lego-loam数据
The topics covered in this post are as follows
这篇文章涵盖的主题如下
Introduction
介绍
The Task
任务
The fastai DataBlock API
Fastai DataBlock API
Training A Classification Model
训练分类模型
Interpreting A Classification Model
解释分类模型
You can click on any topic above to navigate to the respective section
您可以单击上面的任何主题以导航到相应部分
介绍(Introduction)
Image Classification has been a very common task since time immemorial however it wasn’t until Deep Learning that computers were proficient at doing this task. With the advent of Convolutional Neural Networks this task has become so good that in recent years computers have also beat humans in few classification applications. Building a model to do image classification (MNIST digit recognition) marks the start of the deep learning journey for many beginners. Let’s therefore do the same only let’s make it even more exciting by using a dataset curated on Kaggle called LEGO Minifigures classification.
自远古以来,图像分类一直是非常常见的任务,但是直到深度学习计算机才精通此任务。 随着卷积神经网络的出现,这项任务变得如此出色,以至于近年来计算机在少数分类应用中也击败了人类。 建立模型进行图像分类(MNIST数字识别)标志着许多初学者开始深度学习的旅程。 因此,让我们做同样的事情,只是使用在Kaggle上精选的称为LEGO Minifigures分类的数据集,使其更加令人兴奋。
fastai developed by Jeremy Howard and Sylvain Gugger is a library built on top of PyTorch for deep learning practitioners to ease the process of building/training and inferring from DL models. With relatively a very short code, you can build state of the art models for almost all tasks (classification, regression (on both structured & unstructured data), collaborative filtering etc.)using this library; that’s the amount of effort that has gone into making it. So let’s leverage it to our benefit and start with this task of image classification.
由杰里米·霍华德(Jeremy Howard)和西尔万·古格(Sylvain Gugger)开发的fastai是在PyTorch之上构建的库,供深度学习从业人员使用,以简化构建/训练和从DL模型推断的过程。 使用相对较短的代码,您可以使用该库为几乎所有任务(分类,回归(在结构化和非结构化数据上),协作过滤等)建立最新模型。 这就是为此付出的努力。 因此,让我们利用它来受益,并从图像分类这一任务开始。
任务 (The Task)
We have images of 27 different mini-figures built by Lego which are obtained from Kaggle here. We have to build a classifier which when given an image of a particular minifigure can tell which superhero/character it is. Let’s read in the dataset and have a look at few entries from the same.
我们有乐高(Lego)建造的27种不同小人像的图像,这些图像是从Kaggle这里获得的。 我们必须构建一个分类器,当给定特定人像的图像时,该分类器可以分辨出它是哪个超级英雄/字符。 让我们阅读数据集,看看来自同一数据集的一些条目。
# Get the necessary imports
import pandas as pd
from IPython.display import display_html
# Read in the index and metadata files and display the structure of the same
paths_dframe = pd.read_csv('./index.csv', index_col=0)
metadata = pd.read_csv('./metadata.csv', index_col=0)
print(f"Index file:")
display_html(paths_dframe.head().to_html(), raw = True)
print(f"\nMetadata file:")
display_html(metadata.head().to_html(), raw = True)
As we can see that the index file holds the information required to load the data that needs to be fed to the model and the metadata contains information about the different classes.
如我们所见,索引文件包含加载需要馈送到模型的数据所需的信息,并且元数据包含有关不同类的信息。
When we take a close look at the minifigures, it is observed that both class_id 1 and class_id 17 represent SPIDER-MAN. The SPIDER-MAN from class_id 17 is from a marvel superheroes collection and is therefore renamed accordingly to MARVEL SPIDER-MAN. Once that’s done, we can then join the index and metadata files on the class_id as primary key.
当我们仔细观察这些小图时,可以看到class_id 1和class_id 17都代表蜘蛛侠。 来自class_id 17的SPIDER-MAN来自奇迹超级英雄集合,因此相应地重命名为MARVEL SPIDER-MAN。 完成后,我们可以将class_id上的索引和元数据文件加入为主键。
Also, the DataBlock API expects the column train-valid to be a column of boolean values which have a value true if the row belongs to validation set and false otherwise. Hence making that change as well and after completing all of this, the final dataframe is as shown below.
另外,DataBlock API期望train-valid列为一列布尔值,如果该行属于验证集,则其值为true,否则为false。 因此,也进行更改,完成所有这些操作后,最终数据帧如下所示。
# On looking closely, we can observe that the minigigure name for marvel's spiderman and sony's spiderman are the same.
# We need to change that before we merge the two datasets together
minifigure_names = metadata.minifigure_name
minifigure_names[16] = "MARVEL SPIDER-MAN"
metadata.minifigure_name = minifigure_names
# Keep only the two required columns in the metadata
metadata = metadata[["class_id", "minifigure_name"]]
# Now merge the two datasets on class_id and override the path dataframe by this new dataframe
paths_dframe = pd.merge(paths_dframe, metadata, how = "inner", on = "class_id")
# Change the train-valid column to include a boolean field indicating whether the item is a validation item
paths_dframe["train-valid"] = paths_dframe["train-valid"].apply(lambda x: x == "valid")
# Display a few entries from the paths dataframe
display_html(paths_dframe.head().to_html(), raw = True)
Let’s have a look at the number of images that we have in train and validation sets respectively. It’s generally good to have them in equal proportions and also they should both belong to the same population. Let’s see how the distribution of data looks like.
让我们看一下训练集和验证集中的图像数量。 通常,以相等的比例来分配它们是很好的,而且它们都应该属于同一人口。 让我们看看数据的分布情况如何。
# Check the train-valid counts to get an idea of number of train and validation images in the dataset
valid_n = paths_dframe["train-valid"].sum()
train_n = len(paths_dframe) - valid_n
labels = ["train", "valid"]
fig, ax = plt.subplots(1, 1)
ax.bar(labels, [train_n, valid_n])
ax.set_title("Distribution of Data in Train & Validation Sets", fontsize = 15)
plt.show()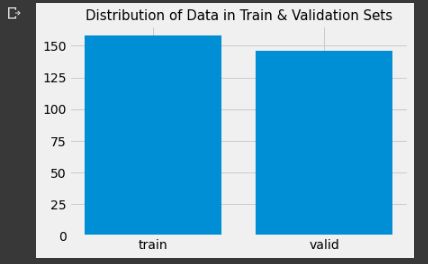
The dataset looks pretty much balanced with almost a hundred and fifty elements each in train and validation sets. Well, with respect to image standards, this number is pretty low for training a Neural Network classifier. Deep Neural Networks learn good representation functions when there’s a lot of images. A few hundreds or thousands of images per classification label is pretty normal with respect to normal deep learning standards. Over here we have a combined 300 odd images for 27 classes which means we have not more than 10–12 images per class. Let’s see how good a model we can build using this data.
数据集看起来非常平衡,在训练和验证集中每个都有近一百五十个元素。 好吧,关于图像标准,对于训练神经网络分类器来说,这个数字非常低。 当有很多图像时,深度神经网络会学习良好的表示功能。 相对于正常的深度学习标准,每个分类标签数百或数千个图像是非常正常的。 在这里,我们为27个班级组合了300张奇数图像,这意味着每班不超过10–12张图像。 让我们看看我们可以使用这些数据构建的模型有多好。
Fastai DataBlock API (The fastai DataBlock API)
A substantial amount of time is consumed in curating the data in a format suitable to feed to the deep learning model in any application. To simplify this process so that any DL Practitioner can focus on the model building and interpretation more than data curation, fastai came up with the DataBlock API which is excellent at data curation.
以适合任何应用程序中的深度学习模型的格式来整理数据时,会花费大量时间。 为了简化此过程,以便任何DL Practitioner都可以专注于模型构建和解释,而不是数据管理,fastai提出了DataBlock API,它在数据管理方面非常出色。
Generally, data is structured in one of the following two ways
通常,数据是通过以下两种方式之一构建的
Imagenet目录结构(The Imagenet Directory Structure)
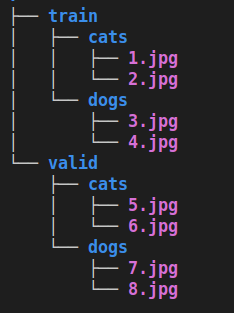
In this format, data is curated folderwise. There are separate folders for train and validation sets and each of them have folders corresponding to the respective classes that have the relevant data corresponding to those classes. The tree structure aside is for a cat-dog dataset curated in an Imagenet directory kind of style.
以这种格式,数据按文件夹进行整理。 有用于训练和验证集的单独文件夹,并且每个文件夹都有对应于相应类别的文件夹,这些文件夹具有与那些类别相对应的相关数据。 除了树形结构外,它还以Imagenet目录类型的样式整理了猫狗数据集。
在CSV中包装信息 (Wrapping info in a csv)
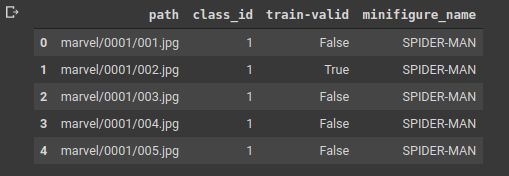
In this method, the information about how the data is structured is wrapped in a csv. It has all information like the path to the data, class of the data, whether or not the item belongs to training or validation set and so forth. Our current dataset is curated in this particular format which we will leverage to create a datablock.
在此方法中,有关数据结构的信息包装在csv中。 它具有所有信息,例如数据路径,数据类别,项目是否属于训练集或验证集等。 我们当前的数据集以这种特定格式进行整理,我们将利用它来创建数据块。
fastai’s datablock API provides support for both of these structures and even a few more however, we’ll look at the general structure of the API and how we can use the same for the sake of this problem.
fastai的datablock API提供了对这两种结构以及更多结构的支持,但是,我们将研究API的常规结构,以及如何针对此问题使用相同的结构。
base_path = "./"
dblock = DataBlock(blocks=(ImageBlock, CategoryBlock),
# Specify on which column to split for train and validation items
splitter=ColSplitter(col="train-valid"),
# Specify which columns contain the paths of files with an optional prefix or suffix
get_x=ColReader(cols = 0, pref = base_path),
# Specify which columns to extract labels for the items from
get_y=ColReader(cols = 3),
# Specify Item Transforms
item_tfms=Resize(224),
# Specify Batch Transforms
batch_tfms=aug_transforms())The datablock API takes in several arguments some of which are compuslory and some are optional. We’ll go through each one of them sequentially.
数据块API接受几个参数,其中一些是compuslory,一些是可选的。 我们将按顺序逐一处理它们。
blocks: In order to specify the input and output. Here, we have an Image as an input and a category/label as output. Our output is a CategoryBlock but other outputs can be ImageBlock(for autoencoders), MultiCategoryBlock(for multi-label classification) etc.
块:为了指定输入和输出。 在这里,我们将图像作为输入,将类别/标签作为输出。 我们的输出是CategoryBlock,但是其他输出可以是ImageBlock(对于自动编码器),MultiCategoryBlock(对于多标签分类)等。
splitter: Jeremy always emphasizes the importance of a validation set in order to evaluate the performance of a model and rightly so! Without doing this, we’ll never truly now how well is our model performing. To do this, we can specify a RandomSplitter or a column in our case which specifies whether an entry belongs to training set or validation set.
splitter: Jeremy始终强调验证集的重要性,以便评估模型的性能,这是正确的! 如果不这样做,我们将永远无法真正实现模型的性能。 为此,我们可以指定一个RandomSplitter或一列,以指定条目是属于训练集还是验证集。
get_x: This argument asks for the location of the inputs i.e. ImageBlock here. In our dataframe, the first column i.e. path column contains the paths hence we’ve specified cols = 0. Also optionally we can add a prefix and suffix here using pref and suff arguments. Since we have relative path of images, to get absolute path, prefixes are needed. In csvs, sometimes the extensions of items in the path columns are dropped which is where suffix argument comes in handy.
get_x:此参数要求输入的位置,即此处的ImageBlock。 在我们的数据框中,第一列(即path列)包含路径,因此我们指定了cols =0。此外,我们还可以在此处使用pref和suff参数添加前缀和后缀。 由于我们具有图像的相对路径,因此要获取绝对路径,需要前缀。 在csvs中,有时会删除path列中项的扩展名,这是后缀参数派上用场的地方。
get_y: This argument asks for the output values. In the dataframe, since the 4th column i.e. minifigure_name is the label we’d like to predict, we specified cols = 3 in the ColReader object to the get_y argument.
get_y:此参数要求输出值。 在数据帧中,由于第4列即minifigure_name是我们要预测的标签,因此我们在get_y参数的ColReader对象中指定了cols = 3。
item_tfms: Before making a batch of items for the neural network to train, we need to apply some transforms to ensure that they’re all the same size (generally square) and in certain other cases, some other transforms as well. These are mentioned in this argument.
item_tfms:在为神经网络训练一批项目之前,我们需要应用一些变换以确保它们的大小相同(通常为正方形),在某些其他情况下,还需要进行其他一些变换。 这些都在该论点中提到。
batch_tfms: These are the augmentation methods which you wish to use for making the model learn general features by cropping, zooming, perspective warping and other such transformations. You can choose to ignore this argument if you already have a large dataset size with a significant variety of images but otherwise, it always helps to add transforms to learn generalised models rather than over-fitted ones.
batch_tfms:这些是您希望用于使模型通过裁剪,缩放,透视变形和其他此类转换来学习一般特征的增强方法。 如果您已经拥有很大的数据集且包含大量图像,则可以选择忽略此参数,但否则,始终可以添加变换来学习广义模型,而不是过度拟合模型。
Once we have the DataBlock API object, we can create dataloaders using this object which can be fed into the model for training. After creating a dataloader, we can see how data is input to the model using show_batch method and subsequently the vocab attribute can be used to see what and how many classes/labels are present in the dataset as a whole.
一旦有了DataBlock API对象,我们就可以使用该对象创建数据加载器,该数据加载器可以输入到模型中进行训练。 创建数据加载器之后,我们可以看到如何使用show_batch方法将数据输入到模型中,随后可以使用vocab属性查看整个数据集中存在哪些类/标签以及多少个类/标签。
# Create a dataloader using batch size of 8
dls = dblock.dataloaders(paths_dframe, bs = 8)
# Have a look at a sample batch from the dataset
dls.show_batch(max_n = 9)
# Have a look at all the class names
dls.vocab
The dataloaders object contains both the train and validation dataloaders in it. The items in vocab correspond to the classes pertaining to train dataloader and the validation dataloader may have less than or equal number of labels/classes as the train dataloader. Also, notice that in the show_batch method, you can provide the number of items that you want to see but if the number is bigger than batch size (9 as opposed to a bs of 8), then you’ll only see as many images as in the batch size.
dataloaders对象在其中包含训练和验证数据加载器。 vocab中的项目对应于与火车数据加载器有关的类,并且验证数据加载器可以具有少于或等于火车数据加载器的标签/类数。 另外,请注意,在show_batch方法中,您可以提供要查看的项目数量,但是如果该数量大于批处理大小(9而不是8的bs),那么您将只能看到尽可能多的图像如批次大小。
训练分类模型 (Training A Classification Model)
Once you have a dataloader, next step is to create a model and to train it with an appropriate optimisation algorithm. fastai already abstracts a lot of these things and provides you with a very simple learner object which also has a lot of arguments but let me stress on the most important ones below.
拥有数据加载器后,下一步就是创建模型并使用适当的优化算法对其进行训练。 fastai已经抽象了很多这样的东西,并为您提供了一个非常简单的学习器对象,该对象也有很多参数,但让我强调以下最重要的参数。
The compulsory arguments that our Learner object takes are as follows:
我们的学习者对象接受的强制性参数如下:
dls: The dataloader object which we defined using the DataBlocks API above. It contains train and validation datasets and their labels.
dls:我们使用上面的DataBlocks API定义的dataloader对象。 它包含训练和验证数据集及其标签。
model: This is the model architecture that you would like to use. Since we’re doing transfer learning, we will be using a predefined resnet101 model trained on ImageNet weights. But, if you want you can build your own PyTorch model by inheriting the nn.Module class and implementing it’s forward method; that is beyond the scope of this article, so we wouldn’t discuss it here.
模型:这是您要使用的模型架构。 由于我们正在进行转移学习,因此我们将使用在ImageNet权重上训练的预定义的resnet101模型。 但是,如果您愿意,可以通过继承nn.Module类并实现它的forward方法来构建自己的PyTorch模型; 这超出了本文的范围,因此我们在这里不再讨论。
loss_func: Also known as the objective/cost function, this is the function based which the optimization algorithm is trying to minimize (well in most cases; unless you define an objective to maximize). For classification, CrossEntropy Loss and for regression MSE Loss are the most commonly used loss functions.
loss_func:也称为目标/成本函数,这是优化算法试图将其最小化的函数(在大多数情况下,除非您定义一个最大化的目标)。 对于分类,CrossEntropy损失和MSE回归是最常用的损失函数。
Other optional but important arguments are opt_func which specifies the optimisation algorithm to be used for training the model and metrics which specify what metrics to gauge the performance on (it could be accuracy, precision, recall, any custom metric). Also there is a capability of calling different callbacks as well which is not in the scope of this article. You can refer here to understand more about the same.
其他可选但重要的参数是opt_func,它指定用于训练模型的优化算法和指标,这些指标指定用于评估性能的指标(可以是准确性,精度,召回率,任何自定义指标)。 另外,还具有调用不同回调的功能,这不在本文讨论范围之内。 您可以在这里参考以更多地了解相同内容。
Once we have the learner object, we can utilize the lr_find function to find an optimal learning rate for our model. Looking at the loss vs learning rate profile, we should select the learning rate where the loss is minimum or a rate slightly below that point. It’s good to be conservative with learning rates because in my personal opinion, delayed convergence is more tolerable than overshooting the optimal point.
一旦有了学习者对象,就可以利用lr_find函数为模型找到最佳学习率。 查看损失与学习率的关系曲线,我们应该选择损失最小或略低于该点的学习率。 对学习率保持保守是个好习惯,因为我个人认为,延迟收敛比超出最佳点要容忍得多。

The function also gives suggestions for lr_min and the point where the steepest descent in loss was observed. The lr_min is an estimate of the minimum learning rate that one should pick in order to see decent speed of training without being extremely wary of skipping the optimal point in the loss surface while simultaneously ensuring that the model is learning something and parameter updates are happening. So, let’s for this case pick a learning rate of .01 and start the training.
该函数还提供有关lr_min的建议以及观察到损耗最陡下降的点。 lr_min是对最小学习速率的一种估计,为了不失谨慎地跳过损失表面上的最佳点,同时确保模型正在学习某些东西并且正在进行参数更新,人们应该选择最小的学习速率以便看到不错的训练速度。 因此,在这种情况下,让我们选择.01的学习率并开始训练。
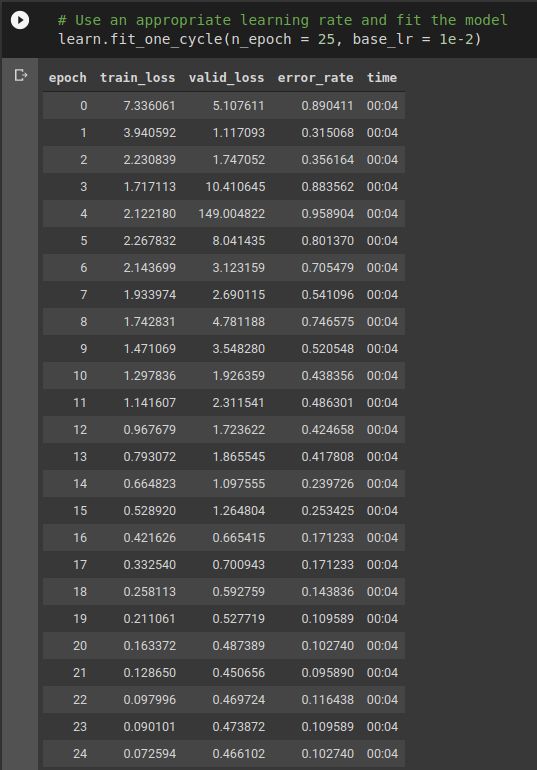
Since we have only about 154 training images, each epoch takes around 4 seconds with validation and metric computation. In this case, for resnet101 pretrained model, it’s top fc layers and a few penultimate convolution layers are getting the weight updates and the rest of the network is frozen i.e. weight updates don’t propagate further backwards than that. This fine-tuning approach has empirically observed to be the best when adopting a pre-trained model for a custom task; however after substantial improvement, like when the error rate drops to 10% or accuracy reaches almost 90%, we can also unfreeze that portion of the network and again train the model with the parameter updates now penetrating throughout the neural network.
由于我们只有约154张训练图像,因此每个阶段大约需要4秒钟进行验证和指标计算。 在这种情况下,对于resnet101预训练模型,其顶层fc层和一些倒数第二个卷积层正在获取权重更新,而其余网络则被冻结,即,权重更新不会向后传播。 根据经验观察到,对于定制任务采用预训练的模型,这种微调方法是最好的。 但是,经过重大改进后,例如当错误率下降到10%或准确性达到近90%时,我们还可以解冻网络的那一部分,并再次使用现在遍及整个神经网络的参数更新来训练模型。

That’s exactly what we did here. After training for 25 epochs, we unfreezed the model and checked for a good learning rate with the help of lr_find and ran the training loop for 5 more epochs. However we couldn’t find any substantial improvement in the error rate. It went down to 8.9% from 10.27%; this shows that the model is now saturated and no matter what you do to the model unless you provide new data, there wouldn’t be any major impact on the accuracy of this model.
这正是我们在这里所做的。 在训练了25个纪元后,我们解冻了模型,并在lr_find的帮助下检查了良好的学习率,并在训练循环中又进行了5个纪元。 但是,我们找不到错误率的任何实质性改善。 从10.27%下降至8.9%; 这表明该模型已经饱和,无论您对模型进行什么操作,除非您提供新数据,否则对该模型的准确性不会有任何重大影响。
In order to save this model for interpretation in future, you can simply use the command
为了保存此模型以供将来解释,您可以简单地使用以下命令
learn.export("filename.pkl")This will save the model with the name filename as a pkl file that could be later reloaded for inference. Now that we’re through with all the training part, let’s interpret the model and look at the predictions that it has made.
这会将名称为filename的模型另存为pkl文件,以后可以重新加载以进行推断。 现在我们已经完成了所有训练部分,让我们解释该模型并查看其做出的预测。
解释分类模型 (Interpreting A Classification Model)
After building a model, the performance of the model needs to gauged to ensure it’s usability and fastai provides a class ClassificationInterpretation for the same. We can create an instance of this class with the learner object that we fit in the training part.
建立模型后,需要评估模型的性能以确保其可用性,而fastai为其提供了一个ClassificationInterpretation。 我们可以使用适合训练部分的学习者对象来创建此类的实例。
Once we do that, we can observe the confusion matrix for validation data to see where the mistakes were made and how many of them were there.
一旦这样做,我们就可以观察验证数据的混淆矩阵,以查看错误发生在哪里以及其中有多少错误。
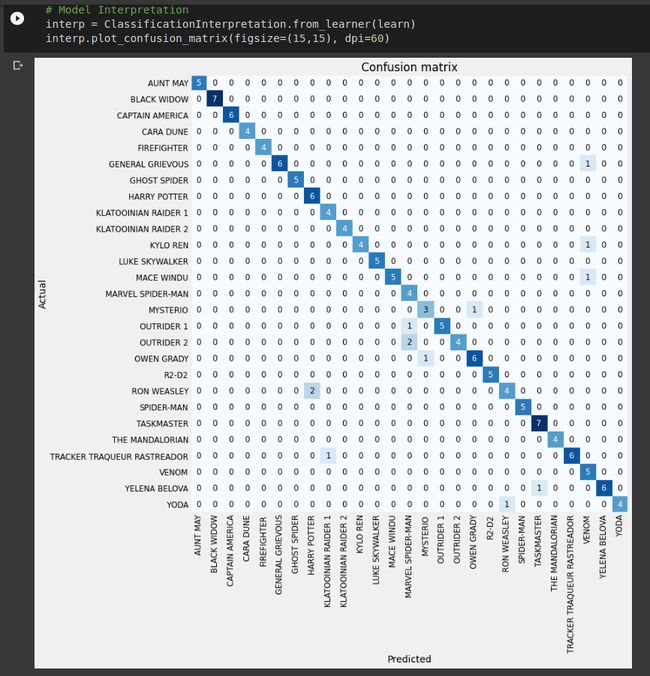
The overall structure of this seems good. In an idea case the diagonal is completely saturated with all the other non-diagonal elements being null. Here we can see that’s not the case. This means that our model has misclassified some action figures for eg. 2 RON WEASLY Legos were incorrectly classified as HARRY POTTER, a YODA figure was misclassified as RON WEASLEY and so on. In order to particularly highlight the ones which are misclassified, the ClassificationInterpretation class also has one more method.
这样的整体结构看起来不错。 在一个理想的情况下,对角线完全饱和,而所有其他非对角线元素均为零。 在这里,我们可以看到情况并非如此。 这意味着我们的模型为例如2 RON WEASLY乐高积木被错误地归类为HARRY POTTER,YODA人物被错误归类为RON WEASLEY,依此类推。 为了特别突出那些分类错误的分类,ClassificationInterpretation类还提供了另一种方法。
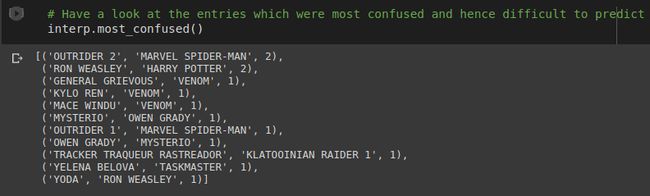
Here we can see tuples of misclassified items. Each tuple is structured as (Ground Truth, Prediction, number of misclassifications) respectively. Optionally you can also provide a parameter which looks at only those pairs which were misclassified above a certain threshold number of times. This can help us identify the pairs which need to be focussed more on. Thereby we can make decisions like adding more data or deleting wrongly labelled data and so on.
在这里,我们可以看到错误分类的元组。 每个元组的结构分别为(地面真理,预测,错误分类数)。 (可选)您还可以提供一个参数,该参数仅查看那些在特定阈值次数以上被错误分类的对。 这可以帮助我们确定需要重点关注的对。 因此,我们可以做出决策,例如添加更多数据或删除标签错误的数据等等。
from fastai.vision.widgets import *
cleaner = ImageClassifierCleaner(learn)
cleaner
for idx in cleaner.delete(): cleaner.fns[idx].unlink()
for idx, cat in cleaner.change(): shutil.move(str(cleaner.fns[idx]), path/cat)Although in my application everything is neatly labelled, there can be instances of mislabelling like below. The above code helps to create a GUI inline in the notebook which can be used to basically keep/delete/move items from one class to another. This is present in the widgets class in the fastai.vision package. If you’re sometime not sure about the labelling in your dataset, auditing your dataset like this is worth a try to clean it.
尽管在我的应用程序中,所有内容都经过了整齐的标记,但仍可能出现以下错误标记的情况。 上面的代码有助于在笔记本中创建一个内联GUI,可用于基本上将项目从一个类保留/删除/移动到另一个类。 这存在于fastai.vision包的小部件类中。 如果您不确定数据集中的标签,则值得尝试像这样对数据集进行审核。

So that’s it for this post guys; I hope you understood the steps to start using fastai for making your own image classifier. It has saved me a lot of time in terms of data preprocessing, model training and model interpretation, particularly in deep learning. Unlike PyTorch where we have to define the Datasets and Dataloader, the datablock API obviates the need for that step as it nicely wraps everything into one function call. Hope you liked the article and thanks for reading through!
这就是这个职位的家伙; 我希望您了解开始使用fastai制作自己的图像分类器的步骤。 在数据预处理,模型训练和模型解释方面,这为我节省了很多时间,尤其是在深度学习方面。 与必须定义数据集和数据加载器的PyTorch不同,数据块API无需执行该步骤,因为它很好地将所有内容包装到一个函数调用中。 希望您喜欢这篇文章,并感谢您通读!
翻译自: https://towardsdatascience.com/datablocks-api-image-classification-in-fastai-using-lego-minifigures-dataset-3360f97175fe
lego-loam数据