基础的强化学习(RL)算法及代码详细demo
文章目录
-
-
- 一、Sarsa (悬崖问题)
-
- 1.1 CliffWalking-v0环境介绍
- 1.2 Sarsa算法流程
- 1.3 具体代码
- 1.4 演示效果
- 二、Q-Learning (悬崖问题)
-
- 2.1 CliffWalking-v0环境介绍
- 2.2 Q-Learning算法流程
- 2.3 具体代码
- 2.4 演示效果
- 三、PG 策略梯度 (倒立摆)
-
- 3.1 CartPole-v1环境介绍
- 3.2 PG算法流程(REINFORCE)
- 3.3 具体代码
- 3.4 演示效果
- 四、PPO (飞船降落)
-
- 4.1 LunarLander-v2环境介绍
- 4.2 PPO-Clip算法流程
- 4.3 具体代码
- 4.4 演示效果
- 五、DQN (打砖块)
-
- 5.1 Breakout-v0环境介绍
- 5.2 DQN算法流程
- 5.3 具体代码
- 5.4 演示效果
- 六、DDPG (单摆)
-
- 6.1 Pendulum-v1环境介绍
- 6.2 DDPG算法流程
- 6.3 具体代码
- 6.4 演示效果
-
-
gym环境: https://www.gymlibrary.dev/
-
环境安装:
-
我的版本:
package module gym 0.24.0 ale-py 0.7.5 torch 1.11.0 torchvision 0.12.0 tensorboard 2.6.0 -
安装方法:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gym pip install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py pip install gym[atari] pip uninstall ale-py pip install ale-py安装box2d: 可能会遇到building wheel failed for box2d
在 https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载相应的 PyBox2D的whl文件 然后在命令行: pip install D:\FILES\PYTHON_PROJECTS\Box2D-2.3.10-cp37-cp37m-win_amd64.whl
-
一、Sarsa (悬崖问题)
1.1 CliffWalking-v0环境介绍
在一个4x12的网格中,智能体以网格的左下角位置为起点,以网格的下角位置为终点,目标是移动智能体到达终点位置,智能体每次可以在上、下、左、右这4个方向中移动一步,每移动一步会得到 -1 的奖励。

-
如果智能体“掉入悬崖” ,会立即回到起点位置,并得到-100单位的奖励
-
当智能体移动到终点时,该回合结束,该回合总奖励为各步奖励之和
import gym
env = gym.make("CliffWalking-v0")
observation = env.reset()
env.render()

- 从起点到终点最少需要13步,每步得到-1的reward。我们的目标也是要通过RL训练出一个模型,使得该模型能在测试中一个episode的reward能够接近于-13左右。
1.2 Sarsa算法流程
算法参数: 步长 α < 1 \alpha<1 α<1 极小值 ϵ \epsilon ϵ (两个超参数)
对于所有 Q ( s , a ) Q(s,a) Q(s,a)随机初始化,终点处$ Q(s_{end},a) = 0$
for (each trajectory):
初始化 S S S
a t = ϵ − g r e e d y ( s t ) a_t = \epsilon -greedy \quad(s_t) at=ϵ−greedy(st)
for (each step):
执行 a t a_t at,得到 ( r t + 1 , s t + 1 ) (r_{t+1},s_{t+1}) (rt+1,st+1)
a t + 1 = ϵ − g r e e d y ( s t + 1 ) a_{t+1} = \epsilon -greedy \quad(s_{t+1}) at+1=ϵ−greedy(st+1)
Q ( s t , a t ) = Q ( s t , a t ) + α [ r t + 1 + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ] Q(s_{t},a_{t})=Q(s_{t},a_{t})+\alpha[r_{t+1}+\gamma Q(s_{t+1},a_{t+1})-Q(s_{t},a_{t})] Q(st,at)=Q(st,at)+α[rt+1+γQ(st+1,at+1)−Q(st,at)]
s t = s t + 1 , a t = a t + 1 s_t = s_{t+1},a_t = a_{t+1} st=st+1,at=at+1
1.3 具体代码
import numpy as np
import gym
import time
class SarsaAgent:
def __init__(self, obs_n, act_n, learning_rate=0.01, gamma=0.9, e_greed=0.1):
self.act_n = act_n
self.lr = learning_rate
self.gamma = gamma
self.epsilon = e_greed
self.Q = np.zeros((obs_n, act_n))
# e_greed:根据s_t,选择a_t
def sample(self,obs):
if np.random.uniform(0,1) < (1.0 - self.epsilon):
action = self.predict(obs)
else:
action = np.random.choice(self.act_n) # 0,1,2,3
return action
# a_t = argmax Q(s)
def predict(self, obs):
Q_list = self.Q[obs, :] #当前s下所有a对应的Q值
maxQ = np.max(Q_list)
action_list = np.where(Q_list == maxQ)[0] # action_list=所有=Qmax的索引
action = np.random.choice(action_list)
return action
def learn(self, obs, action, reward, next_obs, next_action, done): # (S,A,R,S,A)
'''
done: episode是否结束
'''
predict_Q = self.Q[obs,action]
if done:
target_Q = reward
else:
target_Q = reward + self.gamma * self.Q[next_obs,next_action]
# 更新Q表格
self.Q[obs,action] += self.lr * (target_Q - predict_Q)
def save(self):
npy_file = './q-table.npy'
np.save(npy_file, self.Q)
print(npy_file + ' saved.')
def load(self, npy_file='./q_table.npy'):
self.Q = np.load(npy_file)
print(npy_file + ' loaded.')
def run_episode(env, agent, render=False):
total_steps = 0 # 记录当前episode走了多少step
total_reward = 0
obs = env.reset()
action = agent.sample(obs)
while True:
next_obs, reward, done, _ = env.step(action)
next_action = agent.sample(next_obs)
agent.learn(obs, action, reward, next_obs, next_action, done)
action = next_action
obs = next_obs
total_reward += reward
total_steps += 1
if render:
env.render()
time.sleep(0.)
if done:
break
return total_reward, total_steps
def test_episode(env, agent):
total_steps = 0 # 记录当前episode走了多少step
total_reward = 0
obs = env.reset()
while True:
action = agent.predict(obs)
next_obs, reward, done, _ = env.step(action)
total_reward += reward
total_steps += 1
obs = next_obs
time.sleep(0.5)
env.render()
if done:
break
return total_reward, total_steps
def main():
env = gym.make("CliffWalking-v0")
agent = SarsaAgent(obs_n=env.observation_space.n,
act_n=env.action_space.n,
learning_rate=0.025, gamma=0.9, e_greed=0.1)
for episode in range(1000):
total_reward, total_steps = run_episode(env, agent, False)
print('Episode %s: total_steps = %s , total_reward = %.1f' % (episode, total_steps, total_reward))
test_episode(env, agent)
main()
1.4 演示效果
训练了1000个episode, r e w a r d = − 23 reward=-23 reward=−23

二、Q-Learning (悬崖问题)
2.1 CliffWalking-v0环境介绍
(介绍见1.1)
2.2 Q-Learning算法流程
(Q-Learning其实真正执行的策略和Sarsa是一样的,只不过学习的策略是保守的最优策略)
算法参数: 步长 α < 1 \alpha<1 α<1 极小值 ϵ \epsilon ϵ (两个超参数)
对于所有 Q ( s , a ) Q(s,a) Q(s,a)随机初始化,终点处 Q ( s e n d , a ) = 0 Q(s_{end},a) = 0 Q(send,a)=0
for (each trajectory):初始化 S S S
for (each step):
a t = ϵ − g r e e d y ( s t ) a_{t} = \epsilon -greedy \quad(s_{t}) at=ϵ−greedy(st)(行为策略)
执行 a t a_t at,得到 ( r t + 1 , s t + 1 ) (r_{t+1},s_{t+1}) (rt+1,st+1)
Q ( s t , a t ) = Q ( s t , a t ) + α [ r t + 1 + γ m a x a Q ( s t + 1 , a ) − Q ( s t , a t ) ] Q(s_{t},a_{t})=Q(s_{t},a_{t})+\alpha[r_{t+1}+\gamma \underset{a}{max}Q(s_{t+1},a)-Q(s_{t},a_{t})] Q(st,at)=Q(st,at)+α[rt+1+γamaxQ(st+1,a)−Q(st,at)]
s t = s t + 1 s_t = s_{t+1} st=st+1
2.3 具体代码
import numpy as np
import gym
import time
class QLearningAgent:
def __init__(self, obs_n, act_n, learning_rate=1e-2, gamma=0.9, e_greed=0.1):
self.act_n = act_n # 动作维度,有几个动作可选
self.lr = learning_rate # 学习率
self.gamma = gamma # reward的衰减率
self.epsilon = e_greed # 按一定概率随机选动作
self.Q = np.zeros((obs_n, act_n))
def sample(self, obs):
if np.random.uniform(0, 1) < (1.0 - self.epsilon): # 根据table的Q值选动作
action = self.predict(obs)
else:
action = np.random.choice(self.act_n) # 有一定概率随机探索选取一个动作
return action
# 根据输入观察值,预测输出的动作值
def predict(self, obs):
Q_list = self.Q[obs, :]
maxQ = np.max(Q_list)
action_list = np.where(Q_list == maxQ)[0] # maxQ可能对应多个action
action = np.random.choice(action_list)
return action
def learn(self, obs, action, reward, next_obs, done): #(S,A,R,S)
predict_Q = self.Q[obs, action]
if done:
target_Q = reward
else:
target_Q = reward + self.gamma * np.max(self.Q[next_obs,:])
self.Q[obs, action] += self.lr * (target_Q - predict_Q)
def save(self):
npy_file = './q-table.npy'
np.save(npy_file, self.Q)
print(npy_file + ' saved.')
def load(self, npy_file='./q_table.npy'):
self.Q = np.load(npy_file)
print(npy_file + ' loaded.')
def run_episode(env, agent, render=False):
# 其实真正执行的策略和Sarsa是一样的,只不过学习的策略是保守的最优策略
total_steps = 0
total_reward = 0
obs = env.reset()
while True:
action = agent.sample(obs)
next_obs, reward, done, _ = env.step(action)
agent.learn(obs, action, reward, next_obs, done)
obs = next_obs
total_reward += reward
total_steps += 1
if render:
env.render()
if done:
break
return total_reward, total_steps
def test_episode(env, agent):
total_reward = 0
obs = env.reset()
while True:
action = agent.predict(obs) # greedy
next_obs, reward, done, _ = env.step(action)
total_reward += reward
obs = next_obs
time.sleep(0.5)
env.render()
if done:
break
return total_reward
def main():
env = gym.make("CliffWalking-v0") # 0 up, 1 right, 2 down, 3 left
# 创建一个agent实例,输入超参数
agent = QLearningAgent(
obs_n=env.observation_space.n,
act_n=env.action_space.n,
learning_rate=0.1,
gamma=0.9,
e_greed=0.1)
# 训练500个episode,打印每个episode的分数
for episode in range(500):
ep_reward, ep_steps = run_episode(env, agent, False)
print('Episode %s: steps = %s , reward = %.1f' % (episode, ep_steps, ep_reward))
# 全部训练结束,查看算法效果
test_reward = test_episode(env, agent)
print('test reward = %.1f' % (test_reward))
main()
2.4 演示效果
三、PG 策略梯度 (倒立摆)
3.1 CartPole-v1环境介绍
(Cart Pole - Gym Documentation (gymlibrary.dev))
一根杆通过一个未驱动的关节连接到一辆小车上,小车沿着一条无摩擦的轨道移动。将钟摆垂直放置在推车上,目标是通过在推车上施加左右方向的力来平衡杆。
倒立摆:


-
obs: (1,4)
Num Observation Min Max 0 Cart Position0 -4.8 4.8 1 Cart Velocity -Inf Inf 2 Pole Angle -0.418 rad 0.418 rad 3 Pole Angular Velocity -Inf Inf -
action: (1,2)
动作空间是离散的:
Num Action 0 向左推车 1 向右推车 -
reward
每活着经过一个时间步,奖励 + 1。
-
终止条件:
- ① Pole Angle > 12°
- ② |水平位置|>2.4’
- ③ 超过500步
3.2 PG算法流程(REINFORCE)
输入: 可微调的策略参数 π ( a ∣ s , θ ) \pi(a|s,\theta) π(a∣s,θ)
算法参数: 步长大小 α > 0 \alpha>0 α>0
初始化的策略参数 θ \theta θ
循环(each trajectory):
根据 π ( ⋅ ∣ ⋅ , θ ) \pi(\cdot|\cdot,\theta) π(⋅∣⋅,θ),生成 S 0 , A 0 , R 1 , . . . S T − 1 , A T − 1 , R T S_0,A_0,R_1,...S_{T-1},A_{T-1},R_{T} S0,A0,R1,...ST−1,AT−1,RT
对一个回合的每一步进行循环, t = 0 , 1 , . . . , T − 1 t=0,1,...,T-1 t=0,1,...,T−1
G = ∑ k = t + 1 T γ k − t − 1 R k G = \sum_{k=t+1}^{T} \gamma^{k-t-1} R_k G=∑k=t+1Tγk−t−1Rk
θ = θ + α γ t G ▽ l n [ π ( a t ∣ s t , θ ) ] \theta = \theta + \alpha \gamma^t G \bigtriangledown ln[\pi(a_t|s_t,\theta)] θ=θ+αγtG▽ln[π(at∣st,θ)]
3.3 具体代码
import torch
import gym
import numpy as np
import torch.nn as nn
from torch.nn import Linear
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
import time
lr = 0.002
gamma = 0.8
class PGPolicy(nn.Module):
def __init__(self, input_size=4, hidden_size=128, output_size=2):
super(PGPolicy, self).__init__()
self.fc1 = Linear(input_size, hidden_size)
self.fc2 = Linear(hidden_size, output_size)
self.dropout = nn.Dropout(p=0.6)
self.saved_log_probs = []# 记录每一步的动作概率
self.rewards = []#记录每一步的r
def forward(self, x):
x = self.fc1(x)
x = self.dropout(x)
x = F.relu(x)
x = self.fc2(x)
out = F.softmax(x, dim=1)
return out
def choose_action(state, policy):
state = torch.from_numpy(state).float().unsqueeze(0) # 在索引0对应位置增加一个维度
probs = policy(state)
m = Categorical(probs) #创建以参数probs为标准的类别分布,之后的m.sampe就会按此概率选择动作
action = m.sample()
policy.saved_log_probs.append(m.log_prob(action))
return action.item()#返回的就是int
def learn(policy, optimizer):
R = 0
policy_loss = []
returns = []
for r in policy.rewards[::-1]:
R = r + gamma*R
returns.insert(0,R)#从头部插入,即反着插入
returns = torch.tensor(returns)
# 归一化(均值方差),eps是一个非常小的数,避免除数为0
eps = np.finfo(np.float64).eps.item()
returns = (returns - returns.mean()) / (returns.std() + eps)
for log_prob, R in zip(policy.saved_log_probs, returns):
policy_loss.append(-log_prob*R)
optimizer.zero_grad()
policy_loss = torch.cat(policy_loss).sum()
policy_loss.backward()
optimizer.step()
del policy.rewards[:] # 清空数据
del policy.saved_log_probs[:]
def train(episode_num):
env = gym.make('CartPole-v1')
env.seed(1)
torch.manual_seed(1)
policy = PGPolicy()
# policy.load_state_dict(torch.load('save_model.pt')) # 模型导入
optimizer = optim.Adam(policy.parameters(), lr)
average_r = 0
for i in range(1, episode_num+1): #采这么多轨迹
obs = env.reset()
ep_r = 0
for t in range(1, 10000):
action = choose_action(obs, policy)
obs, reward, done, _ = env.step(action)
policy.rewards.append(reward)
ep_r += reward
if done:
break
average_r = 0.05 * ep_r + (1-0.05) * average_r
learn(policy, optimizer)
if i % 10 == 0:
print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format(i, ep_r, average_r))
torch.save(policy.state_dict(), 'PGPolicy.pt')
def test():
env = gym.make('CartPole-v1')
env.seed(1)
torch.manual_seed(1)
policy = PGPolicy()
policy.load_state_dict(torch.load('PGPolicy.pt')) # 模型导入
average_r = 0
with torch.no_grad():
obs = env.reset()
ep_r = 0
for t in range(1, 10000):
action = choose_action(obs, policy)
obs, reward, done, _ = env.step(action)
policy.rewards.append(reward)
env.render()
time.sleep(0.1)
ep_r += reward
if done:
break
train(1000)
# test()
3.4 演示效果
训练过程:


四、PPO (飞船降落)
4.1 LunarLander-v2环境介绍
(该环境需要安装box2d)
https://www.gymlibrary.dev/environments/box2d/lunar_lander/?highlight=lunarlander

-
observation (1,8)
Num Observation 0 x 1 y 2 V x V_x Vx 3 V y V_y Vy 4 a n g l e angle angle 5 a n g u l a r v e l o c i t y angular \quad velocity angularvelocity 6 左腿是否触地(bool) 7 右腿是否触地(bool) -
action (1,4)
Num Action 0 啥也不干 1 左侧点火 2 下面(主发动机)点火 3 右侧点火 -
reward
从屏幕顶部移动到着陆台的奖励约为100-140分。如果着陆器没降落到陆台,它将失去奖励。如果着陆器坠毁,它将获得额外的-100分。如果它成功降落,它将获得额外的+100分。接地的每个支腿为+10点。每架主机点火-0.3分。侧面发动机每帧点火-0.03分。解决的是200分。
-
终止条件
- 飞船与月球接触
- 飞船|x|>1
4.2 PPO-Clip算法流程
初始化策略函数的参数 θ 0 \theta_0 θ0, 初始化价值函数的参数 ϕ 0 \phi_0 ϕ0
for k = 0,1,2,…
基于 π ( θ k ) \pi(\theta_k) π(θk)来采集轨迹组 D k = τ k D_k={\tau_k} Dk=τk
计算 R t R_t Rt
计算 A t A_t At
更新策略: θ k + 1 = a r g m a x θ 1 ∣ D k ∣ T ∑ τ ∑ t m i n ( π θ ( a t ∣ s t ) π θ ′ ( a t ∣ s t ) A ( s t , a t ) , g ( ϵ , A ( s t , a t ) ) ) \theta_{k+1}=\underset{\theta}{argmax}\frac{1}{|D_k|T}\underset{\tau }{\sum}\underset{t }{\sum} min(\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta^{'}}(a_t|s_t)}A(s_t,a_t),\quad g(\epsilon,A(s_t,a_t))) θk+1=θargmax∣Dk∣T1τ∑t∑min(πθ′(at∣st)πθ(at∣st)A(st,at),g(ϵ,A(st,at)))
更新价值函数: ϕ k + 1 = a r g m i n ϕ 1 ∣ D k ∣ T ∑ τ ∑ t ( V ( s t ) − R ) 2 \phi_{k+1}=\underset{\phi}{argmin}\frac{1}{|D_k|T}\underset{\tau }{\sum}\underset{t }{\sum} (V(s_t)-R)^2 ϕk+1=ϕargmin∣Dk∣T1τ∑t∑(V(st)−R)2
4.3 具体代码
import torch
import torch.nn as nn
from torch.distributions import Categorical
import gym
device = 'cpu'
class Memory:
def __init__(self):
self.actions = []
self.states = []
self.logprobs = []
self.rewards = []
self.is_terminals = []
def clear_memory(self):
del self.actions[:]
del self.states[:]
del self.logprobs[:]
del self.rewards[:]
del self.is_terminals[:]
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim, n_latent_var):
super(ActorCritic, self).__init__()
# actor
self.action_layer = nn.Sequential(
nn.Linear(state_dim, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, action_dim),
nn.Softmax(dim=-1)
)
# critic
self.value_layer = nn.Sequential(
nn.Linear(state_dim, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, 1)
)
def forward(self):
# 如果这个方法没有被子类重写,但是调用了,就会报错
raise NotImplementedError
def act(self, state, memory):
state = torch.from_numpy(state).float().to(device)
action_probs = self.action_layer(state)
dist = Categorical(action_probs)
action = dist.sample()
memory.states.append(state)
memory.actions.append(action)
memory.logprobs.append(dist.log_prob(action))
return action.item()
def evaluate(self, state, action):
action_probs = self.action_layer(state)
dist = Categorical(action_probs)
action_logprobs = dist.log_prob(action)
dist_entropy = dist.entropy()
state_value = self.value_layer(state)
return action_logprobs, torch.squeeze(state_value), dist_entropy
class PPO:
def __init__(self, state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip):
self.lr = lr
self.betas = betas
self.gamma = gamma
self.eps_clip = eps_clip
self.K_epochs = K_epochs
self.policy = ActorCritic(state_dim, action_dim, n_latent_var).to(device)
self.optimizer = torch.optim.Adam(self.policy.parameters(), lr=lr, betas=betas)
self.policy_old = ActorCritic(state_dim, action_dim, n_latent_var).to(device)
self.policy_old.load_state_dict(self.policy.state_dict())
self.MseLoss = nn.MSELoss()
def update(self, memory):
# Monte Carlo estimate of state rewards:
rewards = []
discounted_reward = 0
for reward, is_terminal in zip(reversed(memory.rewards), reversed(memory.is_terminals)):
if is_terminal:
discounted_reward = 0
discounted_reward = reward + (self.gamma * discounted_reward)
rewards.insert(0, discounted_reward)
# Normalizing the rewards:
rewards = torch.tensor(rewards).to(device).to(torch.float32)
rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-5)
# convert list to tensor
old_states = torch.stack(memory.states).to(device).detach().to(torch.float32)
old_actions = torch.stack(memory.actions).to(device).detach().to(torch.float32)
old_logprobs = torch.stack(memory.logprobs).to(device).detach().to(torch.float32)
# Optimize policy for K epochs:
for _ in range(self.K_epochs):
# Evaluating old actions and values :
logprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)
# Finding the ratio (pi_theta / pi_theta__old):
ratios = torch.exp(logprobs - old_logprobs.detach())
# Finding Surrogate Loss:
advantages = rewards - state_values.detach()
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages
loss = -torch.min(surr1, surr2) + 0.5*self.MseLoss(state_values, rewards) - 0.01*dist_entropy
loss =loss.to(torch.float32)
# take gradient step
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
# Copy new weights into old policy:
self.policy_old.load_state_dict(self.policy.state_dict())
def main():
############## Hyperparameters ##############
env_name = 'LunarLander-v2'# "LunarLander-v2"
# creating environment
env = gym.make(env_name)
env = env.unwrapped
state_dim = env.observation_space.shape[0]
action_dim = 4
render = False
solved_reward = 200 # stop training if avg_reward > solved_reward
log_interval = 20 # print avg reward in the interval
max_episodes = 5000 # max training episodes
max_timesteps = 1000 # max timesteps in one episode
n_latent_var = 64 # number of variables in hidden layer
update_timestep = 2000 # update policy every n timesteps
lr = 0.002
betas = (0.9, 0.999)
gamma = 0.99 # discount factor
K_epochs = 4 # update policy using 1 trajectory for K epochs
eps_clip = 0.2 # clip parameter for PPO
random_seed = 123
#############################################
if random_seed:
torch.manual_seed(random_seed)
env.seed(random_seed)
memory = Memory()
ppo = PPO(state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip)
print(lr,betas)
# logging variables
running_reward = 0
avg_length = 0
timestep = 0
# training loop
for i_episode in range(1, max_episodes+1):
state = env.reset()
for t in range(max_timesteps):
timestep += 1
# Running policy_old:
action = ppo.policy_old.act(state, memory)
state, reward, done, _ = env.step(action)
# Saving reward and is_terminal:
memory.rewards.append(reward)
memory.is_terminals.append(done)
# update if its time
if timestep % update_timestep == 0:
ppo.update(memory)
memory.clear_memory()
timestep = 0
running_reward += reward
if render:
env.render()
if done:
break
avg_length += t
# stop training if avg_reward > solved_reward
if running_reward > (log_interval*solved_reward):
print("########## Solved! ##########")
torch.save(ppo.policy.state_dict(), './PPO_{}_{}.pth'.format(env_name,lr))
break
# logging
if i_episode % log_interval == 0:
avg_length = int(avg_length/log_interval)
running_reward = int((running_reward/log_interval))
print('Episode {} \t avg length: {} \t reward: {}'.format(i_episode, avg_length, running_reward))
running_reward = 0
avg_length = 0
if i_episode % 2000 == 0:
torch.save(ppo.policy.state_dict(), './PPO_{}_{}.pth'.format(env_name,lr))
def test():
############## Hyperparameters ##############
env_name = "LunarLander-v2"
# creating environment
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = 4
render = False
max_timesteps = 500
n_latent_var = 64 # number of variables in hidden layer
lr = 0.0002
betas = (0.9, 0.999)
gamma = 0.99 # discount factor
K_epochs = 4 # update policy for K epochs
eps_clip = 0.2 # clip parameter for PPO
#############################################
n_episodes = 3
max_timesteps = 300
render = True
save_gif = False
filename = "PPO_{}_0.002.pth".format(env_name)
directory = "./"
memory = Memory()
ppo = PPO(state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip)
ppo.policy_old.load_state_dict(torch.load(directory+filename))
for ep in range(1, n_episodes+1):
ep_reward = 0
state = env.reset()
for t in range(max_timesteps):
action = ppo.policy_old.act(state, memory)
state, reward, done, _ = env.step(action)
ep_reward += reward
if render:
env.render()
if done:
break
print('Episode: {}\tReward: {}'.format(ep, int(ep_reward)))
ep_reward = 0
env.close()
if __name__ == '__main__':
main()
# test()
4.4 演示效果


五、DQN (打砖块)
5.1 Breakout-v0环境介绍
Breakout - Gym Documentation (gymlibrary.dev)
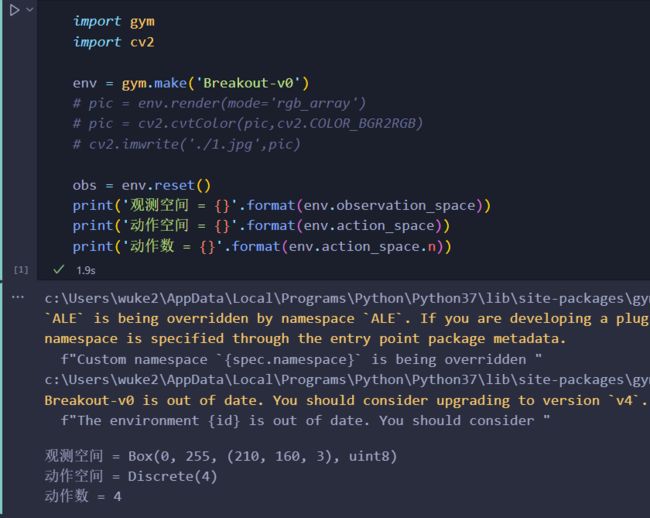
- observation (210,160,3)

-
action (1,4)
Num Action 0 NOOP 1 FIRE 2 RIGHT 3 LEFT -
reward

5.2 DQN算法流程
(带有经验回放池的DQN)
初始化经验回放池 D D D(容量为 N N N)
随机初始化 动作-价值 函数 Q Q Q
for (each episode)
初始化序列 s 1 = [ x 1 ] s_1=[x_1] s1=[x1],预处理 ϕ 1 = ϕ ( s 1 ) \phi_1=\phi(s_1) ϕ1=ϕ(s1)
for (each step)
a t = m a x a Q ∗ ( ϕ ( s t ) , a : θ ) a_t=\underset{a}{max}Q^*(\phi(s_t),a:\theta) at=amaxQ∗(ϕ(st),a:θ) (概率=1- ϵ \epsilon ϵ)
执行 a t a_t at,得到 r t r_t rt和图片 x t + 1 x_{t+1} xt+1
s t + 1 = s t , ϕ t + 1 = ϕ ( s t + 1 ) s_{t+1}=s_t,\phi_{t+1}=\phi(s_{t+1}) st+1=st,ϕt+1=ϕ(st+1)
将 ( ϕ t , a t , r t , ϕ t + 1 ) (\phi_t,a_t,r_t,\phi_{t+1}) (ϕt,at,rt,ϕt+1)存储进 D D D
在 D D D中采样
y i = { r j ( t e r m i n a l ϕ j + 1 ) r j + γ m a x Q ( ϕ j + 1 , a ′ ; θ ) ( n o n − t e r m i n a l ϕ j + 1 ) y_i = \left\{\begin{matrix} r_j & (terminal\quad \phi_{j+1})\\ r_j +\gamma max Q( \phi_{j+1},a^{'}; \theta) & (non-terminal\quad \phi_{j+1}) \end{matrix}\right. yi={rjrj+γmaxQ(ϕj+1,a′;θ)(terminalϕj+1)(non−terminalϕj+1)
根据 ( y i − Q ( ϕ j , a j : θ ) ) 2 (y_i-Q(\phi_j,a_j:\theta))^2 (yi−Q(ϕj,aj:θ))2进行梯度下降
5.3 具体代码
import gym
import cv2
import torch
import numpy as np
import torch.nn as nn
import pandas as pd
from torch.nn import Linear, Conv2d, ReLU
import PIL.Image as Image
device=torch.device("cuda:0" if torch.cuda.is_available() else"cpu")
# 经验池
class DQBReplayer:
def __init__(self, capacity):
# (S,A,R,S)
self.memory = pd.DataFrame(index=range(capacity), columns=['observation', 'action', 'reward', 'next_observation', 'done'])
self.i = 0
self.count = 0
self.capacity = capacity
def store(self,*args):
self.memory.loc[self.i] = args
self.i = (self.i + 1)%self.capacity
self.count = min(self.count+1, self.capacity)
def sample(self, size):
indics = np.random.choice(self.count, size=size)
return (np.stack(self.memory.loc[indics,field]) for field in self.memory.columns)
# Q-Network
class DQN_net(nn.Module):
def __init__(self):
super(DQN_net, self).__init__()
self.conv = nn.Sequential(
Conv2d(in_channels=4, out_channels=32, kernel_size=8, stride=4),
ReLU(),
Conv2d(in_channels=32, out_channels=64, kernel_size=4, stride=2),
ReLU(),
Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1),
ReLU()
)
self.classifier = nn.Sequential(
Linear(3136, 512),
ReLU(),
Linear(512, 4)
)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0),-1)
output = self.classifier(x)
return output
class DQN(nn.Module):
def __init__(self, input_shape, env):
super(DQN, self).__init__()
self.replayer_start_size = 100000
self.upon_times = 20
self.replayer = DQBReplayer(capacity=self.replayer_start_size)
self.action_n = env.action_space.n
self.image_stack = input_shape[2]
self.gamma = 0.99
self.image_shape = (input_shape[0], input_shape[1])
self.e_net = DQN_net()
self.t_net = DQN_net()
self.learn_step = 0
self.max_learn_step = 650000
self.epsilon = 1.
self.start_learn = False
def get_next_state(self,state=None,observation=None):
img=Image.fromarray(observation,"RGB")
img=img.resize(self.image_shape).convert('L')
img=np.asarray(img.getdata(),dtype=np.uint8,).reshape(img.size[1],img.size[0])
if state is None:
next_state = np.array([img,]*self.image_stack)
else:
next_state = np.append(state[1:],[img,],axis=0)
return next_state
def decide(self,state,step):
if self.start_learn == False: #前50000步随机选择
action = np.random.randint(0, 4)
return action
else:
self.epsilon -= 0.0000053
if step < 30:
#每局前三十步随机选择,中间30万,
#以一定概率(1-epsilon)通过神经网络选择,
# 最后30万次以0.99概率通过神经网络选择
action = np.random.randint(0, 4)
elif np.random.random() < max(self.epsilon, 0.0005):
action = np.random.randint(0,4)
else:
state = state/128 - 1
y = torch.Tensor(state).float().unsqueeze(0)
y = y.to(device)
x = self.e_net(y).detach()
if self.learn_step%2000==0:
print("q value{}".format(x))
action = torch.argmax(x).data.item()
return action
def main():
sum_reward = 0
store_count = 0
env = gym.make('Breakout-v0')
net = DQN([84,84,4], env).cuda()
Load_Net = 0
if Load_Net==1:
load_net_path = './epsiode_2575_reward_10.0.pkl'
print("Load old net and the path is:",load_net_path)
net.e_net = torch.load(load_net_path)
net.t_net = torch.load(load_net_path)
max_score = 0
mse = nn.MSELoss()
mse = mse.cuda()
opt = torch.optim.RMSprop(net.e_net.parameters(), lr=0.0015)
for i in range(20000):
lives = 5
obs = env.reset()
state = net.get_next_state(None,obs)
epoch_reward = 0
if i%100==0:
print("{} times_game".format(i),end=':')
print('epoch_reward:{}'.format(epoch_reward))
for step in range(500000):
action = net.decide(state,step=step)
obs, reward, done, _ = env.step(action)
next_state = net.get_next_state(state, obs)
epoch_reward += reward
net.replayer.store(state, action, reward, next_state, done)
net.learn_step += 1
if net.learn_step >= net.replayer_start_size // 2 and net.learn_step % 4 == 0:
if net.start_learn == False:
net.start_learn = True
print('Start Learn!')
sample_n = 32
states, actions, rewards, next_states, dones = net.replayer.sample(sample_n)
states, next_states = states / 128 -1, next_states / 128 -1
rewards = torch.Tensor(np.clip(rewards,-1,1)).unsqueeze(1).cuda()
states, next_states = torch.Tensor(states).cuda(), torch.Tensor(next_states).cuda()
actions = torch.Tensor(actions).long().unsqueeze(1).cuda()
dones = torch.Tensor(dones).unsqueeze(1).cuda()
q = net.e_net(states).gather(1, actions)
q_next = net.t_net(next_states).detach().max(1)[0].reshape(sample_n, 1)
tq = rewards + net.gamma * (1-done) * q_next
loss = mse(q, tq)
opt.zero_grad()
loss.backward()
opt.step()
if net.learn_step % (net.upon_times * 5) == 0:
net.t_net.load_state_dict(net.e_net.state_dict())
if net.learn_step % 100 == 0:
loss_record = loss.item()
a_r = torch.mean(rewards, 0).item()
state = next_state
if done:
save_net_path = './'
sum_reward+=epoch_reward
if epoch_reward > max_score:
name = "epsiode_" + str(net.learn_step) + "_reward_" + str(epoch_reward) + ".pkl"
torch.save(net.e_net, save_net_path+name)
max_score = epoch_reward
elif i % 1000 == 0:
name ="No."+str(i)+".pkl"
torch.save(net.e_net, save_net_path + name)
if i%10==0:
sum_reward=0
break
import cv2
def PictureArray2Video(pic_list, path='./test.mp4'):
h,w,_ = pic_list[0].shape[0], pic_list[0].shape[1], pic_list[0].shape[2]
print(h,w)
writer = cv2.VideoWriter(path, cv2.VideoWriter_fourcc('m', 'p', '4', 'v'), 10, (w, h), True)
total_frame = len(pic_list)
for i in range(total_frame):
writer.write(pic_list[i])
writer.release()
def test():
pics = []
sum_reward = 0
store_count = 0
env = gym.make('Breakout-v0')
net = DQN([84,84,4], env).cuda()
Load_Net = 1
if Load_Net==1:
load_net_path = './epsiode_10219_reward_9.0.pkl'
print("Load old net and the path is:",load_net_path)
net.e_net = torch.load(load_net_path)
net.t_net = torch.load(load_net_path)
max_score = 0
mse = nn.MSELoss()
mse = mse.cuda()
obs = env.reset()
state = net.get_next_state(None,obs)
epoch_reward = 0
for step in range(500000):
action = net.decide(state,step=step)
obs, reward, done, _ = env.step(action)
pic = env.render(mode='rgb_array')
pic = cv2.cvtColor(pic,cv2.COLOR_BGR2RGB)
next_state = net.get_next_state(state, obs)
pics.append(pic)
if done:
PictureArray2Video(pics)
break
5.4 演示效果
这个我感觉要训练好久,我训练了两个小时,reward=11,然后停下了。

六、DDPG (单摆)
6.1 Pendulum-v1环境介绍
https://www.gymlibrary.dev/environments/classic_control/pendulum/?highlight=pendulum+v1
-
observation (1,3)
Num Observation Min Max 0 cos(theta) -1 1 1 sin(angle) -1 1 2 角速度 -8.0 8.0 -
action (1,)
力矩,大小在(-2,2)之前的值
-
奖励
r = − ( θ 2 + 0.1 × ω 2 + 0.001 × 力 矩 2 ) r = -(\theta^2 + 0.1×\omega^2 + 0.001×力矩^2) r=−(θ2+0.1×ω2+0.001×力矩2)
6.2 DDPG算法流程
随机初始化 评论员 Q ( s , a ∣ θ Q ) Q(s,a|\theta^Q) Q(s,a∣θQ)和 演员 μ ( s ∣ θ μ ) \mu(s|\theta^\mu) μ(s∣θμ)
初始化目标策略价值网络 Q ′ Q{'} Q′和 θ ′ \theta^{'} θ′,
θ Q ′ = θ Q , θ μ ′ = θ μ \theta^{Q^{'}}=\theta^Q,\theta^{\mu^{'}}=\theta^\mu θQ′=θQ,θμ′=θμ
初始化经验回放池Rfor (each episode)
for (each step)
a t = μ ( s t ∣ θ μ ) a_t=\mu(s_t|\theta^{\mu}) at=μ(st∣θμ)
s t + 1 , r t , d o n e , = e n v . s t e p ( a t ) s_{t+1},r_t,done,_ = env.step(a_t) st+1,rt,done,=env.step(at)
将 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)存储进R
从R中采样N条轨迹 ( s i , a i , r i , s i + 1 ) (s_i,a_i,r_i,s_{i+1}) (si,ai,ri,si+1)
y i = r i + γ Q ′ ( s i + 1 , μ ′ ( s i + 1 ∣ θ Q ′ ) ∣ θ Q ′ ) y_i = r_i + \gamma Q^{'}(s_{i+1},\mu^{'}(s_{i+1}|\theta^{Q^{'}})|\theta^{Q^{'}}) yi=ri+γQ′(si+1,μ′(si+1∣θQ′)∣θQ′)
L o s s = 1 N Σ ( y i − Q ( s i , a i ∣ θ Q ) ) 2 Loss = \frac{1}{N}\Sigma(y_i-Q(s_i,a_i|\theta^{Q}))^2 Loss=N1Σ(yi−Q(si,ai∣θQ))2, 更新评论员网络
▽ θ μ J = 1 N Σ ▽ a Q ( s , a ∣ θ Q ) ∣ s = s i , a = μ ( s i ) ▽ θ μ μ ( s ∣ θ μ ) ∣ ) s i \bigtriangledown _{\theta^\mu}J = \frac{1}{N}\Sigma \bigtriangledown_a Q(s,a|\theta^Q)|_{s=s_i,a=\mu(s_i)}\bigtriangledown_{\theta^\mu} \mu(s|\theta^\mu)|)_{s_i} ▽θμJ=N1Σ▽aQ(s,a∣θQ)∣s=si,a=μ(si)▽θμμ(s∣θμ)∣)si
更新目标网络:
θ Q ′ = τ θ Q + ( 1 − τ ) θ Q ′ \theta^{Q^{'}} = \tau \theta^Q + (1-\tau)\theta^{Q^{'}} θQ′=τθQ+(1−τ)θQ′
θ μ ′ = τ θ μ + ( 1 − τ ) θ μ ′ \theta^{\mu^{'}} = \tau \theta^\mu + (1-\tau)\theta^{\mu^{'}} θμ′=τθμ+(1−τ)θμ′
6.3 具体代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
import time
##################### hyper parameters ####################
EPISODES = 200
EP_STEPS = 200
LR_ACTOR = 0.001
LR_CRITIC = 0.002
GAMMA = 0.9
TAU = 0.01
MEMORY_CAPACITY = 10000
BATCH_SIZE = 32
RENDER = False
ENV_NAME = 'Pendulum-v1'
########################## DDPG Framework ######################
class ActorNet(nn.Module): # define the network structure for actor and critic
def __init__(self, s_dim, a_dim):
super(ActorNet, self).__init__()
self.fc1 = nn.Linear(s_dim, 30)
self.fc1.weight.data.normal_(0, 0.1) # initialization of FC1
self.out = nn.Linear(30, a_dim)
self.out.weight.data.normal_(0, 0.1) # initilizaiton of OUT
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
x = self.out(x)
x = torch.tanh(x)
actions = x * 2 # for the game "Pendulum-v0", action range is [-2, 2]
return actions
class CriticNet(nn.Module):
def __init__(self, s_dim, a_dim):
super(CriticNet, self).__init__()
self.fcs = nn.Linear(s_dim, 30)
self.fcs.weight.data.normal_(0, 0.1)
self.fca = nn.Linear(a_dim, 30)
self.fca.weight.data.normal_(0, 0.1)
self.out = nn.Linear(30, 1)
self.out.weight.data.normal_(0, 0.1)
def forward(self, s, a):
x = self.fcs(s)
y = self.fca(a)
actions_value = self.out(F.relu(x+y))
return actions_value
class DDPG(object):
def __init__(self, a_dim, s_dim, a_bound):
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
self.pointer = 0 # serves as updating the memory data
# Create the 4 network objects
self.actor_eval = ActorNet(s_dim, a_dim)
self.actor_target = ActorNet(s_dim, a_dim)
self.critic_eval = CriticNet(s_dim, a_dim)
self.critic_target = CriticNet(s_dim, a_dim)
# create 2 optimizers for actor and critic
self.actor_optimizer = torch.optim.Adam(self.actor_eval.parameters(), lr=LR_ACTOR)
self.critic_optimizer = torch.optim.Adam(self.critic_eval.parameters(), lr=LR_CRITIC)
# Define the loss function for critic network update
self.loss_func = nn.MSELoss()
def store_transition(self, s, a, r, s_): # how to store the episodic data to buffer
transition = np.hstack((s, a, [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old data with new data
self.memory[index, :] = transition
self.pointer += 1
def choose_action(self, s):
# print(s)
s = torch.unsqueeze(torch.FloatTensor(s), 0)
return self.actor_eval(s)[0].detach()
def learn(self):
# softly update the target networks
for x in self.actor_target.state_dict().keys():
eval('self.actor_target.' + x + '.data.mul_((1-TAU))')
eval('self.actor_target.' + x + '.data.add_(TAU*self.actor_eval.' + x + '.data)')
for x in self.critic_target.state_dict().keys():
eval('self.critic_target.' + x + '.data.mul_((1-TAU))')
eval('self.critic_target.' + x + '.data.add_(TAU*self.critic_eval.' + x + '.data)')
# sample from buffer a mini-batch data
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
batch_trans = self.memory[indices, :]
# extract data from mini-batch of transitions including s, a, r, s_
batch_s = torch.FloatTensor(batch_trans[:, :self.s_dim])
batch_a = torch.FloatTensor(batch_trans[:, self.s_dim:self.s_dim + self.a_dim])
batch_r = torch.FloatTensor(batch_trans[:, -self.s_dim - 1: -self.s_dim])
batch_s_ = torch.FloatTensor(batch_trans[:, -self.s_dim:])
# make action and evaluate its action values
a = self.actor_eval(batch_s)
q = self.critic_eval(batch_s, a)
actor_loss = -torch.mean(q)
# optimize the loss of actor network
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# compute the target Q value using the information of next state
a_target = self.actor_target(batch_s_)
q_tmp = self.critic_target(batch_s_, a_target)
q_target = batch_r + GAMMA * q_tmp
# compute the current q value and the loss
q_eval = self.critic_eval(batch_s, batch_a)
td_error = self.loss_func(q_target, q_eval)
# optimize the loss of critic network
self.critic_optimizer.zero_grad()
td_error.backward()
self.critic_optimizer.step()
############################### Training ######################################
# Define the env in gym
env = gym.make(ENV_NAME)
env = env.unwrapped
env.seed(1)
s_dim = env.observation_space.shape[0]
a_dim = env.action_space.shape[0]
a_bound = env.action_space.high
a_low_bound = env.action_space.low
ddpg = DDPG(a_dim, s_dim, a_bound)
var = 3 # the controller of exploration which will decay during training process
t1 = time.time()
for i in range(EPISODES):
s = env.reset()
ep_r = 0
for j in range(EP_STEPS):
if RENDER: env.render()
# add explorative noise to action
a = ddpg.choose_action(s)
a = np.clip(np.random.normal(a, var), a_low_bound, a_bound)
s_, r, done, info, _ = env.step(a)
ddpg.store_transition(s, a, r / 10, s_) # store the transition to memory
if ddpg.pointer > MEMORY_CAPACITY:
var *= 0.9995 # decay the exploration controller factor
ddpg.learn()
s = s_
ep_r += r
if j == EP_STEPS - 1:
print('Episode: ', i, ' Reward: %i' % (ep_r), 'Explore: %.2f' % var)
if ep_r > -300 : RENDER = True
break
print('Running time: ', time.time() - t1)
if __name__ == "__main__":
learn()
env.close()
6.4 演示效果