论文阅读《Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection》
论文地址:https://arxiv.org/abs/2103.17115
代码地址:https://github.com/hzhupku/DCNet
目录
- 1、存在的问题
- 2、算法简介
- 3、算法细节
-
- 3.1、密集关系蒸馏模块(DRD)
- 3.2、上下文感知聚合模块(CFA)
- 3.3、学习策略
- 4、实验
-
- 消融实验
1、存在的问题
在以往的小样本目标检测工作中,支持特征和查询特征之间的关系没有得到充分的发掘和利用,传统方法利用支持特征的全局池化生成的分类向量来调整查询特征,从整体角度指导特征学习。然而,由于外观变化或遮挡在自然图像中是常见的,当同一类对象在查询和支撑样本之间变化很大时,整体特征可能会产生误导。另外,当大部分物体由于遮挡而看不见时,局部上下文细节丢失,这时局部细节特征的检索变得非常重要,而以往的方法完全忽略了这一点。
同时,小样本目标检测问题中,多尺度特征提取器存在基类和新类过拟合的问题。为了解决上述问题,提出了基于上下文感知聚合的密集关系蒸馏算法(DCNet)。
2、算法简介
1、密集关系蒸馏模块(DRD):使用共享特征提取器,在像素级别上匹配查询特征和支持特征,充分利用支持信息。
2、上下文感知聚合模块(CFA):捕获RoI池化过程中不同尺度的全局和局部特征。
3、算法细节
训练过程中,每个episode的输入为一个查询图像和来自N个类的N个支持图像掩码对。
首先,共享特征提取器提取出查询特征和支持特征;
然后,密集关系蒸馏模块进行密集特征匹配;
上下文感知聚合模块根据RPN区域建议框 自适应地利用不同尺度的池化操作生产特征。

3.1、密集关系蒸馏模块(DRD)

1、输入查询图像和支持图像到共享特征提取器中;
2、共享特征提取器输出查询特征和支持特征;
3、查询特征和支持特征通过深度编码器被编码为一对键和值,
对于查询图像,输出的是:
k q ∈ R C / 8 × H × W k_{q} \in\mathbb R^{C/8 \times H \times W} kq∈RC/8×H×W , v q ∈ R C / 2 × H × W v_{q}\in\mathbb R^{C/2 \times H \times W} vq∈RC/2×H×W
其中C为特征维数,H为高度,W为输入特征映射的宽度。
对于支撑特征,输出的是:
k s ∈ R N × C / 8 × H × W k_{s} \in\mathbb R^{N\times C/8 \times H \times W} ks∈RN×C/8×H×W, v s ∈ R N × C / 2 × H × W v_{s}\in\mathbb R^{N\times C/2 \times H \times W} vs∈RN×C/2×H×W
其中N为目标类的数量(即支撑样本的数量)。
4、查询键值对和支持键值对输入到密集关系蒸馏模块中;
5、关系蒸馏,计算查询特征和支持特征的相似性;
F ( k q i , k s j ) = φ ( k q i ) T φ ′ ( k s j ) , (1) F(k_{qi}, k_{sj}) = φ(k_{qi})^T φ'(k_{sj}), \tag{1} F(kqi,ksj)=φ(kqi)Tφ′(ksj),(1)
6、特征相似性通过softmax进行归一化,得到软权重;
W i j = e x p ( F ( k q i , k s j ) ) ∑ i e x p ( F ( k q i , k s j ) ) . (2) W_{ij} = \frac{exp(F(k_{qi}, k_{sj}))}{\sum_{i}exp(F(k_{qi}, k_{sj}))}.\tag{2} Wij=∑iexp(F(kqi,ksj))exp(F(kqi,ksj)).(2)
7、所有的软权重加权求和得到最终权重W;
W ∗ v s (3) W * v_s\tag{3} W∗vs(3) 其中 ∗ 表示矩阵内积。
8、最终权重W和支持特征拼接,得到最终输出。
y = c o n c a t [ v q , W ∗ v s ] , (4) y = concat[v_q, W * v_s],\tag{4} y=concat[vq,W∗vs],(4)
最终输出可以看作是经过提炼、蒸馏、细化的查询特征。有一些类别是同时存在于查询集和支持集中的,属于这些类别的查询集图像对应的特征在密集关系蒸馏模块中被激活,提供一个辅助信息,方便类和边界框的预测。
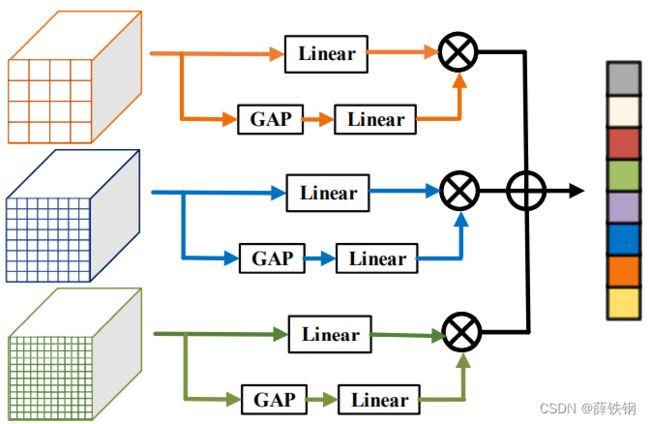
3.2、上下文感知聚合模块(CFA)

1、经过提炼、蒸馏、细化的查询特征被输入到上下文感知聚合模块中;
2、细化后的查询特征经过RPN的处理输出区域建议框;
3、区域建议框和特征输入到RoI Align中;
4、RoI Align中采用4,8,12三种分辨率分别对特征进行池化操作;
较大的分辨率能够关注到较小的对象的更加详细的局部上下文信息,较大的分辨率能够关注到整体的信息;
5、采用自适应融合池化结果的注意力机制对不同尺度的特征进行自适应聚合,输出的是加全局和后的特征。
3.3、学习策略
1、元训练阶段:联合训练特征提取器、密集关系蒸馏模块、上下文感知特征聚合模块和检测模型的其他基本组件
2、元微调阶段:在基类和新类上训练模型,训练过程和元训练阶段相同,但迭代次数更少。
4、实验
对单一尺度的图像进行训练和测试。
查询图像较短的边被调整为800像素,较长的边小于1333像素,同时保持长宽比。
支持图像被调整为256 × 256的平方图像。
Backbone的权重在ImageNet上进行预训练。
实验参数设置
| 项目 | Value |
|---|---|
| 特征提取器 | ResNet-101 |
| RoI特征提取器 | RoI Align |
| Backbone | ImageNet上预训练 |
| 训练方法 | SGD优化器 |
| mini-batch | 4 |
| 动量 | 0.9 |
| 权重衰减 | 0.0001 |
| 基线方法 | Meta R-CNN |
在PASCAL VOC上进行元训练时,训练模型进行240k、8k和4k迭代,学习率分别为0.005、0.0005和0.00005。在元微调过程中,对模型进行1300、400和300次迭代训练,学习率分别为0.005、0.0005和0.00005。
在MS COCO数据集进行元训练时,模型进行56k、14k和10k迭代,学习率分别为0.005、0.0005和0.00005。在元微调过程中,对模型进行2800、700和500次迭代的10-shot的微调,5600、1400和1000次迭代的30-shot的微调。
消融实验
上下文感知聚合模块:
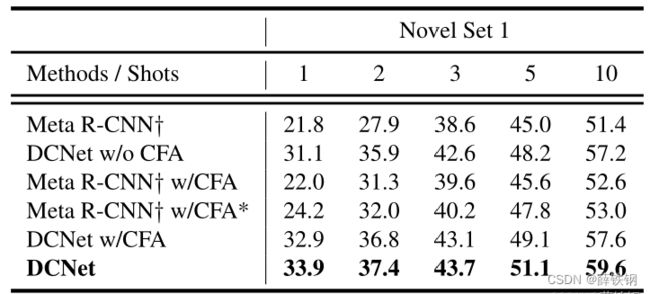
不同ROI池化:
