【5 - 连接查询或多表查询】Sql Server - 郝斌(内连接inner、左/右外连接left/right、完全连接full、交叉连接cross、自连接、联合union、分页查询)
课程地址:数据库 SQLServer 视频教程全集(99P)| 22 小时从入门到精通_哔哩哔哩_bilibili

目录
连接查询(多表查询)
定义
分类
语法
内连接
select ... from A, B(笛卡尔积)
select ... from A, B where ...
select ... from A join B on ...
内连接使用的注意事项
sql92标准和sql99标准转换
select、from、where、join、on、group、order、top、having 的混合使用
习题
1. 求出每个员工的姓名、部门编号、薪水和薪水的等级
2. 查找每个部门的编号、该部门所有员工的平均工资、平均工资的等级(嵌套查询)
3. 求出emp表中所有领导的信息
4. 求出平均薪水最高的部门的编号和部门的平均工资
5. 把工资最低的人排除掉后,剩下的人中工资最低的前3个人的姓名、工资、部门编号、部门名称、工资等级输出
查询的顺序
左(右)外连接
外连接概述
左外连接运行原理
左外连接的实际意义
完全连接和交叉连接
完全连接(full join)
交叉连接(cross join)
自连接
联合union
分页查询
总结
下次课程预告
连接查询(多表查询)
定义
将两个或两个以上的表以一定的连接条件横向连接起来,从中检索出满足连接条件的数据
分类
- 内连接(inner join)
- 外连接(out join —— left 和 right)
- 完全连接(full join)
- 交叉连接(cross join)
- 自连接
- 联合
语法
select [top] select_list
from {table_name [join_type]
join table_name2
on join_condition}[...n]内连接
返回所有相匹配的行对,废弃两个表中不匹配的行
select E.ename "员工姓名", D.dname "部门名称"
from emp E join dept D
on E.deptno = D.deptno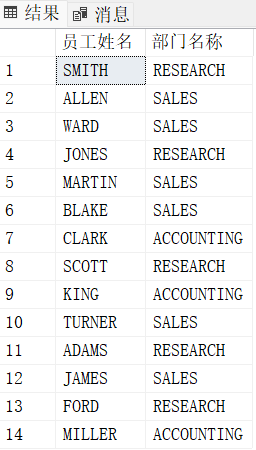
select ... from A, B(笛卡尔积)
产生的结果:行数为A和B两个表行数的乘积,列数为A和B两个表列数之和
或者说把A表的每一条记录都和B表的每一条记录组合在一起,形成的是个笛卡尔积
或者说把B表的每一条记录都和A表的每一条记录组合在一起,形成的是个笛卡尔积
- emp表有14行、8列
- dept表有5行、3列
select * from emp,dept -- 70行11列(笛卡尔积),当做临时表
-- 等价于
select * from emp join dept on 1 = 1select * from A, B 输出结果 和 select * from B, A 输出结果 是一模一样的
select ... from A, B where ...
对 select ... from A, B 产生的笛卡尔积用 where 中的条件进行过滤(A和B顺序互换,输出结果不变)
select * from emp,dept where empno = 7369 -- 5行11列
select * from emp,dept where ename = 'king' -- 5行11列
select * from emp,dept where loc = 'NEW YORK' -- 14行11列
select * from emp,dept where emp.deptno = 10 -- 5的倍数行(dept表行数的倍数行)
-- 把emp表的每一行和dept表的所有行(5行)组合
-- emp表中不止一条记录的deptno为10,故为5的倍数行
select * from emp,dept where dept.deptno = 10 -- 14行(输出的行数肯定是emp表行数的倍数)
select * from emp,dept where emp.deptno = dept.deptno -- 14行11列小结:
select * from emp,dept- 产生的是个笛卡尔积
- 查询结果集的记录个数是emp表和dept表记录个数的乘积
- 查询结果集中每条记录的字段个数是emp和dept表字段个数之和
select * from emp,dept where ename = 'king'- select * from emp,dept 产生的是个笛卡尔积
- where ename = 'king' 是用来对笛卡尔积进行过滤(where中写的过滤条件是对 (emp, dept) 产生的笛卡尔积临时表过滤)
select * from emp,dept where emp.deptno = dept.deptno- emp,dept可以互换,对输出结果没有任何影响
- emp.deptno = dept.deptno 也可以互换,对输出结果没有任何影响
select ... from A join B on ...
join是连接,on后面写连接条件(不能省),有join就必须有on(A和B顺序互换,输出结果不变)
select *
from emp E
join dept D
on 1 = 1 -- 永远成立,结果70行11列
select E.ename "员工姓名", D.dname "部门名称"
from emp E
join dept D
on 1 = 1 -- 永远成立,结果70行2列
select *
from emp E
join dept D -- 表示连接哪一张表
on E.deptno = D.deptno -- 表示连接条件
-- 结果14行11列
select E.ename "员工姓名", D.dname "部门名称"
from emp E
join dept D
on E.deptno = D.deptno -- 结果14行2列判断下面语句是否正确:
select deptno -- 不明确
from emp E
join dept D
on 1 = 1
-- 如果在很多表里存在同一个字段,必须得在字段面前加一个表的名字以下两种写法结果是一样的:
-- 下面两种写法,输出结果一样,均为14行11列
select *
from emp, dept
where emp.deptno = dept.deptno -- 是sql92标准
select *
from emp E
join dept D
on E.deptno = D.deptno -- 是sql99标准(推荐使用这种)
-- sql99更容易理解,且在sql99标准中,on和where可以做不同分工
-- on指定连接条件,where对连接之后临时表的数据进行过滤把工资大于2000的员工的姓名和部门的名称输出
-- sql92的实现方式
select E.ename, D.dname
from emp E, dept D
where E.sal > 2000 and E.deptno = D.deptno
-- sql99的实现方式
select E.ename, D.dname
from emp E join dept D
on E.deptno = D.deptno
where E.sal > 2000
-- 也可以写成
select E.ename, D.dname
from emp E join dept D
on E.deptno = D.deptno and E.sal > 2000 
on中既可以写连接条件,也可以写过滤条件
但是不推荐,应该分开写,on中只写连接条件, where中写过滤条件
把工资大于2000的员工的姓名和部门的名称和工资的等级输出
- SALGRADE (GRADE, LOSAL, HISAL) 5行3列
select *
from emp E
join dept D
on 1 = 1
join salgrade S
on 1 = 1 -- 输出的是350行11列,行数是乘积,列数是之和-- sql99标准
select E.ename, D.dname, S.GRADE
from emp E
join dept D
on E.deptno = D.deptno
join SALGRADE S
on E.sal >= S.LOSAL and E.sal <= S.HISAL
where E.sal > 2000
-- sql92标准
select E.ename, D.dname, S.GRADE
from emp E, dept D, SALGRADE S
where E.deptno = D.deptno
and E.sal >= S.LOSAL and E.sal <= S.HISAL
and E.sal > 2000 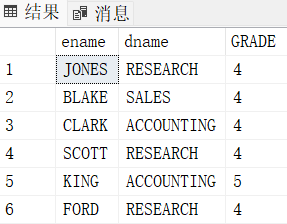
where是否可以写在 join on 的前面?
-- error
select E.ename, D.dname, S.GRADE
from emp E
where E.sal > 2000
join dept D
on E.deptno = D.deptno
join SALGRADE S
on E.sal >= S.LOSAL and E.sal <= S.HISAL查询姓名第二个字母是A的所有员工的姓名、工资、部门编号、部门名称、薪水等级
select ename, sal, E.deptno, dname, S.grade
from emp E
join dept D
on E.deptno = D.deptno
join salgrade S
on E.sal between S.losal and S.hisal
where E.ename like '_A%'内连接使用的注意事项
select * from 表名1 -- 1行
join 表名2 -- 2行
on 连接条件 -- 3行- 如果含有了join,则必须得加on,即有2行代码就必须得有3行代码
- from 表名1 后面不能再加其他表名
sql92标准和sql99标准转换
-- sql92标准
select * from emp, dept
where dept.deptno = 10 -- 不是连接条件,是过滤条件
-- 考虑如何把上面的sql语句用sql99标准来实现
-- sql99标准(错误)
select * from emp
join dept
on dept.deptno = emp.deptno -- 错误,on中指定的是连接条件,上述语句的连接条件永远为真
having dept.deptno = 10 -- 错误,因为having是对分组之后的过滤,这里没有分组,肯定出错
-- sql99标准(正确)
select * from emp
join dept
on 1 = 1
where dept.deptno = 10 -- 结果为14行select、from、where、join、on、group、order、top、having 的混合使用
输出姓名不包含A的所有员工中工资最高的前三名的每个员工的姓名、工资、工资等级、部门名称
select top 3 E.ename, E.sal, S.grade, D.dname
from emp E
join dept D
on E.deptno = D.deptno
join salgrade S
on E.sal between S.losal and S.hisal
where E.ename not like '%A%'
order by E.sal desc习题
- 求出每个员工的姓名、部门编号、薪水和薪水的等级
- 查找每个部门的编号、该部门所有员工的平均工资、平均工资的等级
- 求出emp表中所有领导的姓名
- 求出平均薪水最高的部门的编号和部门的平均工资
- 把工资大于所有员工中工资最低的前3个人的姓名、工资、部门编号、部门名称、工资等级输出
1. 求出每个员工的姓名、部门编号、薪水和薪水的等级
select E.ename, E.deptno, E.sal, S.grade
from emp E
join salgrade S
on E.sal >= S.losal and E.sal <= S.hisal2. 查找每个部门的编号、该部门所有员工的平均工资、平均工资的等级(嵌套查询)
select T.deptno, T.avg_sal "部门平均工资", S.grade "工资等级"
from(
select deptno, avg(sal) as "avg_sal"
from emp group by deptno
) T
join salgrade S
on T.avg_sal between S.losal and S.hisal -- 结果为3行
# 第二种写法
select T.deptno, T.avg_sal "部门平均工资", S.grade "工资等级"
from(
select deptno, avg(sal) as "avg_sal"
from emp group by deptno
) T, salgrade S
where T.avg_sal between S.losal and S.hisal -- 结果为3行
若在以上基础上还想查询部门名称:
select T.deptno, T.avg_sal "部门平均工资", S.grade "工资等级", D.dname
from(
select deptno, avg(sal) as "avg_sal"
from emp group by deptno
) T
join salgrade S
on T.avg_sal between S.losal and S.hisal
join dept D
on T.deptno = D.deptno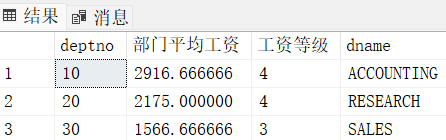
3. 求出emp表中所有领导的信息
select * from emp
where empno in (select mgr from emp)
思考:求出emp表中所有非领导的信息
select * from emp
where empno not in (select mgr from emp) -- 这样写不对
-- in与null组合所带来的问题 mgr 存在 null值
mgr 存在 null值
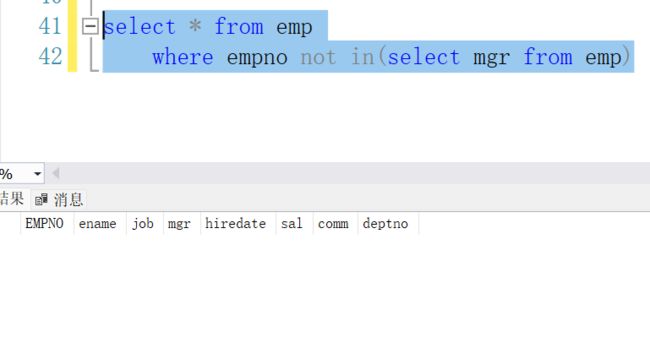
正确写法:
select * from emp
where empno not in(select mgr from emp where mgr is not null)4. 求出平均薪水最高的部门的编号和部门的平均工资
-- 写法1(只能在SQL Server里用,Oracle不能用,因为Oracle里没有top)
select top 1 deptno "部门编号", avg(sal) "平均工资"
from emp
group by deptno
order by avg(sal) desc
-- 写法2
select E.*
from (
select deptno, avg(sal) "avg_sal" -- 独立嵌套子查询
from emp
group by deptno
) E
where E.avg_sal = (select max(avg_sal) from (select avg(sal) "avg_sal" from emp
group by deptno) T) 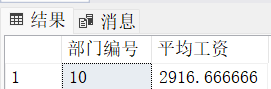
5. 把工资最低的人排除掉后,剩下的人中工资最低的前3个人的姓名、工资、部门编号、部门名称、工资等级输出
select top 3 E.ename, E.sal, E.deptno, D.dname, S.grade
from (
select * from emp E where sal > (select min(sal) from emp) -- 工资>最低工资800
) E -- 可以和里面的emp E同名,没有冲突,因为范围不同
join dept D
on E.deptno = D.deptno
join salgrade S
on E.sal between S.LOSAL and S.HISAL
order by E.sal asc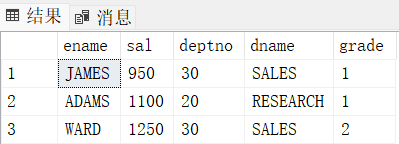
嵌套查询分为
- 独立嵌套子查询(内部查询语句可以单独运行出结果)
- 关联嵌套子查询(内部查询语句运行必须依附外部查询语句)
查询的顺序
select [top] ...
from A
join B
on ...
join C
on ...
where...
group by...
having...
order by...把工资大于1500的所有员工按部门分组,把部门平均工资大于2000的、最高的、前2个部门的编号、名称、平均工资等级输出
select top 2 E.deptno, D.dname, S.grade -- 问题在于D.dname, S.grade不是聚合字段
from emp E
join dept D
on E.deptno = D.deptno
join salgrade S
on E.sal between S.losal and S.hisal
where E.sal > 1500
group by E.deptno
having avg(E.sal) > 2000
order by avg(E.sal) desc
select top 2 E.deptno, avg(E.sal) "avg_sal"
from emp E
join dept D
on E.deptno = D.deptno
join salgrade S
on E.sal between S.losal and S.hisal
where E.sal > 1500
group by E.deptno
having avg(E.sal) > 2000
order by avg(E.sal) desc
再通过 deptno 去查找 dname,avg_sal 去查找 grade(部门平均工资等级)
-- 写法1
select D.dname, T.*, S.GRADE
from dept D
join(
select top 2 E.deptno, avg(E.sal) "avg_sal"
from emp E
join dept D
on E.deptno = D.deptno
join salgrade S
on E.sal between S.losal and S.hisal
where E.sal > 1500
group by E.deptno
having avg(E.sal) > 2000
order by avg(E.sal) desc) T
on D.deptno = T.deptno
join salgrade S
on T.avg_sal between S.LOSAL and S.HISAL
- having里不能写字段的别名
- order by里可以写字段的别名
-- 写法2
select D.dname, T.*, S.GRADE
from dept D
join
(select top 2 deptno, avg(sal) as "avg_sal"
from emp where sal > 1500
group by deptno
having avg(sal) > 2000
order by "avg_sal" desc) T
on D.deptno = T.deptno
join SALGRADE S
on T.avg_sal between S.LOSAL and S.HISAL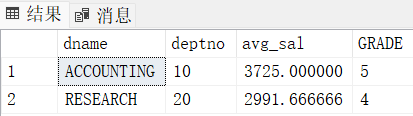
左(右)外连接
join默认是内连接(inner join),前面的 inner 可以省略
外连接概述
定义:不但返回满足连接条件的所有记录,而且会返回部分不满足条件的记录
分类:
- 左外连接:不但返回满足连接条件的所有记录,而且会返回左表不满足连接条件的记录
- 右外连接:不但返回满足连接条件的所有记录,而且会返回右表不满足连接条件的记录
左外连接运行原理
- 用左表的第一行分别和右表的所有行进行连接,如果有匹配的行,则一起输出;如果右表有多行匹配,则结果集输出多行;如果没有匹配行,则结果集中只输出一行,该输出行左边为左表第一行内容,右边全部输出null
- 然后再用左表第二行和右边所有行进行连接,如果有匹配的行,则一起输出;如果右表有多行匹配,则结果集输出多行;如果没有匹配行,则结果集中只输出一行,该输出行左边为左表第二行内容,右边全部输出null
- 以此类推,直至左边所有行连接完毕
- 因此右边很可能出现有多行和左边的某一行匹配,所以左连接产生的结果集的行数很可能大于 left join 左边表的记录的总数
- 帮助文档:左向外连接的结果集包括 left outer 子句中指定的左表的所有行,而不仅仅是连接列所匹配的行。如果左边的某行在右边中没有匹配行,则在相关联的结果集行中右边的所有选择列表列均为空值
实际上左连接产生的结果集的行数很可能大于 left join 左边表的记录的总数,不能理解为:左连接 left join 左边表有n行,最终产生的记录也是n行。实际上左连接产生的结果集的行数很可能大于 left join 左边表的记录的总数
select * from emp E left join dept D
on E.deptno = D.deptno -- 至少是左边表的行数(14)
select * from dept D left join emp E
on E.deptno = D.deptno
-- 这里dept表是5行,其中3行对应了emp中的14条记录,还有2行没有对应
-- 故输出结果为14+2=16行左外连接的实际意义
返回一个事物及其该事物的相关信息,如果该事物没有相关信息,则输出null
例子:

完全连接和交叉连接
完全连接(full join)
select * from A
full join B
on A.xxx = B.xxx结果集中包含三部分内容:
- 两个表中匹配的所有行记录
- 左表中那些在右表中找不到匹配的行的记录,这些记录的右边全为null
- 右表中那些在左表中找不到匹配的行的记录,这些记录的左边全为null
交叉连接(cross join)
交叉连接就是笛卡尔积
select * from emp cross join dept
等价于
select * from emp, dept自连接
定义:一张表自己和自己连接起来查询数据
例子:求出薪水最高的员工的信息
-- 用聚合函数
select * from emp
where sal = (select max(sal) from emp)
-- 不能用聚合函数
-- 自连接必须要用别名来命名两个相同的表
select distinct E1.empno
from emp E1, emp E2
where E1.sal < E2.sal
select distinct E1.empno -- 不包含sal最高的记录的empno(13个)
from emp E1
join emp E2
on E1.sal < E2.sal
-- 答案
select * from emp
where empno not in(
select distinct E1.empno -- 不包含sal最高的记录的empno(13个)
from emp E1
join emp E2
on E1.sal < E2.sal
)
子查询分为单行单列、单行多列、多行单列、多行多列( = 只能用在单行里,多行要用 in)
联合union
输出每个员工的姓名、工资、上司的姓名
select E1.ename, E1.sal, E2.ename
from emp E1
join emp E2
on E1.mgr = E2.EMPNO 结果少了一个 没有mgr的员工(即官位最大,没有上司)
结果少了一个 没有mgr的员工(即官位最大,没有上司)
正确写法:
-- 写法1:left join
select E1.ename, E1.sal, E2.ename
from emp E1
left join emp E2
on E1.mgr = E2.EMPNO
-- 写法2:union
select E1.ename "员工姓名", E1.sal "员工工资", E2.ename "上司姓名"
from emp E1
join emp E2
on E1.mgr = E2.EMPNO
union
select ename "员工姓名", sal "员工工资", '已是最大老板' from emp where mgr is null -- 字符串用单引号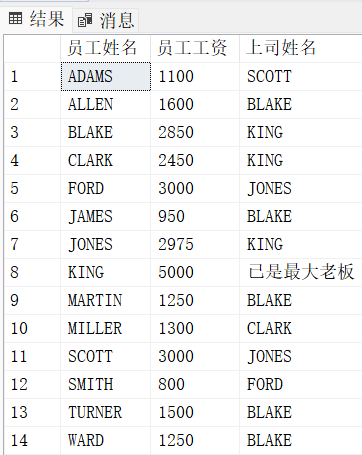
联合定义:纵向的连接表中的数据,即表和表之间的数据以纵向的方式连接在一起
我们之前讲的所有连接都是以横向的方式连接在一起
注意:若干个select子句要联合成功的话,必须得满足两个条件:
- 这若干个select子句输出的列数必须是相等的
- 这若干个select子句输出列的数据类型至少是兼容的
整型和字符型类型的转换 convert() —— 显式转换
分页查询
输出工资最高的前三个员工的所有信息
select top 3 * from emp order by sal desc -- 从输出结果来看,先执行order by,后执行top
工资从高到低排序,输出工资是第4-6的员工信息
select top 3 * from emp
where empno not in (select top 3 empno from emp order by sal desc)
order by sal desc
工资从高到低排序,输出工资是第7-9的员工信息
select top 3 * from emp
where empno not in (select top 6 empno from emp order by sal desc)
order by sal desc
总结
- 第1页 0
- 第2页 3
- 第3页 6 = (第3页-1)*每页3条
- 第4页 9 = (第4页-1)*每页3条
假设每页显示n条记录,当前要显示的是第m页,表名是A,主键是A_id
select top n *
from A
where A_id not in (select top (m-1)*n A_id from emp order by...)下次课程预告
- 视图
- 事务
- 索引
- 存储过程
- 游标
- TL_SQL