find(Long id) {
return restTemplate.getForObject("http://user-service/users/{1}", User.class, id);
}
@Override
public List<User> findAll(List<Long> ids) {
return restTemplate.getForObject("http://user-service/users?ides={1}", List.class, StringUtils.join(ids, ""));
}
}
接下来我们实现将短时间内获取多个单一的User对象的请求命令进行合并
- 第一步,为请求合并的实现准备一个批量请求命令的实现,具体如下:
import com.cloud.ribbonconsumer.po.User;
import com.cloud.ribbonconsumer.service.UserService;
import com.netflix.hystrix.*;
import java.util.List;
public class UserBatchCommand extends HystrixCommand<List<User>> {
UserService userService;
List<Long> userIds;
public UserBatchCommand(UserService userService, List<Long> userIds) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("userServiceCommand")));
this.userIds = userIds;
this.userService = userService;
}
@Override
protected List<User> run() throws Exception {
return userService.findAll(userIds);
}
}
批量请求命令实际上就是一个简单的HystrixCommand 实现,从上面的实现中可以看到它通过调用userService.findAll方法来访问/users?ids={ids}接口以返回User的列表结果。
- 第二步,通过继承HystrixCollapser实现请求合并器:
import com.cloud.ribbonconsumer.po.User;
import com.cloud.ribbonconsumer.service.UserService;
import com.netflix.hystrix.*;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.stream.Collectors;
public class UserCollapseCommand extends HystrixCollapser<List<User>, User, Long> {
private UserService userService;
private Long userId;
public UserCollapseCommand(UserService userService, Long userId) {
super(Setter.withCollapserKey(HystrixCollapserKey.Factory.asKey("userCollapseCommand"))
.andCollapserPropertiesDefaults(
HystrixCollapserProperties.Setter().withTimerDelayInMilliseconds(100)
));
this.userService = userService;
this.userId = userId;
}
@Override
public Long getRequestArgument() {
return userId;
}
@Override
protected HystrixCommand<List<User>> createCommand(Collection<CollapsedRequest<User, Long>> collapsedRequests) {
List<Long> userIds = new ArrayList<>(collapsedRequests.size());
userIds.addAll(collapsedRequests.stream().map(CollapsedRequest::getArgument).collect(Collectors.toList()));
return new UserBatchCommand(userService, userIds);
}
@Override
protected void mapResponseToRequests(List<User> batchResponse, Collection<CollapsedRequest<User, Long>> collapsedRequests) {
int count = 0;
for (CollapsedRequest<User, Long> collapsedRequest : collapsedRequests) {
User user = batchResponse.get(count++);
collapsedRequest.setResponse(user);
}
}
}
在上面的构造函数中,我们为请求合并器设置了时间延迟属性,合并器会在该时间窗内收集获取单个User的请求并在时间窗结束时进行合并组装成单个批量请求。
getRequestArgument方法返回给定的单个请求参数userId,而createCommand和mapResponseToRequests是请求合并器的两个核心。
- createCommand: 该方法的collapsedRequests参数中保存了延迟时间窗中收集到的所有获取单个User的请求。通过获取这些请求的参数来组织,上面我们准备的批量请求命令UserBatchCommand实例。
- mapResponseToRequests: 在批量请求命令UserBa tchCommand实例被触发执行完成之后,该方法开始执行,其中batchResponse 参数保存了createCommand中组织的批量请求命令的返回结果,而collapsedRequests参数则代表了每个被合并的请求。在这里我们通过遍历批量结果batchResponse对象,为collapsedRequests中每个合并前的单个请求设置返回结果,以此完成批量结果到单个请求结果的转换。
下图展示了在未使用HystrixCollapser请求合并器之前的线程使用情况。可以看到,当服务消费者同时对USER-SERVICE的/users/{id}接口发起了5个请求时,会向该依赖服务的独立线程池中申请5个线程来完成各自的请求操作。
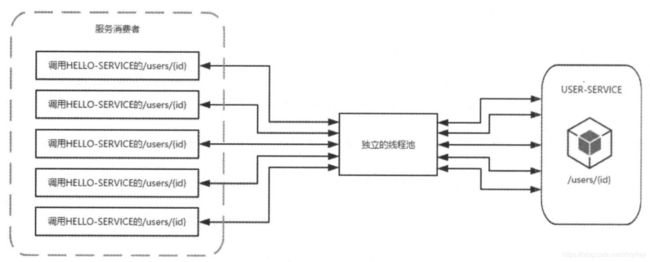
而在使用了HystrixCollapser 请求合并器之后,相同情况下的线程占用如下图所示。由于同一时间发生的5个请求处于请求合并器的一个时间窗内,这些发向/users/{id}接口的请求被请求合并器拦截下来,并在合并器中进行组合,然后将这些请求合并成一个请求发向USER-SERVICE的批量接口/users?ids={ids }。在获取到批量请求结果之后,通过请求合并器再将批量结果拆分并分配给每个被合并的请求。从图中我们可以看到,通过使用请求合并器有效减少了对线程池中资源的占用。所以在资源有效并且短时间内会产生高并发请求的时候,为避免连接不够用而引起的延迟可以考虑使用请求合并器的方式来处理和优化。

5.8.2 使用注解实现请求合并
import com.cloud.ribbonconsumer.po.User;
import com.cloud.ribbonconsumer.service.UserService;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCollapser;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixProperty;
import org.apache.commons.lang.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.List;
@Service
public class UserServiceImpl implements UserService {
@Autowired
private RestTemplate restTemplate;
@Override
@HystrixCollapser(batchMethod = "findAll", collapserProperties = {
@HystrixProperty(name = "timerDelayInMilliseconds", value = "100")
})
public User find(Long id) {
return restTemplate.getForObject("http://user-service/users/{1}", User.class, id);
}
@Override
@HystrixCommand
public List<User> findAll(List<Long> ids) {
return restTemplate.getForObject("http://user-service/users?ides={1}", List.class, StringUtils.join(ids, ""));
}
}
我们之前已经介绍过@HystrixCommand了,可以看到,这里通过它定义了两个Hystrix命令:
- 一个用于请求/users/ {id}接口
- 一个用于请求/users?ids= {ids}接口。
而在请求/users/{id}接口的方法上通过@HystrixCollapser注解为其创建了合并请求器,通过batchMethod属性指定了批量请求的实现方法为findAll方法(即请求/users?ids={ids }接口的命令),同时通过collapserProperties属性为合并请求器设置了相关属性,这里使用@HystrixProperty(name=“timerDelayInMilliseconds”,value = “100”)将合并时间窗设置为100 毫秒。这样通过@HystrixCollapser注解简单而又优雅地实现了在/users/{id}依赖服务之前设置了一个批量请求合并器。
5.8.3 请求合并的额外开销
虽然通过请求合并可以减少请求的数量以缓解依赖服务线程池的资源,但是在使用的时候也需要注意它所带来的额外开销:用于请求合并的延迟时间窗会使得依赖服务的请求延迟增高。
比如,某个请求不通过请求合并器访问的平均耗时为5ms,请求合并的延迟时间窗为10ms (默认值),那么当该请求设置了请求合并器之后,最坏情况下(在延迟时间窗结束时才发起请求)该请求需要15ms才能完成。
由于请求合并器的延迟时间窗会带来额外开销,所以我们是否使用请求合并器需要根据依赖服务调用的实际情况来选择,主要考虑下面两个方面。
- 请求命令本身的延迟 如果依赖服务的请求命令本身是一个高延迟的命令,那么可以使用请求合并器,因为延迟时间窗的时间消耗显得微不足道了。
- 延迟时间窗内的并发量 如果一个时间窗内只有1~2个请求,那么这样的依赖服务不适合使用请求合并器。这种情况不但不能提升系统性能,反而会成为系统瓶颈,因为每个请求都需要多消耗-一个时间窗才响应。相反,如果一个时间窗内具有很高的并发量,并且服务提供方也实现了批量处理接口,那么使用请求合并器可以有效减少网络连接数量并极大提升系统吞吐量,此时延迟时间窗所增加的消耗就可以忽略不计了。
下一篇:《SpringCloud06—声明式服务调用:Spring Cloud Feign》