自定义神经网络入门-----Pytorch
文章目录
-
- 目标检测的相关评价指标
-
- IoU
- mAP
-
- 正例和负例
- 准确率P
- 召回率R
- 准确率ACC
- P-R曲线--AP
- nn.Module类
-
- 全连接层
- 感知机类
- 使用nn.Sequential进行构造
- 使用randn函数进行简单测试
- 损失函数nn.functional
- nn.optim
- 模型处理
-
- 网络模型库torchvision.models
- 模型Fine-tune和save
- 参考
目标检测的相关评价指标
IoU
IoU(Intersection of Union)用来评估预测框和真实框的贴合程度来判断检测的质量。其计算方式如下图所示,使用两个边框的交集与并集的比值,就能得到IoU.
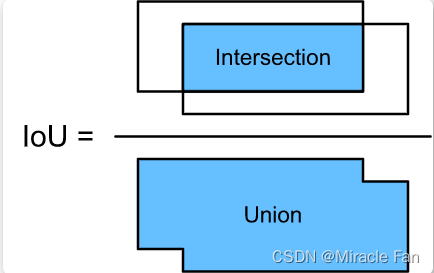
公式如下所示:
I o U A , B = S A ⋂ S B S A ⋃ S B IoU_{A,B}=\frac{S_A\bigcap S_B}{S_A\bigcup S_B} IoUA,B=SA⋃SBSA⋂SB
利用Python实现IoU计算的代码如下:
# boxA = (Ax1,Ay1,Ax2,Ay2)
# boxB = (Bx1,By1,Bx2,By2)
def iou(boxA,boxB):
#计算重合部分的上、下、左、右4个边的值
#因为在该处检测框的坐标位置是以左上角为原点
#对于左边界,就是比较哪个框的x坐标大,同理对于上边界
#对于右边界和下边界则相反,哪个小就是intersection的边界
left_max=max(boxA[0],boxB[0])
top_max=max(boxA[1],boxB[1])
right_min=min(boxA[2],boxB[2])
bottom_min=min(boxA[3],boxB[3])
#计算重合部分面积
#和0作比较就是判断是否有交集,没有交集则为0
inter=max(0,(right_min-left_max)*max(0,(bottom_min-top_max)))
Sa=(boxA[2]-boxA[0])*(boxA[3]-boxA[1])
Sb=(boxB[2]-boxB[0])*(boxB[3]-boxB[1])
#计算并集
union=Sa+Sb-inter
#计算iou
iou=inter/union
return iou
对于iou,显而易见它的取值范围为[0,1],iou值越大,表示两个框重合的越好,也就是预测的越好。所以我们平时实际使用过程中,通常取某个阈值,当iou大于阈值,就认为其是一个有效的预测,反之,就属于一个无效预测。
mAP
正例和负例
(1)True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
(2)False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
(3)False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
(4)True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
准确率P
表示预测样本中实际正样本数占所有正样本数的比例。
p r e c i s i o n = T P T P + F P precision=\frac{TP}{TP+FP} precision=TP+FPTP
召回率R
表示预测样本中实际正样本数占所有预测样本的比例。
r e c a l l = T P T P + F N recall=\frac{TP}{TP+FN} recall=TP+FNTP
准确率ACC
预测样本中预测正确数占所有样本的比例。
a c c = T P + T N T P + F P + T N + F N acc=\frac{TP+TN}{TP+FP+TN+FN} acc=TP+FP+TN+FNTP+TN
P-R曲线–AP
A P = ∫ 0 1 P d R AP=\int_{0}^{1}PdR AP=∫01PdR
AP代表曲线包围的面积,综合考虑了不同召回率下的准确率,对每个类别的AP进行平均取值就可以得到mAP
$$
$$
nn.Module类
nn.Module类是pytorch提供的一个神经网络类,并在类中实现了各层的定义及前向计算与反向传播机制。在我们搭建自己的神经网络,只需要继承nn.Module类,在初始化中定义模型结构与参数,在函数forward()中编写网络前向传播即可。
全连接层
class Linear(nn.Module):
def __init__(self, in_dim, out_dim):
# 调用nn.Module的构造函数
super(Linear, self).__init__()
# 使用nn.Parameter来构造需要学习的参数
self.w = nn.Parameter(torch.randn(in_dim, out_dim))
self.b = nn.Parameter(torch.randn(out_dim))
# 在forward函数中实现前向传播过程
def forward(self, x):
x = x.matmul(self.w)
y = x + self.b.expand_as(x)
return y
感知机类
class Perception(nn.Module):
def __init__(self, in_dim, hid_dim, out_dim):
super(Perception, self).__init__()
self.layer1 = Linear(in_dim, hid_dim)
self.layer2 = Linear(hid_dim, out_dim)
def forward(self, x):
x = self.layer1(x)
y = torch.sigmoid(x)
y = self.layer2(y)
y = torch.sigmoid(y)
return y
使用nn.Sequential进行构造
class Perception(nn.Module):
def __init__(self, in_dim, hid_dim, out_dim):
super(Perception, self).__init__()
self.layer = nn.Sequential(
nn.Linear(in_dim, hid_dim),
nn.Sigmoid(),
nn.Linear(hid_dim, out_dim),
nn.Sigmoid()
)
def forward(self, x):
y = self.layer(x)
return y
使用randn函数进行简单测试
mlp = MLP(2, 6, 2)
#用于输出参数名称,以及参数的数值
for name,param in mlp.named_parameters():
print(name,param)
data=torch.randn(4,2)
print(data)
print(mlp(data))
#输出结果如下
# layer.0.weight Parameter containing:
# tensor([[-0.6859, 0.0836],
# [ 0.1598, -0.3973],
# [-0.4115, -0.1504],
# [ 0.5661, -0.6860],
# [ 0.6184, 0.5957],
# [ 0.4745, 0.0665]], requires_grad=True)
# layer.0.bias Parameter containing:
# tensor([ 0.2333, -0.3779, -0.5412, 0.0109, 0.3617, -0.2331],
# requires_grad=True)
# layer.2.weight Parameter containing:
# tensor([[-0.3937, 0.3270, 0.3897, -0.1779, -0.2968, 0.3092],
# [ 0.2164, -0.0256, -0.1913, 0.1014, 0.0315, 0.2570]],
# requires_grad=True)
# layer.2.bias Parameter containing:
# tensor([-0.1708, 0.2282], requires_grad=True)
# tensor([[ 0.0470, -0.4241],
# [-1.4543, 1.1945],
# [-0.0185, 0.4032],
# [ 1.4869, -0.6973]])
# tensor([[0.4464, 0.6108],
# [0.4221, 0.6021],
# [0.4340, 0.6113],
# [0.4562, 0.6196]], grad_fn=)
损失函数nn.functional
from torch import nn
import torch
import torch.nn.functional as F
label=torch.Tensor([0,1,1,0])
pred=torch.Tensor([0.4464,0.6021,0.6113,0.4562])
#实例化nn.CrossEntropy
criterion=nn.CrossEntropyLoss()
loss_nn =criterion(pred,label)
loss_func=F.cross_entropy(pred,label)
print(loss_nn,loss_func)
#输出
#tensor(2.6232) tensor(2.6232)
nn.optim
该库包含了各种常见的优化算法,用来更新参数,包括随机梯度下降SGD、Adam、Adagrad、RMSProp
模型处理
网络模型库torchvision.models
from torchvision import models
vgg=models.vgg16()
print(vgg)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
可以看到vgg16分为了三个层次,分别为提取特征层,均值池化层,分类层.
模型Fine-tune和save
加载预训练模型
-
预训练模型
from torch import nn from torchvision import models vgg=models.vgg16(pretrained=True) -
加载本地模型
from torch import nn from torchvision import models import torch vgg=models.vgg(16) state_dict=torch.load("local model path") vgg.load_state_dict({k:v for k,v in state_dict_items() if k in vgg.state_dict()})
冻结部分预训练层
for layer in range(10):
for p in vgg[layer].parameters():
p.require_grad=False
模型保存
torch.save({
'model':model.state_dict(),
'optimizer':optimizer.state_dict(),
'model_path.path'
})
参考
[深度学习小常识]什么是mAP?
深度学习之Pytorch物体检测实战