自然语言处理之Seq2seq的注意力机制,循环模型的问题,self-attention及Transformer结构讲解
Encoder-decoder模型
特点: 1. 典型的end2end模型
2. 不论序列长度,固定大小的中间向量,可能造成信息缺失(前面的信息被后面的覆盖)
3. 根据不同的任务可以选取不同的编码器和解码器(cnn,rnn,lstm,gru等)
缺点:
Encoder将输入(Source)编码为固定大小的向量的过程是一个“信息有损的压缩过程”,信息量越大,转化得到的固定向量中信息的损失就越大,这就得Decoder无法直接无关注输入信息的更多细节。
Decoder输出形式
- 输入和输出同等数量,每一个向量对应一个label和value,例如NER,词性标注
- 输出只有一个label或者value(例如文本分类或者情感分析)
- 输入和输出数量不相同,就是seq2seq
seq2seq(泛称)
即通过一个RNN作为encoder将输入的源语言转化为某表征空间中的向量,再通过另一个RNN作为decoder将其转化为目标语言中的句子。
问题:1. encoder中的最后一个隐藏状态需要保存源句的所有信息,达到了信息瓶颈(不论句子长度多少,中间的向量大小是固定的)
2. 中间语义向量c无法表达全部信息
3. 向量c对输出的所有y贡献是一样的

Attention的机制(在seq2seq中的解释decoder关注encoder的信息)
目的:解决这一由长序列到定长向量转化而造成的信息损失的瓶颈(核心:在decoder中的每一个时间步,对encoder使用直接连接去专注于源句某个特定的部分,聚焦于对训练任务有帮助的部分)
过程:从decoder的每一个隐藏状态都会与在encoder中的每一个隐藏状态进行dot product点积(后续会有其他的方法),形成一个注意力分数,基于这些注意力分数进行softmax的概率分布(注意力分布)
实质:加权求和,在模型中就是通过额外的神经网络层,给输入的不同部分分配不同的权重(query和value点积得到的注意力分数)这个权是通过计算向量之间的相关性进行度量的
这样,当我们decoder预测目标翻译的时候就可以看到encoder的所有信息,而不仅局限于原来模型中定长的隐藏向量,并且不会丧失长程的信息。
Attention机制流程(query和value的计算,此时的key也是value):
- 信息输入
- 计算注意力权重(输入对输出的重要性程度,query和key的计算)(Query和Key用来计算对应Value的权重系数)
- 对权重归一化(利用softmax 或者是Relu等激活函数(例如计算加性相关性))
- 计算输入信息的加权平均(上面得到的和value的计算)(对Source中元素的Value值进行加权求和)
Attention ouput是基于注意力分数对encoder的各个隐藏状态的加权平均值

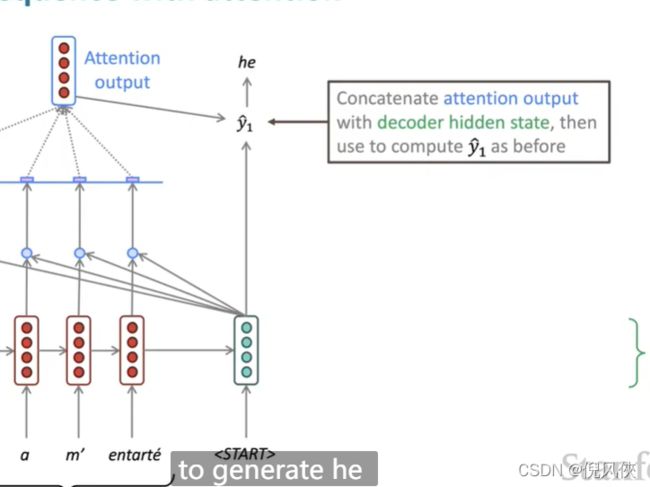
然后将output和decoder的隐藏状态结合计算出decoder的输出
再将输出作为下一个的输入连续计算
有时候我们从前一个时间步计算了attention output也会将其和平时的输入联合作为输入decoder的变量
Attention的作用:更好的方式从源句中获取更多的信息
Attention的公式角度

Attention的优点
- Attention明显的提升了NMT的表现(对于decoder关注源句特定的部分有作用),中间向量c针对不同的源句有不同的贡献
- 提供了MT过程的’human-like‘模型(可以直接回头看源句,而不需要记住它)
- 解决了信息瓶颈的问题(绕过了只需要最后的隐藏状态,直接了解源句)
- 有效缓解了梯度消失的问题(提供了通向远处状态的路径(避免了中间过程梯度的计算))
- 我们通过观察attention 权重矩阵的变化,可以更好地知道哪部分翻译对应哪部分源文字,有助于更好的理解模型工作机制

Attention中注意力分数(计算向量之间的相关性)计算的变种
- 加性相关性(tanh(q+k))
- 点积相关性(xt*y)
- 缩放点积相关性(在transformer中使用,目的:attention score的均值和方差和q、k相同,有利于缓解梯度消失)
- 双线性相关性(qWk)

Attnetion广泛的定义(query确定在信息值value中要得到的信息)

解释: 1. 加权和是值中包含的信息的选择性汇总,其中查询确定要关注的值
2. 注意力是一种获得任意一组表示(值)的固定大小表示的方法,依赖于其他一些表示(查询) 
循环模型的问题
- 线性交互距离(在文本中,某些词依赖于某些词,就需要模型去捕捉到这些关系,例如在双向RNN中,捕捉上下文的关系) 问题:1. 由于梯度的原因:导致模型很难学习长距离的依赖关系 2. 单词的线性顺序是“baked in”;我们已经知道线性顺序不是思考句子的正确方式
所以在rnn以及是lstm这些工具中,当步长较大之后,由于存在梯度的问题,所以可能这些关系捕捉不到,相距较远时RNN的效果常常较差,且由于其顺序性处理效率也较低. - 在seq2seq中,输出和输入之间做attention,关注句子和句子间的特征,没有关注句子内部的信息(如语法特征、短语结构等)

2.计算缺乏并行性(循环模型计算正向和反向传播需要O(n)不并行的操作)

如何解决以上模型带来的问题?
如果没有循环,用词窗口?
词窗口来统计上下文(类似于一维卷积,上面的窗口卷积下一层的信息,只不过是同样的大小)
不并行的操作不会增加句子长度

堆叠的窗口可以交互距离较远的word

去掉循环模型,直接用注意力?
Attention模型本身可以看到全局的信息, 那么一个自然的疑问是我们能不能去掉RNN结构,仅仅依赖于Attention模型呢,这样我们可以使训练并行化,同时拥有全局信息。
词窗口是统计部分的信息,在self-attention中是(all words attend to all words)
self-attention(**)
query key value(在实际中,这些数量可以不同)
query是知道某些信息的key,value是得到具体信息
self-attention就是针对qkv的计算(q和k经过dot product 然后softmax概率分布后与v计算得到加权求和的值, query和不同的(k,v)对儿进行计算 q1k1v1+q1k2v2)

类似于堆叠的窗口统计,模型利用不同self-attention进行堆叠,但是self-attention不可以作为替代循环模型的工具(是一种对于集合的操作,但是对顺序没有注意到)
自注意力机制建立单词和整个句子的attention关系,可以学到句子内部的信息,并且每个单词的self-attention计算可以并行。

self-attention的种类
- Truncated self-attention(当输入的文本或者语音长度很大,计算注意力分数是N*N,计算量很大,可以利用窗口,每次只计算窗口中的score)
- 多头注意力机制(计算流程:输入x和Wq,Wk,Wv相乘,这里W是多个,然后按照score分布加权求和得到每个头的输出,将这些头拼接再乘以一个矩阵Wo得到最终的输出(因为输出和输入x的大小要一致,所以对多头做了处理))
self-attention的优缺
优:
- 并行的计算attention
- 解决长距离依赖关系的获取问题,每个词之间计算attention score,计算距离最大是1
缺:
- 损失了句子内部单词之间的位置信息
- 运算量很大
以下是如果网络只用self-attention没有解决的问题
问题1:序列顺序信息解决(损失了句子内部单词之间的位置信息)
由于self-attention并没有建立顺序信息,需要编码信息到word embedding中,再经过self-attention处理
为什么需要位置信息?
答:没有单独位置信息,那么各个位置没有任何差别,例如再ner任务中,某个词放在句首,那么是动词的可能性就低,位置编码补充这种信息
位置表示向量
要求: 保证值域固定,且不同长度文本,相差相同字数,差相同值,不同顺序(方向)含义不同
- 固定编码(优点:周期性特征代表绝对编码 可以外推 缺点:不能学习)
- 位置作为可学习参数(不能外推)


问题2:现在堆叠self-attention层的qkv计算只是在做加权求和权重计算,网络层没有非线性拟合能力
解决:添加FFN(前馈神经网络)处理每一层的输出

问题3:在有decoder时(例如MT或者是语言模型的时候),不去欺骗在预测未来的时候,因为在之前的信息中得到了依赖关系(在decoder中去mask the future,权值就为0)
inference的时候,decoder是把1到t-1时刻的输出序列作为t时刻的输入(t时刻的输入得到前面全部的信息)

Transformer结构(E和D各有6层)

encoder读入输入数据,利用层层叠加的Self-Attention机制对每一个词得到新的考虑了上下文信息的表征。Decoder也利用类似的Self-Attention机制,但它不仅仅看之前产生的输出的文字,而且还要attend encoder的输出。
堆叠层的含义从RNN那回忆:捕捉高阶特征

Encoder 结构
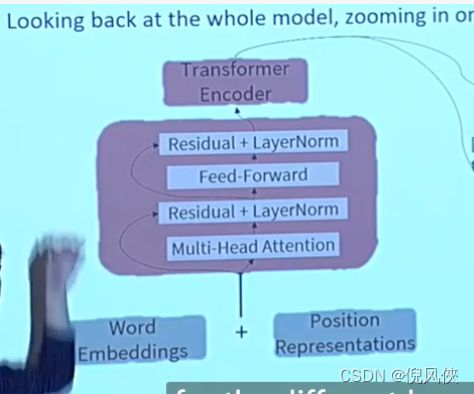
- 如何得到K-Q-V向量
- 在一层中设置多头注意力机制(每个head学习到在不同表示空间中的特征,例如在图像卷积中设置多个卷积核的作用)
- 在训练中的trick:1. res,残差连接 2. 层标准化 3. 缩放dot product 4.以上这些trick不会提升模型要做的事情,但是能加快提升训练进程

多头注意力:设置多个kqv的权重矩阵
Multi-head Attention其实就是多个Self-Attention结构的结合,每个head学习到在不同表示空间中的特征,学习到的Attention侧重点可能略有不同,给了模型更大的容量。
 q和k可能是查看关注x中的某些位置而v则是要记录下x中的某些信息
q和k可能是查看关注x中的某些位置而v则是要记录下x中的某些信息



残差连接(使损失变得平滑,训练更加容易找到全局最值点)
解决的问题:
- 一定程度解决梯度消失问题(在bp中,导数小于1,那么网络增加之后,反向传播中参数不会更新)
- 一定程度解决网络退化问题(深度神经网络随着深度增加,网络表现可能减弱)
- 一定程度上缓解梯度破碎问题(深度增加,梯度逐渐呈现为白噪声,神经元对网络输出的影响不稳定 )
如何解决:
残差模块:xl = xl + F(xl,Wl) 包含直接映射和残差部分
- 在反向传播求导的时候,因为直接加了映射,所以在求导的时候多了一项常数1,梯度连乘也不会造成梯度消失
- 在残差中,给了从低层到高层的直接映射, 减少网络退化问题(直接跳过了中间的几层)
- 对梯度破碎的问题还没搞清楚

layer norm是标准化,帮助模型训练更快(单独对一个样本的所有单词作缩放,与batch normalization的方向垂直)
为什么做Normlization?
答: 目的:让分布稳定下来(降低各个维度数据的方差)
原因: 1. 不同特征具有不同数据量级的数据,在经过线性组合之后,数量级大的特征影响更大,Norm是可以协调特征在空间上的分布,方便进行梯度下降
2. 线性层经过激活函数,例如在sigmoid中,特征大的数据经过激活函数就落入了饱和区,激活函数值都在 1 附近,不会有太大变化,这样激活函数就对这个特征不敏感, 例如在使用SGD优化方法的时候,不同量纲的数据会使网络不平衡
为什么Transformer是对layer而不是batch做归一化?
- BN是对同一维度的信息归一化,但是对于文本信息,对于一些问题来说,一个序列的输入同一”维度“上的信息可能不是同一个维度
- 图像的bn是认为 不同卷积核feature map(channel维)之间的差异性很重要,ln会降低这种差异性(BN仅是为了进一步保证同一个卷积核在不同样本上提取特征的稳定性), 文本的ln认为batch内不同样本同一位置token之间的差异性更重要

尺度缩放
计算Q与K之间的点乘,然后为了防止其结果过大(当维度过大时,点积的结果可能也会较大,经过softmax的时候,使得梯度变小),会除以一个尺度标度为一个query和key向量的维度。
Mask机制
- 处理非定长序列的padding mask
- 防止标签泄露的sequence mask
padding mask
NLP的输入文本长度不一致,在放入网络需要整齐的batch,提前对文本进行截断或者padding操作,padding符号要一致,在mask矩阵中,1可以表示有效字,0表示无效
padding mask 矩阵的生成和使用
- padding(补齐)操作在batch输入网络前完成,同步生成padding mask矩阵
- padding mask矩阵常常用在最终结果输出、损失函数计算等等,常用在计算受样本实际长度影响
sequence mask设计多样
- transformer中decoder利用了不泄露要预测的标签信息,就需要 mask 来“遮盖”信息(通过对qk计算得到矩阵中需要覆盖的值为-inf,在经过softmax后值就变为0)
- 模型利用这种填空机制帮助模型学的更好(Bert(选择15%的***token***覆盖掉)等,ERNIE是在短语级别掩码)
decoder结构
- 在第一层多头注意力要将future的元素进行masked,权重变为0,只能attend到前面已经翻译过的输出的词语
- 多头交叉注意力(k和v来自encoder的最后一层 q来自decoder的上一层输出
类似是在seq2seq中的decoder向encoder中查找信息)
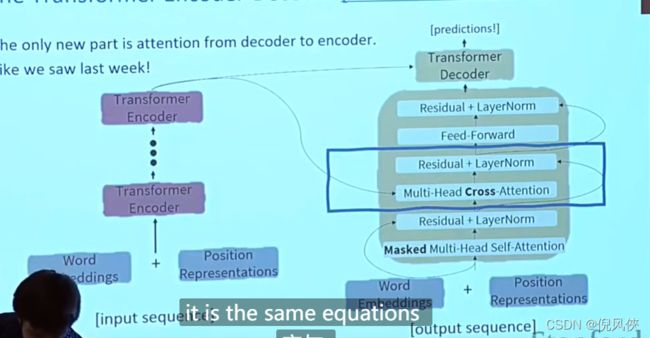
第二级decoder也被称作encoder-decoder attention layer,即它的query来自于之前一级的decoder层的输出,但其key和value来自于encoder的输出,这使得decoder的每一个位置都可以attend到输入序列的每一个位置。

提升方向
1.计算所有元素对的时间是句子长度的二次方
2. 位置表示


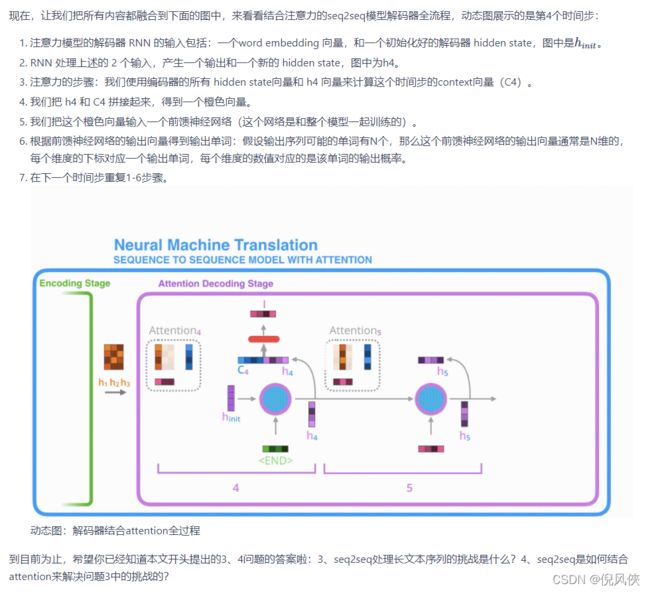
Seq2seq的注意力模型
https://gitee.com/datawhalechina/learn-nlp-with-transformers/blob/main/docs/%E7%AF%87%E7%AB%A02-Transformer%E7%9B%B8%E5%85%B3%E5%8E%9F%E7%90%86/2.1-%E5%9B%BE%E8%A7%A3attention.md
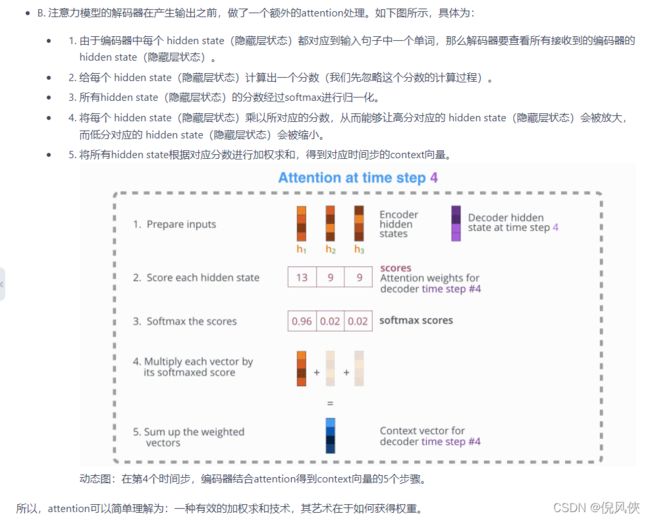
RNN的注意力模型解码的过程是所有Encoder的hidden (进行score softmax 加权平均计算得到)和 decoder的 hidden计算 得到decoder的下一个时间步的input