AI-Tesseract-OCR简介
文章目录
-
- windows
-
- Tesseract安装
- Tesseract的使用
- TESSERACT手册页(tesseract.1.asc)
-
- 输入/输出参数(IN/OUT ARGUMENTS)
-
- FILE
- OUTPUTBASE
- 可选项(OPTIONS)
-
- -c CONFIGVAR=VALUE
- --dpi N
- -l LANG -l SCRIPT
- --psm N
- --oem N
- --tessdata-dir PATH
- --user-patterns FILE
- --user-words FILE
- CONFIGFILE
- 单一选项(SINGLE OPTIONS)
-
- -h, --help
- --help-extra
- --help-psm
- --help-oem
- -v, --version
- --list-langs
- --print-parameters
- 语言和脚本(LANGUAGES AND SCRIPTS)
- 配置文件和用户数据增强(CONFIG FILES AND AUGMENTING WITH USER DATA)
- 环境变量
-
- TESSDATA_PREFIX
- OMP_THREAD_LIMIT
- 编译(Compiling)
-
- Windows
-
- 主分支,3.05及更高版本
-
- 使用Tesseract
- 构建最新的库
- VS2017编译
- Android
-
- 前提
- 直接使用
- 手动编译
- 样本训练
-
- 3.02XX助手训练字库
-
- 准备工作
- 训练字库
-
- 准备字体图片tif文件
-
- 方法一:获取游戏字体文件
- 方法二:游戏内截图
- 生成box文件
- 使用jTessBoxEditor工具修正(可选)
- 打包字库文件
- 生成训练文件
- 加载使用
windows
Tesseract安装
适用于Tesseract 3.05和Tesseract 4的Windows安装程序可从UB Mannheim的Tesseract获得。
例如64位安装包:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v4.1.0.20190314.exe
下载完成后,右击安装即可,安装完成之后,配置一下环境变量,编辑 系统变量里面 path,添加下面的安装路径:
C:\Program Files\Tesseract-OCR
安装完成之后,直接cmd输入:
C:\Users\Administrator>tesseract -v
tesseract v4.0.0.20190314
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.2.0
Found AVX2
Found AVX
Found SSE
安装python的封装接口:
pip install pillow #一个python的图像处理库,pytesseract依赖
pip install pytesseract
注意第一步必须安装成功,同时配置好环境变量,否则第二步必会报错,因为第二步是接口,运行时候会调用第一步的原C++写的类库。
语言包可以在这里下载。
之后解压放在C:\Program Files\Tesseract-OCR\tessdata目录下。
Tesseract的使用
Tesseract是一个命令行程序,因此首先打开一个终端或命令提示符。 该命令使用如下:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
因此,在名为“myscan.jpg”的图像上执行OCR并将结果保存到“out.txt”的基本用法是:
tesseract H:\OpenSource_Git\ocr\sucai\myscan.jpg H:\OpenSource_Git\ocr\sucai\out
动图如下:

也可以使用德文语言包:
tesseract H:\OpenSource_Git\ocr\sucai\myscan.jpg H:\OpenSource_Git\ocr\sucai\out -l deu
它甚至可以用多种语言的训练数据,例如。 英语和德语:
tesseract H:\OpenSource_Git\ocr\sucai\myscan.jpg H:\OpenSource_Git\ocr\sucai\out -l eng+deu
Tesseract还包括一个hOCR模式,它生成一个特殊的HTML文件,其中包含每个单词的坐标。 这可用于使用诸如Hocr2PDF之类的工具创建可搜索的pdf。 要使用它,请使用’hocr'配置选项,如下所示:
tesseract H:\OpenSource_Git\ocr\sucai\myscan.jpg H:\OpenSource_Git\ocr\sucai\out hocr
生成的out.hocr直接拖到浏览器中就可以看到效果了:
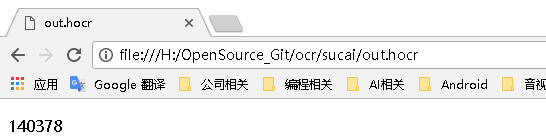
您还可以直接从tesseract创建可搜索的pdf(文字版的)(版本> = 3.03):
tesseract H:\OpenSource_Git\ocr\sucai\myscan.jpg H:\OpenSource_Git\ocr\sucai\out pdf
有关各种选项的更多信息,请参见Tesseract联机帮助页。
TESSERACT手册页(tesseract.1.asc)
参考于:https://github.com/tesseract-ocr/tesseract/blob/master/doc/tesseract.1.asc
tesseract - 命令行OCR引擎
tesseract FILE OUTPUTBASE [OPTIONS]… [CONFIGFILE]…
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
输入/输出参数(IN/OUT ARGUMENTS)
FILE
输入文件的名称。可以是图像文件或文本文件。
支持大多数图像文件格式(Leptonica可读的任何格式)。
如果是文本文件,则文本中列出所有输入图像的名称(每行一个图像名称)。
对于每种输出文件格式(txt,pdf,hocr,xml),结果都将合并到一个文件中。
如果FILE是stdin或 - 则使用标准输入。
OUTPUTBASE
输出文件的基本名称(将附加相应的扩展名)。默认情况下,输出将是一个文本文件,其中.txt添加到基本名称,除非有一个或多个参数设置明确指定所需的输出。如果OUTPUTBASE是stdout或 - 则使用标准输出。
可选项(OPTIONS)
-c CONFIGVAR=VALUE
将参数CONFIGVAR的值设置为VALUE。允许多个-c参数。
–dpi N
在DPI中为输入图像指定分辨率N.N的典型值为300.如果没有此选项,则从图像中包含的元数据中读取分辨率。如果图像不包含该信息,Tesseract会尝试猜测它。
-l LANG -l SCRIPT
要使用的语言或脚本。如果未指定,则假定为eng(英语)。可以指定多种语言,用加号字符分隔。Tesseract使用3个字符的ISO 639-2语言代码(请参阅下面的 LANGUAGES AND SCRIPTS)。
例如:
tesseract H:\OpenSource_Git\ocr\sucai\myscan.jpg H:\OpenSource_Git\ocr\sucai\out -l chi_sim
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata ,简体中文字库文件名为: chi_sim.traineddata)
–psm N
将Tesseract设置为仅运行分析的某个子集并假设某种形式的图像。N的选项是:
0 =仅限方向和脚本检测(OSD)。
1 =使用OSD自动分页。
2 =自动页面分割,但没有OSD或OCR。(未实现)
3 =全自动页面分割,但没有OSD。(默认)
4 =假设一列可变大小的文本。
5 =假设一个垂直对齐文本的统一块。
6 =假设一个统一的文本块。
7 =将图像视为单个文本行。
8 =将图像视为单个单词。
9 =将图像视为圆形中的单个单词。
10 =将图像视为单个字符。
11 =稀疏文本。找到尽可能多的文本,没有特定的顺序。
12 =带OSD的稀疏文本。
13 =原始线。将图像视为单个文本行,绕过特定于Tesseract的黑客攻击。
例如:
tesseract H:\OpenSource_Git\ocr\sucai\myscan.jpg H:\OpenSource_Git\ocr\sucai\out --psm 7
--psm 7表示告诉tesseract myscan.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3。
–oem N
指定OCR引擎模式。N的选项是:
0 =仅原始Tesseract。
1 =神经网络仅限LSTM。
2 = Tesseract + LSTM。
3 =默认,基于可用的内容。
–tessdata-dir PATH
指定tessdata路径的位置。
–user-patterns FILE
指定用户模式文件的位置,
用于某种“正则表达式”.如果我们假设您正在扫描具有相同格式的数据的书籍,则可以使用它.
–user-words FILE
指定用户词文件的位置。
CONFIGFILE
要使用的配置的名称。名称可以是tessdata/configs或tessdata/tessconfigs中的文件,也可以是绝对或相对文件路径。配置是纯文本文件,其中包含参数列表及其值,每行一个,空格分隔参数值。有趣的配置文件包括:
- alto - 以ALTO格式输出(OUTPUTBASE.xml)。
- hocr - 以hOCR格式输出(OUTPUTBASE.hocr)。
- pdf - 输出PDF(OUTPUTBASE.pdf)。
- tsv - 输出TSV(OUTPUTBASE.tsv)。
- txt - 输出纯文本(OUTPUTBASE.txt)。
- get.images - 将处理后的输入图像写入文件(tessinput.tif)。
- logfile - 将调试消息重定向到文件(tesseract.log)。
- lstm.train - LSTM培训使用的输出文件(OUTPUTBASE.lstmf)。
- makebox - 写入框文件(OUTPUTBASE.box)。
- quiet - 将调试消息重定向到/ dev / null。
可以选择几个配置文件,例如tesseract image.png demo alto hocr pdf txt将创建四个带有OCR结果的输出文件demo.alto,demo.hocr,demo.pdf和demo.txt。
例如:
tesseract H:\OpenSource_Git\ocr\sucai\myscan.jpg H:\OpenSource_Git\ocr\sucai\out pdf
这时会生成out.pdf文件,pdf是文字版的。
选项
-l LANG,-l SCRIPT和--psm N必须在任何CONFIGFILE之前出现。
单一选项(SINGLE OPTIONS)
-h, --help
显示帮助信息。
–help-extra
为高级用户显示额外帮助。
–help-psm
显示psm mode。
–help-oem
显示oem mode。
-v, --version
返回tesseract可执行文件的当前版本。
–list-langs
列出tesseract引擎的可用语言。可以与--tessdata-dir PATH一起使用。
–print-parameters
打印tesseract参数。
语言和脚本(LANGUAGES AND SCRIPTS)
要使用Tesseract识别某些文本,通常需要使用-l LANG或-l SCRIPT指定文本的语言或脚本(除非它是默认支持的英文文本)。
选择语言还会自动选择特定于语言的字符集和字典(单词列表)。
选择脚本通常会选择该脚本的所有字符,这些字符可以来自不同的语言。包含的字典还包含来自不同语言的混合。在大多数情况下,脚本也支持英语。因此,可以通过使用训练有素的数据来识别未经过专门训练的语言。
使用+可以指定多种语言或脚本。示例:tesseract myimage.png myimage -l eng+deu+fra。
https://github.com/tesseract-ocr/tessdata_fast 提供了快速语言和脚本模型,这些模型也是Linux发行版的一部分。
对于Tesseract 4,tessdata_fast包含以下语言的训练数据文件:
afr (Afrikaans), amh (Amharic), ara (Arabic), asm (Assamese), aze (Azerbaijani),
aze_cyrl (Azerbaijani - Cyrilic), bel (Belarusian), ben (Bengali), bod (Tibetan),
bos (Bosnian), bre (Breton), bul (Bulgarian), cat (Catalan; Valencian), ceb (Cebuano),
ces (Czech), chi_sim (Chinese simplified), chi_tra (Chinese traditional), chr (Cherokee),
cym (Welsh), dan (Danish), deu (German), dzo (Dzongkha), ell (Greek, Modern, 1453-), eng (English),
enm (English, Middle, 1100-1500), epo (Esperanto), equ (Math / equation detection module),
est (Estonian), eus (Basque), fas (Persian), fin (Finnish), fra (French), frk (Frankish), frm (French, Middle, ca.1400-1600), gle (Irish), glg (Galician), grc (Greek, Ancient, to 1453), guj (Gujarati),
hat (Haitian; Haitian Creole), heb (Hebrew), hin (Hindi), hrv (Croatian), hun (Hungarian),
iku (Inuktitut), ind (Indonesian), isl (Icelandic), ita (Italian), ita_old (Italian - Old),
jav (Javanese), jpn (Japanese), kan (Kannada), kat (Georgian), kat_old (Georgian - Old), kaz (Kazakh),
khm (Central Khmer), kir (Kirghiz; Kyrgyz), kmr (Kurdish Kurmanji), kor (Korean),
kor_vert (Korean vertical), kur (Kurdish), lao (Lao), lat (Latin), lav (Latvian), lit (Lithuanian),
ltz (Luxembourgish), mal (Malayalam), mar (Marathi), mkd (Macedonian), mlt (Maltese),
mon (Mongolian), mri (Maori), msa (Malay), mya (Burmese), nep (Nepali), nld (Dutch; Flemish),
nor (Norwegian), oci (Occitan post 1500), ori (Oriya), osd (Orientation and script detection module), pan (Panjabi; Punjabi), pol (Polish), por (Portuguese), pus (Pushto; Pashto), que (Quechua), ron (Romanian;
Moldavian; Moldovan), rus (Russian), san (Sanskrit), sin (Sinhala; Sinhalese), slk (Slovak),
slv (Slovenian), snd (Sindhi), spa (Spanish; Castilian), spa_old (Spanish; Castilian - Old),
sqi (Albanian), srp (Serbian), srp_latn (Serbian - Latin), sun (Sundanese), swa (Swahili),
swe (Swedish), syr (Syriac), tam (Tamil), tat (Tatar), tel (Telugu), tgk (Tajik), tgl (Tagalog),
tha (Thai), tir (Tigrinya), ton (Tonga), tur (Turkish), uig (Uighur; Uyghur), ukr (Ukrainian),
urd (Urdu), uzb (Uzbek), uzb_cyrl (Uzbek - Cyrilic), vie (Vietnamese), yid (Yiddish), yor (Yoruba)
要使用名为foo.traineddata的非标准语言包,请设置TESSDATA_PREFIX环境变量,以便可以在TESSDATA_PREFIX/tessdata/foo.traineddata中找到该文件,并为Tesseract提供参数-l foo。
对于Tesseract 4,tessdata_fast包含以下脚本的训练数据文件:
Arabic, Armenian, Bengali, Canadian_Aboriginal, Cherokee, Cyrillic, Devanagari, Ethiopic, Fraktur, Georgian, Greek, Gujarati, Gurmukhi,
HanS (Han simplified), HanS_vert (Han simplified, vertical), HanT (Han traditional), HanT_vert (Han traditional, vertical), Hangul,
Hangul_vert (Hangul vertical), Hebrew, Japanese, Japanese_vert (Japanese vertical), Kannada, Khmer, Lao, Latin, Malayalam, Myanmar,
Oriya (Odia), Sinhala, Syriac, Tamil, Telugu, Thaana, Thai, Tibetan, Vietnamese.
可以从 https://github.com/tesseract-ocr/tessdata_best 获得相同的语言和脚本。tessdata_best提供慢速语言和脚本模型。训练需要这些模型。它们也可以提供更好的OCR结果,但识别需要更多时间。
tessdata_fast和tessdata_best都只支持LSTM OCR引擎。
还有第三个存储库,https://github.com/tesseract-ocr/tessdata, 其模型支持Tesseract 3传统OCR引擎和Tesseract 4 LSTM OCR引擎。
配置文件和用户数据增强(CONFIG FILES AND AUGMENTING WITH USER DATA)
Tesseract配置文件由parameter-value对的行组成(空格分隔)。这些参数在源代码中记录为标志,如tesseractclass.h中的以下标志:
BOOL_VAR_H(tessedit_train_line_recognizer, false,
"Break input into lines and remap boxes if present");
STRING_VAR_H(tessedit_char_blacklist, "", "Blacklist of chars not to recognize");
这些参数可以启用或禁用引擎的各种功能,并且可以使其加载(或不加载)各种数据。
例如,假设你想用英语OCR,但是要压缩普通字典并加载另一个单词列表和另一个模式列表 - 这两个文件是最常用的额外数据文件。
如果您的语言包位于/path/to/eng.traineddata中,并且hocrr配置位于/path/ to/configs/hocr中,则创建三个新文件:
/path/to/eng.user-words:
the
quick
brown
fox
jumped
/path/to/eng.user-patterns:
1-\d\d\d-GOOG-411
www.\n\\\*.com
/path/to/configs/bazaar:
load_system_dawg F
load_freq_dawg F
user_words_suffix user-words
user_patterns_suffix user-patterns
现在,如果您将单词bazaar作为CONFIGFILE(参看前面)传递给Tesseract,Tesseract将不会加载系统字典或频繁单词的字典,它将加载和使用您提供的eng.user-words和eng.user-patterns文件。前者是一个简单的单词列表,每行一个。后者的格式记录在dict/trie.h的read_pattern_list()中。
环境变量
TESSDATA_PREFIX
如果在path中设置TESSDATA_PREFIX,则该路径用于查找带有语言和脚本识别模型和配置文件的tessdata目录。使用--tessdata-dir PATH是推荐的替代方法。
OMP_THREAD_LIMIT
如果tesseract可执行文件是使用多线程支持构建的,它通常会使用四个CPU内核进行OCR过程。虽然对于单个映像来说这可能会更快,但如果主机提供的CPU核心数少于四个或者许多映像都是OCR,则会导致性能下降。OMP_THREAD_LIMIT=1来表示只使用一个CPU内核。
编译(Compiling)
参考于:https://github.com/tesseract-ocr/tesseract/wiki/Compiling#windows
Windows
主分支,3.05及更高版本
使用Tesseract
!!!重要!!!要在您的应用程序中使用Tesseract(包括tess或将其链接到您的应用程序),请参阅这个非常简单的示例:
https://github.com/tesseract-ocr/tesseract/wiki/User-App-Example。
构建最新的库
CPPAN可以理解为C++的包管理器,包含了众多依赖包,只需要向CPPAN指定依赖包,CPPAN就会帮你下载好需要的依赖包和相关配置。怎么指定?那就是通过cppan.yml文件了。
- 下载源码,在源码的根目录你可以找到
cppan.yml和CMakeLists.txt。
我用的是git clone https://github.com/tesseract-ocr/tesseract.git -b 4.0.0,下载了4.0.0分支,也可以直接下载master分支git clone https://github.com/tesseract-ocr/tesseract.git,两者我都编译通过了。 - 从 https://cppan.org/client/ [下载]最新的CPPAN(C ++ Archive Network https://cppan.org/ )客户端。
: https://raw.githubusercontent.com/cppan/binaries/master/cppan-master-Windows-client.zip 解压后得到cppan.exe,并把cppan.exe所在目录加入环境变量。 - 切换到tesseract目录,使用
cppan命令下载依赖库,下载的依赖库位于C:\Users\Administrator\.cppan下。 - cmake生成对应vs工程即可
对应命令简化如下:
git clone https://github.com/tesseract-ocr/tesseract tesseract -b 4.0.0
cd tesseract
cppan
mkdir build
cd build
cmake ..
如果是想生成64位工程,就使用cmake -G "Visual Studio 15 Win64" ,-G指定CMake的generator,Visual Studio 15即Visual Studio 2017,Win64即64位。当然,你也可以使用cmake gui来生成,更为方便。
VS2017编译
以管理员权限进入build打开工程,并编译,一般推荐先编译cpp-d-b-d,再ALL_BUILD。
编译会报大约120个C2001错误,都是字符编码问题,点击C2001错误所在的文件,使用notepad++打开,改成使用UTF-8 BOM编码即可, 并保存:

然后在vs2017上加载更新后的文件,重新编译,我修改了以下几个文件:

然后正常编译通过了!
还有另一种修改方式也测试通过,因为报错点都是g_set_error中的双引号字符串,如下图:

直接把中间的异常双引号删除即可,可以用ctrl+H快速替换当前页所有的这种异常的双引号。
正常编译通过后如下图:
网上提到的equationdetect.cpp需要改成简体中文(GB2312-80)格式,我并没有遇到,可能是因为我编译的是32位版本吧。
编译完成后,点选CMakeTargets–>INSTALL,执行安装,因为安装在C盘,所以VS必须以管理员权限打开:
1>------ 已启动生成: 项目: cppan-d-b-d, 配置: Debug Win32 ------
2>------ 已启动生成: 项目: build-dependencies, 配置: Debug Win32 ------
3>------ 已启动生成: 项目: copy-dependencies, 配置: Debug Win32 ------
4>------ 已启动生成: 项目: INSTALL, 配置: Debug Win32 ------
4>-- Install configuration: "Debug"
4>-- Installing: C:/Program Files (x86)/tesseract/lib/pkgconfig/tesseract.pc
4>-- Installing: C:/Program Files (x86)/tesseract/bin/tesseract.exe
4>-- Installing: C:/Program Files (x86)/tesseract/lib/tesseract40d.lib
4>-- Installing: C:/Program Files (x86)/tesseract/bin/tesseract40d.dll
.....
4>-- Installing: C:/Program Files (x86)/tesseract/bin/set_unicharset_properties.exe
4>-- Installing: C:/Program Files (x86)/tesseract/bin/unicharset_extractor.exe
4>-- Installing: C:/Program Files (x86)/tesseract/bin/text2image.exe
========== 生成: 成功 4 个,失败 0 个,最新 21 个,跳过 0 个 ==========
从 https://github.com/tesseract-ocr/tessdata_fast 下载对应的语言和脚本,解压放在C:\Program Files (x86)\tesseract\bin\tessdata下
之后就可以愉快的使用前面的命令了
Android
https://github.com/rmtheis/tess-two
tess-two是适用于Android的Tesseract Tools(tesseract-android-tools)的一个分支,增加了一些额外的功能。
Tesseract Tools for Android是一套用于Tesseract OCR和Leptonica图像处理库的Android API和构建文件。
这份代码可以在android studio中直接编译通过!!
它包括了以下部分:
- Tesseract 3.05
- Leptonica 1.74.1
- libjpeg 9b
- libpng 1.6.25
这些依赖项的源代码位于tess-two/jni文件夹中。
tess-two模块包含用于编译Tesseract和Leptonica库以在Android平台上使用的工具。它提供了一个Java API,用于访问native层的Tesseract和Leptonica API。
eyes-two模块包含从eyes-free 项目中拷贝的额外的图像处理代码。它包含了用于文本检测,模糊检测,光流检测和阈值处理的native函数。使用Tesseract或Leptonica API不需要使用Eyes-two。
tess-two-test模块包含用于tess-two的单元测试。
前提
1.Android 2.3 或更高
2.将v3.04 trained data file拷贝到安卓设备中,文件夹名必须为tessdata。
直接使用
在build.gradle中增加:
dependencies {
implementation 'com.rmtheis:tess-two:9.0.0'
}
java文档:https://rmtheis.github.io/tess-two/javadoc/index.html
手动编译
https://github.com/rmtheis/tess-two/blob/master/BUILDING.md
如果你想修改tess-two代码,或者你想使用eyes-two模块,你可以在本地自己构建项目。
样本训练
https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract#run-tesseract-for-training
不同样本需要下载不同的训练包: https://github.com/tesseract-ocr/tesseract/wiki/Data-Files
3.02XX助手训练字库
准备工作
下载Tesseract-OCR官方命令行工具:https://sourceforge.net/projects/tesseract-ocr-alt/files/tesseract-ocr-setup-3.02.02.exe/download 下载完成后安装,安装完成后,打开cmd命令行,输入tesseract -v,如果安装成功,将会出现这样的提示界面:

下载jTessBoxEditor:https://osdn.net/projects/sfnet_vietocr/downloads/jTessBoxEditor/jTessBoxEditor-1.5.zip/ 下载完成后解压即可。
jTessBoxEditor需要依赖于JAVA虚拟机:1.8版本以上就行了,我用的是1.8.0_73
训练字库
准备字体图片tif文件
字体图片有两种主要获取方式,适用不同的字库制作需要:
方法一:获取游戏字体文件
一般游戏字体文件分两种,一种是直接加载ttf等标准字体文件,另一种是使用bmfont,也就是图片(一般是png)加额外的配置文件来加载字体。后者一般是用于少数的字体展示,例如数字0-9、字母a-Z。
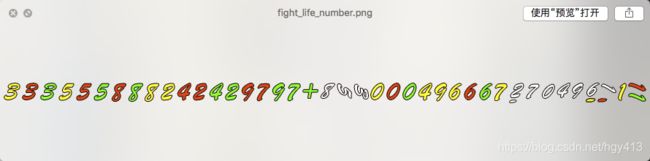
某游戏的bmfont字体文件,本质上就是一张png图片,加plist配置文件
不论是哪种,目标依然是要将这些字体文件转换成一张tif图片,如果是bmfont类型直接用转换工具例如PS导出tif格式即可(图片处理成白底黑字),这里讨论ttf格式的制作办法。
以部落X突为例,对apk包进行解压缩,可以在assets/font目录下发现一个熟悉的字体文件Supercell-Magic_5.ttf:

这个正是游戏里普遍使用的英文数字字体文件,打开并安装字体文件到PC,然后打开PS,随便新建一个合适大小的纯白底色图片,然后选择文本框将0-9数字输入(如果需要识别其他符号例如.、:,也可一并输入,英文字符同理):
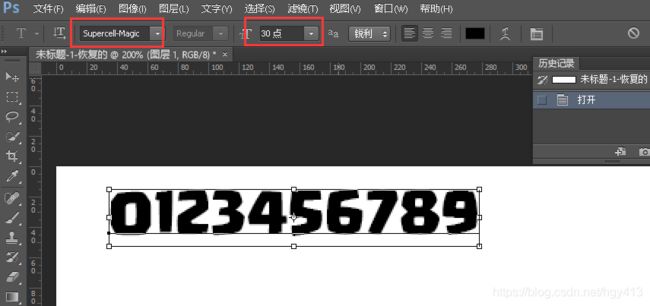
注意事项:安装字体后,选择对应的字体,底图需要纯白,字体颜色为纯黑。另外底图尺寸不要太小,字体大小适中即可
最后PS导出图片选择TIFF格式,即可得到游戏的字体图片tif文件。
网上也有一堆在线tif转tiff的转换工具。
方法二:游戏内截图
这个方法适用于无法获得游戏资源文件(加密或经过压缩处理等),或者每次展现的字体都有区别的情况(游戏内提示的验证码、手写字体等)。
基本原理是将出现的字符图片尽量可能多的截图并收集起来,最终通过处理拼成一张白底黑字的大图,例如某游戏的验证码:

通过对数字部分的截取和分割,由大量验证码数字组成新的tif图片:

一个重要原则是,尽量使用分辨率较高的tif图片制作字库,同时保证tif图片里字体展示清晰,这样生成的字库识别率会更高。
生成box文件
准备好字体图片tif文件后,可以开始正式制作我们识别用的字库了。第一步是先生成box文件,为了统一起见,将上面得到的tif文件,命名为num.font.exp0.tif,在cmd中切换到tif文件所在目录,然后输入以下命令行:
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
如果是训练中文,需要加入 -l chi_sim:
下载3.0.2的中文包:https://github.com/tesseract-ocr/tesseract/wiki/Data-Files#data-files-for-version-302
tesseract num.font.exp0.tif num.font.exp0 -l chi_sim batch.nochop makebox
详细介绍可以参考 https://code.google.com/p/tesseract-ocr/wiki/TrainingTesseract3#Putting_it_all_together

命令可能会产生一些warning输出,属于正常现象,可以忽略。
命令执行成功的话,同目录下会生成num.font.exp0.box文件,如上图, 否则,请确认命令是否正确输入。
使用jTessBoxEditor工具修正(可选)
box文件本质上就是一堆配置信息,记载了字符和字符在tif文件中的框选位置信息,如下描述了0-9数字的位置:

这一步是可选的,熟悉流程操作后可以直接用编辑器打开上一步产生的box文件直接修改,这里借助jTessBoxEditor工具确认。
直接双击运行jTessBoxEditor目录下的train.bat文件运行java程序,然后点击Box Editor窗口,点击Open加载tif文件。
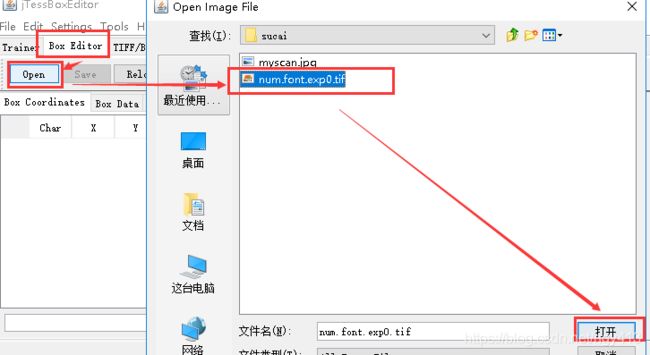
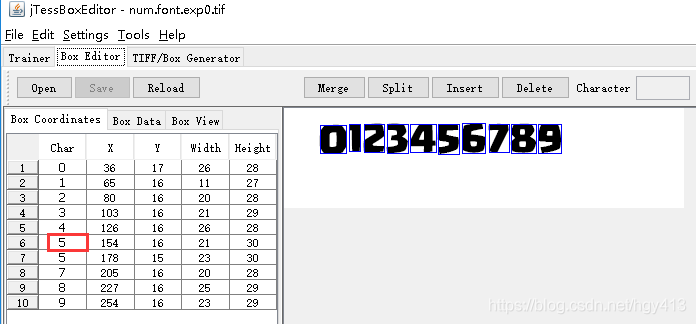
默认生成的box不一定可靠,这里数字6识别成5了,需要手动修改。
直接点击对应错误的位置,替换正确数字即可,确认框选位置没有错误,对应字符也正确的情况下,点击save按钮完成box修正:
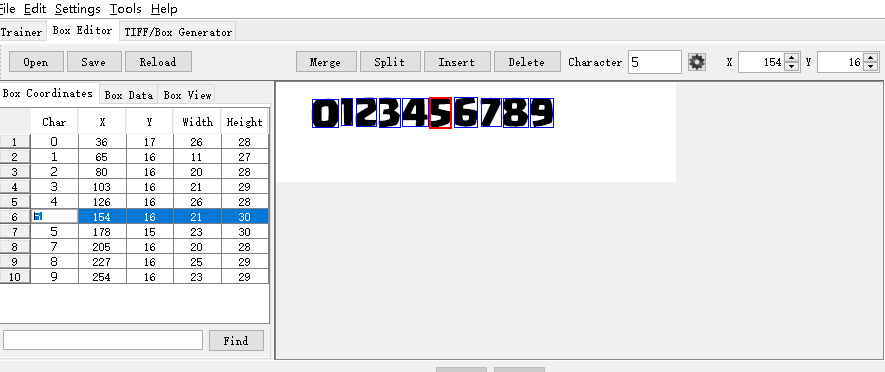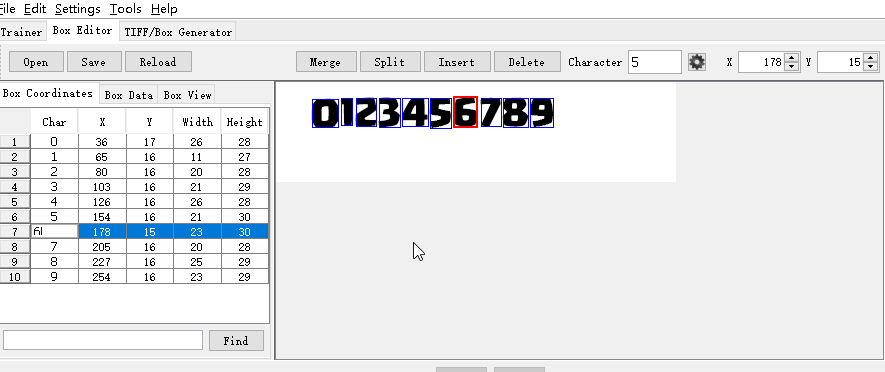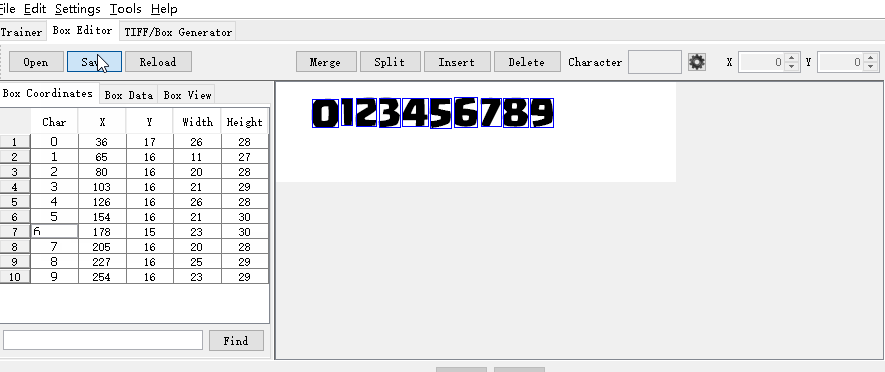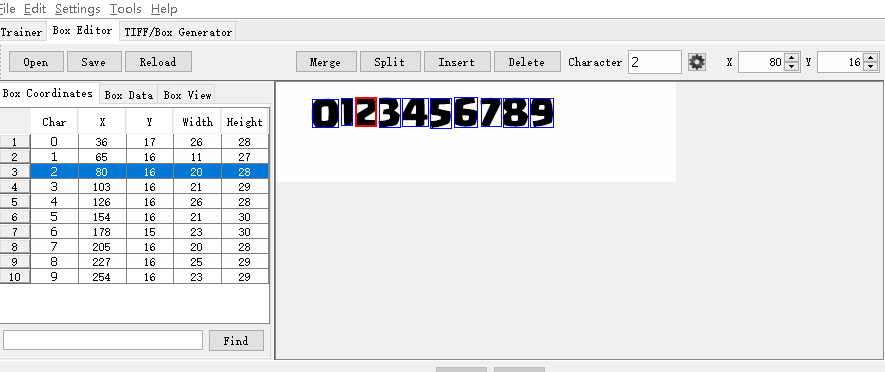
你也可以通过Insert按钮插入新的训练字符
打包字库文件
打包字库需要一个额外文件font_properties,这个文件指定字库的样式,每一行格式是:
其中italic、bold、fixed、serif和fraktur用1/0代表是/否,例如:timesitalic 1 0 0 1 0
在这里,不需要特殊设置,直接创建一个font_properties文件,填写font 0 0 0 0 0即可。
也可以执行echo命令生成font_properties:
echo font 0 0 0 0 0 >font_properties
这里要特别注意:
font 0 0 0 0 0中的font和num.font.中的font是完全相同的,如果你把内容改为font1 0 0 0 0 0,
那么在下面的生成训练文件时将报错:font_id_map_.SparseSize():Error:Assert failed:in file ..\..\classify\trainingsampleset.cpp, li ne 622 ```
生成训练文件
::生成训练文件
tesseract num.font.exp0.tif num.font.exp0 nobatch box.train
::生成unicharset字符集文件
unicharset_extractor num.font.exp0.box
::生成shape文件,经常会崩溃,XX助手是关掉的
::shapeclustering -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
::生成聚集字符特征文件
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
::生成字符正常化特征文件
cntraining num.font.exp0.tr
::更名
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename unicharset num.unicharset
rename shapetable num.shapetable
::合并训练文件
combine_tessdata num.
将上述文件保存成xunlian.bat直接运行即可得到num.traineddata训练文件:
H:\OpenSource_Git\ocr\sucai>xunlian.bat
H:\OpenSource_Git\ocr\sucai>tesseract num.font.exp0.tif num.font.exp0 nobatch box.train
Tesseract Open Source OCR Engine v3.02 with Leptonica
TIFFReadDirectory: Warning, TIFFstream: wrong data type 7 for "RichTIFFIPTC"; tag ignored.
TIFFReadDirectory: Warning, TIFFstream: wrong data type 7 for "RichTIFFIPTC"; tag ignored.
TIFFReadDirectory: Warning, TIFFstream: wrong data type 7 for "RichTIFFIPTC"; tag ignored.
APPLY_BOXES:
Boxes read from boxfile: 10
Found 10 good blobs.
TRAINING ... Font name = font
Generated training data for 1 words
H:\OpenSource_Git\ocr\sucai>unicharset_extractor num.font.exp0.box
Extracting unicharset from num.font.exp0.box
Wrote unicharset file ./unicharset.
H:\OpenSource_Git\ocr\sucai>mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
Warning: No shape table file present: shapetable
Reading num.font.exp0.tr ...
Flat shape table summary: Number of shapes = 10 max unichars = 1 number with multiple unichars = 0
Done!
H:\OpenSource_Git\ocr\sucai>cntraining num.font.exp0.tr
Reading num.font.exp0.tr ...
Clustering ...
Writing normproto ...
H:\OpenSource_Git\ocr\sucai>rename normproto num.normproto
A duplicate file name exists, or the file
cannot be found.
H:\OpenSource_Git\ocr\sucai>rename inttemp num.inttemp
A duplicate file name exists, or the file
cannot be found.
H:\OpenSource_Git\ocr\sucai>rename pffmtable num.pffmtable
A duplicate file name exists, or the file
cannot be found.
H:\OpenSource_Git\ocr\sucai>rename unicharset num.unicharset
A duplicate file name exists, or the file
cannot be found.
H:\OpenSource_Git\ocr\sucai>rename shapetable num.shapetable
A duplicate file name exists, or the file
cannot be found.
H:\OpenSource_Git\ocr\sucai>combine_tessdata num.
Combining tessdata files
TessdataManager combined tesseract data files.
Offset for type 0 is -1
Offset for type 1 is 140
Offset for type 2 is -1
Offset for type 3 is 798
Offset for type 4 is 135318
Offset for type 5 is 135401
Offset for type 6 is -1
Offset for type 7 is -1
Offset for type 8 is -1
Offset for type 9 is -1
Offset for type 10 is -1
Offset for type 11 is -1
Offset for type 12 is -1
Offset for type 13 is 136783
Offset for type 14 is -1
Offset for type 15 is -1
Offset for type 16 is -1
H:\OpenSource_Git\ocr\sucai>
如果遇到类似于Error opening unicharset file的错误,那是因为在bat中unicharset 没有被重命名为num.unicharset 。
执行结果中,1,3,4,5,13这几行必须不为-1,才代表命令执行成功,注意期间有没有错误输出(关键词error):

加载使用
num.traineddata文件最终要拷贝tesseract安装目录的tessdata目录下,才能被tesseract找到。

jTessBoxEditor是一个基本成型的三方样本训练工具,它的功能就是自动执行上述脚本命令,但是在实际使用中,还存在不够完善的地方,譬如不能加psm参数,生成shape时经常程序异常崩溃
3.02训练出来的训练集,可以在4.0上直接使用
参考:
Tesseract OCR集成Android Studio实现OCR识别
利用jTessBoxEditor工具进行Tesseract3.02.02样本训练,提高验证码识别率
如何使用Tesseract-OCR(v3.02.02)训练字库
android中tesseract-ocr的介绍