PyFlink 有状态流处理在线机器学习基础实例 手写体识别
01 在线机器学习
1.1 在线机器学习简介
准确地说,在线学习并不是一种模型,而是一种模型的训练方法。
能够根据线上反馈数据,实时快速地进行模型调整,形成闭环的系统,同时也使得模型能够及时反映线上的变化,提高线上预测的准确率。
在线学习与离线学习,在数据的输入与利用上有明显的区别:
- 在线学习的训练数据是一条条(或者是 mini-batch 微批少量)进来的,不像离线学习时可以一次性加载大量的数据。
- 在线学习的数据只能被训练一次,过去了就不会再回来,不像离线学习可以反复地在数据集上训练模型。
很容易发现,对于在线学习,模型每次只能沿着少量数据产生的梯度方向进行下降,而非基于全局梯度进行下降,整个寻优过程变得随机,因此在线学习的效率并没有离线学习的高。但同时由于它每次参与训练的样本量很小,我们并不需要再用大内存、高性能的机器了,直接好处就是省钱呀。
对在线学习有兴趣的同学可以看一下这篇文章:在线学习(Online Learning)导读
02 手写体识别在线机器学习实践
2.1 实例业务场景
本实例使用 PyFlink + Scikit-Learn 基于kafka输入的实时手写体数据,在线训练一个手写体识别机器学习模型,以及提供实时的手写体识别服务;并实现对模型训练过程的实时监控。
本在线机器学习实例,分为如下 3 个部分:
- 模型的训练 Online Learning :利用有标签的流式训练数据,来进行增量学习,不断地更新模型参数。
- 模型的服务 Online Serving :在 UDF 里设定模型的加载与保存逻辑,并利用 Flask 加载 Redis 里的最新模型以提供服务。
- 模型的监控 Model Monitor :在 UDF 里自定义监控指标,然后利用 Flink 的 Metric 机制,可以在自带的 WebUI 里实时查看。
2.2 构建数据生成器
首先,我们需要模拟线上已经做了特征工程的手写体实时数据。
本实例中,我们编写一个 data_producer.py 的脚本,提供了数据模拟器的功能。
该脚本的功能是往 kafka 服务的 handwritten_digit 主题里,每秒写入 10 条 Scikit-Learn 的 digits 数据集里的样本,数据格式为 json 字符串,如下:
{
"ts": "2020-01-01 01:01:01", # 当前时间
"x": [0, 1, 2, 16, ...], # 展平后的图像灰度数据,包含有 64 个整数的数组,整数的定义域为 [0, 16]
"actual_y": 1, # 真实标签
}
模拟生成实时数据
使用 Kafka 生产者往 Kafka 里依次写入 sklearn 的 digits 手写数字图片数据集
def write_data(self):
# 导入数据
digits = datasets.load_digits()
all_x = digits.data.astype(int)
all_y = digits.target.astype(int)
start_time = datetime.now()
# 初始化 kafka 生产者
producer = KafkaProducer(
bootstrap_servers=self._bootstrap_servers,
value_serializer=lambda x: dumps(x).encode('utf-8')
)
# 生产实时数据,并发送到 kafka
while True:
# 打乱数据
idx = np.arange(digits.data.shape[0])
np.random.shuffle(idx)
all_x = all_x[idx]
all_y = all_y[idx]
for x, y in zip(all_x, all_y):
# 生产数据,并发送到 kafka
cur_data = {
"ts": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"x": x.tolist(),
"actual_y": int(y)
}
# 将数据写入 kafka topic
producer.send(self._topic, value=cur_data)
# 停止时间
sleep(1 / self._max_msg_per_second)
# 终止条件
if (now - start_time).seconds > self._run_seconds:
break
查看用户操作数据
使用 Kafka 消费者查看已经写入的实时数据
# 读取 kafka 的手写体实时数据并打印
def print_data():
consumer = KafkaConsumer(
topic, # topic的名称
group_id= 'group',
bootstrap_servers=bootstrap_servers, # 指定kafka服务器
auto_offset_reset='latest',
)
for msg in consumer:
print(msg.value.decode('utf-8').encode('utf-8').decode('unicode_escape'))
2.3 根据输入数据和输出结果创建源表和结果表
本实例的数据来源于 kafka 并将处理结果也输出到 kafka,所以我们要创建 kafka 表并指定topic, kafka_servers, group_id 等必要参数如下:
kafka_servers = "localhost:9092"
kafka_consumer_group_id = "group0" # group ID
source_topic = "handwritten_digit" # 源数据
sink_topic = "digit_predict" # 结果
本实例的数据对象就是手写数字图像数据,输入数据包含 x:图片灰度数据,actual_y:实际数字,ts:数据生成时间 共三个字段,创建 Kafka 源表如下:
source_ddl = f"""
CREATE TABLE source (
x ARRAY, -- 图片灰度数据
actual_y TINYINT, -- 实际数字
ts TIMESTAMP(3) -- 图片产生时间
) with (
'connector' = 'kafka',
'topic' = ' {source_topic}',
'properties.bootstrap.servers' = '{kafka_servers}',
'properties.group.id' = '{kafka_consumer_group_id}',
'scan.startup.mode' = 'latest-offset',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true',
'format' = 'json'
)
"""
t_env.execute_sql(source_ddl)
本实例的统计结果包含 x:图片灰度数据,actual_y:实际数字,predict_y:预测数字 共三个字段,创建 Kafka 结果表如下:
sink_ddl = f"""
CREATE TABLE sink (
x ARRAY, -- 图片灰度数据
actual_y TINYINT, -- 实际数字
predict_y TINYINT -- 预测数字
) with (
'connector' = 'kafka',
'topic' = ' {sink_topic}',
'properties.bootstrap.servers' = '{kafka_servers}',
'properties.group.id' = '{kafka_consumer_group_id}',
'scan.startup.mode' = 'latest-offset',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true',
'format' = 'json'
)
"""
t_env.execute_sql(sink_ddl)
2.4 编写 UDF 实现实时模型训练与指标监控
我们使用标量函数定义 UDF,并通过继承 pyflink.table.udf 中的基类 ScalarFunction 的方式定义,实现 eval 方法来定义标量函数的行为,eval 方法支持可变长参数,例如 eval(* args)。
通过继承 ScalarFunction 的方式来定义 Python UDF 有以下用处:
- ScalarFunction 的基类 UserDefinedFunction 中定义了一个 open 方法,该方法只在作业初始化时执行一次,因此可以利用该方法做加载机器学习模型的初始化工作
- 还可以通过 open 方法中的 function_context 参数,注册及使用 metrics,实现对指标的监控
2.4.1 模型加载
UDF 在初始化的时候,会先从 Redis 里尝试加载预训练好的模型,如果 Redis 里不存在模型数据,则初始化一个 sklearn 中的分类器 SGDClassifier 用于模型训练
# 加载模型,如果 redis 里存在模型,则优先从 redis 加载,否则初始化一个新模型
def load_model(self):
r = redis.StrictRedis(**self.redis_params)
clf = None
try:
clf = pickle.loads(r.get(self.model_name))
except TypeError:
logging.info('Redis 内没有指定名称的模型,因此初始化一个新模型')
except (redis.exceptions.RedisError, TypeError, Exception):
logging.warning('Redis 出现异常,因此初始化一个新模型')
finally:
clf = clf or SGDClassifier(alpha=0.01, loss='log', penalty='l1')
return clf
2.4.2 模型训练与预测
模型训练行为定义在 UDF 的 eval 方法中,Kafka 每来一条数据,Flink 则会调用一次 UDF 的 eval 方法,方法内部会调用模型的 partial_fit 方法来训练,更新模型的参数。
在 UDF 的 eval 方法里,完成本次的训练后,还会对训练用到的样本做个预测,并将预测结果作为 UDF 的输出写回到 Kafka 。
在 UDF 的 eval 方法里,完成模型预测后,该结果用于计算相关的指标,并更新模型监控的指标,模型训练中监控的指标包含:
metric_counter: 从作业开始至今的所有样本数量metric_predict_acc:模型预测的准确率(用过去 10 条样本来评估)metric_distribution_y:标签 y 的分布metric_total_10_sec:过去 10 秒内训练过的样本数量metric_right_10_sec:过去 10 秒内的预测正确的样本数
# 模型训练
def eval(self, x, y):
"""
:param x: 图像的一维灰度数据,8*8=64 个值
:param y: 图像的真实标签数据,0~9
"""
# 需要把一维数据转成二维的,即在 x 和 y 外层再加个列表
self.clf.partial_fit([x], [y], classes=self.classes)
self.dump_model() # 保存模型到 redis
# 预测当前
y_pred = self.clf.predict([x])[0]
# 更新指标
self.metric_counter.inc(1) # 训练过的样本数量 + 1
self.metric_total_10_sec.mark_event(1) # 更新仪表 Meter :来一条数据就 + 1 ,统计 10 秒内的样本量
if y_pred == y:
self.metric_right_10_sec.mark_event(1) # 更新仪表 Meter :来一条数据就 + 1 ,统计 10 秒内的样本量
self.metric_predict_acc = self.metric_right_10_sec.get_count() / self.metric_total_10_sec.get_count() # 准确率
self.metric_distribution_y.update(y) # 更新分布 Distribution :训练过的样本数量 + 1
# 返回预测结果
return y_pred
2.4.3 模型保存
在线学习过程,我们需要不断地更新并保存模型。如果不对模型进行备份,那么模型只会在内存中,如果作业挂掉就模型将会丢失。所以我们需要在 UDF 中设定模型的备份规则,将模型定时备份到 Redis中保存。
def dump_model(self):
if (datetime.now() - self.last_dump_time).seconds >= self.interval_dump_seconds:
r = redis.StrictRedis(**self.redis_params)
try:
r.set(self.model_name, pickle.dumps(self.clf, protocol=pickle.HIGHEST_PROTOCOL))
except (redis.exceptions.RedisError, TypeError, Exception):
logging.warning('无法连接 Redis 以存储模型数据')
self.last_dump_time = datetime.now() # 无论是否更新成功,都更新保存时间
2.4.4 指标监控
在模型训练的过程中,我们通过监控指标了解在线模型训练的运行状态。
首先,我们在UDF 的 open 方法里注册要监控的指标( Metric );然后,在 UDF 的 eval 方法里,完成模型预测后,更新这些监控指标。
定义指标注册和指标计算之后,Flink 自动化地利用 Metric Reporter 收集指标到存储与分析系统;最后,我们可以使用 Flink Dashboard 可视化地观察监控指标的当前值和历史变化趋势。
当然我们也可以根据监控指标的状态定义告警机制。
# 访问指标系统,并注册指标,以便于在 webui (localhost:8081) 实时查看算法的运行情况
def open(self, function_context):
# 访问指标系统,并定义 Metric Group 名称为 online_ml 以便于在 webui 查找
# Metric Group + Metric Name 是 Metric 的唯一标识
metric_group = function_context.get_metric_group().add_group("online_ml")
# 目前 PyFlink 1.11.2 支持 4 种指标:计数器 Counters,量表 Gauges,分布 Distribution 和仪表 Meters 。
# 1、计数器 Counter,用于计算某个东西出现的次数,可以通过 inc()/inc(n:int) 或 dec()/dec(n:int) 来增加或减少值
self.metric_counter = metric_group.counter('sample_count') # 训练过的样本数量
# 2、量表 Gauge,用于根据业务计算指标,可以比较灵活地使用
# 目前 pyflink 只支持 Gauge 为整数值
metric_group.gauge("prediction_acc", lambda: int(self.metric_predict_acc * 100))
# 3、分布 Distribution,用于报告某个值的分布信息(总和,计数,最小,最大和平均值)的指标,可以通过 update(n: int) 来更新值
# 目前 pyflink 只支持 Distribution 为整数值
self.metric_distribution_y = metric_group.distribution("metric_distribution_y")
# 4、仪表 Meters,用于汇报平均吞吐量,可以通过 mark_event(n: int) 函数来更新事件数。
# 统计过去 10 秒内的样本量、预测正确的样本量
self.metric_total_10_sec = metric_group.meter("total_10_sec", time_span_in_seconds=10)
self.metric_right_10_sec = metric_group.meter("right_10_sec", time_span_in_seconds=10)
2.5 流处理完整程序结构
除了上述源表和结果表的创建,以及定义 UDF 模型训练与指标监控业务,流处理过程中要需要完成如下任务:
- 创建流处理环境
- 指定 kafka 依赖
- 指定 python 依赖
- 注册 UDF
- 使用 UDF 执行流处理任务
import os
from udf_model import Model
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import (DataTypes, TableDescriptor, Schema, StreamTableEnvironment, EnvironmentSettings)
from pyflink.table.window import Slide
from pyflink.table.udf import udaf
from pyflink.table.expressions import col, lit
def online_learning():
# ------------------------- kafka 配置 --------------------
kafka_servers = "localhost:9092"
kafka_consumer_group_id = "group0" # group ID
source_topic = "handwritten_digit" # 源数据
sink_topic = "digit_predict" # 结果
# ------------------------- 初始化流处理环境 -----------------
# 创建 Blink 流处理环境
env = StreamExecutionEnvironment.get_execution_environment()
env.set_max_parallelism(1)
env.set_parallelism(1)
env_settings = EnvironmentSettings.new_instance().in_streaming_mode().use_blink_planner().build()
t_env = StreamTableEnvironment.create(stream_execution_environment=env, environment_settings=env_settings)
# 指定 kafka jar 包依赖 flink-sql-connector-kafka.jar
jars = []
for file in os.listdir(os.path.abspath(os.path.dirname(__file__))):
if file.endswith('.jar'):
jars.append(os.path.abspath(file))
str_jars = ';'.join(['file://' + jar for jar in jars])
t_env.get_config().get_configuration().set_string("pipeline.jars", str_jars)
# 指定 python 依赖
dir_requirements = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'requirements.txt')
dir_cache = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'cached_dir')
if os.path.exists(dir_requirements):
if os.path.exists(dir_cache):
# 方式 1:上传到集群以支持离线安装
t_env.set_python_requirements(dir_requirements, dir_cache)
else:
# 方式 2:指定描述依赖的依赖文件 requirements.txt,作业运行时下载
t_env.set_python_requirements(dir_requirements)
# ------------------------ 创建源表和结果表 ------------------
# 创建源表(source)
source_ddl = f"""
CREATE TABLE source (
x ARRAY, -- 图片灰度数据
actual_y TINYINT, -- 实际数字
ts TIMESTAMP(3) -- 图片产生时间
) with (
'connector' = 'kafka',
'topic' = ' {source_topic}',
'properties.bootstrap.servers' = '{kafka_servers}',
'properties.group.id' = '{kafka_consumer_group_id}',
'scan.startup.mode' = 'latest-offset',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true',
'format' = 'json'
)
"""
t_env.execute_sql(source_ddl)
t_env.from_path('source').print_schema()
# 创建结果表(sink) 将统计结果实时写入到 Kafka
sink_ddl = f"""
CREATE TABLE sink (
x ARRAY, -- 图片灰度数据
actual_y TINYINT, -- 实际数字
predict_y TINYINT -- 预测数字
) with (
'connector' = 'kafka',
'topic' = ' {sink_topic}',
'properties.bootstrap.servers' = '{kafka_servers}',
'properties.group.id' = '{kafka_consumer_group_id}',
'scan.startup.mode' = 'latest-offset',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true',
'format' = 'json'
)
"""
t_env.execute_sql(sink_ddl)
# ------------------------ 注册 UDF -----------------
model = udf(Model(), input_types=[DataTypes.ARRAY(DataTypes.INT()), DataTypes.TINYINT()],
result_type=DataTypes.TINYINT())
t_env.register_function('train_and_predict', model)
# ------------------------ 执行流处理任务 --------------
t_env.sql_query("""
SELECT
x,
actual_y,
train_and_predict(x, actual_y) AS predict_y
FROM
source
""").insert_into("sink")
t_env.execute('Classifier Model Train')
if __name__ == "__main__":
online_learning()
2.6 查看在线模型训练状态
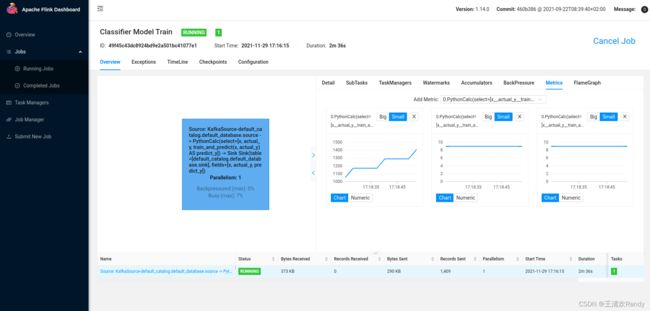
我们通过 Flink Dashboard 可视化地观察监控指标的当前值和历史变化趋势以反映在线模型训练的状态
模型训练的状态获得过程如下:
指标注册:在 UDF 的 open 方法里,对几个监控指标( Metric )进行注册。指标计算:在 UDF 的 eval 方法里,完成模型预测后,再计算之前定义的监控指标。指标收集:这一步是 Flink 自动完成的,Flink 会利用 Metric Reporter 收集指标到存储或分析系统。指标可视化:在 Flink Dashboard (http://localhost:8081 )可以看到指标的当前值和历史变化趋势,如下图所示
2.7 使用模型进行手写体识别
前面我们已经在 UDF 里设定模型的加载与保存逻辑,最后利用 Flask 加载 Redis 里的最新模型进行手写体识别。
我们基于 Flask 框架,实现网页的渲染和提供预测 API 服务,实现手写体数字输入的 Web 服务;其中,预测 API 服务中需要完成模型加载、特征工程和模型预测三项主要功能。
在开始编写 API 之前需要下载相关依赖环境 pip install -r requirement.txt:
svglib>=1.0.1
reportlab>=3.5.55
Flask>=1.1.1
Flask-Cors>=3.0.8
opencv-python>=4.4.0.46
Pillow>=6.2.1
2.7.1 模型加载
由于模型体积很小,因此无论是否有在实时训练,每次调用预测 API 时都会从 Redis 里动态加载最新的模型;实际线上运行时,需要异步地确认模型版本、异步地加载模型
# Redis 设置
redis_params = dict(
host='localhost',
password='redis_password',
port=6379,
db=0
)
model_key = 'online_ml_model'
# 加载最新模型
def load_latest_clf_model():
# 连接 Redis
r = redis.StrictRedis(**redis_params)
model = None
try:
model = pickle.loads(r.get(model_key))
except TypeError:
logging.exception('Redis 内没有找到模型,请确认 Key 值')
except (redis.exceptions.RedisError, TypeError, Exception) as err:
logging.exception(f'Redis 出现异常:{err}')
return model
2.7.2 特征工程
线上传过来的手写数据是类型为 image/svg+xml;base64 的字符串,而模型需要的数据为 1 * 64 的灰度数组,因此需要做数据转换,这里就统称为特征工程,主要用到了 PIL / Svglib / numpy 等框架
def format_svg_base64(s: str) -> np.array:
# base64 to svg
with open('digit.svg', 'wb') as f:
f.write(base64.b64decode(s))
# svg to png
drawing = svg2rlg("digit.svg")
renderPM.drawToFile(drawing, "digit.png", fmt="PNG")
# 由于 png 的长宽并不规则,因此需要先将 png 压缩到能装入目标大小的尺寸
target_w, target_h = 8, 8 # 目标宽度和高度
png = Image.open('digit.png')
w, h = png.size # 压缩前的宽和高
scale = min(target_w / w, target_h / h) # 确定压缩比例,保证缩小后到能装入 8 * 8
new_w, new_h = int(w * scale), int(h * scale) # 压缩后的宽和高
png = png.resize((new_w, new_h), Image.BILINEAR) # 压缩
# 将 png 复制粘贴到目标大小的空白底图中间,并用白色填充周围
new_png = Image.new('RGB', (target_w, target_h), (255, 255, 255)) # 新建空白底图
new_png.paste(png, ((target_w - new_w) // 2, (target_h - new_h) // 2)) # 复制粘贴到空白底图的中间
# 颜色反转(将手写的白底黑字,转变为模型需要的黑底白字),然后压缩数值到 0~16 的范围,并修改尺寸为 1 * 64
array = 255 - np.array(new_png.convert('L')) # 反转颜色
array = (array / 255) * 16 # 将数值大小压缩到 0~16
array = array.reshape(1, -1) # 修改尺寸为 1 * 64
return array
2.7.3 模型预测
数据处理完成后,直接喂给加载好的模型,调用模型的 predict 方法得到预测结果,再用 Flask 的 jsonify 函数序列化后返回给前端
def predict():
global clf
img_string = request.form['imgStr']
# 格式化 svg base64 字符串为模型需要的数据
data = format_svg_base64(img_string)
# 每次都从 redis 里加载模型
model = load_latest_clf_model()
clf = model or clf # 如果 redis 加载模型失败,就用最后一次加载的有效模型
# 模型预测
predict_y = int(clf.predict(data)[0])
return jsonify({'success': True, 'predict_result': predict_y}), 201
2.8 运行实例
首先我们使用 docker 按照如下容器编排创建一个 kafka,同时构建一个 zookeeper 与 kafka 结合一起使用,用于管理 kafka 的 broker,以及实现负载均衡。
version: "3.5"
services:
zookeeper:
image: zookeeper:3.6.2
ports:
- "2181:2181" ## 对外暴露的 zookeeper 端口号
container_name: zookeeper
kafka:
image: wurstmeister/kafka:2.13-2.6.0
volumes:
- /etc/localtime:/etc/localtime ## kafka 镜像和宿主机器之间时间保持一致
ports:
- "9092:9092" ## 对外暴露的 kafka 端口号
depends_on:
- zookeeper
environment:
KAFKA_ADVERTISED_HOST_NAME: localhost
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_PORT: 9092
KAFKA_BROKER_ID: 1
KAFKA_LOG_RETENTION_HOURS: 120
KAFKA_MESSAGE_MAX_BYTES: 10000000
KAFKA_REPLICA_FETCH_MAX_BYTES: 10000000
KAFKA_GROUP_MAX_SESSION_TIMEOUT_MS: 60000
KAFKA_NUM_PARTITIONS: 3
KAFKA_DELETE_RETENTION_MS: 1000
KAFKA_CREATE_TOPICS: "stream-in:1:1,stream-out:1:1" ## 自动创建 topics
container_name: kafka
redis:
image: redis:6.0.9
ports:
- 6379:6379
command:
# 设置 redis 密码为 redis_password
redis-server --requirepass redis_password --appendonly yes
container_name: redis
1 启动容器环境
docker-compose up -d
2 运行数据模拟程序
python data_producer.py
3 运行流处理任务程序
flink run -m localhost:8081 -python online_learning.py
4 启动 Flask Web 模型预测服务
python server.py
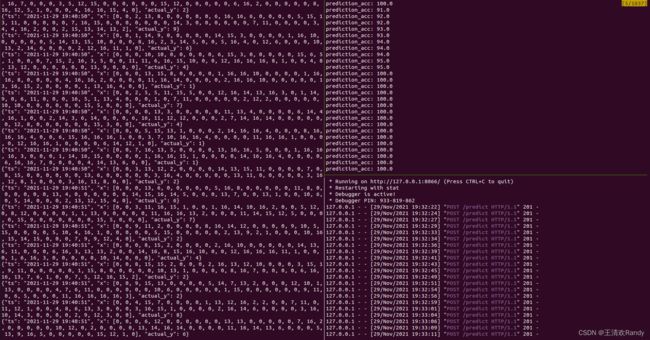
5 查看模型训练状态
终端运行状态如下图所示,左侧为数据生成程序,右侧上部为在线模型训练过程,右侧下部为 Web 服务调用情况
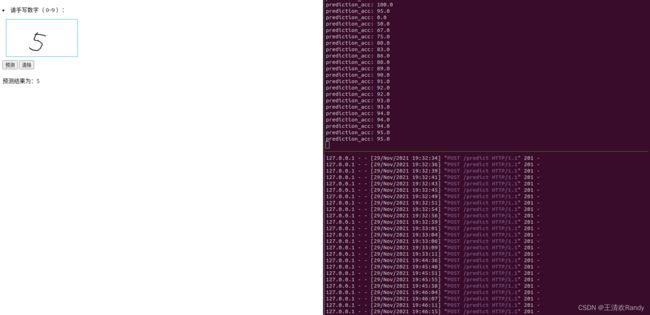
6 使用模型预测服务
启动 Flask Web 模型预测服务后在浏览器访问 http://127.0.0.1:8066/ 进行手写体数字输入,并完成预测服务
2.9 重新训练模型
如果要重新开始在线模型训练任务
- 首先请在 WebUI 里关闭任务,防止模型持续地备份到 Redis。
- 然后清空 Redis 里的模型备份数据,防止模型被重新加载,我在本案例目录下准备了一个
redis_clear.py脚本,直接运行即可清空 Redis 。
# 如果在脚本后面传入多个 key,则会逐个删除 redis 里的这些 key
python redis_clear.py
redis_clear.py 具体代码如下:
import redis
import sys
# 连接 Redis
redis_params = dict(
host='localhost',
password='redis_password',
port=6379,
db=0
)
r = redis.StrictRedis(**redis_params)
try:
model = r.ping()
except (redis.exceptions.RedisError, TypeError, Exception) as err:
raise Exception(f'无法连接 Redis:{err}')
# 如果没有传入任何 key ,则清空整个库
if len(sys.argv) == 1:
r.flushdb()
else:
# 如果传入了 key ,则检查是否存在,并删除
for key in sys.argv[1:]:
if r.exists(key):
r.delete(key)
print(f'已删除 {key}')
else:
print(f'{key} 不存在')
2.10 手写体识别在线机器学习实践完整代码
参考资料
PyFlink 从入门到精通