一、09-多分类问题
1. 基本概念整理
1.1 ReLU函数:线性整流函数(Rectified Linear Unit),又称为修正线性单元,通常指以斜坡函数及其变种为代表的非线性函数。
1.2 softmax函数: 多分类问题需要一个特定的激活函数,可以满足两个条件
* $p_i \geq1$
* $\sum p_i=1$
* softmax函数定义式:$P(y=i)=\frac{e^{z_i}}{\sum_{j=0}^{K-1}e^{z_i}}$

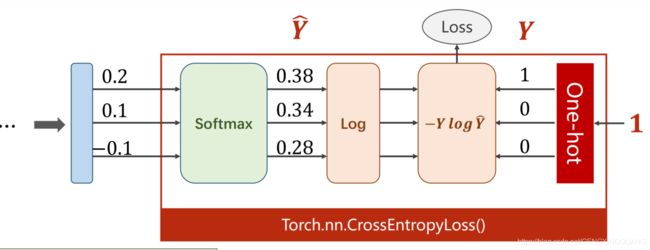
1.3 NLL Loss函数,多分类问题的损失函数 L o s s ( Y i , Y ) = − Y l o g Y i Loss(Y_i,Y)=-YlogY_i Loss(Yi,Y)=−YlogYi
- CrossEntropyLoss()=softmax()+NLL Loss()
*
1.4 神经网络训练的基本流程
| 1.准备数据 |
| 2. 构建模型(class) |
| 3. 定义损失函数和优化器 |
| 4. Train cycle+Test |
1.5 多连接问题里的标签需要是torch.LongTensor类型 \
1.6 需要引入的头文件的介绍
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.function as F
import torch.optim as optim
1.7
- torchvision.transforms是pytorch中的图像预处理包。一般用Compose把多个步骤整合到一起:
- 比如说:
transforms.Compose([transforms.CenterCrop(10),transforms.ToTensor(),...])这样就把两个步骤整合到了一起。
| 函数 |
说明 |
| Resize |
把给定的图片resize到given size |
| Normalize |
Normalized an tensor image with mean and standard deviation |
| ToTensor |
convert a PIL image to tensor (HWC) in range [0,255] to a torch.Tensor(CHW) in the range [0.0,1.0] |
| ToPILImage |
convert a tensor to PIL image |
| Scale |
目前已经不用了,推荐用Resize |
| CenterCrop |
在图片的中间区域进行裁剪 |
| RandomCrop |
在一个随机的位置进行裁剪 |
| RandomHorizontalFlip |
以0.5的概率水平翻转给定的PIL图像 |
| RandomVerticalFlip |
以0.5的概率竖直翻转给定的PIL图像 |
| RandomResizedCrop |
将PIL图像裁剪成任意大小和纵横比 |
| Grayscale |
将图像转换为灰度图像 |
| RandomGrayscale |
将图像以一定的概率转换为灰度图像 |
| FiceCrop |
把图像裁剪为四个角和一个中心 |
| Pad |
填充 |
| ColorJitter |
随机改变图像的亮度对比度和饱和度。 |
1.8 torch.utils.data
from torch.utils.data import DataLoader
DataLoader(dataset, batch_size=1, shuffle=false, sampler=None, batch_sampler=None, num_workers=0, collate_fn=, pin_memory=false, drop_last=false, timeout=0, worker_init_fn=None)
| DataLoader内部参数 |
说明 |
| dataset |
加载的数据集 |
| batch_size |
每批加载的样本个数 |
| shuffle |
是否对数据进行打乱 |
| sampler |
定义从数据集中提取样本的策略,返回一个样本 |
| num_workers |
用于加载数据的子进程数,可以选择用多线程加载数据 |
| … |
其他参数后续用到再学 |
1.9 几个优化器的比较
| 函数名 |
原理 |
优点 |
缺点 |
| BGD |
采用整个训练集计算cost function对参数的梯度 |
|
对整个数据集操作,计算慢 |
| SGD |
每个更新使对每个样本进行梯度更新 |
对于很大数据集,可能会有相似样本,BGD易出现冗余,SGD计算快,没有冗余 |
由于更新频繁,会造成cost function严重震荡;对噪声敏感 |
| MBGD |
每次取一小批样本进行训练 |
可降低参数更新时方差,收敛更稳定 |
但不能保证很好的收敛性,learing rate太小收敛慢,太大会导致loss function在极小值处不停震荡 |
| 应对方法 |
原理 |
超参数取值 |
|
| momentum |
可加速SGD,抑制震荡 v t = γ v t − 1 + α ∇ i J ( i ) v_t=\gamma v_{t-1}+\alpha \nabla_iJ(i) vt=γvt−1+α∇iJ(i)( i = i − v t i=i-v_t i=i−vt) |
一般取 γ = 0.9 \gamma=0.9 γ=0.9 |
|
| Adagrad |
新算法,可对低频参数做较大更新,对高频参数做较小更新,对稀疏数据友好,提高SGD鲁棒性;优点是减少了学习率的手动调节;缺点是分母会不断积累,学习率最终会变得非常小 |
一般学习率 η = 0.01 \eta =0.01 η=0.01 |
|
| Adadelta |
对Adagrad的改进 |
γ = 0.9 \gamma =0.9 γ=0.9 |
|
| RMSprop |
自适应学习率方法,和Adadelta都是对Adagrad学习率急剧下降的改进 |
建议 γ = 0.9 , α = 0.001 \gamma=0.9, \alpha=0.001 γ=0.9,α=0.001 |
|
| Adam |
计算每个参数的自适应学习率方法,目前在DL领域最常见 |
建议 β 1 = 0.9 , β 2 = 0.999 , ϵ = 10 e − 8 \beta1=0.9,\beta2=0.999,\epsilon=10e-8 β1=0.9,β2=0.999,ϵ=10e−8 |
|
| 总结 |
1.如果数据是稀疏的,就用自适应方法,即 Adagrad, Adadelta, RMSprop, Adam;2.RMSprop, Adadelta, Adam 在很多情况下的效果是相似的;3.Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum;4. 随着梯度变的稀疏,Adam 比 RMSprop 效果会好。整体来讲,Adam 是最好的选择。 |
|
|
|
|
|
|
torch.optim.Adam(params, lr=0.01, betas=(0.9,0.99),eps=1e-8,weight_decay=0)
1.10 momentum的伪代码

1.11 torch的几个用法集锦
torch.randn(n1,n2)
torch.toTensor()
torch.nn.Sequential()
torch.nn.Linear(n1,n2)
1.12 super().xx 在类继承中的应用
- super.f_name是继承父类的该函数f_name的声明。如果子类没有这个声明,那么如果子类里覆盖了这个函数,则父类的函数不再执行;若进行了声明,则子类变量也可以使用该父类函数
- super.__init__()是继承父类的__init__()函数
| 假设 |
结果 |
| 1. 子类重载了父类函数,但是没有添加super().f_name() |
子类实例调用该函数执行子类的代码 |
| 2. 子类重载了父类函数,并且使用了super.f_name() |
子类借助父类的函数进行了自己的计算 |
| 3. 子类没有重载该函数 |
子类实例可以调用该函数,执行的是父类代码 |
|
|
class Person:
def __init__(self,name='Person'):
self.name=name
print('Person __init__()')
def add(self,a,b):
self.sum=a+b
print('Person add()')
return self.sum
def mul(self,a,b):
print('Person mul()')
return a*b
class people_1(Person):
def __init__(self,age,name):
self.age=age
self.name=name
print('people __init__()')
def add(self,a,b):
print('people add()')
return super.add(a,b)
p1=people_1(4,'zhenzhen')
c1=p1.add(3,4)
c2=p1.mul(5,6)
1.13 python的静态方法与静态变量
class Person:
account=0
def __init__(self,name):
self.name=name
@staticmethod
def add_person():
Person.account+=1
print('The number of persons is: ',account)
return account
p1=Person('dingzhen')
num=p1.add_person()
p1.account=10
print(Person.account)
print(p1.add_person())
print(p1.account)
Person.account=8
print(Person.account)
(1) @staticmethod应该和静态变量搭配使用
(2) @staticmethod 函数只能操作静态变量
(3) 实例化的类调用静态变量并改变其值后,只能改变该实例本身的静态变量值,不影响该类在全局的该静态变量值,若要改变其全局的值,方法一为利用类名调用;方法二利用静态函数调用
2. 全部代码集锦
import numpy as np
import pandas as pd
import PIL
import matplotlib.pyplot as plt
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size=64
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])
train_dataset=datasets.MNIST(root='./dataset/minist/',train=True,download=True,transform=transform)
train_loader=DataLoader(train_dataset,shuffle=True,batch_size=batch_size,num_workers=2)
test_dataset=datasets.MNIST(root='./dataset/minst/',train=False,download=True,transform=transform)
test_loader=DataLoader(test_dataset,shuffle=False, batch_size=batch_size,num_workers=2)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.l1=torch.nn.Linear(784,512)
self.l2=torch.nn.Linear(512,256)
self.l3=torch.nn.Linear(256,128)
self.l4=torch.nn.Linear(128,64)
self.l5=torch.nn.Linear(64,10)
def forward(self,x):
x=x.view(-1,784)
x=F.relu(self.l1(x))
x=F.relu(self.l2(x))
x=F.relu(self.l3(x))
x=F.relu(self.l4(x))
return self.l5(x)
model=Net()
criterion=torch.nn.CrossEntropyLoss()
optimizer=optim.Adam(model.parameters(),lr=0.01,betas=(0.9,0.99),eps=10e-8)
def train(epoch):
running_loss=0
for batch_idx, data in enumerate(train_loader,0):
inputs,target=data
optimizer.zero_grad()
outputs=model(inputs)
loss=criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if batch_idx % 300 == 299:
print('output',outputs)
print('[%d, %5d] loss: %.3f',(epoch+1),(batch_idx+1),(running_loss/300))
running_loss=0
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
images, labels=data
outputs =model(images)
_,predicted=torch.max(outputs.data, dim=1)
total+=labels.size(0)
correct+=(predicted==labels).sum().item()
print('Accuracy on test set:%d %%',(100*correct/total))
if __name__=='__main__':
for epoch in range(5):
train(epoch)
test()