作者:谢益培
1 背景
关键词:并发、丢失更新
预收款账户表上有个累计抵扣金额的字段,该字段的含义是统计商家预收款账户上累计用于抵扣结算成功的金额数。更新时机是,账单结算完成时,更新累计抵扣金额=累计抵扣金额+账单金额。
2 问题及现象
发现当账单结算完成时,偶尔会发生累计抵扣金额字段值更新不准确的现象。
比如,某商家账户上累计抵扣金额原本为0元,当发生两笔分别为10和8的账单结算完成后,理论上累计抵扣金额应该变为18元,但实际为10元。也就是说,第二次更新把前一次更新内容给覆盖掉了。
3 问题分析
该问题为典型的第二类丢失更新问题。
3.1 概念解释
事务在并发情况下,常见如下问题:
- 脏读:一个事务读取了已被另个一个事务修改但尚未提交的数据。当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中;这时另外一个事务也访问这个数据,然后使用了这个未提交的数据。
- 不可重复读:在一个事务内,多次读同一数据,读到的结果不同。第一个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
- 幻读:同一事务中,当同一个查询执行多次的时候,由于其他事务进行了插入操作并提交事务,导致每次返回不同的结果集。幻读是事务非独立执行时发生的一种现象。例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表的全部数据行。同时,第二个事务也修改了这个表中的数据,这种修改是向表中插入了一行新数据。那么,就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好像发生了幻觉一样。
- 更新丢失:两个事务同时更新一行数据,一个事务对数据的更新把另一个事务对数据的更新覆盖了。这是因为系统没有执行任何的锁操作,因此并发事务并没有被隔离开来。
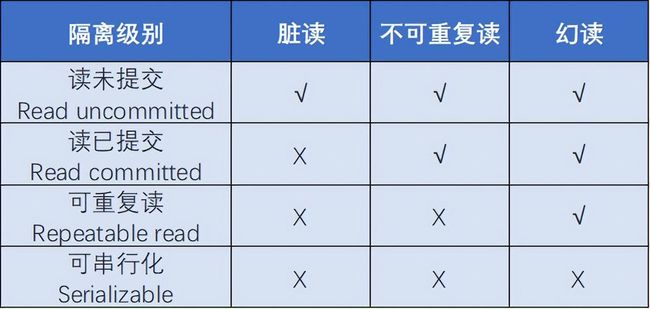
图1 SQL标准定义了4种数据库事务隔离级别
第一类丢失更新:A事务撤销时,把已经提交的B事务的更新数据覆盖了。SQL标准中未对此做定义,所有数据库都已解决了第一类丢失更新的问题。
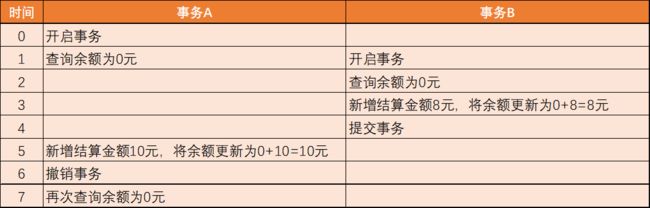
图2 第一类丢失更新
第二类丢失更新:A事务覆盖B事务已经提交的数据,造成B事务所做操作丢失。第二类丢失更新,和不可重复读本质上是同一类并发问题,通常将它看成不可重复读的特例。当两个或多个事务查询相同的记录,然后各自基于查询的结果更新记录时会造成第二类丢失更新问题。每个事务不知道其它事务的存在,最后一个事务对记录所做的更改将覆盖其它事务之前对该记录所做的更改。

图3 第二类丢失更新
3.2 疑惑点
发生问题的代码:
@Transactional(propagation = Propagation.REQUIRED, isolation = Isolation.REPEATABLE_READ)
public void finishDeductTransaction(String customerCode, String entityCode, String currency, ABTransaction abTransaction) {
Account account = getAccount(customerCode, entityCode, currency);
BigDecimal newValue = account.getCumulativeDeductionAmount().add(transaction.getTransactionAmount());
account.setCumulativeDeductionAmount(newValue);
//持久化
Account update = new Account();
update.setId(account.getId());
update.setCumulativeDeductionAmount(account.getCumulativeDeductionAmount());
accountBalanceInfoMapper.update(update);
}上述代码中可以看到,该方法已设置事务隔离级别为可重复读(isolation = Isolation.REPEATABLE_READ,也是MySQL的默认隔离级别)。按照之前对隔离级别规范的理解,可重复读级别是应该能够避免第二类更新丢失的问题的,但为啥还是发生了呢?!于是上网查阅相关资料,得到的结论是:MySQL数据库,设置事务隔离级别为可重复读无法避免发生“第二类丢失更新”问题。从这个案例中也得到一个教训就是,规范标准和所选的产品(组件)实际实现情况,两者需要同时考虑,对于边缘性或存在争议的规范内容要尽可能避免直接使用,最好通过其他机制来保证。
4 解决方案
以下整理了针对该问题的常见解决方案并按解决思路进行了分类。
4.1 依赖数据库的思路
方法1:
将事务隔离级别改为串行,能解决但并发性能低,还可能导致大量超时和锁竞争。
方法2:
调整SQL语句,将更新赋值逻辑改为“c=c+x”形式,其中c为要更新的字段,x为增量值。这种方式能确保累加值不会被覆盖。但这种方式需要额外编写特殊的SQL,而且严格意义上讲,存在业务逻辑泄露到持久层的不规范问题。
4.2 悲观锁思路
方法3:
方法执行时增加分布式锁,来控制同一账户同一时刻只有一个线程可对其进行操作。效果等同将事务级别改为串行,也是排队执行,并发性能也低,只是锁机制不是由数据库实现了而已。
分布式锁的实现方式有多种,比如该项目中有封装好的基于Redis的分布式锁,其注解的使用方式如下:
@CbbSingle(key = "QF:finishDeductTransaction:customerCode", value = {"#{customerCode}"})
public void finishDeductTransaction(String customerCode, String entityCode, String currency, ABTransaction abTransaction) {方法4:
通过SQL语句启用数据库排他锁,例如:select * from table where name=’xxx’ for update。通过此sql查询到的数据就会被数据库上排他锁,因此其他事务就无法对该数据及进行修改了。
该方法比上面两种在并发性能方面会好一些,但仍然可能存在锁等待和超时情况发生。
4.3 乐观锁思路
方法5:
乐观锁的思路是假设并发冲突发生概率较低,开启事务时先不加锁,在更新数据时通过版本比对以及判断影响行数来判断是否更新成功。
其中,版本概念,可以是要更新记录的版本号,或者更新时间等。也可以用旧值条件或校验和等方式;
该方法并发性能最好,但一旦发生并发冲突会导致方法执行失败,此时就需要搭配额外的重试或自旋逻辑来闭环。
思路如下:
//先查询出来要更新的数据
select column1,id,version from table where id=1001;
//进行业务逻辑处理
//更新这条数据
update table set column1=xx where id=1001 and version=查询出来当时的version值
//判断影响行数
if (records < 1) 更新失败...本案例中的问题便是采用这种方法解决的:
@Transactional(propagation = Propagation.REQUIRED, isolation = Isolation.REPEATABLE_READ)
public void finishDeductTransaction(String customerCode, String entityCode, String currency, ABTransaction abTransaction) {
Account account = getAccount(customerCode, entityCode, currency);
BigDecimal newValue = account.getCumulativeDeductionAmount().add(transaction.getTransactionAmount());
account.setCumulativeDeductionAmount(newValue);
//持久化
Account update = new Account();
update.setId(account.getId());
update.setVersion(account.getVersion());
update.setCumulativeDeductionAmount(account.getCumulativeDeductionAmount());
int records = accountBalanceInfoMapper.updateByIdAndVersion(update);
if (records < 1) {
throw new SingleThreadException("更新时数据版本号已发生改变。原因:发生并发事务");
}
}5 总结
- 对于常见并发事务问题,需要将事务隔离级别和锁机制结合起来一起使用;
- 需要对并发问题从业务场景上进行分析和识别,对于并发冲突少的场景,首选乐观锁思路;对于并发冲突高的场景采用悲观锁思路;